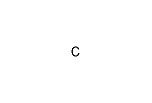読み方:しーぷらすぷらす
《C++ languageとも》コンピューターのプログラミング言語の一。C言語にオブジェクト指向の拡張を施したもの。米国AT&T社が1992年に策定。C++言語。シープラプラ。
読み方:しー
3 〈C〉《(スウェーデン)Celsius》セ氏温度を表す記号。
6 〈C〉音楽の用語。
7 〈c〉《(フランス)centi-》数の単位、センチの記号。
9 〈C〉《(フランス)coulomb》電気量の単位、クーロンの記号。
10 〈©〉⇒丸(まる)シー
12 〈C〉インフルエンザウイルスの型。
13 〈C〉《complement》英文法などで、補語を示す符号。→S →V →O
| 分子式: | C |
| その他の名称: | 炭素【動物性,植物性】、カーボンブラックエキストラクト、Carbon black extract、Carbon、C、活性炭、Activated carbon、活性炭素、Graphitized carbon black、Carbon black、Acetylene black、せきぼく、Grapite、カーボンブラック、アセチレンブラック、黒鉛化カーボンブラック、Activeated carbon【powder】、活性炭【粒状】、Activeated carbon【granule】、活性炭【粉末】、AST-120、クレメジン、Kremezin |
| 体系名: | 炭素 |
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2026/03/01 16:45 UTC 版)
|
Cc Cc
|
|||||||||||||||||||||||||||||||
| ラテン文字 | |||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|||||||||||||||||||||||||||||||
Cは、ラテン文字(アルファベット)の3番目の文字。小文字は c 。
ギリシア文字のΓ(ガンマ)の字体に由来し、キリル文字のГも同系である。これに対し、キリル文字のСは別字で、ラテン文字のSに相当する文字である。


大文字、小文字とも半円形ないし不完全な円である。
フラクトゥールでは
| 大文字 | Unicode | JIS X 0213 | 文字参照 | 小文字 | Unicode | JIS X 0213 | 文字参照 | 備考 |
|---|---|---|---|---|---|---|---|---|
| C | U+0043 |
1-3-35 |
CC |
c | U+0063 |
1-3-67 |
cc |
半角 |
| C | U+FF23 |
1-3-35 |
CC |
c | U+FF43 |
1-3-67 |
cc |
全角 |
| Ⓒ | U+24B8 |
‐ |
ⒸⒸ |
ⓒ | U+24D2 |
1-12-35 |
ⓒⓒ |
丸囲み |
| 🄒︎ | U+1F112 |
‐ |
🄒🄒 |
⒞ | U+249E |
‐ |
⒞⒞ |
括弧付き |
| 𝐂 | U+1D402 |
‐ |
𝐂𝐂 |
𝐜 | U+1D41C |
‐ |
𝐜𝐜 |
太字 |
| 𝐶 | U+1D436 |
‐ |
𝐶𝐶 |
𝑐 | U+1D450 |
‐ |
𝑐𝑐 |
イタリック体 |
| 𝑪 | U+1D46A |
‐ |
𝑪𝑪 |
𝒄 | U+1D484 |
‐ |
𝒄𝒄 |
イタリック体太字 |
| 𝒞 | U+1D49E |
‐ |
𝒞𝒞 |
𝒸 | U+1D4B8 |
‐ |
𝒸𝒸 |
筆記体 |
| 𝓒 | U+1D4D2 |
‐ |
𝓒𝓒 |
𝓬 | U+1D4EC |
‐ |
𝓬𝓬 |
筆記体太字 |
| ℭ | U+212D |
‐ |
ℭℭ |
𝔠 | U+1D520 |
‐ |
𝔠𝔠 |
フラクトゥール |
| ℂ | U+2102 |
‐ |
ℂℂ |
𝕔 | U+1D554 |
‐ |
𝕔𝕔 |
黒板太字 |
| 𝕮 | U+1D56E |
‐ |
𝕮𝕮 |
𝖈 | U+1D588 |
‐ |
𝖈𝖈 |
フラクトゥール太字 |
| 𝖢 | U+1D5A2 |
‐ |
𝖢𝖢 |
𝖼 | U+1D5BC |
‐ |
𝖼𝖼 |
サンセリフ |
| 𝗖 | U+1D5D6 |
‐ |
𝗖𝗖 |
𝗰 | U+1D5F0 |
‐ |
𝗰𝗰 |
サンセリフ太字 |
| 𝘊 | U+1D60A |
‐ |
𝘊𝘊 |
𝘤 | U+1D624 |
‐ |
𝘤𝘤 |
サンセリフイタリック |
| 𝘾 | U+1D63E |
‐ |
𝘾𝘾 |
𝙘 | U+1D658 |
‐ |
𝙘𝙘 |
サンセリフイタリック太字 |
| 𝙲 | U+1D672 |
‐ |
𝙲𝙲 |
𝚌 | U+1D68C |
‐ |
𝚌𝚌 |
等幅フォント |
| Ⅽ | U+216D |
1-3-35 |
ⅭⅭ |
ⅽ | U+217D |
1-3-67 |
ⅽⅽ |
ローマ数字100 |
| 記号 | Unicode | JIS X 0213 | 文字参照 | 名称 |
|---|---|---|---|---|
| ᴄ | U+1D04 |
‐ |
ᴄᴄ |
LATIN LETTER SMALL CAPITAL C |
| ᶜ | U+1D9C |
‐ |
ᶜᶜ |
MODIFIER LETTER SMALL C |
| 🄲︎ | U+1F132 |
‐ |
🄲🄲 |
SQUARED LATIN CAPITAL LETTER C |
| 🅒︎ | U+1F152 |
‐ |
🅒🅒 |
NEGATIVE CIRCLED LATIN CAPITAL LETTER C |
| 🅲︎ | U+1F172 |
‐ |
🅲🅲 |
NEGATIVE SQUARED LATIN CAPITAL LETTER C |
| 🄫︎ | U+1F12B |
‐ |
🄫🄫 |
CIRCLED ITALIC LATIN CAPITAL LETTER C |
(C. から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2026/03/03 06:11 UTC 版)
|
C#のロゴ
|
|
| パラダイム | 構造化プログラミング、命令型プログラミング、オブジェクト指向プログラミング、イベント駆動型プログラミング、関数型プログラミング、ジェネリックプログラミング、リフレクション、クラスベース、正格プログラミング、マルチパラダイムプログラミング |
|---|---|
| 登場時期 | 2000年 |
| 設計者 | マイクロソフト(アンダース・ヘルスバーグ率いるチーム) |
| 開発者 | マイクロソフト |
| 最新リリース | 14.0/ 2025年11月11日[a 1] |
| 型付け | 強い静的型付け(4.0から動的型導入) |
| 主な処理系 | CLR, Mono |
| 影響を受けた言語 | C++、C言語、Java、Delphi、Modula-3、Cω、Eiffel、F Sharp、Haskell、Icon、J Sharp、Microsoft Visual J++、Object Pascal、Rust、ML、Visual Basic |
| 影響を与えた言語 | D言語, F#, Java, Nemerle, Vala, TypeScript |
| プラットフォーム | Windows, macOS, Linuxなど |
| ライセンス | Apacheライセンス (Roslyn) |
| ウェブサイト | docs |
| 拡張子 | cs、csx |
C#(シーシャープ)は、マイクロソフトが開発した汎用かつマルチパラダイムなプログラミング言語。
 |
この節は検証可能な参考文献や出典が全く示されていないか、不十分です。 (2026年3月)
|
開発にはボーランドのTurbo PascalやDelphiを開発したアンダース・ヘルスバーグを筆頭として多数のDelphi開発陣が参加している。構文はC系言語(C言語、C++、Java[注釈 1]など)の影響を受けており、その他の要素には、以前、ヘルスバーグが所属していたボーランド設計のDelphiの影響が見受けられる。また、主要言語へのasync/await構文や、ヘルスバーグが言語設計に関わるTypeScriptでのジェネリクス採用など、他言語への影響も見られる。
C#は共通言語ランタイム(CLR)などの共通言語基盤(CLI)が解釈する共通中間言語(CIL)にコンパイルされて実行される。
また、C#はマルチパラダイムをサポートする汎用高レベルプログラミング言語で、静的型付け、タイプセーフ、スコープ、命令型、宣言型、関数型、汎用型、オブジェクト指向(クラスベース)、コンポーネント指向のプログラミング分野を含んでいる。他にも自動ボックス化、デリゲート、プロパティ、インデクサ、カスタム属性、ポインタ演算操作、構造体(値型オブジェクト)、多次元配列、可変長引数、async/await構文、null安全などの機能を持つ。また、Javaと同様に大規模ライブラリ、プロセッサ・アーキテクチャに依存しない実行形態、ガベージコレクション、JITコンパイルによる実行の高速化、AOTコンパイラによる高速実行、などが実現されている(もっともこれらはC#の機能というより.NET によるものである)。
共通言語基盤といった周辺技術も含め、マイクロソフトのフレームワークである「.NET」の一部である。また、以前のVisual J++で「非互換なJava」をJavaに持ち込もうとしたマイクロソフトとは異なり、その多くの[注釈 2]仕様を積極的に公開し、ECMAやISOなど標準化機構に託して自由な利用を許す[注釈 3]など、同社の姿勢の変化があらわれている。
.NET構想における中心的な開発言語であり、XML WebサービスやASP.NETの記述にも使用される。他の.NET系の言語でも記述可能だが、.NET APIはC#からの利用を第一に想定されており、他の.NET系言語(特に2023年以降新構文の追加なしと宣言されたVB.NET[a 2])では利用できない、あるいは将来的に利用できなくなる機能が存在する。
C#は、Windowsの.NET Framework上で動作することを前提として開発された言語であった。2016年6月からはクロスプラットフォームな.NETランタイム上で動作する[2]。Microsoft Windowsを含む複数のデスクトップ環境、ウェブアプリ・ウェブサービス(ASP.NET、ASP.NET Coreなど)、クラウドコンピューティング、モバイル、ゲーム開発(ゲームエンジンのUnityなど)などで採用されている。
マイクロソフトの統合開発環境(Microsoft Visual Studio)では、Microsoft Visual C#がC#に対応している。また、Visual Studio Codeに専用のC#向け拡張(C# DevKit)を導入することでクロスプラットフォームで開発することが可能[a 3]。
共通言語仕様のCLSによって、他のCLS準拠の言語(F#やVisual Basic .NET、C++/CLIなど)と相互に連携することができる。
| バージョン | 言語仕様 | リリース時期[a 4] | .NET | Visual Studio | 出典と注釈 | ||||
|---|---|---|---|---|---|---|---|---|---|
| ECMA[3][4] | ISO/IEC | マイクロソフト | 公式発表 | 個人サイト | その他 | ||||
| 1.0 | ECMA-334:2003 (2002年12月) |
ISO/IEC 23270:2003 (2003年4月) |
CSharp Language Specification v1.0.doc | 2002年1月 | .NET Framework 1.0 | .NET (2002) | [a 5] | N/A | N/A |
|
csharp language specification v1.2.doc | 2003年4月 | .NET Framework 1.1 | .NET 2003 | [b 1] | ||||
| 2.0 | ECMA-334:2006 (2006年6月) |
ISO/IEC 23270:2006 (2006年9月) |
csharp 2.0 specification_sept_2005.doc | 2005年11月 |
|
2005 | [b 2] | ||
| 3.0 | N/A | CSharp Language Specification.doc | 2007年11月 |
|
2008 | N/A | [注釈 4] | ||
| 4.0 | N/A | 2010年4月 | .NET Framework 4 | 2010 | [b 3] | N/A | |||
| 5.0 | ECMA-334:2017 (2017年12月) |
ISO/IEC 23270:2018 (2018年12月) |
C# Language Specification 5.0 | 2012年8月 | .NET Framework 4.5 |
|
[b 4] | ||
| 6.0 | ECMA-334:2022 (2022年6月) |
N/A | N/A | 2015年7月 |
|
2015 | N/A | [6] | |
| 7.0 | ECMA-334:2023 (2023年12月) |
ISO/IEC 20619:2023 (2023年9月) |
2017年3月 | .NET Framework 4.7 | 2017 version 15.0 | [a 6] | [7] | ||
| 7.1 | N/A | 2017年8月 | .NET Core 2.0 | 2017 version 15.3 | [a 5][a 7] | N/A | |||
| 7.2 | 2017年11月 | .NET Core 2.0 | 2017 version 15.5 | [a 5][a 8] | |||||
| 7.3 | 2018年5月 |
|
2017 version 15.7 | [a 9] | [b 5] | ||||
| 8.0 | C# 8 のドラフト仕様 | 2019年9月 |
|
2019 version 16.3 | [a 10] | N/A | [8] | ||
| 9.0 | 機能仕様 | 2020年11月 | .NET 5.0 | 2019 version 16.8 | [a 11][a 12] | [注釈 5] | |||
| 10.0 | 2021年12月 |
|
2022 version 17.0 | [a 13][a 14] | |||||
| 11.0 | 2022年11月8日 | .NET 7.0 | 2022 version 17.4 | [a 15][a 16][a 17] | [b 6] | ||||
| 12.0 | 2023年11月14日 | .NET 8.0 | 2022 version 17.8 | [a 18][a 19][a 20][a 21] | [b 7] | ||||
| 13.0 | 2024年11月12日 | .NET 9.0 | 2022 version 17.12 | [a 22][a 23][a 24] | [b 8] | ||||
| 14.0 | 2025年11月11日 | .NET 10.0 | 2026 version 18.0 | [a 25][a 26][a 1][a 27] | [b 9] | ||||
さまざまな意味において[要追加記述]、基盤である共通言語基盤(CLI)の多くの機能を反映している言語であるといえる。C#にある組み込み型のほとんどは、共通言語基盤のフレームワークに実装されている値型と対応している。
しかし、C#の言語仕様はコンパイラのコード生成については何も言及していないため、CLRに対応しなければならないとか、 CILなどの特定のフォーマットのコードを生成しなければならないとかいうことは述べられていない。
そのため、理論的にはC++やFORTRANのように環境依存のマシン語を生成することも可能である。しかし、現在存在するすべてのC#コンパイラはCLIをターゲットにしている。
.NET 7.0以降で可能になった事前コンパイルの一種である「Native AOT」でデプロイすることで実行可能な環境依存のバイナリを出力することが可能である。しかしながらこの手法もCLIとランタイムを事前に各アーキテクチャ向けのバイナリに変換しているだけであり、CLIを経由することに変わりはない[a 28]。
特殊な例としては、UnityのScripting Backendである「IL2CPP」[9]や「Burst」[10]がある。IL2CPPはC#をコンパイルしたCILをさらにC++コードへと変換後、ネイティブバイナリへC++コンパイラによってコンパイルされる。BurstはC#をコンパイルしたCILをLLVMコンパイラによってネイティブバイナリへコンパイルするものである。
最新のC#ではHello Worldを下記の通りに1行で記述できる[a 29]。
Console.WriteLine("Hello World!");
上記のコードは、コンパイラによって下記の様なコードに展開される。
using System;
namespace Wikipedia
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World!");
}
}
}
次の言語機能によって実現されている。ただし、未対応の古いコンパイラを用いる場合は、省略できない。
C#では、CやC++と比較してさまざまな制限や改良が加えられている。また、仕様の多くはC#言語というよりは、基盤である.NETそのものに依拠している。Javaで導入された制限および改良をC#でも同様に採用しているものが多いが、C#で新たに導入された改良がのちにJavaにも同様に採用されたものもある。その例を次に挙げる。
boolが存在し、while文やif文のように条件をとるステートメントには、bool型の式を与えなければならない。C言語では、ブール型が無くint型(0を偽とし、非0を真とする)に兼用させた上、(ヌルポインタを偽とみなすこととするといろいろと便利だった、ということもあり)ポインタでもwhile文やif文に与える式にできる、という仕様としていた。これは便利なこともあったが、本来比較式を記述すべきところで誤って代入式を記述してもコンパイル適合となってしまうなど、ミスが見逃されることもあった。C#では
ミスを防止するため[要出典]に、そのような仕様ではなくブール型を独立させ、またブール型を厳密に要求する場所を多くしている。switch文に整数型あるいは整数型に準ずる型のみならず、文字列型stringを使用できる。caseラベルには、整数型あるいは整数型に準ずる型の定数のみならず、文字列リテラル(文字列定数)を使用できる。
unsafeスコープ内のみで使用することができ、適切な権限をもつプログラムのみがunsafeとマークされたコードを実行することができる。オブジェクトへのアクセスの大部分は管理された安全な参照によってなされ、大部分の算術演算はオーバフローのチェックがなされる。unsafeポインタは値型や文字列を指すことができる。セーフコードでは、必ずしもそうする必要はないものの、IntPtr型を通してポインタをやりとりすることができる。IDisposableインタフェースとusingステートメントまたはusing宣言によってなされる。objectクラス (System.Object) の派生型である。つまりobjectクラスのもつすべてのプロパティやメソッドを継承する。例えば、すべての型はToString()メソッドをもつ。class) は参照型であり、構造体 (struct) および列挙型 (enum) は値型である。構造体はクラスよりも軽量で、C/C++との相互運用性に優れるが、派生型を定義することができない。event) が用意されている。部分型(英: Partial Type)が導入された[a 5]。以下のようにクラスや構造体の宣言にpartial修飾子をつけることで、その宣言を分割することができる。
partial class MyClass { int a; }
partial class MyClass { int b; }
これは以下と同義である。
class MyClass { int a; int b; }
これによって、巨大なクラスを分割したり、自動生成されたコードを分離したりすることができる。partial修飾子はすべての宣言につける必要がある[11]。
ジェネリクスが導入された[a 5]。これは.NET Framework 2.0の機能である。クラス、構造体、インタフェース、デリゲート、メソッドに対して適用することができる。
.NETのGenericsはC++のテンプレート、あるいはJavaにおけるそれとも異なるもので、コンパイルによってではなく実行時にランタイムによって特殊化される。これによって異なる言語間の運用を可能にし、リフレクションによって型パラメーターに関する情報を取得することができる。また、where節によって型パラメーターに制約を与えることができる。一方、C++のように型パラメーターとして式を指定することはできない。なお、ジェネリックメソッドの呼び出し時に引数によって型パラメーターが推論できる場合、型パラメーターの指定は省略できる[12]。
静的クラスが導入された[a 5]。static属性をクラスの宣言につけることで、クラスはインスタンス化できなくなり、静的なメンバーしか持つことができなくなる[11]。
yieldキーワードによるコルーチンを使うことで、イテレータの生成を楽に実装できるようになった。
プロパティのgetもしくはsetアクセサのどちらかにアクセス修飾子を指定することでアクセス制御が別個にできるようになった[a 5]。次の例では、getアクセサはpublic、setアクセサはprivateである[13]。
public class MyClass
{
private string status = string.Empty;
public string Status
{
get { return status; }
private set { status = value; }
}
}
nullを保持できる値型、Nullableが導入された[a 5]。
int? i = 512;
i = null;
int? j = i + 500; //jはnullとなる。nullとの演算の結果はnullになる。
int?はNullable<int>の糖衣構文である。また、nullを保持しているNull許容型のインスタンスをボックス化しようとすると、単に空参照(null)に変換される[a 35][14]。
int? x = null;
object o = x;
System.Console.WriteLine(o == null); //Trueが出力される
また、null結合演算子 (??)が導入された。これは、nullでない最初の値を返す。
object obj1 = null;
object obj2 = new object();
object obj3 = new object();
return obj1 ?? obj2 ?? obj3; // obj2 を返す
この演算子は主にNullable型を非Nullable型に代入するときに使われる。
int? i = null;
int j = i ?? -1; // nullをint型に代入することはできない
var キーワードが導入され、型推論を利用したローカル変数の宣言ができるようになった[a 5]。
var s = "foo";
// 上の文は右辺が string 型であるため、次のように解釈される:
string s = "foo";
// 以下に挙げる文は誤りである(コンパイルエラーとなる):
var v; // 初期化式を欠いている (型を推論する対象が存在しない)
var v = null; // 型が推論できない (曖昧である)
拡張メソッド(英: extension method)が導入された[a 5]。既存のクラスを継承して新たなクラスを定義することなく、新たなインスタンスメソッドを疑似的に追加定義することができる。具体的には、入れ子になっていない、非ジェネリックの静的クラス内に、this 修飾子をつけた、拡張メソッドを追加する対象の型の引数を最初に持つメソッドをまず定義する。これによって、通常の静的メソッドとしての呼び出しの他に、指定した型のインスタンスメソッドとしての呼び出しを行うことができるメソッドを作ることができる。以下に例を挙げる:
public static class StringUtil
{
public static string Repeat(this string str, int count)
{
var array = new string[count];
for (var i = 0; i < count; ++i) array[i] = str;
return string.Concat(array);
}
}
この例は、文字列(string型のインスタンス)を指定した回数繰り返し連結したものを返すメソッドRepeatを、既存のstring型に追加している。このメソッドは、以下のように呼び出すことができる:
// 静的メソッドとしての呼び出し
StringUtil.Repeat("foo", 4);
// 拡張メソッドとしての呼び出し
"foo".Repeat(4);
// (どちらの例も "foofoofoofoo" を返す)
また、列挙型やインタフェースなど本来メソッドの実装を持ち得ない型に、見かけ上インスタンスメソッドを追加することも可能である。以下に例を挙げる:
public enum Way
{
None, Left, Right, Up, Down
}
public static class EnumUtil
{
public static Way Reverse(this Way src)
{
switch (src)
{
case Way.Left: return Way.Right;
case Way.Right: return Way.Left;
case Way.Up: return Way.Down;
case Way.Down: return Way.Up;
default: return Way.None;
}
}
}
このメソッドは以下のように呼び出すことができる:
Way l = Way.Left;
Way r = l.Reverse(); // Way.Right
拡張メソッドは糖衣構文の一種であり、カプセル化の原則に違反するものではないが、必要な場合に限り注意して実装することがガイドラインとして推奨されている[a 36]。
部分メソッドが導入された[a 5]。部分型(partial型)内で定義されたprivateで、かつ戻り値が voidのメソッドに partial修飾子をつけることでメソッドの宣言と定義を分離させることができる。定義されていない部分メソッドは何も行わず、何らエラーを発生させることもない。例えば:
partial class Class
{
partial void DebugOutput(string message);
void Method()
{
DebugOutput("Some message");
Console.WriteLine("Did something.");
}
}
上のコードにおいて Method() を呼び出すと、Did something. と表示されるだけだが、ここで以下のコード:
partial class Class
{
partial void DebugOutput(string message)
{
Console.Write("[DEBUG: {0}] ", message);
}
}
を追加した上でMethod()を呼び出すと、[DEBUG: Some message] Did something.と表示される。
ラムダ式が導入された[a 5]。この名前はラムダ計算に由来する。
以下の匿名メソッド
// iを変数としてi+1を返すメソッド
delegate (int i) { return i + 1; }
は、ラムダ式を使って次のように記述できる:
(int i) => i + 1; /* 式形式のラムダ */
//或いは:
(int i) => { return i + 1; }; /* ステートメント形式のラムダ */
ラムダ式は匿名メソッドと同様に扱えるが、式形式のラムダがExpression<TDelegate>型として扱われた場合のみ匿名メソッドとして扱われず、コンパイラによって式木を構築するコードに変換される。匿名デリゲートが実行前にコンパイルされたCILを保持するのに対し、式木はCILに実行時コンパイル可能であるDOMのような式の木構造そのものを保持する。これはLINQクエリをSQLクエリなどに変換する際に役立つ。
以下は、3つの任意の名前の変数、整数、括弧、及び四則演算子のみで構成された式を逆ポーランド記法に変換する汎用的なコードである:
public static string ToRPN(Expression<Func<int, int, int, int>> expression)
{
return Parse((BinaryExpression) expression.Body).TrimEnd(' ');
}
private static string Parse(BinaryExpression expr)
{
string str = "";
if (expr.Left is BinaryExpression)
{
str += Parse((BinaryExpression) expr.Left);
}
else if (expr.Left is ParameterExpression)
{
str += ((ParameterExpression) expr.Left).Name + " ";
}
else if (expr.Left is ConstantExpression)
{
str += ((ConstantExpression) expr.Left).Value + " ";
}
if (expr.Right is BinaryExpression)
{
str += Parse((BinaryExpression) expr.Right);
}
else if (expr.Right is ParameterExpression)
{
str += ((ParameterExpression) expr.Right).Name + " ";
}
else if (expr.Right is ConstantExpression)
{
str += ((ConstantExpression) expr.Right).Value + " ";
}
return str + expr.NodeType.ToString()
.Replace("Add", "+")
.Replace("Subtract", "-")
.Replace("Multiply", "*")
.Replace("Divide", "/")
+ " ";
}
// 呼び出し例:
ToRPN((x, y, z) => (x + 1) * ((y - 2) / z)); // "x 1 + y 2 - z / *" を返す
オブジェクトの初期化が式として簡潔に記述できるようになった。
var p = new Point { X = 640, Y = 480 };
// 上の文は次のように解釈される:
Point __p = new Point();
__p.X = 640;
__p.Y = 480;
Point p = __p;
また、コレクションの初期化も同様に簡潔に記述できるようになった。
var l = new List<int> {1, 2, 3};
var d = new Dictionary<string, int> {{"a", 1}, {"b", 2}, {"c", 3}};
// 上の文は次のように解釈される:
List<int> __l = new List<int>();
__l.Add(1);
__l.Add(2);
__l.Add(3);
List<int> l = __l;
Dictionary<string, int> __d = new Dictionary<string, int>();
__d.Add("a", 1);
__d.Add("b", 2);
__d.Add("c", 3);
Dictionary<string, int> d = __d;
但し、上のコードでは匿名の変数に便宜的に __p、__l、__d と命名している。実際はプログラマはこの変数にアクセスすることはできない。
プロパティをより簡潔に記述するための自動実装プロパティが導入された[a 5]。プロパティの定義にget; set;と記述することで、プロパティの値を保持するための匿名のフィールド(プログラマは直接参照することはできない)と、そのフィールドにアクセスするためのアクセサが暗黙に定義される。また、C# 5.0までは get;とset;のどちらか片方だけを記述することは出来なかったが、C# 6.0からはget;のみが可能。以下のコード:
public int Value { get; set; }
は、以下のようなコードに相当する動作をする:
private int __value;
public int Value
{
get { return __value; }
set { __value = value; }
}
但し、上のコードでは匿名のフィールドに便宜的に__valueと命名している。実際はプログラマはこのフィールドにアクセスすることはできない。
一時的に使用される型を簡単に定義するための匿名型が導入された[a 5]。以下に例を挙げる:
new { Name = "John Doe", Age = 20 }
上の式は、以下の内容のクラスを暗黙に定義する。定義されたクラスは匿名であるが故にプログラマは参照できない。
public string Name { get; }
public int Age { get; }
同じ型、同じ名前のプロパティを同じ順序で並べた匿名型は同じであることが保証されている。即ち、以下のコード:
var her = new { Name = "Jane Doe", Age = 20 }
var him = new { Name = "John Doe", Age = 20 }
において、her.GetType() == him.GetType()はtrueである。
newキーワードを用いた配列の宣言の際、型を省略できるようになった。匿名型の配列を宣言する際に威力を発揮する。
var a = new[] {"foo", "bar", null};
// 上の文は次のように解釈される:
string[] a = new string[] {"foo", "bar", null};
// 以下の文:
var a = new[] {"foo", "bar", 123};
// は次のように解釈されることなく、誤りとなる:
object[] a = new object[] {"foo", "bar", 123};
LINQをサポートするために、クエリ式が導入された[a 5]。これはSQLの構文に類似しており、最終的に通常のメソッド呼び出しに変換されるものである。以下に例を示す:
var passedStudents =
from s in students
where s.MathScore + s.MusicScore + s.EnglishScore > 200
select s.Name;
上のコードは以下のように変換される:
var passedStudents = students
.Where(s => s.MathScore + s.MusicScore + s.EnglishScore > 200)
.Select(s => s.Name);
C# 3.0で追加された構文の多くは式であるため、より巨大な式(当然クエリ式も含まれる)の一部として組み込むことができる。旧来複数の文に分けたり、作業用の変数を用意して記述していたコードを単独の式としてより簡潔に記述できる可能性がある。
出井秀行著の『実戦で役立つ C#プログラミングのイディオム/定石&パターン』(技術評論社、2017年)という書籍ではクエリ構文よりメソッド構文を推奨しており、クエリ構文ではLINQの全ての機能を使用できるわけではないこと、メソッド呼び出しは処理を連続して読める可読性があること、メソッド呼び出しであればMicrosoft Visual Studioの強力なインテリセンスが利用できることを理由に、著者はクエリ構文をほとんど使用していないと記している。
dynamicキーワードが導入され、動的型付け変数を定義できるようになった[a 5]。dynamic型として宣言されたオブジェクトに対する操作のバインドは実行時まで遅延される。
// xはint型と推論される:
var x = 1;
// yはdynamic型として扱われる:
dynamic y = 2;
public dynamic GetValue(dynamic obj)
{
// objにValueが定義されていなくとも、コンパイルエラーとはならない:
return obj.Value;
}
VBやC++に実装されているオプション引数・名前付き引数が、C#でも利用できるようになった[a 5]。
public void MethodA()
{
// 第1引数と第2引数を指定、第3引数は未指定:
Console.WriteLine("Ans: " + MethodB(1, 2)); // Ans: 3 … 1 + 2 + 0となっている
// 第1引数と第3引数を指定、第2引数は未指定:
Console.WriteLine("Ans: " + MethodB(A: 1, C: 3)); // Ans: 4 … 1 + 0 + 3となっている
}
// 引数が指定されなかった場合のデフォルト値を等号で結ぶ:
public int MethodB(int A = 0, int B = 0, int C = 0)
{
return A + B + C;
}
ジェネリクスの型引数に対してin、out修飾子を指定することにより、ジェネリクスの共変性・反変性を指定できるようになった[a 5]。
IEnumerable<string> x = new List<string> { "a", "b", "c" };
// IEnumerable<T>インターフェイスは型引数にout修飾子が指定されているため、共変である。
// したがって、C# 4.0では次の行はコンパイルエラーにならない
IEnumerable<object> y = x;
静的usingディレクティブを利用することで、型名の指定無しに他クラスの静的メンバーの呼び出しを行えるようになった。利用するにはusing staticの後に完全修飾なクラス名を指定する。
using static System.Math;
// ↑ソースコードの上部で宣言
class Hogehoge {
// System.Math.Pow() , System.Math.PI を修飾無しで呼び出す
double area = Pow(radius, 2) * PI;
}
catchの後にwhenキーワードを使用することで、処理する例外を限定することができるようになった。
try {
// ...
}
catch (AggregateException ex) when (ex.InnerException is ArgumentException) {
// ...
}
out引数で値を受け取る場合、その場所で変数宣言可能となった[a 38]。
total += int.TryParse("123", out var num) ? num : 0;
is式の構文が拡張され、型の後ろに変数名を宣言できるようになった[a 38]。拡張されたis式はマッチした場合に宣言した変数にキャストした値を代入し、さらにtrueと評価される。マッチしなかった場合はfalseと評価され、宣言した変数は未初期化状態となる。
void CheckAndSquare(object obj) {
// objの型チェックと同時にnumに値を代入する。
if (obj is int num && num >= 0) {
num = num * num;
}
else {
num = 0;
}
// if文の条件セクションは、ifの外側と同じスコープ
Console.WriteLine(num);
}
switch文のマッチ方法が拡張され、caseラベルに従来の「定数パターン」に加え、新たに「型パターン」を指定できるようになった。また、「型パターン」のcaseラベルでは、when句に条件を指定することができる。「型パターン」を含むswitch文では、必ずしも条件が排他的でなくなったため、最初にマッチしたcaseラベルの処理が実行される。[a 39]
void Decide(object obj) {
switch (obj) {
case int num when num < 0:
Console.WriteLine($"{num}は負の数です。");
break;
case int num:
Console.WriteLine($"{num}を二乗すると{num * num}です。");
break;
case "B":
Console.WriteLine($"これはBです。");
break;
case string str when str.StartsWith("H"):
Console.WriteLine($"{str}はHから始まる文字列です。");
break;
case string str:
Console.WriteLine($"{str}は文字列です。");
break;
case null:
Console.WriteLine($"nullです");
break;
default:
Console.WriteLine("判別できませんでした");
break;
}
}
タプルのための軽量な構文が導入された[a 38]。従来のSystem.Tupleクラスとは別に、System.ValueTuple構造体が新しく追加された。
2個以上の要素を持つタプルのための記法が導入された。引数リストと同様の形式で、タプルを記述できる。
// タプル記法
(int, string) tuple = (123, "Apple");
Console.WriteLine($"{tuple.Item1}個の{tuple.Item2}");
多値戻り値を簡単に扱えるように、分解がサポートされた[a 38]。
var tuple = (123, "Apple");
// 分解
(int quantity, string name) = tuple;
Console.WriteLine($"{quantity}個の{name}");
分解はタプルに限らない。Deconstruct()メソッドが定義されたクラスでも、分解を利用できる[a 38]。
以下に、DateTime型に分解を導入する例を示す。
static class DateExt {
public static void Deconstruct(this DateTime dateTime, out int year, out int month, out int day) {
year = dateTime.Year;
month = dateTime.Month;
day = dateTime.Day;
}
}
上記のコードでDateTime型にDeconstruct()拡張メソッドを定義し、
// 分解
(int year, int month, int day) = DateTime.Now;
のように左辺で3つの変数に値を受け取ることができる。
分解、out引数、パターンマッチングで、値の破棄を明示するために_が利用できるようになった。破棄された値は、後で参照することはできない。
// 年と日は使わない
(_, int month, _) = DateTime.Now;
// 解析結果だけ取得し、変換された値は使わない
bool isNumeric = int.TryParse(str, out _);
switch (obj) {
// string型で分岐するが、値は使わない
case string _:
// Do something.
break;
}
refキーワードの使用方法が拡張された。これによって、安全な参照の使い道が広がった。
戻り値の型をrefで修飾することで、オブジェクトの参照を戻り値とすることができる。
// 二つの参照引数の内、値の大きいものの参照戻り値を返す
static ref int Max(ref int left, ref int right) {
if (left >= right) {
return ref left;
}
else {
return ref right;
}
}
変数の寿命は変わらないため、メソッド終了時に破棄されるローカル変数をref戻り値とすることはできない。
static int s_count = 1;
// メンバーの参照はref戻り値になる。
static ref int ReturnMember() {
return ref s_count;
}
// ref引数はもちろんref戻り値になる。
static ref int ReturnRefParam(ref int something) {
return ref something;
}
// ローカル変数をref戻り値とすることはできない。
// static ref int ReturnLocal() {
// int x = 1;
// return ref x;
// }
ローカル変数の型をrefで修飾することで、参照を代入することができる。
// 参照戻り値を参照変数で受け取る
ref int max = ref Max(ref x, ref y);
// limitとmaxは同じ値を参照する
ref int limit = ref max;
Mainメソッドの戻り値として、Task型、Task(int)型が認められた[a 40]。
static Task Main()
static Task<int> Main()
型推論可能な場面では、defaultの型指定は省略可能となった[a 40]。
int number = default;
string name = default;
C#7.2で追加された仕様は以下の通り[a 41][a 42]。
値型におけるパフォーマンス向上を意図した複数の機能が追加された。
引数にinを指定することで、読み取り専用参照渡しを指定できる。また、戻り値にref readonlyを指定することで、読み取り専用参照戻り値を指定できる。
これにより、構造体のコピーを避けると共に、意図しない値の変更を抑止できる。
構造体宣言時にreadonlyを指定することで、真の読み取り専用構造体を定義できる。readonly構造体の全てのフィールドはreadonlyでなければならず、thisポインタも読み取り専用となる。
これにより、メンバーアクセス時の意図しない防御的コピーを抑止できる。
構造体宣言時にrefを指定することで、ヒープ領域へのコピーを防ぐ構造体がサポートされる。ref構造体では、box化できない、配列を作成できない、型引数になることができない、など、ヒープ領域へのコピーを防ぐための厳しい制限がかかる。
この機能は、Span<T>のような構造体をサポートするために利用され、unsafe文脈以外でのstackallocの利用をも可能とする。
C#4.0で追加された名前付き引数が末尾以外でも利用できるようになった。
Hogehoge(name: "John", 17);
同一アセンブリ内、かつ、継承先からのアクセス許可を表すprivate protectedアクセス修飾子が追加された。
十六進リテラルの0x、二進リテラルの0bの直後のアンダースコアが認められた。
int bin = 0b_01_01;
int hex = 0x_AB_CD;
C#7.3では以下の仕様が追加された[a 43]。
System.Enum、System.Delegateunmanaged(文脈キーワード)unsafe class MyGenericsClass<T1,T2,T3>
where T1 : System.Enum
where T2 : System.Delegate
where T3 : unmanaged {
public MyGenericsClass(T1 enum1, T1 enum2, T2 func, T3 unmanagedValue) {
if (enum1.HasFlag(enum2)) {
func.DynamicInvoke();
}
else {
T3* ptr = &unmanagedValue;
}
}
}
refローカル変数の再割り当てstackalloc初期化子fixedステートメントclass MyOutVar {
// メンバー変数初期化子やコンストラクタ初期化子で出力変数宣言が可能
readonly int x = int.TryParse("123", out var number) ? number : -1;
}
(long, long) tuple = (1L, 2L);
// タプルのすべての要素間で == が比較可能
if (tuple == (1, 2)) { }
// 要素数が異なるタプル同士は比較できない。
//if (tuple == (1, 2, 3)) { }
// C#7.2までは無効な指定(コンパイル自体は可能。無視される)
// C#7.3からはバッキングフィールドに対するAttribute指定と見なされる
[field: NonSerialized]
public int MyProperty { get; set; }
C# 8.0で追加された仕様は以下の通り。[a 44][19]
参照型にnull許容性を指定できるようになった。参照型の型名に?を付加した場合にnull許容参照型となる。
参照型の型名に?を付加しない場合、null非許容参照型となる。
フロー解析レベルでのnull許容性チェックが行われる。null許容値型のNullable<T>のような新しい型は導入されない。
参照型のnull許容性は、null許容コンテキストによって有効、無効の切り替えが可能である。C#7.3以前の互換性のために、既定では無効となっている。
#nullable ディレクティブ: ソースコードの部分ごとにnull許容コンテキストを指定する
annotations オプション、warningsオプションにより、適用範囲を限定できるnull許容参照型の変数名の後に !を使用することで、フロー解析時の警告が免除される。
インタフェースのメンバーに既定の実装を指定できるようになった。また、インタフェースに静的メンバーを持つことができるようになった。
さらに、インタフェースのメンバーにアクセシビリティを指定できるようになった。
public となる。virtual となり override可能である。overrideさせないためにsealedを指定することができる。switch式が追加された。プロパティパターン、タプルパターン、位置指定パターンの追加により、再帰的なパターンマッチングが可能になった。
IAsyncEnumerable<T>インタフェースを返すことで、イテレータ構文と非同期構文の共存が可能になった。
async IAsyncEnumerable<int> EnumerateAsync() {
await Task.Delay(100);
yield return 1;
await Task.Delay(100);
yield return 2;
}
await foreachによって非同期ストリームを列挙する。
async void SpendAsync() {
await foreach (var item in EnumerateAsync()) {
Console.WriteLine(item);
}
}
IndexとRangeを指定できる専用構文が追加された。
Index a = 1; // new Index(1, fromEnd: false)
Index b = ^1; // new Index(1, fromEnd: true)
Range range = a..b; // new Range(start: a, end: b)
stackallocC# 9.0で追加された仕様は以下の通り。
nint型、nuint型)delegate*型)C# 10.0で追加された仕様は以下の通り。
C# 11.0で追加された仕様は以下の通り[a 15][b 6]。
エスケープなどの加工を施さない生の文字列を、3個以上の二重引用符で括る事で表現できる様になった[b 12]。未加工の文字列リテラルとも呼ばれる。生文字列中には、その文字列を括っている二重引用符より少ない数で連続した二重引用符を普通の文字として埋め込む事ができる。文字列の開始を示す二重引用符の直後に何らかの文字列が記述されているかどうかで単一行か複数行かが弁別される。
単一行の場合は、"""あいうえお"かきくけこ"さしすせそ"""の様に記述でき、これはあいうえお"かきくけこ"さしすせそ
を表す。文字列中に3個の二重引用符を含める場合は""""たちつてと"""なにぬねの""""などと書ける。
複数行の場合において開始を示す二重引用符の直後は、空白または改行のみが受け付けられ、次の行が実際の一行目となる。複数行の生文字列の行はインデントする事ができ、文字列の終了を示す二重引用符のインデント位置と同等の空白文字とタブ文字が全ての行から削除される。その為、終了を示す二重引用符は、最終行の次の行にインデントと伴に置かなければならず、途中の行をこのインデント位置より浅くするとコンパイルエラーになる[b 12]。
複数行の生文字列の記述例は次の通り。
string logMsg = """
原因不明のエラーが発生しました。
詳細はログファイル "C:\Logs\exception.log" を確認してください。
""";
開始を示す二重引用符の直前に任意の数の$を置く事で、補間文字列の機能を用いる事もできる。式を埋め込むには$と同数の半角波括弧({と})で括らなければならない。$より少ない数で連続した波括弧は普通の文字として扱われ、$より多い数で連続させるとコンパイルエラーになる[b 12]。
属性の型が型引数を持てる様になった。
// 属性
[AttributeUsage(AttributeTargets.Class, AllowMultiple = true, Inherited = true)]
public class ConverterContractAttribute<TFrom, TTo> : Attribute { }
// 使用例
[ConverterContract<byte, string>()]
[ConverterContract<sbyte, string>()]
[ConverterContract<short, string>()]
[ConverterContract<ushort, string>()]
[ConverterContract<int, string>()]
[ConverterContract<uint, string>()]
[ConverterContract<long, string>()]
[ConverterContract<ulong, string>()]
public class IntToStringConverter
{
// ...
}
リストや配列に対するパターンマッチが可能になった[a 47][b 13]。
int[] nums = new[] { 0, 1, 2, 3, 4, 5 };
if (nums is [ 0, 1, 2, .. ]) {
Console.WriteLine("配列は 0, 1, 2 から始まります。");
} else {
Console.WriteLine("配列は 0, 1, 2 から始まりません。");
}
また、Span<char>やReadOnlySpan<char>に対して文字列を用いたパターンマッチが可能になった。
bool CheckSignature(ReadOnlySpan<char> sig)
=> sig is "HOGE";
型引数に「数値型または数値型に類似している型」である事を示す制約を付け加える機能が導入された[a 48][b 14]。また、それに呼応して下記の変更が行われた。
>>>演算子)が追加された。int型以外の型を指定できる様になった。checked演算子のオーバーロードができる様になった。static abstractキーワード(静的抽象)とstatic virtualキーワード(静的仮想)を指定できる様になった[a 49][a 50]。ジェネリック型数値演算を用いた一例を下記に示す[a 51][a 52]。
// 大抵の演算子インターフェイスは System.Numerics 内に実装されている。
using System.Numerics;
// 任意の型に対して加算を行う事ができる関数。
static T MyAdd<T>(T value1, T value2)
where T: IAdditionOperators<T, T, T> // 加算が可能な型のみを受け付ける制約。
=> value1 + value2; // + 演算子を使う事ができる。
// 上記の関数定義のみで、下記の様に加算演算が定義された型であれば、任意の型で呼び出す事ができる。
int a = MyAdd( 123, 456); // 結果:579
ulong b = MyAdd(111UL, 222UL); // 結果:333
double c = MyAdd( 1.5D, 2.1D); // 結果:3.6
nameofのスコープ拡張IntPtrに別名 nint、UIntPtrに別名 nuintが付いたrefフィールドscoped ref変数C# 12.0で追加された仕様は以下の通り[a 18][b 7]。
レコード型(record)以外のクラス(class)と構造体(struct)でプライマリコンストラクターが使えるようになった。
class Example(string message)
{
public string Message { get; } = message;
}
配列、コレクション、Span<T>などの初期化の記法が共通の記法([])で書けるようになった。
// Create an array:
int[] a = [1, 2, 3, 4, 5, 6, 7, 8];
// Create a list:
List<string> b = ["one", "two", "three"];
// Create a span
Span<char> c = ['a', 'b', 'c', 'd', 'e', 'f', 'h', 'i'];
コレクション式で複数のコレクションをインライン展開できる新しい演算子(..)が追加された。
int[] row0 = [1, 2, 3];
int[] row1 = [4, 5, 6];
int[] row2 = [7, 8, 9];
// 1, 2, 3, 4, 5, 6, 7, 8, 9,
int[] single = [.. row0, .. row1, .. row2];
ref readonlyパラメーターC# 13.0で追加された仕様は以下の通り[a 22][b 8]。
エスケープ文字[注釈 7]を表すエスケープシーケンスとして\eが追加された。これに従って\x1bの使用は非推奨となった。
オブジェクト初期化子においても^演算子を用いたアクセスが可能となった。これにより、初期化子内でも配列やリストなどの末尾から値へアクセスできる。
params コレクションコレクション式に対応している型であれば、引数にparams修飾子を付けられる様になった[b 15]。
// 関数定義
void Print(string format, params IEnumerable<object> args)
{
/* ... 任意の実装 ... */
// 例えば
Console.WriteLine(format, args.ToArray());
}
// 呼び出し
int a = 2, b = 3;
Print("{0} + {1} = {2}", a, b, a + b);
プロパティとインデクサにもpartial修飾子の指定が可能となった[a 53]。
public partial bool IsThisPartialProperty { get; }
public partial char this[int index] { get; }
Lock クラスに対する lock任意のオブジェクトで排他制御される問題への対策として、lock文専用のLockクラスが用意された[b 16]。以下の様に使う。
var lockObj = new Lock();
lock (lockObj) {
// 排他制御されるコード
}
// このコードは、コンパイラによって次の形に展開される:
using (lockObj.EnterScope()) {
// 排他制御されるコード
}
ref 構造体のインターフェイス実装OverloadResolutionPriority 属性(オーバーロードの解決優先度を変更できる)ref/unsafeC# 14.0で追加された仕様は以下の通り[a 25][b 9]。
新たに extension ブロックが導入され、拡張プロパティと拡張インデクサーを実装できる様になった[a 54][a 55]。この機能は、拡張メンバー[a 54](英: extension members[a 56])または拡張宣言[a 57](英: extension declarations[a 58])などと呼称される。特定の型に対してメンバーを外部の型から後付する事ができる。型引数を受け取るには、extension キーワードの後ろに <T> と記述する。また、動的メンバーだけではなく静的メンバーを追加する事もできる。
整数型に新たなプロパティを追加するコードを以下に示す。
static class Some
{
extension(int arg)
{
public int Twice => arg << 1;
public int Half => arg >> 1;
}
}
field キーワードプロパティのアクセサー内で field キーワードを用いる事でバッキングフィールドを自動生成できる[a 59][a 60]。従ってプロパティ専用の変数を新たに定義する必要は無い。既に field という名称の変数が存在する場合、代わりに @field[注釈 8] または this.field[注釈 9] と記述しなければならない。
get アクセサーのみで用いる場合は以下の様に記述できる。
class Some
{
public object? Data { get => field ?? new(); set; }
}
対して、set アクセサーのみで用いる場合は以下の様に記述できる。
class Some
{
public int Number { get; set => value = field + 1; }
}
両方のアクセサーで同時に用いる事も、set の代わりに init 内で用いる事も、従来通り get; set; と記述する事もできる。バッキングフィールドに属性を付与する場合は、プロパティ宣言の直前に [field: AttributeClassName()] と記述する。
null 条件付き割り当てnull 条件演算子を代入演算子の左辺でも用いられる様になった[a 61][a 62]。
例えば、次の様なクラスが定義されているものとする。
class Some
{
public string? Name { get; set; }
}
通常は、if 文を用いて null ではない場合にのみ代入処理が実施される様にしなければならない。
void SetName(Some? obj, string? name)
{
if (obj is not null) {
obj.Name = name;
}
}
新しい演算子によって、変数の検証を略記できる様になった。
void SetName(Some? obj, string? name)
{
obj?.Name = name;
}
複合代入演算子の動作を上書きできる様になった[a 63]。コピーコストの削減が目的である[b 17]。他の演算子と同じ書式で定義できる。
public void operator +=(int arg) { /* ... ここに具体的なコードを書く ... */ }
nameof の拡張(引数無しのジェネリック型にも対応)Span<T> と ReadOnlySpan<T> の変換partial の拡張(部分コンストラクタと部分イベント)C#の言語仕様は標準化団体Ecma Internationalを通じて公開・標準化されており、第三者がマイクロソフトとは無関係にコンパイラや実行環境を実装することができる[1][20]。
ECMA-334 3rd/4th/5th edition によると、C# は「C Sharp(シーシャープ)」と発音し、LATIN CAPITAL LETTER C (U+0043)の後に NUMBER SIGN # (U+0023)と書く[22]。MUSIC SHARP SIGN ♯ (U+266F) ではなく NUMBER SIGN # (U+0023)を採用したのは、フォントやブラウザなどの技術的な制約に加え、ASCIIコードおよび標準的キーボードには前者の記号が存在しないためである。
「#」を接尾辞とする名称は、他の .NET 言語にも使用されており、J#(Javaのマイクロソフトによる実装)、A#(Adaから)、F#(System Fなどから[23])が含まれる。更には、Gtk#(GTK などの GNOME ライブラリの .NET ラッパ)、Cocoa#(Cocoa のラッパ)などのライブラリにも使用されている。そのほか、SharpDevelopなどの「Sharp」を冠する関連ソフトウェアも存在する。
C# という名称の解釈として、「(A-Gで表された)直前の音を半音上げる」という音楽記号の役割に着目し、「C言語を改良したもの」を意味したのではないか、 というものがある[要出典]。これは、C++の名称が「C言語を1つ進めたもの」という意味でつけられたことにも似ている。アンダース・ヘルスバーグは、「C#」が「C++++」(すなわち「C++ をさらに進めたもの」)にみえるのが由来である、と語っている[24][25]。
global using とも呼ばれる。 U+001Bとなる文字。 |
|
|
|---|---|
| アーキテクチャ | |
| 共通言語基盤 | |
| 言語 |
|
| パッケージマネージャ | |
| 関連技術 |
|
| その他のCLI実装 |
|
| 組織 | |
| 開発環境 |
|
| その他 |
|
| |
|
|
ISO標準
|
|
|---|---|
| 国際標準一覧 · ローマ字表記国際規格一覧 · 国際電気標準会議が定める国際標準一覧 |
|
| 1から 10000まで |
|
| 10001から 20000まで |
|
| 20001以上 |
|
| 組織 | |
| 関連項目: ISOで始まる記事一覧 | |
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/10/21 23:59 UTC 版)
|
C++のロゴ
|
|
| パラダイム | 手続き型プログラミング、データ抽象化、オブジェクト指向プログラミング、ジェネリックプログラミング[1] |
|---|---|
| 登場時期 | 1983年 |
| 開発者 | ビャーネ・ストロヴストルップ |
| 最新リリース | ISO/IEC 14882:2024/ 2024年10月19日 |
| 評価版リリース | ISO/IEC 14882:2026 (予定) / 2024年10月16日 |
| 型付け | nominative, 安全でない強い静的型付け |
| 主な処理系 | GCC、Clang、Microsoft Visual C++、Intel C++ Compiler、C++ Builder |
| 影響を受けた言語 | C言語、Simula、ALGOL 68、CLU、ML、Ada |
| 影響を与えた言語 | Java、Rust、C#、C++/CLI、D言語、PHP |
| ウェブサイト | isocpp |
| 拡張子 | .C、 .cc、 .cpp、 .cxx、 .c++、 .h |
C++(シープラスプラス)は、汎用プログラミング言語のひとつである。派生元であるC言語の機能や特徴を継承しつつ、表現力と効率性の向上のために、手続き型プログラミング・データ抽象・オブジェクト指向プログラミング・ジェネリックプログラミングといった複数のプログラミングパラダイムが組み合わされている[1]。C言語のようにハードウェアを直接扱うような下位層向けの低水準言語としても、複雑なアプリケーションソフトウェアを開発するための上位層向け高水準言語としても使用可能である。アセンブリ言語以外の低水準言語を必要としないこと、使わない機能に時間的・空間的コストを必要としないことが、言語設計の重要な原則となっている[2][3]。
C++は、1983年にAT&Tベル研究所の計算機科学者ビャーネ・ストロヴストルップによって公開された。また様々なプラットフォームでその開発環境が導入された。1998年からISOとIECの共同で言語仕様とテンプレートライブラリの標準化が行われるようになり、その後2003年、2011年、2014年、2017年、2020年、2023年に標準規格が改訂されている。2025年時点での最新規格は「ISO/IEC 14882:2024」通称「C++23」[4]。
ストロヴストルップはプログラミング言語C with Classes(クラス付きのC言語)の開発を1979年に開始した。彼は大規模なソフトウェアの開発に有用な特徴をSimulaが備えていることに気がついたが、Simulaは実行速度が遅く実用的ではなかった。一方でBCPLは実行速度こそ速かったものの、大規模なソフトウェア開発を念頭に置いた場合にあまりにも低級だった。
これらの事情を鑑みて、ストロヴストルップは当時既に汎用的な言語だったC言語にSimulaの特徴を取り入れることを試みた。この取り組みにあたってはALGOL68やAda、CLU、ML等の言語の影響も受けている。最初はクラスと派生クラス、型検査機構の強化、インライン関数、デフォルト引数の機能を、Cfrontを介してC言語に追加した。1985年10月に最初の商用リリースがなされた[5]。
1983年にはC with ClassesからC++に名称を変更した。この際に、仮想関数と、関数と演算子の多重定義、参照型、const型、ユーザー制御可能な自由領域メモリ制御、型検査機構の改良、BCPL形式の(「//」による)行単位のコメントなどの機能が追加された。1985年には『The C++ Programming Language』の初版が出版された(邦訳『プログラミング言語C++』1988年))。この時点では公式な標準が策定されていなかったために、この本が事実上のリファレンスとなった。1989年C++のバージョン2.0として、多重継承と抽象クラス、静的メンバ関数、constメンバ関数、protectedメンバ等の機能が追加されたものがリリースされた。1990年に『The Annotated C++ Reference Manual (ARM)』[6](邦訳『注解C++リファレンスマニュアル』[7])が出版され、将来の標準化の土台となるものを提供した。後に追加された機能にはテンプレートと例外処理、名前空間、新形式のキャスト、ブール型が含まれた。
ARMが事実上の標準として使われた時代が続いたが、標準化が進んだ。C++言語の最初の標準は1998年にISO/IEC 14882:1998として承認された。2003年の改訂版を経て、2011年にメジャーアップデートとして制定されたのがISO/IEC 14882:2011、通称「C++11」である。このバージョンは、元々、非公式に「C++0x」と呼ばれていた。2000年代中に制定され、正式に「C++09」と呼称されることを見越した仮称だったが、2000年代中には実現しなかった。2011年8月10日まで続いた最終国際投票で C++0x は全会一致で承認された。これにより C++0x と呼ばれてきた C++ の次期改正案はついに国際標準になり、C++11と呼べるようになった。
C++言語の進化に伴い、標準ライブラリもまた進化していった。C++標準ライブラリに最初に追加されたのは、従来のC言語の printf() や scanf() といった関数を置き換えるストリームI/Oライブラリである。また、C++98における標準ライブラリへの追加で最も重要なものはStandard Template Library (STL) である。C++11では、正規表現による検索・置換や複数スレッドでの同時実行、ハッシュテーブル・ハッシュセットの追加などさらなる拡充が続いている。
| 規格発行日 | C++ 国際規格 | 非公式名称 | 対応する日本工業規格 |
|---|---|---|---|
| 1998年9月1日 | ISO/IEC 14882:1998[8] | C++98 | ― |
| 2003年10月16日 | ISO/IEC 14882:2003[9] | C++03 | JIS X 3014:2003 |
| 2007年11月15日 | ISO/IEC TR 19768:2007[10] | C++TR1 | ― |
| 2011年9月1日 | ISO/IEC 14882:2011[11] | C++11 | ― |
| 2014年12月15日 | ISO/IEC 14882:2014[12] | C++14 | ― |
| 2017年11月30日[13] | ISO/IEC 14882:2017[14] | C++17 | ― |
| 2020年12月15日 | ISO/IEC 14882:2020[15] | C++20 | ― |
| 2024年10月19日 | ISO/IEC 14882:2024[4] | C++23 | ― |
長年にわたる作業の後、ANSIとISOの合同委員会はプログラミング言語C++を1998年に標準化した (ISO/IEC 14882:1998)。1998年の標準の公式なリリースから数年間にわたって委員会は不具合の報告を続け、2003年に改訂版を出版した。2003年12月に制定された日本工業規格(現:日本産業規格)JIS X 3014:2003「プログラム言語C++」(日本産業標準調査会、経済産業省)は、ISO/IEC 14882:2003 (E) の日本語訳である。
2007年11月15日、C++ Technical Report 1 (TR1) という技術報告書(テクニカルレポート)がリリースされた。これは規格の公式な一部ではなかったが、次の版のC++に含まれると期待される、標準ライブラリへの数多くの拡張を与えた。TR1の内容は、多少の修正を加えてC++11に取り込まれている。
2011年9月1日、C++98以来初の大きな改訂となるISO/IEC 14882:2011が発行された。
2014年8月18日、ISO/IEC 14882:2014 (C++14) が投票で承認され[16]、同年12月15日に公式に発行された。
2017年11月30日[13]、ISO/IEC 14882:2017 (C++17) が公式に発行された。
2020年9月4日、ISO/IEC 14882:2020 (C++20) が投票で承認され[17][18]、同年12月15日、ISO/IEC 14882:2020 (C++20)に公式に発行された[19]。
2023年2月、ISO/IEC 14882:2023 (C++23)の技術仕様がISO C++ 規格会議にてまとまり[20]、2024年10月19日に発行された[4]。2019年末から始まったCovid-19の世界的流行により、開発者同士の対面によるミーティングの開催を図ることが難しくなった[21][22][23]ことから、C++23の仕様策定は難航した。
Boost C++ライブラリを開発しているBoostコミュニティはC++の方向性の決定に大きく貢献し、さらにC++標準化委員会へ改良すべき点などを意見している。2006年当時はマルチパラダイムプログラミングをより自然に行えるようにすることに力が注がれており、C++の関数型プログラミングやメタプログラミングの可能性を模索していた。
C++という名称はRick Mascittiの功績で、最初に使用されたのは1983年の12月である[要出典]。初期の研究期間では、開発中の言語は「C with Classes」と呼ばれていた。最終名は、変数の値を一つ加算する、C言語の++(インクリメント)演算子からの派生である。また一般的な命名規則での「+」の使用は、機能強化されたコンピュータプログラムを意味する。ストロヴストルップによれば「この名前は、C言語からの変更の革新的な本質を示している」ということである。C+は、より初期の無関係なプログラミング言語の名前である[要出典]。
ストロヴストルップは著書『The C++ Programming Language』の前文で名前の起源を語り、ジョージ・オーウェルの小説『1984年』の付録から「C++」が連想されるかもしれないと付け加えている。ニュースピークという架空の言語の解説に宛てられた3つの章の中に、科学技術に関する専門用語とジャーゴンの解説に宛てられた「C vocabulary」という章がある。ニュースピークで「ダブルプラス」は最上級の修飾語である。ゆえにニュースピークで「C++」は「最も極端な専門用語またはジャーゴン」という意味になるだろう。
1992年、Rick Mascittiは名前について非公式に質問されると、彼はおふざけのつもりで命名したという旨の回答をした。彼はこの言語の正式な名称になるとは夢にも思っていなかった[要出典]。
ビャーネ・ストロヴストルップは著書『C++の設計と進化(1994)』でC++を設計する際に用いたルールを述べている。
C++のコンパイラがどのようにコードを出力しメモリのレイアウトを決めるのかということについては『Inside the C++ Object Model』(Lippman, 1996)に記載されている。ただしコンパイラが出力するコードの仕様はコンパイラ制作者の裁量に任されている。
1998年に施行されたANSI/ISO C++ 規格は言語仕様とライブラリの2つのパートで構成される。ライブラリ規格の大半はStandard Template Library (STL) とC言語の標準ライブラリの改良版についての内容である。標準規格以外にも様々なライブラリが数多く存在し、リンカを使用することにより、C言語/FORTRAN/Pascal/BASICのような言語を用いて作成されたライブラリを利用できる。規格外のライブラリが利用できるかどうかはコンパイラに依存する。
C++標準ライブラリはC++向けに若干の最適化が施されたC言語標準ライブラリを含んでいる。C++標準ライブラリの大部分はSTLである。 コンテナ(可変長配列やリストなど)、コンテナを配列のように扱えるようにするイテレータ、検索やソートを行うアルゴリズムといった有用なツールが提供されている。さらにmapやmultimapのような連想配列や、setやmultisetのようなソート済みコンテナも提供され、これらは全てインターフェイスに互換性がある。テンプレートを用いることにより、あらゆるコンテナ(またはイテレータで定義したシーケンス)に適用できる汎用的なアルゴリズムを記述できる。C言語と同様にライブラリの機能には#include ディレクティブを使ってヘッダファイルを読み込むことによってアクセスする。C++には69本の標準ヘッダファイルがあるが、このうち19本については非推奨となっている。
STLは標準規格に採用される前は、ヒューレット・パッカードの(一時はシリコングラフィックスの)商用ライブラリだった。STLは標準規格の単なる一部分に過ぎず規格書にSTLという表記は見られないが、入出力ストリーム、国際化、デバッグ機能、およびC言語標準ライブラリ等の、STL以外の部分と区別するために、今でも多くの人がSTLという用語を使っている。
大半のC++コンパイラはSTLを含むC++標準ライブラリの実装を提供している。STLPortのようなコンパイラ非依存のSTLも存在する。様々な目的でC++標準ライブラリを独自に実装しているプロジェクトは他にもある。
C++の標準ライブラリは大きく次のように分けられる。多種多様な実行環境が存在することを考慮して、GUIに関するライブラリは標準に含まれていない。
以下に、C++で広く使われていると思われる[独自研究?]ライブラリを挙げる。
C言語に、オブジェクト指向プログラミングをはじめとする様々なプログラミングパラダイムをサポートするための改良が加えられたものといえる。ただし、他のプログラミング言語と違い、旧来のCと同様に手続き型言語としても扱えるという特徴がある。また、C言語と比べて型チェックが厳しくなっており、型安全性が向上している。このことから、C++をbetter Cというふうに呼ぶことがある。すなわち、基本的にC言語に対して上位互換性がある。初期のC++はCへのトランスレータとして実装され、C++プログラムを一旦Cプログラムに変換してからコンパイルしていた。
ただし、C++という名称が定まった当初の時期から、C言語とC++との間には厳密な互換性はない[24][25]。当時、Cとの互換性について議論の末、「C++とANSI Cの間には不正当な非互換性はない」という合意が形成されることとなった。そのため、正当な非互換性を巡って多くの議論が発生した[26]。ただし、まだANSIによるC言語の標準規格も策定途中の時期である。
その後、先祖であるC言語のANSIによる標準規格制定時には、関数のプロトタイプ宣言やconst修飾など、C++の機能がC言語に取り入れられることにもなった。C99の出現により、//コメントなどのC++で使われていた便利な機能が加わってCとC++の互換性が高まる一方、別々に審議し、別の時期に発行していることと、開発対象が必ずしも同じでないために利害関係者が異なることによる違いもある[要出典]。
C++はCにクラスのサポートを追加しただけでなく、さらに次のような多種多様な機能を持っており、言語仕様は大変複雑である。言語処理系すなわちコンパイラの実装も、Cなどと比べて難易度が非常に高い。
ここから、よりオブジェクト指向を強化し、「なんでもあり」ではない代わりにシンプルで分かりやすくスマートな設計を目指した新たな言語(JavaやD言語など)が作られることとなった。

|
この節のサンプルは編集しないでください。詳細は編集コメントを参照してください。
|
C++はC言語およびそのプリプロセッサの構文をほぼ継承している。以下のサンプルはビャーネ・ストロヴストルップの書籍「The C++ Programming Language, 4th Edition」(ISBN 978-0321563842) の「2.2.1 Hello, World!」に記載されている標準C++ライブラリのストリーム機能を用いて標準出力に出力するHello worldプログラムである[27][※ 1]。
#include <iostream>
int main()
{
std::cout << "Hello, World!\n";
}
書籍でも明記されているが、main()関数で意図的に返り値を返さない手法が使用されている。
C++には、四則演算、ビット演算、論理演算、比較演算、メンバーアクセスなどの30を超える演算子がある[28]。メンバーアクセス演算子 (.と.*) のような一部の例外はあるが、大半の演算子はユーザー定義によるオーバーロードが可能である。オーバーロード可能な演算子が豊富に揃えられているため、C++を一種のドメイン固有言語として利用できる。またオーバーロード可能な演算子はスマートポインタや関数オブジェクトのような組み込み型の機能を模倣したユーザー定義クラスの実装や、テンプレートメタプログラミングのような先進的な実装テクニックに欠かせないものとなっている。演算子をオーバーロードしても演算の優先順位は変化せず、また演算子のオペランドの数も変化しない。ただし指定したオペランドが無視される可能性はある。
C++には、ジェネリックプログラミングを実現する機能としてテンプレートが存在する。テンプレートにできる対象は、関数とクラスである。C++14以降では変数もテンプレートの対象となった。テンプレートはコード中の型および定数をパラメータ化できる。テンプレートのパラメータ(テンプレート仮引数)に、型、コンパイル時定数またはその他のテンプレート(テンプレート実引数)を与えることで、テンプレートはコンパイル時にインスタンス化(実体化・具現化などとも)される。コンパイラは関数やクラスをインスタンス化するために、テンプレート仮引数をテンプレート実引数に置き換える。テンプレートはジェネリックプログラミング、テンプレートメタプログラミング、コード最適化などのために利用される強力なツールであるが、一定のコストを伴う。各テンプレートのインスタンスはテンプレート仮引数毎にテンプレートコードのコピーを生成するためコードサイズが肥大化する。これはコンパイル時に実型引数の情報を削除することで単一の型インスタンスを生成するランタイム型のジェネリクスを実装したJavaなどの言語とは対照的である。なお、C# (.NET Framework) は実行時コンパイラにより実型引数の情報を削除することなく複数の型インスタンスを生成する方式を採用しており、C++とJavaの中間的なアプローチとなっている。
テンプレートとプリプロセッサマクロはいずれもコンパイル時に処理される言語機能であり、静的な条件に基づいたコンパイルが行われるが、テンプレートは字句の置き換えに限定されない。テンプレートはC++の構文と型を解析し、厳密な型チェックに基づいた高度なプログラムの流れの制御ができる。マクロは条件コンパイルに利用できるが、新しい型の生成、再帰的定義、型の評価などは行えないため、コンパイル前のテキストの置き換えや追加・削除といった用途に限定される。つまりマクロは事前に定義されたシンボルに基づいてコンパイルの流れを制御できるものの、テンプレートとは異なり独立して新しいシンボルを生成することはできない。テンプレートは静的な多態(下記参照)とジェネリックプログラミングのためのツールである。
C++のテンプレートはコンパイル時におけるチューリング完全なメカニズムである。これはテンプレートメタプログラミングを用いて実行する前にコンピュータが計算可能なあらゆる処理を表現できることを意味している。
概略すれば、テンプレートはコードの記述に本来必要な型や定数を明確にすることなく抽象的な記述ができる、パラメータ化された関数またはクラスである。テンプレート仮引数に実引数を与えてインスタンス化した結果は、テンプレート仮引数に指定した型に特化した形で記述されたコードと全く等価になる。これによりテンプレートは、汎用的かつおおまかに記述された関数およびクラス(テンプレート)と、特定の型に特化した実装(インスタンス化されたテンプレート)の依存関係を解消し、パフォーマンスを犠牲にすることなく抽象化できる手段を提供する。
C++はC言語にオブジェクト指向プログラミングをサポートするための改良を加えたものといえる。C++のクラスには、オブジェクト指向言語で一般的な抽象化、カプセル化、継承、多態の4つの機能がある。オブジェクトは実行時に生成されるクラスの実体である。クラスは実行時に生成される様々なオブジェクトのひな形と考えることができる。
なお、C++はSmalltalkなどに見られるメッセージ転送の概念によるオブジェクト指向を採用していない。
カプセル化とは、データ構造を保証し、演算子が意図したとおりに動作し、クラスの利用者が直感的に使い方を理解できるようにするためにデータを隠蔽することである。クラスや関数はC++の基礎的なカプセル化のメカニズムである。クラスのメンバはpublic、protected、privateのいずれかとして宣言され明示的にカプセル化できる。publicなメンバはどの関数からでもアクセスできる。privateなメンバはクラスのメンバ関数から、またはクラスが明示的にアクセス権を与えたフレンド関数からアクセスできる。protectedなメンバはクラスのメンバおよびフレンド関数に加えてその派生クラスのメンバからもアクセスできる。
オブジェクト指向では原則としてクラスのメンバ変数にアクセスする全ての関数はクラスの中にカプセル化されなければならない。C++ではメンバ関数およびフレンド関数によりこれをサポートするが、強制はされない。プログラマはメンバ変数の一部または全体をpublicとして定義でき、型とは無関係な変数をpublicな要素として定義できる。このことからC++はオブジェクト指向だけでなく、モジュール化のような機能分割のパラダイムもサポートしているといえる。
一般的には、全てのデータをprivateまたはprotectedにして、クラスのユーザに必要最小限の関数のみをpublicとして公開することがよい習慣であると考えられている。このようにしてデータの実装の詳細を隠蔽することにより、設計者はインターフェイスを変更することなく後日実装を根本から変更できる[29] [30]。
継承を使うと他のクラスの資産を流用できる。基底クラスからの継承はpublic、protected、privateのいずれかとして宣言する。このアクセス指定子により、派生クラスや全く無関係なクラスが基底クラスのpublicおよびprotectedメンバにアクセスできるかどうかを決定できる。普通はpublic継承のみがいわゆる派生に対応する。残りの二つの継承方法はあまり利用されない。アクセス指定子を省略した場合、構造体はpublic継承になるのに対し、クラスではprivate継承になる。基底クラスをvirtualとして宣言することもできる。これは仮想継承と呼ばれる。仮想継承は基底クラスのオブジェクトが一つだけ存在することを保証するものであり、多重継承の曖昧さの問題を避けることができる。
多重継承はC++の中でもしばしば問題になる機能である。多重継承では複数の基底クラスから一つのクラスを派生できる。これにより継承関係が複雑になる。例えばFlyingCatクラスはCatクラスとFlyingMammalクラスから派生できる。JavaやC#では、基底クラスの数を一つに制限する一方で、複数のインターフェイスを実装でき、これにより制約はあるものの多重継承に近い機能を実現できる(実装の多重継承ではなく型の多重継承)。インターフェイスはクラスと異なり抽象メソッド(純粋仮想関数)を宣言できるのみであり、関数の実装やフィールド(メンバ変数)は定義できない。JavaとC#のインターフェイスは、C++の抽象基底クラスと呼ばれる純粋仮想関数宣言のみを持つクラスに相当する。JavaやC#の継承モデルを好むプログラマは、C++において実装の多重継承は使わず、実装の継承は単一継承に絞り、抽象基底クラスによる型の多重継承のみを使うポリシーを採用することもできる。
多態 (ポリモーフィズム) は様々な場面で多用されている機能である。多態により、状況や文脈に応じてオブジェクトに異なる振る舞いをさせることができる。逆に言うと、オブジェクト自身が振る舞いを決定することができる。
C++は静的な多態と動的な多態の両方をサポートする。コンパイル時に解決される静的な多態は柔軟性に劣るもののパフォーマンス面で有利である。一方、実行時に解決される動的な多態は柔軟性に優れているもののパフォーマンス面で不利である。
関数のオーバーロードは名称が同じ複数の関数を宣言できる機能である。ただし引数は異なっていなければならない。個々の関数は引数の数や型の順序で区別される。同名の関数はコードの文脈によってどの関数が呼ばれるのかが決まる。関数の戻り値の型で区別することはできない。
関数を宣言する際にプログラマはデフォルト引数を指定できる。関数を呼び出すときに引数を省略した場合はデフォルト引数が適用される。関数を呼び出すときに宣言よりも引数の数が少ない場合は、左から右の順で引数の型が比較され、後半部分にデフォルト引数が適用される。たいていの場合は一つの関数にデフォルト引数を指定するよりも、引数の数が異なる関数をオーバーロードする方が望ましい。
C++のテンプレートでは、より洗練された汎用的な多態を実現できる。特にCuriously Recurring Template Patternにより仮想関数のオーバーライドをシミュレートした静的な多態を実装できる。C++のテンプレートは型安全かつチューリング完全であるため、テンプレートメタプログラミングによりコンパイラに条件文を再帰的に解決させて実行コードを生成させることにも利用できる。
基底クラスへのポインタおよび参照は、正確に型が一致するオブジェクトだけでなく、その派生クラスのオブジェクトを指すことができる(リスコフの置換原則)。これにより、複数の異なる派生型を、同一の基底型で統一的に扱うことが可能となる。また、基底型へのポインタの配列やコンテナは、複数の異なる派生型へのポインタを保持できる。派生オブジェクトから基底オブジェクトへの変換(アップキャスト)では、リスコフの置換原則により、明示的なキャストは必要ない。
dynamic_castは基底オブジェクトから派生オブジェクトへの変換(ダウンキャスト)を実行時に安全に行うための演算子である。この機能は実行時型情報 (RTTI) に依存している。あるオブジェクトが特定の派生型のオブジェクトであることがあらかじめ分かっている場合はstatic_cast演算子でキャストすることもできる。static_castは純粋にコンパイル時に解決されるため動作が速く、またRTTIを必要としない。また、static_castは従来のC言語形式のキャスト構文と違い継承階層のナビゲーションをサポートするため、多重継承した場合もメモリレイアウトを考慮したダウンキャストを実行することができる。ただし、static_castでは多重継承において継承関係を持たない基底型同士のキャスト(クロスキャスト)を実行することはできず、dynamic_castを用いる必要がある。とはいえ、ダウンキャストやクロスキャストが必要となる場合、通例そのプログラムの設計に問題があることが多く、本来は仮想関数のオーバーライドによる多態を用いるべきである。
クラスのメンバー関数をvirtualキーワードで修飾することにより、派生クラスでオーバーライド(再定義)することが可能な仮想関数 (virtual function) となる。仮想関数は「メソッド」と呼ばれることもある[31]。派生クラスにて、基底クラスの仮想関数と名前および引数の数や型の順序が同じ関数を定義することでオーバーライドする(C++11以降では、overrideキーワードにより修飾することでオーバーライドを明示することもできる)。基底クラスの仮想関数を派生クラスでオーバーライドした場合、実際に呼び出される関数はオブジェクトの型によって決定される。基底クラスのポインタのみが与えられた場合、コンパイラはオブジェクトの型をコンパイル時に特定できず正しい関数を呼び出せないため、実行時にこれを特定する。これをダイナミックディスパッチと呼ぶ。仮想関数により、オブジェクトに割り当てられた実際の型に従って、最上位の派生クラスで実装した関数が呼び出される。一般的なC++コンパイラは仮想関数テーブルを用いる。オブジェクトの型が判明している場合はスコープ解決演算子を利用して仮想関数テーブルを使わないようにバイパスすることもできるが、一般的には実行時に仮想関数の呼び出しを解決するのが普通である。
通常のメンバー関数に加え、オーバーロードした演算子やデストラクタも仮想関数にできる。原則的にはクラスが仮想関数を持つ場合はデストラクタも仮想関数にすべきである。コンストラクタやその延長線上にあるコピーコンストラクタはコンパイルされた時点でオブジェクトの型が確定しないため仮想関数にできない。しかし、派生オブジェクトへのポインタが基底オブジェクトへのポインタとして渡された場合に、そのオブジェクトのコピーを作らなければならない場合は問題が生じる。このような場合はclone()関数(またはそれに準じる物)を仮想関数として作成するのが一般的な解決方法である。clone()は派生クラスのコピーを生成して返す。
= 0をメンバー関数宣言の末尾セミコロンの直前に挿入することにより、メンバー関数を純粋仮想関数 (pure virtual function) にできる。純粋仮想関数を持つクラスは純粋仮想クラスと呼ばれ、このクラスからオブジェクトを生成することはできない。このような純粋仮想クラスは基底クラスとしてのみ利用できる。派生クラスは純粋仮称関数を継承するため、派生クラスのオブジェクトを生成したい場合は全ての純粋仮想関数をオーバーライドして実装しなければならない。純粋仮想関数を持つクラスのオブジェクトを生成しようと試みるようなプログラムは行儀が悪い。
型消去 (type erasure) と呼ばれる、テンプレートを活用して動的な(プログラム実行時の)多態性を実現する手法が存在する。この手法はC++の標準ライブラリでもstd::functionやstd::shared_ptrの削除子で採用されている。いずれも、コンストラクタや代入演算子で(一定の条件を満たす)任意のオブジェクトを実引数として渡せるようにすることから多態性を実現している。
C99の制定前、C言語とC++との分かりやすい差異として、// で始まり改行で終わる、単一行コメントの有無があった。
単一行コメントはもともと、C言語の祖先にあたるBCPLに含まれていた仕様である。現在のC++のコンパイラの多くがC言語のコンパイラとしても使えるようになっているのと同様に、C言語が生まれて間もない頃は、C言語に加えB言語やBCPLのコンパイルができるコンパイラが用いられていた。それらコンパイラは、C言語のソースであってもBCPLと同様に単一行コメントが使用できるよう独自の拡張がなされていたため、 BCPLの単一行コメントに慣れ親しんでいたプログラマ達は、C言語でも単一行コメントを使い続けた。その慣習がC++の誕生時まで生き残っていたため、C++では単一行コメントを「復活」させることになった。[独自研究?]
そのためもあって、C言語での仕様外の単一行コメントの使用は半ば常習と化し、[独自研究?]C99によって単一行コメントが正式に規格として組み入れられた。
LALR(1)のような旧式のパースアルゴリズムを用いてC++のパーサを記述することは比較的難しい[32]。その理由の一つはC++の文法がLALRではないことである。このため、コード分析ツールや、高度な修正を行うツール(リファクタリングツールなど)は非常に少ない。この問題を取り扱う方法としてLALR(1)でパースできるように改良されたC++の亜種(SPECS)を利用する方法がある。GLRパーサのようにより強力でシンプルなパーサもあるが処理が遅い。
パースはC++を処理するツールを作成する際の最も難しい問題ではない。このようなツールはコンパイラと同じように識別子の意味を理解しなければならない。従ってC++を処理する実用的なシステムはソースコードをパースするだけでなく、各識別子の定義を正確に適用し(つまりC++の複雑なスコープのルールを正確に取り扱い)、型を正しく特定できなければならない。
いずれにせよC++ソースコード処理ツールが実用的であるためには、GNU GCCやVisual C++で使われているような、様々なC++の方言を取り扱えなければならず、適切な分析処理やソース変換やソース出力などが実装できなければならない。GLRのような先進的なパースアルゴリズムとシンボルテーブルを組み合わせてソースコードを変換する方法を利用すればあらゆるC++ツールを開発できる。
その言語文法の複雑さゆえ、C++規格に準拠したコンパイラを開発するのは一般的に難しい。20世紀末から何年にも渡りC++に部分的に準拠した様々なコンパイラが作られ、テンプレートの部分特殊化などの部分で実装にばらつきがあった。中でも、テンプレートの宣言と実装を分離できるようにするためのexportは問題のキーワードの一つだった。exportを定義したC++98規格がリリースされてから5年後の2003年前半にComeau C/C++が初めてexportを実装した。2004年にBorland C++ Builder Xがexportを実装した。これらのコンパイラはいずれもEDGのフロントエンドをベースにしていた。大半のコンパイラで実装されていないexportは多くのC++関連書籍(例えば"Beginning ANSI C++", Ivor Horton著)にサンプルが記されているが、exportが記載されていることによる問題は特に指摘されていない。GCCをはじめとするその他のコンパイラでは全くサポートしていない。Herb SutterはC++の標準規格からexportを削除することを推奨していたが[33]、C++98では最終的にこれを残す決定がなされた[34]。結局、C++11では実装の少なさ・困難さを理由に削除された。
コンパイラ開発者の裁量で決められる範囲を確保するため、C++標準化委員会は名前修飾や例外処理などの実装に依存する機能の実装方法を決定しないことに決めた。この決定の問題は、コンパイラが異なるとオブジェクトファイルの互換性が保証されない点である。特定の機種やOSでコンパイラの互換性を持たせ、バイナリレベルでのコード再利用性を高めようとするABI[35]のような非標準の規格もあり、一部のコンパイラではこうした準規格を採用している。
2019年現在のメジャーなC++コンパイラ(gcc, Clang, Intel C++ Compiler, Microsoft Visual C++など)の最新版はC++11およびC++14規格にほぼ準拠しており、特にClangは2013年4月時点でC++11の全機能を実装完了した[36][37]。ただしマイナーアップデートとなるC++17を含めると、処理系間でのばらつきは依然として存在する。
C++は基本的にC言語の上位互換であるが、厳密には異なる[38]。C言語で記述された大半のプログラムはC++でコンパイルできるように簡単に修正できるが、C言語では正当でもC++では不正になる部分や、C++とは動作が異なる部分が若干存在する。
例えば、C言語では汎用ポインタvoid*は他の型へのポインタに暗黙的に変換できるが、C++ではキャスト演算子によって変換を明示する必要がある。またC++ではnewやclassといった数多くの新しいキーワードが追加されたが、移植の際に元のC言語のプログラムでそれらが識別子(例えば変数名)として使われていると、問題になる。
C言語の標準規格であるC99やその後継C11ではこうした非互換性の一部が解決されており、//形式のコメントや宣言とコードの混在といったC++の機能がC言語でサポートされている。その一方でC99では、可変長配列、複素数型の組み込み変数、指示初期化子、複合リテラルといった、C++でサポートしていない数多くの新機能が追加された[39]。C99で追加された新機能の一部はC++11に反映され、C++14に対してもC99やC11との互換性を向上される提案が行われた。また、可変長配列や複素数型などのC99に追加された機能の一部はC11でオプションとなった[40][41]。
C++で書かれた関数をC言語で書かれたプログラムから呼び出す、あるいはその逆を行なう場合など、C言語のコードとC++のコードを混在させるためにはCリンケージを利用する必要があり、関数をextern "C"で個別に修飾するか、extern "C" { ... }のブロックの中で宣言しなければならない。また、関数引数や戻り値などのインターフェイスはC言語互換形式に合わせる必要がある。Cリンケージを利用した関数については、C++名前修飾がされず、名前修飾に依存している関数オーバーロード機能は利用できない。
C/C++の相互運用性が確保されていることで、慣れ親しんだC言語標準ライブラリ関数の大半をC++でもそのまま利用し続けることができるということはC++の大きなメリットのひとつである。
std::endlを'\n'に改めている。またmain関数がデフォルトで0を返す件についてはwww.research.att.com及びwww.delorie.com/djgpp/ を参照されたし。このデフォルト仕様はmain関数のみであり他の関数にはない。 |
|
|
|---|---|
| C++の機能 | |
| 標準C++ライブラリ | |
| コンパイラ |
|
| 統合開発環境 | |
| 関連言語 | |
|
ISO標準
|
|
|---|---|
| 国際標準一覧 · ローマ字表記国際規格一覧 · 国際電気標準会議が定める国際標準一覧 |
|
| 1から 10000まで |
|
| 10001から 20000まで |
|
| 20001以上 |
|
| 組織 | |
| 関連項目: ISOで始まる記事一覧 | |
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/10/31 05:09 UTC 版)
| パラダイム | 命令型プログラミング |
|---|---|
| 登場時期 |
|
| 開発者 | サイモン・ペイトン・ジョーンズ、Norman Ramsey |
| 最新リリース | 2.0 / 2005年2月23日[1] |
| 影響を受けた言語 | C言語 |
| ウェブサイト | |
| 拡張子 | c-- |
C--(シーマイナスマイナス)は、人間ではなくコンパイラが生成することを想定したC言語風のプログラミング言語(中間言語)である。Glasgow Haskell Compilerが、複数ある中間言語の一つとして採用している。(なお「C++の反対」として誰でも思いつく名前なので、この記事で述べるもの以外にも同名のものは多数あると思われる[2])
1990年代、マルチプラットフォームのプログラミング言語は、元言語ソースコードをC言語ソースコードへコンパイルして、それをCコンパイラで対象プラットフォームの機械語へコンパイルしていた[3]。C言語コンパイラは多様なプラットフォームをサポートしていたため、C言語を中間言語として採用することは現実的に利にかなった手法である。しかし、C言語は人間が読み書きするプログラミング言語として設計されているため、Haskellコンパイラなどの中間言語としては最適設計ではなかった。例えば、C言語ではガベージコレクションや例外処理は意図的に言語仕様に組み込んでおらず、それらの機能を利用したプログラミング言語でC言語を中間言語とすると、効率良い実現が難しかったりした。
1997年、それらの課題を解決するため、ノーマン・ラムゼーはC--をImplementing Functional LanguagesワークショップでC--: A Portable Assembly Languageのタイトルで、コンパイラが扱うC言語に代わる中間言語として発表した[4]。C--は人間が読み書きするプログラミング言語としての特性より機械が処理する中間言語としての特性を重視し、多種プログラミング言語をフロントエンドに置きうるバックエンド仕様、マルチプラットフォームのマシンコード値型、ガベージコレクション・例外処理などのランタイムインターフェースを提供した。
1999年5月23日、C--バージョン1の言語仕様リファレンスがリリースされた[5]。
2005年2月23日、C--バージョン2の言語仕様リファレンスがリリースされた[6]。
2003年10月6日から2006年10月31日までの間、C--およびQuick C--の開発はアメリカ国立科学財団の支援を受けていた[7]。
C--は、人間が読み書きするためのプログラミング言語としてではなく、マシンが解釈するアセンブリ言語として設計されている。C--コードは極力プラットフォームアーキテクチャに依存せず、直交性・最小性より性能・利便性を重要視した言語仕様である。C--の文法は、C言語の言語仕様に似たプログラミング言語の特徴を持っている[8]。
C--コードをマシンコードにコンパイルする処理系は複数存在する[9]。2018年現在、大半の処理系がソースコードの公開を含めメンテナンスされていない。
(C. から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/11/07 11:33 UTC 版)
|
C言語のロゴ
|
|
| パラダイム | 命令型プログラミング、構造化プログラミング、手続き型プログラミング |
|---|---|
| 登場時期 | 1972年. |
| 開発者 | ベル研究所、デニス・リッチー、米国国家規格協会、国際標準化機構、ケン・トンプソン |
| 最新リリース | ISO/IEC 9899:2024/ 2024年10月31日 |
| 型付け | 弱い静的型付け |
| 主な処理系 | GCC, Clang, Visual C++, Intel C++ Compiler |
| 影響を受けた言語 | ALGOL 68、B言語、アセンブリ言語、FORTRAN、PL/I、CPL、BCPL、ALGOL 60、ALGOL |
| 影響を与えた言語 | awk、csh、C++、Objective-C、Rust、D言語、Java、JavaScript、Limbo |
| プラットフォーム | Microsoft Windows、Unix系 |
| ウェブサイト | |
| 拡張子 | .c, .h |
C言語(シーげんご、英: C programming language)は、1972年にAT&Tベル研究所のデニス・リッチーが主体となって開発した汎用プログラミング言語である。英語圏では「C language」または単に「C」と呼ばれることが多い。日本でも文書や文脈によっては同様に「C」と呼ぶことがある。制御構文などに高水準言語の特徴を持ちながら、ハードウェア寄りの記述も可能な低水準言語の特徴も併せ持つ。基幹系システムや、動作環境の資源制約が厳しい、あるいは実行速度性能が要求されるソフトウェアの開発に用いられることが多い。後発のC++やJava、C#など、「C系」と呼ばれる派生言語の始祖でもある[注釈 1]。
ANSI、ISO、またJISにより言語仕様が標準規格化されている。
|
この節に雑多な内容が羅列されています。
|
Cには他のプログラミング言語と比較して、特筆すべきいくつかの特徴がある。
上記のように、利点でもあり、同時に欠点にもなる特徴を備えている。
もともとUNIXおよびCコンパイラの移植性を高めるために開発されてきた経緯から、オペレーティングシステム(OS)のカーネルおよびコンパイラ向けの低水準な記述ができるなど、ハードウェアをある程度抽象化しつつも、必要に応じて低水準言語と同じことを実現できるようなコンピュータ寄りの言語仕様になっている。そのため、低水準な記述ができる高水準言語と言われたり、高水準言語の顔をした低水準言語(高級アセンブラ[2]、汎用アセンブラ[3])と言われたりすることがある。
Cはアマチュアからプロ技術者まで、プログラマ人口が多く、プログラマのコミュニティが充実している。使用者の多さから、正負の両面含め、Cはプログラミング文化に大きな影響を及ぼしている。また、多目的性と、対応機器の多彩さのため、「コンピュータを使ってやること」は大抵、Cで対応可能である。ただし、Cで効率的かつ安全に記述できるかどうかはまた別の話である。スクリプト言語やコマンドラインシェルを使えば手軽に実現にできるような処理まで、わざわざCで記述する必要はない。また、GUIアプリケーションフレームワークは、Cからは利用できず、統合開発環境と連携する新しいプログラミングツールやプログラミングパラダイムに対応した後発言語でなければ利用できないものもある。
MISRA CやCERT Cというコーディング標準(コーディング規約)を定義して、危険な機能の使用や記述を禁止するという制限を設けることでCを安全に利用するためのガイドラインが運用されている分野もある。特にプログラミングミスが人命に直結する自動車分野などでCを利用するには、このような制約が重要である。
;」で表し、改行文字にも空白にもトークンの区切りとしての意味しか持たせない「フリーフォーマット」という形式を採用している。中括弧{ }によるブロック構造およびスコープをサポートする。goto)を使用する必要はなく、MISRA Cでは当初goto文を禁止していた。main という名前の関数として定義する[注釈 3]。プログラム中で再帰的にmain関数を呼ぶことも可能(C++では不可能[4][5])。フリースタンディング環境では、エントリーポイントと呼ばれるアドレスに置かれたコードをプログラムの開始点とするが、それがmain関数である必要はない。なお再帰呼び出しそのものは、スタックオーバーフローの原因となるため、MISRA Cでは禁止している。int型とみなし、関数の戻り値の型指定がない場合はint型とみなす。ANSI C(C89)ではコンパイル時型検査の強化のために関数プロトタイプの機能が導入されたが、関数の宣言がない場合の戻り値はint型とみなし、引数は未知(任意)とみなす。しかし、このような暗黙の型指定は型安全性を損ない未定義動作を引き起こす危険性があるため、ISO/IEC C:1999(C99)以降では暗黙の型指定に関する仕様が標準規格の文面から削除された。いずれも使用(参照)するより前に適切に宣言する必要がある。ClangやGCCといったC99準拠のコンパイラは、このような暗黙の型指定について、C99モードであってもC89互換の動作を残してはいるものの、非標準の動作であるため警告を出すようになっている。なお、関数宣言において()のように引数を省略すると、引数を未知とする仕様はC99でも残されている。後継言語では完全なプロトタイプ宣言を必須とするか、あるいはプロトタイプ宣言自体を不要としているが、記述によっては先読みが必要になりうる。処理系の簡素化と効率のために、以下のように安全性を犠牲にした仕様が多い。なお、ホスト環境やプログラムの内容によっては、以下に対して脆弱性対策を施したとしても実行速度の低下が無視できる程度であることも多く、言語仕様側の欠点とみなされることも少なくない。
char型の配列を利用する。言語仕様上に特別な扱いはないが、ヌル文字('\0')を終端とする文字列表現を使い、その操作をする標準ライブラリ関数がある。これは実質的にメモリ領域へのポインタアクセスそのものであり、確保されている領域の長さよりも長い文字列を書き込めてしまうために、バッファオーバーランの元凶の1つとなっている。
mallocおよびその類似関数にて提供される。一方、カーネルではメモリ確保の際にスレッドがブロックされるとカーネル内のデータが他のスレッドにより変更され、予期せぬ動作を起こす恐れがあることや、メモリ内容の初期化が必要かどうかによって割当先のページを選択することによりシステムの効率が上がることから、多くの場合POSIXとは異なるAPIを使用している。Linuxカーネルの場合、前者はフラグGFP_KERNELとGFP_ATOMICの使い分け、後者は関数kmalloc(割り当てたメモリの内容は不定)とkzalloc(割り当てたメモリの内容はゼロクリア済)の使い分けにより実装している[7]。C言語のHello worldプログラムは、ホスト環境を前提とするか、フリースタンディング環境を前提とするかで、方向性が異なる。ホスト環境を前提とする場合には、標準入出力の利用により、動作をすぐに確かめることができる。以下では、標準Cライブラリのヘッダstdio.hにて宣言されている、printf関数を利用したものを例示する。
#include <stdio.h>
int main(void)
{
printf("Hello, world!\n");
return 0;
}
上記サンプルソース中の「\n」は、エスケープ文字\によるエスケープシーケンスのひとつであり、改行(ラインフィード)を表す。
main関数は標準的なプログラムエントリーポイントであり、プログラムを開始すると、ランタイムライブラリによるスタートアップ処理が実行された後にこのmain関数が呼ばれる。引数のないバージョン(void)と、コマンドライン引数をポインタ配列として受け取るバージョン(int argc, char* argv[])どちらを使ってもよい[8]。
なお、printf関数は書式文字列とそれに対応する可変個引数を受け取り、書式化された文字列として表示できる高機能な標準出力関数であるが、序盤から例示に使用している入門書もある。
return 0;はmain関数の戻り値としてint型の値0を返している。C99以降では、main関数の戻り値のデータ型がintと互換性があるときは暗黙的に0を返す[8]。従って、C99以降ではreturn 0;を省略しても同じ結果になる。
main関数とprintf関数は、いずれも入門者や初学者にとっては最初の関門となる難解な関数であり、C言語によるプログラミングのハードルを高くしている一因でもある[9][10]。JavaやC#のような後発言語では、文字列の扱いや、可変個引数の扱いがより簡潔で安全になっている。Pythonのようなインタプリタや対話環境上で動作することを前提とした言語では、main関数を定義する必要はない。
C言語は、AT&Tベル研究所のケン・トンプソンが開発したB言語の改良として誕生した(#外部リンクの「The Development of the C Language」参照)。
1972年、トンプソンとUNIXの開発を行っていたデニス・リッチーはB言語を改良し、実行可能な機械語を直接生成するC言語のコンパイラを開発した[11]。後に、UNIXは大部分をC言語によって書き換えられ、C言語のコンパイラ自体も移植性の高い実装のPortable C Compilerに置き換わったこともあり、UNIX上のプログラムはその後にC言語を広く利用するようになった。
ちなみに、「UNIXを開発するためにC言語が作り出された」と言われることがあるが、「The Development of the C Language」によると、これは正しくなく、経緯は以下の通りである。C言語は、当初はあくまでもOS上で動くユーティリティを作成する目的で作り出されたものであり、OSのカーネルを記述するために使われるようになるのは後の展開である。
アセンブリ言語との親和性が高いために、ハードウェアに密着したコーディングがやりやすかったこと、言語仕様が小さいためコンパイラの開発が楽だったこと、小さな資源で動く実行プログラムを作りやすかったこと、UNIX環境での実績があり、後述のK&Rといった解説文書が存在していたことなど、さまざまな要因からC言語は業務開発や情報処理研究での利用者を増やしていった。特にメーカー間でオペレーティングシステムやCPUなどのアーキテクチャが違うUNIX環境では再移植の必要性がしばしば生じて、プログラムをC言語で書いてソースレベル互換[13]を確保することが標準となった。
C言語の開発当初に使われた入力端末はASR-37であったことが知られている[12]。ASR-37は1967年制定の旧ASCII ISO R646-7bitにもとづいており、「{」および「}」の入力を行うことができたが、当時は一般的に使われていた入力端末ではなかった。 当時PDP-11の入力端末として広く使われていたのはASR-33であるが、これは1963年制定の旧ASCIIであるASA X3.4に準拠しており、「{」や「}」の入力を行うことはできなかった[14]。
このことは、ブロック構造に「{」や「}」を用いるC言語(さらに元をたどればB言語)は、当時の一般的な環境では使用不可能であったことを示している。これは、C言語はその誕生当初にあっては一般に広く使われることを想定しておらず、ベル研究所内部で使われることを一義的に考えた言語であったという側面の表れである。
これに対し、PascalやBASIC等の当初から広く使われることを想定した言語では、ブロック構造に記号を用いずにbeginとendをトークンとして用いることや、コメント行を表す際に開始トークンとしてREMという文字列を用いることなど、記号入力に制約がある多くの入力端末に対応できるように配慮されていた。この頃の他の言語やOSで大文字と小文字の区別をしないものが多いのも、当時は大文字しか入力できない環境も少なくなかったことの表れである。
このような事情のため、C言語が普及するのは、ASCII対応端末が一般化した1980年代に入ってからである。
現在、ブロック構造の書式等で、{...}形式のC言語と、begin...end等を使用する他の言語との比較において優劣を論じられることがあるが、開発時の環境等をふまえずに現時点での利便性のみで論じるのは適切ではない場合があることに留意が必要である。
1980年代に普及し始めたパーソナルコンピュータ(PC)は当初、8ビットCPUでROM-BASICを搭載していたものも多く、BASICが普及していたが、1980年代後半以降、16ビットCPUを採用しメモリも増えた(ROM-BASIC非搭載の)PCが主流になりだすと、Turbo CやQuick Cといった2万円程度の比較的安価なコンパイラが存在したこともあり、ユーザーが急増した。8ビットや8086系のPCへの移植は、ポインタなどに制限や拡張を加えることで解決していた。
1990年代中盤には、最初に学ぶプログラミング言語としても主流となった。また、同時期にはゲーム専用機(ゲームコンソール)の性能向上とプログラムの大規模化、マルチプラットフォーム展開を受け、メインの開発言語がアセンブリ言語からC言語に移行した。
1990年代後半 - 2000年代以降は、PCのさらなる性能向上と普及、GUI環境やオブジェクト指向の普及、インターネットおよびウェブブラウザの普及、スマートフォンの普及に伴い、より高水準で開発効率の高い言語やフレームワークを求める開発者が増えたことにより、C++、Visual Basic、Java、C#、Objective-C、PHP、JavaScriptなどが台頭してきた。広く利用されるプログラミング言語の数は増加傾向にあり、相対的にC言語が使われる場面は減りつつある。特にアプリケーションソフトウェアなどの上位層の開発には、C言語よりも記述性に優れるC++、Java、C#などC言語派生の後発言語が利用されることが多くなっている。資源制約の厳しかったゲーム開発においても、ハードウェアの性能向上やミドルウェアの普及により、C++やC#などが使われる場面が増えている。速度性能や省メモリが特に重視されるシステムプログラミングに関しても、伝統的にC/C++の独壇場だったが、新規コードではより安全性の高いRustを導入する事例が現れている[15][16]。
しかし、C言語は比較的移植性に優れた言語であり、個人開発/業務用開発/学術研究開発やプロプライエタリ/オープンソースを問わず、オペレーティングシステムやデバイスドライバーなどの下位層、クロスプラットフォームAPIの外部仕様、C++やJavaなどの高水準言語の処理系および実行環境の実装が困難な小規模の組み込みシステムなどを中心に、2021年現在でも幅広く利用されている。
プログラミング入門者にとっては、Python、JavaScript、Swift、Kotlinなどのように、インタラクティブな対話環境(REPL、インタプリタ)が利用でき、抽象化が進んでおり、煩雑なメモリ管理が不要で、危険な機能を制限した高水準言語のほうが学習・習得しやすいが、コンピュータの動作原理やハードウェア仕様を理解するには、Cのような原始的な言語を用いたほうがかえって分かりやすいケースもある。
米国国家規格協会(ANSI)による標準化が行われるまで、1978年出版のデニス・リッチーとブライアン・カーニハンの共著『The C Programming Language』が実質的なC言語の標準として参照されてきた。この書籍は、著者らのイニシャルを取って「K&R」とも呼ばれている。C言語は発展可能な言語で、K&Rの記述も発展の可能性のある部分は厳密な記述をしておらず、曖昧な部分が存在していた。そのためC言語が普及するとともに、互換性のない処理系が数多く誕生した。
そこで、ISO/IEC JTC1とANSIは協同でC言語の規格の標準化を進め、1989年12月にANSIがANSI X3.159-1989, American National Standard for Information Systems -Programming Language-Cを、1990年12月にISOがINTERNATIONAL STANDARD ISO/IEC 9899:1990(E) Programming Languages-Cを発行した。ISO/IEC規格のほうが章立てを追加しており、その後ANSIもISO/IEC規格にならって章立てを追加した。それぞれC89(ANSI C89)およびISO/IEC C90という通称で呼ぶことがある。
日本では、これを翻訳したものを『JIS X 3010-1993 プログラム言語C』として、1993年10月に制定した。
最大の特徴は、C++と同様の関数プロトタイプ[注釈 4]を導入して引数の型チェックを強化したことと、voidやenumなどの新しい型を導入したことである。一方、「処理系に依存するものとする」に留めた部分も幾つかある(int型のビット幅、char型の符号、ビットフィールドのエンディアン、シフト演算の挙動、構造体などへのパディング等)。
規格では以下の3種類の自由を認めている部分がいくつかある[17]。
これにより、プラットフォームやプロセッサアーキテクチャとの相性による有利不利が生じないような仕様になっている。
8ビット/16ビット/32ビットなど、レジスタ幅(ワードサイズ)の異なるプロセッサ(CPU)に対応・最適化できるようにするため、組み込み型の情報量(大きさ)や内部表現にも処理系の自由を認めている。型のバイト数はsizeof演算子で取得し、各型の最小値・最大値はlimits.hで定義されているマクロ定数で参照することとしている。ただし、1バイトあたりのビット数は規定されていない。sizeof(char) == 1すなわちchar型が1バイトであることは常に保証されるが、8ビット(オクテット)とは限らない。実際のビット数はCHAR_BITマクロ定数で取得できる。とはいえ、現実の多くの処理系ではchar型は8ビットである。また、その他の整数型については、sizeof(int) >= 2、sizeof(int) >= sizeof(short)、sizeof(long) >= sizeof(int)、という大小関係が定められているだけである(符号無し型も同様)。多くの処理系ではshort型のサイズは2バイト(16ビット)であるが、intやlongのサイズはCPUのレジスタ幅などによって決められることが多い。int型、short型、long型で符号を明示しない場合はsignedを付けた符号付き型として扱われる。しかしchar型に関しては、signed(符号付き)にするか、それともunsigned(符号無し)にするかは処理系依存である。char型、signed char型、unsigned char型はそれぞれ異なる型として扱われる。
規格上には、BCPLやC++形式の1行コメント(//…)は無いが、オプションで対応した処理系も多く、gccやClangはGNU拡張-std=gnu89でサポートしている。
GNU Cコンパイラ や Clang では、-std=c89(または-ansiもしくは-std=c90)をつけることにより、GNU拡張を使わないC89規格に準拠したコンパイルを行うことができる[注釈 5]。加えて、-pedanticをつければ診断結果が出る。商用のコンパイラではWatcom Cコンパイラが規格適合の比率が高いと言われていた。現在Open Watcomとして公開している。
C89には、下記の追加の訂正と追加を行った。
1999年12月1日に、ISO/IEC JTC1 SC22 WG14 で規格の改訂を行い、C++の機能のいくつかを取り込むことを含め機能を拡張し、ISO/IEC 9899:1999(E) Programming Language--C(Second Edition)を制定した。この版のC言語の規格を、通称としてC99と呼ぶ。
日本では、日本産業規格 JIS X 3010:2003「プログラム言語C」がある。
主な追加機能:
_Bool型が予約語に追加され、標準ライブラリとしてstdbool.hを追加した。_Complex型や_Imaginary型を予約語に追加し、標準ライブラリとして、complex.hを追加した。long long int型の追加。stdint.h)。//による1行コメント。inlineキーワード)。alloca関数の代替)[18]。C99は下記の訂正がある。
2011年12月8日にISO/IEC 9899:2011(通称・C11)として改訂された。
C11はUnicode文字列(UTF-32、UTF-16、UTF-8の各符号化方式)に標準で対応している。そのほか、type-generic式、C++と同様の無名構造体・無名共用体、排他的アクセスによるファイルオープン方法、quick_exitなどのいくつかの標準関数などを追加した。
また、_Noreturn関数指示子を追加した。_Noreturnは従来処理系ごとに独自に付加していた属性情報(たとえばgccでは__attribute__((__noreturn__)))を標準化したもので、「呼び出し元に戻ることがない」という特殊な関数についてその特性を示すためにある。return文を持たない関数という意味ではなく(規格ではreturn文を持たなくとも、関数の最後の文の実行が終われば制御は呼び出し元に戻る)、_exitやexecveを実行したり、例外、longjmpによる大域ジャンプ[注釈 6]などのために、制御が呼び出し元に戻らないことを明示するためにある。そのような関数は、スタックに戻りアドレスを積む通常の呼び出しではなく、スタックを消費しないジャンプによって実行できる。
C11規格では一部の機能を省略可能とした。即ちコンパイラがC11に合致していても、一部機能は提供しないことがある。コンパイラがどの機能を提供しているかは、テスト用のマクロで判別できる。アラインメント機能や_Atomic型、C言語ネイティブの原始的なスレッド機能などが、C11では省略可能な機能として追加された。また、複素数型と可変長配列はC99では必須機能であったが、C11では省略可能である。
gets関数が廃止された。
2018年にISO/IEC 9899:2018(通称・C17またはC18)として改訂された。仕様の欠陥修正がメインのマイナーアップデートである[19]。
大抵の処理系はC言語とC++双方をサポートしている。C言語とC++の共通部分を明確にし、2つの言語の違いに矛盾が生じないようにすることが課題になっている。
その他にも、OpenGLシェーダー言語であるGLSL、DirectX(Direct3D)シェーダー言語であるHLSL、OpenCLカーネル記述言語であるOpenCL-Cなど、C言語の文法的特徴を取り入れた派生言語やDSLが多数存在する。
gcc -ansi -pedantic -fstrict-aliasing -Wall -Wextra -Wmissing-declarations -Werror test.cとすれば良い(→エイリアシング)。
setjmp.hを参照。 ![]() ウィキメディア・コモンズには、C言語に関するメディアがあります。
ウィキメディア・コモンズには、C言語に関するメディアがあります。
|
|
|
|---|---|
| Cの機能 | |
| 標準Cライブラリの関数 | |
| 標準Cライブラリ | |
| コンパイラ |
|
| 統合開発環境 | |
| 派生言語 | |
| 関連項目 | |
(C. から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/12/11 16:15 UTC 版)
|
|
この記事は検証可能な参考文献や出典が全く示されていないか、不十分です。 (2016年12月)
|
ローマ数字(ローマすうじ)は、数を表す記号の一種である。ラテン文字の一部を用い、例えばアラビア数字における 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 をそれぞれ I, II, III, IV, V, VI, VII, VIII, IX, X のように表記する。I, V, X, L, C, D, Mはそれぞれ 1, 5, 10, 50, 100, 500, 1000 を表す。i, v, x などと小文字で書くこともある。現代の一般的な表記法では、1以上4000未満の数を表すことができる。
ローマ数字のことをギリシャ数字と呼ぶ例が見られるが、これは誤りである。
古代ローマにおいて成立し、中世後期までヨーロッパで一般的に用いられていた表記法。ただしこれを規定する公式な、あるいは広く知られた標準となる表記法は存在していない[注 1]。 16世紀頃からはアラビア数字での表記が一般的になったが、特定の場面においては現代でも用いられている。
十進法に基づいている。 数を10の冪ごとに、つまり 1000の位の量 + 100の位の量 + 10の位の量 + 1の位の量 と分解し、左からこの順番に書き下す。この際、空位の0は書かれることはない。位ごとに異なる記号が用いられるが、記号の組み合わせのパターンは共通である。
| ローマ数字 | I | V | X | L | C | D | M |
|---|---|---|---|---|---|---|---|
| アラビア数字 | 1 | 5 | 10 | 50 | 100 | 500 | 1000 |
それぞれの位の量は更に上記の数字の和に分解され、大きい順に並べて書かれる。5未満は Iの繰り返しで表され、5以上は Vに Iをいくつか加える形で表される。(画線法)
また、小さい数を大きい数の左に書くこともあり、この場合右から左を減ずることを意味する。これを減算則という。
| ローマ数字 | IV | IX | XL | XC | CD | CM |
|---|---|---|---|---|---|---|
| アラビア数字 | 4 | 9 | 40 | 90 | 400 | 900 |
これらの数は減算則を使わず表現することも可能(例:4 を「 IIII」、9を「 VIIII」)だが、通常は減算則を用いて表記する。なお、減算則が用いられるのは4 (40, 400) と9 (90, 900) を短く表記する場合だけであり、それ以外で使うことは通常行われない(例外は#異表記を参照のこと)。つまり、8を「 IIX」と表記したり、位ごとの分離を破って45を「 VL」、999を「 IM」と表記することは基本的でない書き方とされる。
以上を踏まえると、1 から 9 とその 10 倍と 100 倍、および1000、2000、3000は以下のような表記となる。
| ×1 | ×10 | ×100 | ×1000 | |
|---|---|---|---|---|
| 1 | I | X | C | M |
| 2 | II | XX | CC | MM |
| 3 | III | XXX | CCC | MMM |
| 4 | IV | XL | CD | [注 2] |
| 5 | V | L | D | |
| 6 | VI | LX | DC | |
| 7 | VII | LXX | DCC | |
| 8 | VIII | LXXX | DCCC | |
| 9 | IX | XC | CM |
これらを組み合わせることで、1 から 3999 の値が表現できる。だが言い換えれば、(パターンを守ろうとすると)4000以上の数値を表すことは不可能である。また、0 を表す記号は存在しない。このため、 0 の値が入る桁の数値は表記せず、そのまま空位とする。
また、整数と小数が一貫しておらず、整数が十進法(二五進法)である一方、小数には十二進法が適用され、1/12や1/144の小数が作られている。
小数は、3/12 (= 1/4)が「点3つ」、6/12 (= 1/2)が「S」、9/12 (= 3/4)が「Sに点3つ」として、六で一旦繰り上がる方法で表記されている。
| 12 | = | 10 × 1 | + | 1 × 2 | |||||||
| = | X | + | II | ||||||||
| = | XII | ||||||||||
|
|
|||||||||||
| 24 | = | 10 × 2 | + | (−1 + 5) | |||||||
| = | XX | + | IV | ||||||||
| = | XXIV | ||||||||||
|
|
|||||||||||
| 42 | = | (−10 + 50) | + | 1 × 2 | |||||||
| = | XL | + | II | ||||||||
| = | XLII | ||||||||||
|
|
|||||||||||
| 49 | = | (−10 + 50) | + | (−1 + 10) | |||||||
| = | XL | + | IX | ||||||||
| = | XLIX | ||||||||||
|
|
|||||||||||
| 89 | = | 50 | + | 10 × 3 | + | (−1 + 10) | |||||
| = | L | + | XXX | + | IX | ||||||
| = | LXXXIX | ||||||||||
|
|
|||||||||||
| 299 | = | 100 × 2 | + | (−10 + 100) | + | (−1 + 10) | |||||
| = | CC | + | XC | + | IX | ||||||
| = | CCXCIX | ||||||||||
|
|
|||||||||||
| 302 | = | 100 × 3 | + | (10 × 0) | + | 1 × 2 | |||||
| = | CCC | + | + | II | |||||||
| = | CCCII | ||||||||||
|
|
|||||||||||
| 493 | = | (−100 + 500) | + | (−10 + 100) | + | 1 × 3 | |||||
| = | CD | + | XC | + | III | ||||||
| = | CDXCIII | ||||||||||
|
|
|||||||||||
| 1960 | = | 1000 × 1 | + | (−100 + 1000) | + | 50 | + | 10 | + | (1 × 0) | |
| = | M | + | CM | + | L | + | X | ||||
| = | MCMLX | ||||||||||
|
|
|||||||||||
| 3999 | = | 1000 × 3 | + | (−100 + 1000) | + | (−10 + 100) | + | (−1 + 10) | |||
| = | MMM | + | CM | + | XC | + | IX | ||||
| = | MMMCMXCIX | ||||||||||
|
|
|||||||||||
なお、手書きでは、大文字のローマ数字は上下のセリフをつなげて書くことが多い。「V」は上部のセリフをつなぎ、逆三角形(▽)のようになる。小文字ではセリフを書かない。
時計の文字盤は伝統的に4時を「 IIII」と表記することが多い。その由来には下記のように様々な説が唱えられているが定説はない。なお、9時は通常表記の「 IX」の場合が多い。また、4時を通常表記の「 IV」と表記している時計も存在しており、この表記方法は絶対的な物ではない(同様に、9時を「 VIIII」と表記している時計も存在する)。

ローマ数字はもともと厳密な規則が定義されたものではなく、特に減算則に関しては様々な異表記が見られる。当初は減算則が存在しなかったため、4 を「 IIII」、9 を「 VIIII」と書いていた。「The Forme of Cury」(14世紀の著名な英語の料理解説書)は 4 = IIII、9 = IXと表記している一方で「 IV」と表記した箇所もある。
ほかに、80 = R、2000 = Zとする異表記もある。また、 1⁄2 = S、 1⁄12 = • などとする分数の記号もあった。
前述の通り、4000以上の数値の表記は、パターンに従った通常の方法では不可能であり、1 から 3999 の数値までしか表記できない。現代ではあまり使用されないが、4000以上の表記は下記の方法によって行う。
1000 を表すのに「M」ではなく「ↀ」または「CIↃ」を用いる場合もある。5000 を「ↁ」または「IↃↃ」、10000 を「ↂ」または「CCIↃↃ」で表した例もある。同様にして 50000 は「ↇ」または「IↃↃↃ」、100000 は「ↈ」または「CCCIↃↃↃ」となる。
| 基本数字 | C| Ɔ (M) = 1,000 | CC| ƆƆ = 10,000 | CCC| ƆƆƆ = 100,000 |
| + | Ɔ (D) = 500 | C| Ɔ| Ɔ (MD) = 1,500 | CC| ƆƆ| Ɔ = 10,500 | CCC| ƆƆƆ| Ɔ = 100,500 |
| + | ƆƆ = 5,000 | - | CC| ƆƆ| ƆƆ = 15,000 | CCC| ƆƆƆ| ƆƆ = 105,000 |
| + | ƆƆƆ = 50,000 | - | - | CCC| ƆƆƆ| ƆƆƆ = 150,000 |

現在、ローマ数字は序数、章番号、ページ番号、文章の脚注番号などに使うことが多いが、酸化銅(II)など一部例外がある[2]。
|
この節は検証可能な参考文献や出典が全く示されていないか、不十分です。 (2016年12月)
|
古代ローマ人は元々農耕民族だった。羊の数を数えるのに木の棒に刻み目を入れた。柵から1匹ずつヤギが出て行くたびに刻み目を1つずつ増やしていった。3匹目のヤギが出て行くと「III」と表し、4匹目のヤギが出て行くと3本の刻み目の横にもう1本刻み目を増やして「IIII」とした。5匹目のヤギが出て行くと、4本目の刻み目の右にこのときだけ「V」と刻んだ(∧と刻んだ羊飼いもいた)。このときの棒についた刻み目は「IIIIV」となる。6匹目のヤギが出て行くと、刻み目の模様は「IIIIVI」、7匹目が出て行くと「IIIIVII」となる。9匹目の次のヤギが出て行くと「IIIIVIIII」の右に「X」という印を刻んだ。棒の模様は「IIIIVIIIIX」となる。31匹のヤギは「IIIIVIIIIXIIIIVIIIIXIIIIVIIIIXI」と表す。このように刻んだのは、夕方にヤギが1匹ずつ戻ってきたときに記号の1つ1つがヤギ1匹ずつに対応していたほうが便利だったためである。ヤギが戻ると、記号を指で端から1個1個たどっていった。最後のヤギが戻るときに指先が最後の記号にふれていれば、ヤギは全部無事に戻ったことになる。50匹目のヤギはN、+または⊥で表した。100匹目は*で表した。これらの記号はローマのそばのエトルリア人も使った。エトルリアのほうが文明が栄えていたので、そちらからローマに伝わった可能性もある。1000は○の中に十を入れた記号で表した。
よく言われる「X」は「V」を2つ重ねて書いたもの、あるいは「V」は「X」の上半分という説は、誤りとは言い切れないが確たる根拠もないようである。
やがて時代が下り、羊以外のものも数えるようになると、31は単に「XXXI」と書くようになった。5はしばらく「V」と「∧」が混在して使われた。50は当初N、И、K、Ψ、などと書き、しばらく「⊥」かそれに似た模様を使ったが、アルファベットが伝わると混同して「L」となった。100は*だけでなくЖ、Hなどと書いたが、*がしだいに離れて「>|<」や「⊃|⊂」になり、よく使う数なので簡略になり、「C」や「⊃」と書きそのまま残った(ラテン語の"centum=100"が起源という説もある)。500は最初、1000を表す「⊂|⊃」から左の⊂を外し、「|⊃」と書いた。やがて2つの記号がくっつき、「D」となった。「D」の真ん中に横棒がついて「D」や「Ð」とも書いた。1000は○に十の記号が省略されて「⊂|⊃」となった。「∞」と書いた例もある。これが全部くっついたのが「Φ」に似た記号である。これが別の変形をし上だけがくっついて「m」に似た形になり、アルファベットが伝わると自然と「M」と書かれるようにもなった(ラテン語の"mille=1000"からも考慮されている)。そのため、1000は今でも2つの表記法が混在している。
5000以上の数は100と1000の字体の差から自然に決まった。ただし、「凶」を上下逆に書いた形(X)で1000000 (100万)を表したこともある。
古代ローマ共和国時代の算盤では、記号の上に横棒を引いて1000倍を表したものもある。この方法では、10000は「X」の上に横棒を1本引いたもので表される。100000 (10万) や1000000 (100万) は「C」や「M」の上に横棒を1本を引いて表した。たとえば10000は「X」となる。
例:CCX[注 3] = 210000 (21万)
数字の上部分に「 ̄」・左右に「|」をそれぞれつけて10万倍を表すこともあった(上と左右の線をくっつけて表記することも多い)。たとえば10(X)を10万倍した数=1000000 (100万) は、「X」と表記する。
例:
その後、他の文明との接触により変わった表記法が現れた。1世紀、プリニウスは著書『博物誌』で83000を「LXXXIII.M[注 6]」と表記した。83.1000 (83の1000倍) という書き方である。同じ文書中に、XCII.M [注 7](92000)、VM [注 8](5000) という表記もある。この乗算則はしばらく使われたようである。1299年に作成された『王フィリップ4世の財宝帳簿』では、5316を「VmIIIcXVI[注 9]」と表した。漢数字の書き方によく似ている。ただしこれらの乗算則は現在は使われない。
1000を超える数の表記法に混乱があるのは一般人は巨大な数を扱う機会がなかったためと考えられる。
基本的には通常のラテン文字を並べてローマ数字を表現する。Unicode 以前から欧米で一般的に使用されている ISO/IEC 8859 などの文字コードは、ローマ数字専用の符号を持っていない。
日本で用いられる文字コードとしても、JIS X 0208 にはローマ数字専用の符号は定義されていない。これを拡張した Microsoftコードページ932 (CP932) や MacJapanese などにおいて、いわゆる機種依存文字として定義されており、追って JIS X 0213 にも取り入れられた。CP932 にあるのは大文字 I から X と小文字 i から x の合成済み 20 字 (1 から 10 に相当)、MacJapanese にあるのは 大文字 I から XV と小文字 i から xv の合成済み 30 字 (1 から 15 に相当)、JIS X 0213 は大文字 I から XII と小文字 i から xii の合成済み 24 字 (1 から 12 に相当) である。これらは縦書きの組版の際に縦中横を容易に実現するために用いられ(一般の組版ルールでローマ数字は縦中横である)、多くのフォントで全角文字としてデザインされる。
Unicode は、JIS X 0213 などとの互換性のために上述の合成済みローマ数字を収録した上、その延長として Ⅼ, Ⅽ, Ⅾ, Ⅿ, ⅼ, ⅽ, ⅾ, ⅿ[注 10]、また通常のラテン文字にない Ↄ, ↄ, ↀ, ↁ, ↂ, ↇ, ↈ, ↅ, ↆ [注 11]も定義している。これらは U+2160 から U+2188 までの符号位置を割り当てられている。(Unicode 7.0.0 時点)〈登録領域〉Number Form(数字に準じるもの)
ラテン文字と共通の符号を用いるため、「I」「V」「X」「L」「C」「D」「M」が機械処理の際にアルファベットそのものを表しているのか、数字の「1」「5」「10」「50」「100」「500」「1000」を表しているのか解釈を誤る場合がある。
Unicodeに存在しないMacJapaneseのローマ数字 (XIII, XIV, XV, xiii, xiv, xv) は、Unicodeの私用領域にAppleが独自に定義した制御文字の後ろに組文字を構成する文字を続けることで表される[3]。
| 大文字 | Unicode | JIS X 0213 | 文字参照 | 小文字 | Unicode | JIS X 0213 | 文字参照 | 備考 |
|---|---|---|---|---|---|---|---|---|
| Ⅰ | U+2160 |
1-13-21 |
ⅠⅠ |
ⅰ | U+2170 |
1-12-21 |
ⅰⅰ |
ローマ数字1 |
| Ⅱ | U+2161 |
1-13-22 |
ⅡⅡ |
ⅱ | U+2171 |
1-12-22 |
ⅱⅱ |
ローマ数字2 |
| Ⅲ | U+2162 |
1-13-23 |
ⅢⅢ |
ⅲ | U+2172 |
1-12-23 |
ⅲⅲ |
ローマ数字3 |
| Ⅳ | U+2163 |
1-13-24 |
ⅣⅣ |
ⅳ | U+2173 |
1-12-24 |
ⅳⅳ |
ローマ数字4 |
| Ⅴ | U+2164 |
1-13-25 |
ⅤⅤ |
ⅴ | U+2174 |
1-12-25 |
ⅴⅴ |
ローマ数字5 |
| Ⅵ | U+2165 |
1-13-26 |
ⅥⅥ |
ⅵ | U+2175 |
1-12-26 |
ⅵⅵ |
ローマ数字6 |
| Ⅶ | U+2166 |
1-13-27 |
ⅦⅦ |
ⅶ | U+2176 |
1-12-27 |
ⅶⅶ |
ローマ数字7 |
| Ⅷ | U+2167 |
1-13-28 |
ⅧⅧ |
ⅷ | U+2177 |
1-12-28 |
ⅷⅷ |
ローマ数字8 |
| Ⅸ | U+2168 |
1-13-29 |
ⅨⅨ |
ⅸ | U+2178 |
1-12-29 |
ⅸⅸ |
ローマ数字9 |
| Ⅹ | U+2169 |
1-13-30 |
ⅩⅩ |
ⅹ | U+2179 |
1-12-30 |
ⅹⅹ |
ローマ数字10 |
| 大文字 | Unicode | JIS X 0213 | 文字参照 | 小文字 | Unicode | JIS X 0213 | 文字参照 | 備考 |
|---|---|---|---|---|---|---|---|---|
| Ⅺ | U+216A |
1-13-31 |
ⅪⅪ |
ⅺ | U+217A |
1-12-31 |
ⅺⅺ |
ローマ数字11 |
| Ⅻ | U+216B |
1-13-55 |
ⅫⅫ |
ⅻ | U+217B |
1-12-32 |
ⅻⅻ |
ローマ数字12 |
| 大文字 | Unicode | JIS X 0213 | 文字参照 | 小文字 | Unicode | JIS X 0213 | 文字参照 | 備考 |
|---|---|---|---|---|---|---|---|---|
| Ⅼ | U+216C |
‐ |
ⅬⅬ |
ⅼ | U+217C |
‐ |
ⅼⅼ |
ローマ数字50 |
| Ⅽ | U+216D |
‐ |
ⅭⅭ |
ⅽ | U+217D |
‐ |
ⅽⅽ |
ローマ数字100 |
| Ⅾ | U+216E |
‐ |
ⅮⅮ |
ⅾ | U+217E |
‐ |
ⅾⅾ |
ローマ数字500 |
| Ⅿ | U+216F |
‐ |
ⅯⅯ |
ⅿ | U+217F |
‐ |
ⅿⅿ |
ローマ数字1000 |
| Ↄ | U+2183 |
‐ |
ↃↃ |
ↄ | U+2184 |
‐ |
ↄↄ |
ローマ数字逆100 |
| 記号 | Unicode | JIS X 0213 | 文字参照 | 名称 |
|---|---|---|---|---|
| ↀ | U+2180 |
‐ |
ↀↀ |
ローマ数字1000 C D |
| ↁ | U+2181 |
‐ |
ↁↁ |
ローマ数字5000 |
| ↂ | U+2182 |
‐ |
ↂↂ |
ローマ数字10000 |
| ↇ | U+2187 |
‐ |
ↇↇ |
ローマ数字50000 |
| ↈ | U+2188 |
‐ |
ↈↈ |
ローマ数字100000 |
| ↅ | U+2185 |
‐ |
ↅↅ |
ローマ数字6 LATE FORM |
| ↆ | U+2186 |
‐ |
ↆↆ |
ローマ数字50 EARLY FORM |
| 記号の再現 | MacJapanese | 記号の再現 | MacJapanese | 名称 |
|---|---|---|---|---|
| XIII | 0x85AB | xiii | 0x85BF | ローマ数字13 |
| XIV | 0x85AC | xiv | 0x85C0 | ローマ数字14 |
| XV | 0x85AD | xv | 0x85C1 | ローマ数字15 |
| 典拠管理データベース: 国立図書館 |
|---|
(C. から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/12/08 00:02 UTC 版)
上付き文字(うえつきもじ、英: superscript)は、基準となる文字より上部に記述される添え字である。
数学における冪乗を表す目的や、化学におけるイオン価数を表す目的、原子核物理学・放射線医学などにおける放射性同位元素の質量数を表す目的として使われるほか、文書における脚注参照、単位記号、TMなどの一部記号、発音記号、装飾(ロゴタイプ)などとしても用いられる。
冪乗の目的で使用される場合は、イオン価数の目的で使用される文字よりも上部に表記される。
フランス語、イタリア語、スペイン語などのロマンス諸語では、数字に上付きで e もしくは o/a を付記し、序数とその性を表示する。Unicode では、序数標識 º と ª が用意されている。これらは音楽などにも流用され、たとえばtempo primo(テンポプリーモ)をtempo 1ºと表記する。
HTMLのタグで表記する場合は<sup>上付き文字</sup>が使用される。
| 大文字 | Unicode | JIS X 0213 | 文字参照 | 小文字 | Unicode | JIS X 0213 | 文字参照 | 備考 |
|---|---|---|---|---|---|---|---|---|
| ᴬ | U+1D2C |
- |
ᴬᴬ |
ᵃ | U+1D43 |
- |
ᵃᵃ |
A |
| ᴮ | U+1D2E |
- |
ᴮᴮ |
ᵇ | U+1D47 |
- |
ᵇᵇ |
B |
| ᴰ | U+1D30 |
- |
ᴰᴰ |
ᵈ | U+1D48 |
- |
ᵈᵈ |
D |
| ᴱ | U+1D31 |
- |
ᴱᴱ |
ᵉ | U+1D49 |
- |
ᵉᵉ |
E |
| ᴳ | U+1D33 |
- |
ᴳᴳ |
ᵍ | U+1D4D |
- |
ᵍᵍ |
G |
| ᴴ | U+1D34 |
- |
ᴴᴴ |
ʰ | U+02B0 |
- |
ʰʰ |
H |
| ᴵ | U+1D35 |
- |
ᴵᴵ |
ⁱ | U+2071 |
- |
ⁱⁱ |
I |
| ᴶ | U+1D36 |
- |
ᴶᴶ |
ʲ | U+02B2 |
- |
ʲʲ |
J |
| ᴷ | U+1D37 |
- |
ᴷᴷ |
ᵏ | U+1D4F |
- |
ᵏᵏ |
K |
| ᴸ | U+1D38 |
- |
ᴸᴸ |
ˡ | U+02E1 |
- |
ˡˡ |
L |
| ᴹ | U+1D39 |
- |
ᴹᴹ |
ᵐ | U+1D50 |
- |
ᵐᵐ |
M |
| ᴺ | U+1D3A |
- |
ᴺᴺ |
ⁿ | U+207F |
- |
ⁿⁿ |
N |
| ᴼ | U+1D3C |
- |
ᴼᴼ |
ᵒ | U+1D52 |
- |
ᵒᵒ |
O |
| ᴾ | U+1D3E |
- |
ᴾᴾ |
ᵖ | U+1D56 |
- |
ᵖᵖ |
P |
| ᴿ | U+1D3F |
- |
ᴿᴿ |
ʳ | U+02B3 |
- |
ʳʳ |
R |
| ᵀ | U+1D40 |
- |
ᵀᵀ |
ᵗ | U+1D57 |
- |
ᵗᵗ |
T |
| ᵁ | U+1D41 |
- |
ᵁᵁ |
ᵘ | U+1D58 |
- |
ᵘᵘ |
U |
| ⱽ | U+2C7D |
- |
ⱽⱽ |
ᵛ | U+1D5B |
- |
ᵛᵛ |
V |
| ᵂ | U+1D42 |
- |
ᵂᵂ |
ʷ | U+02B7 |
- |
ʷʷ |
W |
| 記号 | Unicode | JIS X 0213 | 文字参照 | 名称 |
|---|---|---|---|---|
| ᶜ | U+1D9C |
- |
ᶜᶜ |
C |
| ᶠ | U+1DA0 |
- |
ᶠᶠ |
F |
| ˢ | U+02E2 |
- |
ˢˢ |
S |
| ˣ | U+02E3 |
- |
ˣˣ |
X |
| ʸ | U+02B8 |
- |
ʸʸ |
Y |
| ᶻ | U+1DBB |
- |
ᶻᶻ |
Z |
| ⁰ | U+2070 |
- |
⁰⁰ |
SUPERSCRIPT ZERO |
| ¹ | U+00B9 |
1-9-16 |
¹¹ |
SUPERSCRIPT ONE |
| ² | U+00B2 |
1-9-12 |
²² |
SUPERSCRIPT TWO |
| ³ | U+00B3 |
1-9-13 |
³³ |
SUPERSCRIPT THREE |
| ⁴ | U+2074 |
- |
⁴⁴ |
SUPERSCRIPT FOUR |
| ⁵ | U+2075 |
- |
⁵⁵ |
SUPERSCRIPT FIVE |
| ⁶ | U+2076 |
- |
⁶⁶ |
SUPERSCRIPT SIX |
| ⁷ | U+2077 |
- |
⁷⁷ |
SUPERSCRIPT SEVEN |
| ⁸ | U+2078 |
- |
⁸⁸ |
SUPERSCRIPT EIGHT |
| ⁹ | U+2079 |
- |
⁹⁹ |
SUPERSCRIPT NINE |
| ⁺ | U+207A |
- |
⁺⁺ |
SUPERSCRIPT PLUS SIGN |
| ⁻ | U+207B |
- |
⁻⁻ |
SUPERSCRIPT MINUS |
| ⁼ | U+207C |
- |
⁼⁼ |
SUPERSCRIPT EQUALS SIGN |
| ⁽ | U+207D |
- |
⁽⁽ |
SUPERSCRIPT LEFT PARENTHESIS |
| ⁾ | U+207E |
- |
⁾⁾ |
SUPERSCRIPT RIGHT PARENTHESIS |
| ª | U+00AA |
1-9-7 |
ªª |
FEMININE ORDINAL INDICATOR |
| ᵃ | U+1D43 |
- |
ᵃᵃ |
MODIFIER LETTER SMALL TURNED A |
| ᵅ | U+1D45 |
- |
ᵅᵅ |
MODIFIER LETTER SMALL ALPHA |
| ᶛ | U+1D9B |
- |
ᶛᶛ |
MODIFIER LETTER SMALL TURNED ALPHA |
| ᴭ | U+1D2D |
- |
ᴭᴭ |
MODIFIER LETTER CAPITAL AE |
| ᵆ | U+1D46 |
- |
ᵆᵆ |
MODIFIER LETTER SMALL TURNED AE |
| ᴯ | U+1D2F |
- |
ᴯᴯ |
MODIFIER LETTER CAPITAL BARRAD B |
| ᵝ | U+1D5D |
- |
ᵝᵝ |
MODIFIER LETTER SMALL BETA |
| ᶝ | U+1D9D |
- |
ᶝᶝ |
MODIFIER LETTER SMALL C WITH CURL |
| ᶞ | U+1D9E |
- |
ᶞᶞ |
MODIFIER LETTER SMALL ETH |
| ᵞ | U+1D5E |
- |
ᵞᵞ |
MODIFIER LETTER SMALL GREEK GAMMA |
| ᵟ | U+1D5F |
- |
ᵟᵟ |
MODIFIER LETTER SMALL DELTA |
| ᵋ | U+1D4B |
- |
ᵋᵋ |
MODIFIER LETTER SMALL OPEN E |
| ᵌ | U+1D4C |
- |
ᵌᵌ |
MODIFIER LETTER SMALL TURNED OPEN E |
| ᶟ | U+1D9F |
- |
ᶟᶟ |
MODIFIER LETTER SMALL REVERSED OPEN E |
| ᴲ | U+1D32 |
- |
ᴲᴲ |
MODIFIER LETTER CAPITAL REVERSED E |
| ᵊ | U+1D4A |
- |
ᵊᵊ |
MODIFIER LETTER SMALL SCHWA |
| ᶡ | U+1DA1 |
- |
ᶡᶡ |
MODIFIER LETTER SMALL DOTLESS J WITH STROKE |
| ᶣ | U+1DA3 |
- |
ᶣᶣ |
MODIFIER LETTER SMALL TURNED H |
| ᶤ | U+1DA4 |
- |
ᶤᶤ |
MODIFIER LETTER SMALL I WITH STROKE |
| ᶥ | U+1DA5 |
- |
ᶥᶥ |
MODIFIER LETTER SMALL IOTA |
| ᶦ | U+1DA6 |
- |
ᶦᶦ |
MODIFIER LETTER SMALL CAPITAL I |
| ᵎ | U+1D4E |
- |
ᵎᵎ |
MODIFIER LETTER SMALL TURNED I |
| ᶧ | U+1DA7 |
- |
ᶧᶧ |
MODIFIER LETTER SMALL CAPITAL I WITH STROKE |
| ᶨ | U+1DA8 |
- |
ᶨᶨ |
MODIFIER LETTER SMALL J WITH CROSSED-TAIL |
| ᶩ | U+1DA9 |
- |
ᶩᶩ |
MODIFIER LETTER SMALL L WITH RETROFLEX TAIL |
| ᶪ | U+1DAA |
- |
ᶪᶪ |
MODIFIER LETTER SMALL L WITH PARATAL HOOK |
| ᶫ | U+1DAB |
- |
ᶫᶫ |
MODIFIER LETTER SMALL CAPITAL L |
| ᶬ | U+1DAC |
- |
ᶬᶬ |
MODIFIER LETTER SMALL M WITH HOOK |
| ᶭ | U+1DAD |
- |
ᶭᶭ |
MODIFIER LETTER SMALL TURNED M WITH LONG LEG |
| ᴻ | U+1D3B |
- |
ᴻᴻ |
MODIFIER LETTER CAPITAL REVERSED N |
| ᶮ | U+1DAE |
- |
ᶮᶮ |
MODIFIER LETTER SMALL N WITH LEFT HOOK |
| ᶯ | U+1DAF |
- |
ᶯᶯ |
MODIFIER LETTER SMALL N WITH RETROFLEX HOOK |
| ᶰ | U+1DB0 |
- |
ᶰᶰ |
MODIFIER LETTER SMALL CAPITAL N |
| ᵑ | U+1D51 |
- |
ᵑᵑ |
MODIFIER LETTER SMALL ENG |
| º | U+00BA |
1-9-17 |
ºº |
MASCULINE ORDINAL INDICATOR |
| ᴽ | U+1D3D |
- |
ᴽᴽ |
MODIFIER LETTER CAPITAL OU |
| ᶱ | U+1DB1 |
- |
ᶱᶱ |
MODIFIER LETTER SMALL BARRED O |
| ᵓ | U+1D53 |
- |
ᵓᵓ |
MODIFIER LETTER SMALL OPEN O |
| ᵔ | U+1D54 |
- |
ᵔᵔ |
MODIFIER LETTER SMALL TOP HALF O |
| ᵕ | U+1D55 |
- |
ᵕᵕ |
MODIFIER LETTER SMALL BOTTOM HALF O |
| ᶲ | U+1DB2 |
- |
ᶲᶲ |
MODIFIER LETTER SMALL PHI |
| ᵠ | U+1D60 |
- |
ᵠᵠ |
MODIFIER LETTER SMALL GREEK PHI |
| ᶳ | U+1DB3 |
- |
ᶳᶳ |
MODIFIER LETTER SMALL S WITH HOOK |
| ᶴ | U+1DB4 |
- |
ᶴᶴ |
MODIFIER LETTER SMALL ESH |
| ᶵ | U+1DB5 |
- |
ᶵᶵ |
MODIFIER LETTER SMALL T WITH PARATAL HOOK |
| ᶶ | U+1DB6 |
- |
ᶶᶶ |
MODIFIER LETTER SMALL U BAR |
| ᶷ | U+1DB7 |
- |
ᶷᶷ |
MODIFIER LETTER SMALL UPSIRON |
| ᶸ | U+1DB8 |
- |
ᶸᶸ |
MODIFIER LETTER SMALL CAPITAL U |
| ᵙ | U+1D59 |
- |
ᵙᵙ |
MODIFIER LETTER SMALL SIDEWAYS U |
| ᵚ | U+1D5A |
- |
ᵚᵚ |
MODIFIER LETTER SMALL TURNED M |
| ᶹ | U+1DB9 |
- |
ᶹᶹ |
MODIFIER LETTER SMALL V WITH HOOK |
| ᶺ | U+1DBA |
- |
ᶺᶺ |
MODIFIER LETTER SMALL TURNED V |
| ᵜ | U+1D5C |
- |
ᵜᵜ |
MODIFIER LETTER SMALL AIN |
| ᵡ | U+1D61 |
- |
ᵡᵡ |
MODIFIER LETTER SMALL CHI |
| ᶼ | U+1DBC |
- |
ᶼᶼ |
MODIFIER LETTER SMALL Z WITH RETROFLEX HOOK |
| ᶽ | U+1DBD |
- |
ᶽᶽ |
MODIFIER LETTER SMALL Z WITH CURL |
| ᶾ | U+1DBE |
- |
ᶾᶾ |
MODIFIER LETTER SMALL EZH |
| ᶿ | U+1DBF |
- |
ᶿᶿ |
MODIFIER LETTER SMALL THETA |
(C. から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/06/22 00:04 UTC 版)
丸囲みCは、囲み英数字の一種で、大文字または小文字のCを丸で囲んだものである。
大文字のCを丸で囲んだもの (Ⓒ) は、Unicodeでは"U+24B8"に収録されている。UTF-8では"e2 92 b8"とエンコードされる。
小文字のcを丸で囲んだもの (ⓒ) は、Unicodeでは"U+24D2"に収録されている。UTF-8では"e2 93 92"とエンコードされる。
| 記号 | Unicode | JIS X 0213 | 文字参照 | 名称 |
|---|---|---|---|---|
| Ⓒ | U+24B8 |
- |
ⒸⒸ |
CIRCLED LATIN CAPITAL LETTER C |
| ⓒ | U+24D2 |
1-12-35 |
ⓒⓒ |
丸C小文字 CIRCLED LATIN SMALL LETTER C |
| © | U+00A9 |
- |
©© |
COPYRIGHT SIGN |
丸囲みCは、著作権マークとして使用されている。
1947年から1949年にかけて発売された千代田光学(後のミノルタ→コニカミノルタ)のカメラには、レンズに"ⓒ Super Rokkor"のように青いⓒマークが付いているものがあった。これは著作権表示ではなく、反射防止(coated)加工がされていることを示すものだった[1]。他のメーカーのレンズにも同様の意味の刻印があり、例えば、オリンパスのズイコーレンズには、赤い"ZUIKO C."という表記があった。
このマークは、第二次世界大戦中に製造されたクルーバー社のプラスチック製の機体認識訓練用模型で広く使用された[2]。
日本語の敬称の「ちゃん (Chan)」の意味で丸囲みCが使用されることがある。
(C. から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/07/08 07:52 UTC 版)
| 囲み英数字 | |
|---|---|
| Enclosed Alphanumerics | |
| 範囲 | U+2460..U+24FF (160 個の符号位置) |
| 面 | 基本多言語面 |
| 用字 | Common |
| 割当済 | 160 個の符号位置 |
| 未使用 | 0 個の保留 |
| Unicodeのバージョン履歴 | |
| 1.0.0 | 139 (+139) |
| 3.2 | 159 (+20) |
| 4.0 | 160 (+1) |
| 公式ページ | |
| コード表 ∣ ウェブページ | |
| 備考: [1][2] | |
囲み英数字(かこみえいすうじ、英語: Enclosed alphanumerics)は、Unicodeの84個目のブロックであり、丸や括弧で囲まれた英数字やピリオドつきの数字が収録されている。この他、Unicode バージョン 6.0で追加多言語面(SMP)に囲み英数字補助ブロックが追加された。
囲み英数字の多くは元々箇条書き用に使用されていた[3]。括弧で囲まれた形式は、歴史的に、丸囲みの文字をタイプライターで表現しようとした形に基づいている[3]。これらの役割は、 リッチテキストにおいてはスタイルやマークアップに置き替えられた。しかし、東アジアの既存の文字コードとの互換性や、テキストファイルでそのような記号が使用される場合のために、囲み文字がUnicode標準に含まれている[3]。Unicode規格では、著作権や商標の記号として定義されている丸囲みのC・P・Rやアットマークなど、目的に特化した文字は囲み文字とは区別している[3]。
英数字を囲むすべての文字がこの区間にあるわけではないことに注意。 Unicode区間装飾記号(Dingbat)では、U+2777からU+2793まで、数字1から10を囲む黒文字、数字1から10を囲む非セリフ文字、数字1から10を囲む非セリフ黒文字の順にある。
本ブロックに含まれる囲み文字は基本的に手順の順序や教育における小問などの番号付きリストを形成するために用いられる。
| コード | 文字 | 文字名(英語) | 用例・説明 |
|---|---|---|---|
| 丸囲み数字 | |||
| U+2460 | ① | CIRCLED DIGIT ONE | |
| U+2461 | ② | CIRCLED DIGIT TWO | |
| U+2462 | ③ | CIRCLED DIGIT THREE | |
| U+2463 | ④ | CIRCLED DIGIT FOUR | |
| U+2464 | ⑤ | CIRCLED DIGIT FIVE | |
| U+2465 | ⑥ | CIRCLED DIGIT SIX | |
| U+2466 | ⑦ | CIRCLED DIGIT SEVEN | |
| U+2467 | ⑧ | CIRCLED DIGIT EIGHT | |
| U+2468 | ⑨ | CIRCLED DIGIT NINE | |
| U+2469 | ⑩ | CIRCLED NUMBER TEN | |
| U+246A | ⑪ | CIRCLED NUMBER ELEVEN | |
| U+246B | ⑫ | CIRCLED NUMBER TWELVE | |
| U+246C | ⑬ | CIRCLED NUMBER THIRTEEN | |
| U+246D | ⑭ | CIRCLED NUMBER FOURTEEN | |
| U+246E | ⑮ | CIRCLED NUMBER FIFTEEN | |
| U+246F | ⑯ | CIRCLED NUMBER SIXTEEN | |
| U+2470 | ⑰ | CIRCLED NUMBER SEVENTEEN | |
| U+2471 | ⑱ | CIRCLED NUMBER EIGHTEEN | |
| U+2472 | ⑲ | CIRCLED NUMBER NINETEEN | |
| U+2473 | ⑳ | CIRCLED NUMBER TWENTY | |
| 括弧囲み数字 | |||
| U+2474 | ⑴ | PARENTHESIZED DIGIT ONE | |
| U+2475 | ⑵ | PARENTHESIZED DIGIT TWO | |
| U+2476 | ⑶ | PARENTHESIZED DIGIT THREE | |
| U+2477 | ⑷ | PARENTHESIZED DIGIT FOUR | |
| U+2478 | ⑸ | PARENTHESIZED DIGIT FIVE | |
| U+2479 | ⑹ | PARENTHESIZED DIGIT SIX | |
| U+247A | ⑺ | PARENTHESIZED DIGIT SEVEN | |
| U+247B | ⑻ | PARENTHESIZED DIGIT EIGHT | |
| U+247C | ⑼ | PARENTHESIZED DIGIT NINE | |
| U+247D | ⑽ | PARENTHESIZED NUMBER TEN | |
| U+247E | ⑾ | PARENTHESIZED NUMBER ELEVEN | |
| U+247F | ⑿ | PARENTHESIZED NUMBER TWELVE | |
| U+2480 | ⒀ | PARENTHESIZED NUMBER THIRTEEN | |
| U+2481 | ⒁ | PARENTHESIZED NUMBER FOURTEEN | |
| U+2482 | ⒂ | PARENTHESIZED NUMBER FIFTEEN | |
| U+2483 | ⒃ | PARENTHESIZED NUMBER SIXTEEN | |
| U+2484 | ⒄ | PARENTHESIZED NUMBER SEVENTEEN | |
| U+2485 | ⒅ | PARENTHESIZED NUMBER EIGHTEEN | |
| U+2486 | ⒆ | PARENTHESIZED NUMBER NINETEEN | |
| U+2487 | ⒇ | PARENTHESIZED NUMBER TWENTY | |
| ピリオド付き数字 | |||
| U+2488 | ⒈ | DIGIT ONE FULL STOP | |
| U+2489 | ⒉ | DIGIT TWO FULL STOP | |
| U+248A | ⒊ | DIGIT THREE FULL STOP | |
| U+248B | ⒋ | DIGIT FOUR FULL STOP | |
| U+248C | ⒌ | DIGIT FIVE FULL STOP | |
| U+248D | ⒍ | DIGIT SIX FULL STOP | |
| U+248E | ⒎ | DIGIT SEVEN FULL STOP | |
| U+248F | ⒏ | DIGIT EIGHT FULL STOP | |
| U+2490 | ⒐ | DIGIT NINE FULL STOP | |
| U+2491 | ⒑ | NUMBER TEN FULL STOP | |
| U+2492 | ⒒ | NUMBER ELEVEN FULL STOP | |
| U+2493 | ⒓ | NUMBER TWELVE FULL STOP | |
| U+2494 | ⒔ | NUMBER THIRTEEN FULL STOP | |
| U+2495 | ⒕ | NUMBER FOURTEEN FULL STOP | |
| U+2496 | ⒖ | NUMBER FIFTEEN FULL STOP | |
| U+2497 | ⒗ | NUMBER SIXTEEN FULL STOP | |
| U+2498 | ⒘ | NUMBER SEVENTEEN FULL STOP | |
| U+2499 | ⒙ | NUMBER EIGHTEEN FULL STOP | |
| U+249A | ⒚ | NUMBER NINETEEN FULL STOP | |
| U+249B | ⒛ | NUMBER TWENTY FULL STOP | |
| 括弧囲みラテン文字 | |||
| U+249C | ⒜ | PARENTHESIZED LATIN SMALL LETTER A | |
| U+249D | ⒝ | PARENTHESIZED LATIN SMALL LETTER B | |
| U+249E | ⒞ | PARENTHESIZED LATIN SMALL LETTER C | |
| U+249F | ⒟ | PARENTHESIZED LATIN SMALL LETTER D | |
| U+24A0 | ⒠ | PARENTHESIZED LATIN SMALL LETTER E | |
| U+24A1 | ⒡ | PARENTHESIZED LATIN SMALL LETTER F | |
| U+24A2 | ⒢ | PARENTHESIZED LATIN SMALL LETTER G | |
| U+24A3 | ⒣ | PARENTHESIZED LATIN SMALL LETTER H | |
| U+24A4 | ⒤ | PARENTHESIZED LATIN SMALL LETTER I | |
| U+24A5 | ⒥ | PARENTHESIZED LATIN SMALL LETTER J | |
| U+24A6 | ⒦ | PARENTHESIZED LATIN SMALL LETTER K | |
| U+24A7 | ⒧ | PARENTHESIZED LATIN SMALL LETTER L | |
| U+24A8 | ⒨ | PARENTHESIZED LATIN SMALL LETTER M | |
| U+24A9 | ⒩ | PARENTHESIZED LATIN SMALL LETTER N | |
| U+24AA | ⒪ | PARENTHESIZED LATIN SMALL LETTER O | |
| U+24AB | ⒫ | PARENTHESIZED LATIN SMALL LETTER P | |
| U+24AC | ⒬ | PARENTHESIZED LATIN SMALL LETTER Q | |
| U+24AD | ⒭ | PARENTHESIZED LATIN SMALL LETTER R | |
| U+24AE | ⒮ | PARENTHESIZED LATIN SMALL LETTER S | |
| U+24AF | ⒯ | PARENTHESIZED LATIN SMALL LETTER T | |
| U+24B0 | ⒰ | PARENTHESIZED LATIN SMALL LETTER U | |
| U+24B1 | ⒱ | PARENTHESIZED LATIN SMALL LETTER V | |
| U+24B2 | ⒲ | PARENTHESIZED LATIN SMALL LETTER W | |
| U+24B3 | ⒳ | PARENTHESIZED LATIN SMALL LETTER X | |
| U+24B4 | ⒴ | PARENTHESIZED LATIN SMALL LETTER Y | |
| U+24B5 | ⒵ | PARENTHESIZED LATIN SMALL LETTER Z | |
| 丸囲みラテン文字 | |||
| U+24B6 | Ⓐ | CIRCLED LATIN CAPITAL LETTER A | しばしば無神論(atheism)のシンボルとして用いられる。 |
| U+24B7 | Ⓑ | CIRCLED LATIN CAPITAL LETTER B | |
| U+24B8 | Ⓒ | CIRCLED LATIN CAPITAL LETTER C | 拡張IPAでは不明瞭な子音(consonant)を表す。 |
| U+24B9 | Ⓓ | CIRCLED LATIN CAPITAL LETTER D | |
| U+24BA | Ⓔ | CIRCLED LATIN CAPITAL LETTER E | |
| U+24BB | Ⓕ | CIRCLED LATIN CAPITAL LETTER F | 拡張IPAでは不明瞭な摩擦音(fricative)を表す。 |
| U+24BC | Ⓖ | CIRCLED LATIN CAPITAL LETTER G | 拡張IPAでは不明瞭な接近音(glide)を表す。 |
| U+24BD | Ⓗ | CIRCLED LATIN CAPITAL LETTER H | 地図記号ではしばしばホテルを表す。 ヘリポートのある場所にはこの記号が地面に表示されている。 |
| U+24BE | Ⓘ | CIRCLED LATIN CAPITAL LETTER I | |
| U+24BF | Ⓙ | CIRCLED LATIN CAPITAL LETTER J | |
| U+24C0 | Ⓚ | CIRCLED LATIN CAPITAL LETTER K | |
| U+24C1 | Ⓛ | CIRCLED LATIN CAPITAL LETTER L | 拡張IPAでは不明瞭な側面音(liquid/lateral)を表す。 |
| U+24C2 | Ⓜ | CIRCLED LATIN CAPITAL LETTER M | 地図記号ではしばしば地下鉄(metro)を表す。 絵文字が提供されている。 |
| U+24C3 | Ⓝ | CIRCLED LATIN CAPITAL LETTER N | 拡張IPAでは不明瞭な鼻音(nasal)を表す。 |
| U+24C4 | Ⓞ | CIRCLED LATIN CAPITAL LETTER O | |
| U+24C5 | Ⓟ | CIRCLED LATIN CAPITAL LETTER P | 拡張IPAでは不明瞭な破裂音(plosive)を表す。 |
| U+24C6 | Ⓠ | CIRCLED LATIN CAPITAL LETTER Q | |
| U+24C7 | Ⓡ | CIRCLED LATIN CAPITAL LETTER R | 拡張IPAでは不明瞭な流音(rhotic/resonant)を表す。 |
| U+24C8 | Ⓢ | CIRCLED LATIN CAPITAL LETTER S | 拡張IPAでは不明瞭な歯擦音(sibilant)を表す。 |
| U+24C9 | Ⓣ | CIRCLED LATIN CAPITAL LETTER T | 拡張IPAでは不明瞭な声調(tone)を表す。 |
| U+24CA | Ⓤ | CIRCLED LATIN CAPITAL LETTER U | |
| U+24CB | Ⓥ | CIRCLED LATIN CAPITAL LETTER V | 拡張IPAでは不明瞭な母音(vowel)を表す。 |
| U+24CC | Ⓦ | CIRCLED LATIN CAPITAL LETTER W | |
| U+24CD | Ⓧ | CIRCLED LATIN CAPITAL LETTER X | |
| U+24CE | Ⓨ | CIRCLED LATIN CAPITAL LETTER Y | |
| U+24CF | Ⓩ | CIRCLED LATIN CAPITAL LETTER Z | |
| U+24D0 | ⓐ | CIRCLED LATIN SMALL LETTER A | |
| U+24D1 | ⓑ | CIRCLED LATIN SMALL LETTER B | |
| U+24D2 | ⓒ | CIRCLED LATIN SMALL LETTER C | |
| U+24D3 | ⓓ | CIRCLED LATIN SMALL LETTER D | |
| U+24D4 | ⓔ | CIRCLED LATIN SMALL LETTER E | |
| U+24D5 | ⓕ | CIRCLED LATIN SMALL LETTER F | |
| U+24D6 | ⓖ | CIRCLED LATIN SMALL LETTER G | |
| U+24D7 | ⓗ | CIRCLED LATIN SMALL LETTER H | |
| U+24D8 | ⓘ | CIRCLED LATIN SMALL LETTER I | |
| U+24D9 | ⓙ | CIRCLED LATIN SMALL LETTER J | |
| U+24DA | ⓚ | CIRCLED LATIN SMALL LETTER K | |
| U+24DB | ⓛ | CIRCLED LATIN SMALL LETTER L | |
| U+24DC | ⓜ | CIRCLED LATIN SMALL LETTER M | |
| U+24DD | ⓝ | CIRCLED LATIN SMALL LETTER N | |
| U+24DE | ⓞ | CIRCLED LATIN SMALL LETTER O | |
| U+24DF | ⓟ | CIRCLED LATIN SMALL LETTER P | |
| U+24E0 | ⓠ | CIRCLED LATIN SMALL LETTER Q | |
| U+24E1 | ⓡ | CIRCLED LATIN SMALL LETTER R | |
| U+24E2 | ⓢ | CIRCLED LATIN SMALL LETTER S | |
| U+24E3 | ⓣ | CIRCLED LATIN SMALL LETTER T | |
| U+24E4 | ⓤ | CIRCLED LATIN SMALL LETTER U | |
| U+24E5 | ⓥ | CIRCLED LATIN SMALL LETTER V | |
| U+24E6 | ⓦ | CIRCLED LATIN SMALL LETTER W | |
| U+24E7 | ⓧ | CIRCLED LATIN SMALL LETTER X | |
| U+24E8 | ⓨ | CIRCLED LATIN SMALL LETTER Y | |
| U+24E9 | ⓩ | CIRCLED LATIN SMALL LETTER Z | |
| 追加の丸囲み数字 | |||
| U+24EA | ⓪ | CIRCLED DIGIT ZERO | |
| 黒丸囲み白数字 | |||
| U+24EB | ⓫ | NEGATIVE CIRCLED NUMBER ELEVEN | |
| U+24EC | ⓬ | NEGATIVE CIRCLED NUMBER TWELVE | |
| U+24ED | ⓭ | NEGATIVE CIRCLED NUMBER THIRTEEN | |
| U+24EE | ⓮ | NEGATIVE CIRCLED NUMBER FOURTEEN | |
| U+24EF | ⓯ | NEGATIVE CIRCLED NUMBER FIFTEEN | |
| U+24F0 | ⓰ | NEGATIVE CIRCLED NUMBER SIXTEEN | |
| U+24F1 | ⓱ | NEGATIVE CIRCLED NUMBER SEVENTEEN | |
| U+24F2 | ⓲ | NEGATIVE CIRCLED NUMBER EIGHTEEN | |
| U+24F3 | ⓳ | NEGATIVE CIRCLED NUMBER NINETEEN | |
| U+24F4 | ⓴ | NEGATIVE CIRCLED NUMBER TWENTY | |
| 二重丸囲み数字 | |||
| U+24F5 | ⓵ | DOUBLE CIRCLED DIGIT ONE | |
| U+24F6 | ⓶ | DOUBLE CIRCLED DIGIT TWO | |
| U+24F7 | ⓷ | DOUBLE CIRCLED DIGIT THREE | |
| U+24F8 | ⓸ | DOUBLE CIRCLED DIGIT FOUR | |
| U+24F9 | ⓹ | DOUBLE CIRCLED DIGIT FIVE | |
| U+24FA | ⓺ | DOUBLE CIRCLED DIGIT SIX | |
| U+24FB | ⓻ | DOUBLE CIRCLED DIGIT SEVEN | |
| U+24FC | ⓼ | DOUBLE CIRCLED DIGIT EIGHT | |
| U+24FD | ⓽ | DOUBLE CIRCLED DIGIT NINE | |
| U+24FE | ⓾ | DOUBLE CIRCLED NUMBER TEN | |
| 追加の黒丸囲み白数字 | |||
| U+24FF | ⓿ | NEGATIVE CIRCLED DIGIT ZERO | |
このブロックの小分類は「丸囲み数字」(Circled numbers)、「括弧囲み数字」(Parenthesized numbers)、「ピリオド付き数字」(Numbers period)、「括弧囲みラテン文字」(Parenthesized Latin letters)、「丸囲みラテン文字」(Circled Latin letters)、「追加の丸囲み数字」(Additional circled number)、「黒丸囲み白数字」(White on black circled numbers)、「二重丸囲み数字」(Double circled numbers)、「追加の黒丸囲み白数字」(Additional white on black circled number)の9つとなっている[4]。
この小分類には丸で囲前れた数字が収録されている。
この小分類には括弧で囲まれた数字が収録されている。
この小分類にはピリオドの付いた数字が収録されている。
U+1F100(囲み英数字補助ブロック)から始まる同様のシンボルも参照すること[4]。
この小分類には括弧で囲まれたラテン文字が収録されている。
U+1F100から始まる大文字セットも参照すること。括弧で囲まれたラテン文字には大文字と小文字のマッピングは存在しない[4]。
この小分類には丸で囲まれたラテン文字が収録されている。
この小分類には丸囲みの0のみが収録されている。
この小分類には黒い丸に囲まれた白い数字が収録されている。
この小分類には二重丸に囲まれた数字が収録されている。
この小分類には黒丸に囲まれた数字の0のみが収録されている。
| 囲み英数字(Enclosed Alphanumerics)[1] Official Unicode Consortium code chart (PDF) |
||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+246x | ① | ② | ③ | ④ | ⑤ | ⑥ | ⑦ | ⑧ | ⑨ | ⑩ | ⑪ | ⑫ | ⑬ | ⑭ | ⑮ | ⑯ |
| U+247x | ⑰ | ⑱ | ⑲ | ⑳ | ⑴ | ⑵ | ⑶ | ⑷ | ⑸ | ⑹ | ⑺ | ⑻ | ⑼ | ⑽ | ⑾ | ⑿ |
| U+248x | ⒀ | ⒁ | ⒂ | ⒃ | ⒄ | ⒅ | ⒆ | ⒇ | ⒈ | ⒉ | ⒊ | ⒋ | ⒌ | ⒍ | ⒎ | ⒏ |
| U+249x | ⒐ | ⒑ | ⒒ | ⒓ | ⒔ | ⒕ | ⒖ | ⒗ | ⒘ | ⒙ | ⒚ | ⒛ | ⒜ | ⒝ | ⒞ | ⒟ |
| U+24Ax | ⒠ | ⒡ | ⒢ | ⒣ | ⒤ | ⒥ | ⒦ | ⒧ | ⒨ | ⒩ | ⒪ | ⒫ | ⒬ | ⒭ | ⒮ | ⒯ |
| U+24Bx | ⒰ | ⒱ | ⒲ | ⒳ | ⒴ | ⒵ | Ⓐ | Ⓑ | Ⓒ | Ⓓ | Ⓔ | Ⓕ | Ⓖ | Ⓗ | Ⓘ | Ⓙ |
| U+24Cx | Ⓚ | Ⓛ | Ⓜ | Ⓝ | Ⓞ | Ⓟ | Ⓠ | Ⓡ | Ⓢ | Ⓣ | Ⓤ | Ⓥ | Ⓦ | Ⓧ | Ⓨ | Ⓩ |
| U+24Dx | ⓐ | ⓑ | ⓒ | ⓓ | ⓔ | ⓕ | ⓖ | ⓗ | ⓘ | ⓙ | ⓚ | ⓛ | ⓜ | ⓝ | ⓞ | ⓟ |
| U+24Ex | ⓠ | ⓡ | ⓢ | ⓣ | ⓤ | ⓥ | ⓦ | ⓧ | ⓨ | ⓩ | ⓪ | ⓫ | ⓬ | ⓭ | ⓮ | ⓯ |
| U+24Fx | ⓰ | ⓱ | ⓲ | ⓳ | ⓴ | ⓵ | ⓶ | ⓷ | ⓸ | ⓹ | ⓺ | ⓻ | ⓼ | ⓽ | ⓾ | ⓿ |
備考
|
||||||||||||||||
このブロックには、1文字の絵文字(U+24C2)が収録されている[5][6]。これは丸囲みのMで、地下鉄(metro)を表す[7]。また、マスクワーク(半導体デバイスのチップ上の配置)を表す[8]。
この文字に対し2種類の異体字セレクタ、絵文字表示(U+FE0F VS16)かテキスト表示(U+FE0E VS15)が適用できる。デフォルトはテキスト表示である[9]。
| U+ | 24C2 |
| base code point | Ⓜ |
| base+VS15 (text) | Ⓜ︎ |
| base+VS16 (emoji) | Ⓜ️ |
以下の表に挙げられているUnicode関連のドキュメントには、このブロックの特定の文字を定義する目的とプロセスが記録されている。
| バージョン | コードポイント[a] | 文字数 | L2 ID | WG2 ID | ドキュメント |
|---|---|---|---|---|---|
| 1.0.0 | U+2460..24EA | 139 | (to be determined) | ||
| L2/11-438[b][c] | N4182 | Edberg, Peter (2011-12-22), Emoji Variation Sequences (Revision of L2/11-429) | |||
| 3.2 | U+24EB..24FE | 20 | L2/99-238 | Consolidated document containing 6 Japanese proposals, (1999-07-15) | |
| N2093 | Addition of medical symbols and enclosed numbers, (1999-09-13) | ||||
| 4.0 | U+24FF | 1 | L2/01-480 | Muller, Eric (2001-12-14), Proposal to add NEGATIVE CIRCLED DIGIT ZERO | |
| L2/02-193 | Muller, Eric (2001-12-14), Proposal to add Negative Circled Digit Zero | ||||
(C. から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2024/08/11 23:36 UTC 版)
著作権マーク(ちょさくけんマーク)またはコピーライトマークとは、大文字のCを丸で囲んだ記号(©)であり、音声録音[1]以外の作品の著作権表示に使用される記号である。
この記号の使用は、アメリカ合衆国の著作権法[2]や、国際的には万国著作権条約[3]に規定されている。ただし、ベルヌ条約の下では登録・納入・著作権表示等の形式的手続がなくても著作物が創作された時に著作権が発生するという無方式主義が採用されたため、ほとんどの国で著作権マークによる明示をしなくても著作権を得ることができる[4]。
作品の著作権を示す記号の先駆は、1670年代のスコットランドの年鑑に見られる。その書籍には、その真正性を示すための紋章が印刷されていた[5]。
著作権の発生要件について、登録、納入、著作権表示など一定の方式を備えることを要件とする立法例を方式主義という[6]。
著作権表示は、アメリカ合衆国の1802年の著作権法によって初めて規定された[7]。それは、"Entered according to act of Congress, in the year , by A. B., in the office of the Librarian of Congress, at Washington."( 年、ワシントンにある議会図書館司書の事務所にA. B.が議会制定法に従って記入した。)のように長いものであった。一般に、著作権表示は著作権で保護された作品自体に表示されていなければならなかったが、絵画のような美術作品の場合には、美術作品が設置されるべき物体の表面に刻印されていてもよい[8]。1874年、"Copyright, 18 , by A. B."と大幅に短縮された表示でも可能とするよう著作権法が改正された[9]。
著作権マーク©は、1909年の著作権法(Copyright Act of 1909)第18条[10]で導入され、最初は絵画、グラフィック、彫刻作品にのみ適用された[11]。1954年、出版された著作物にもこの記号の使用が拡大された[11][12]。
1909年の著作権法は、既存の著作権法を完全に書き直し、改訂することを意図していた。この法案の草案で最初に提案されたように、著作権の保護を受けるためには、芸術作品そのものに"copyright"という文言またはその認可された略語を入れることが要求された。この芸術作品には絵画も含まれていたが、額縁は取り外し可能であることから議論が起こった。1905年と1906年に行われた法案についての著作権保持者間の会議では、芸術家組織の代表者はこの要件に反対し、作品自体に作者名以外の文言を書くことを望まなかった。妥協案として、作品自体に書かれる作者名の横に、比較的邪魔されない記号(大文字のCを丸で囲んだ記号)を書き足す案が出された[13]。実際に、ハーバート・パトナム議会図書館司書の指導の下、著作権委員会がまとめた1906年の議会に提出された法案は、特別な著作権マーク、丸で囲まれた文字Cを、"copyright"やその略語"copr."の代わりに使用することができるが、それは芸術作品などの限られたカテゴリについてのみ使用でき、通常の書籍や定期刊行物は含まれないとしている[14]。1909年の著作権法は、1946年に合衆国法典第17号に組み込まれた時点でも変更されなかった。1954年の改正で、全ての著作物について記号©が"Copyright"または"Copr."の代替として許可された[12]。
1886年に締結されたベルヌ条約は1908年のベルリンでの改正条約で無方式主義を採用した[15]。無方式主義とは著作物が創作された時点で何ら方式を必要とせず著作権の発生を認める立法例をいう[4]。
ベルヌ条約締結後もアメリカ合衆国や中南米諸国の一部などは同条約に加盟せず方式主義をとっていた[15][6]。そこで1952年の万国著作権条約は無方式主義を採る国における著作物が方式主義を採る国でも著作権保護を得ることができるよう、氏名と最初の発行年、©のマークの3つを著作権表示として明示すれば自動的に著作権の保護を受けることができるとした[16](万国著作権条約では©マークは代替の記号ではなく著作権表示の要件の一つである[16])。
その後、1989年にアメリカ合衆国がベルヌ条約に加盟したほか中南米諸国も次々にベルヌ条約に加盟し無方式主義に移行した[16]。ベルヌ条約の加盟国では、著作権を確立するのに著作権表示を行う必要はなく、著作物の作成時に自動的に著作権が確立する[17](ベルヌ条約と万国著作権条約の双方に加盟している場合には万国著作権条約17条によりベルヌ条約が優先する[18])。ほとんどの国がベルヌ条約に加盟しているため、著作権の発生要件としての著作権表示を必要としなくなった。
アメリカ合衆国では、1989年3月1日以前には以下の形式の著作権表示が必要とされた[19]。
例えば、2011年に初めて出版された作品の場合は、以下のようになる。
以上の表示は、かつてアメリカ合衆国で著作権保護を受けるために必要だったが、ベルヌ条約に加盟している国では必要ない[17]。アメリカ合衆国は1989年3月1日にベルヌ条約に加盟した[20]。ただし、万国著作権条約の適用を受けるためには今も©マークを用いた方式をとる必要がある[16]。
なお、条約上の著作権の発生要件の問題とは別に著作権表示は国内法上一定の効果を生じることがある。アメリカの著作権法では著作権の存在を知らずパブリックドメインと信じた者を保護する善意の侵害者(innocent infringers)の法理があるが、©マーク等の著作権表示が著作物に明確に表示されていれば原則として善意の侵害には当たらないとされている[16]。
タイプライターやASCIIベースのコンピュータシステムでは、この記号は長らく利用できなかったため、括弧を使い(C)と表現するのが一般的だった。
Unicodeでは、U+00A9 © copyright sign (HTML: © ©)として割り当てられている[21]。Unicodeには他にU+24B8 Ⓒ
circled latin capital letter c (HTML: Ⓒ)とU+24D2 ⓒ
circled latin small letter c (HTML: ⓒ)もある[22]。これらは、著作権マークがフォントや文字セットで利用できない場合(一部の朝鮮語コードページなど)に代替として使用されることがある。
Windowsでは、⎇ Altを押しながら0 1 6 9を押すことで入力できる。Macintoshでは、オプションキーを押しながらgを押すことで入力できる。Linuxでは、compose O Cのコンポーズキーシーケンスで入力できる。
| 記号 | Unicode | JIS X 0213 | 文字参照 | 名称 |
|---|---|---|---|---|
| © | U+00A9 |
- |
©© |
COPYRIGHT SIGN |
 ) - 著作権マークを左右反転させた記号であり、コピーレフトのシンボルとして使用される。法的には意味を持たない[23]。
) - 著作権マークを左右反転させた記号であり、コピーレフトのシンボルとして使用される。法的には意味を持たない[23]。
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2021/08/19 16:39 UTC 版)
金融街の資金が無くなり、さらに金融街の影響範囲内にある人間全ての未来をミダスマネーに変換し尽くした時に発生する現象。いわゆる「市場閉鎖」であり、金融街と共に影響範囲内にある人間や土地が「存在しなかった」ことになり消滅する。また、「C」により国が消滅するとその影響を受け他国の経済状況の改変が起こる。これは、作中では『「C」の連鎖』と呼ばれている。Calamity、Catastrophe、Chaos、Clash、Crisis、Collapse等の頭文字からアントレには「C」と呼ばれる。本編ではカリブとシンガポールの金融街が「C」により消滅している。
※この「C(シー)」の解説は、「C (アニメ)」の解説の一部です。
「C(シー)」を含む「C (アニメ)」の記事については、「C (アニメ)」の概要を参照ください。
C.と同じ種類の言葉
固有名詞の分類