
「Pythonに興味がある」「プログラミングを勉強してみたい」そんな方におすすめの本連載。
今回は『お菓子』を題材に、最適な選択肢を見つけるためのツールを作ります!Excelと組み合わせて、楽しくはじめられる内容です。
手順の紹介だけではなく、読むだけでも「なるほど!」と思っていただけるよう、ポイントもやさしく解説しています。
今回つくるもの
◆マウスのドラッグ操作で条件を絞り込み!選択肢最適化ツール
Excelは表計算ソフトであるため、データベースとしてさまざまな特徴を記録するのが得意です。しかし、さまざまな特徴を一望して人間が最適な条件を選択するのはいつでも困難な作業となります。ここではExcelに記録した「お菓子候補」のデータを題材に、平行座標図という図を描いて今の気分に最も合うお菓子を選ぶ方法を紹介します。
今回の題材はお菓子ですが、業務データに置き換えることでロジカルに選択肢を絞り込むことができるので、職場でも重宝されるスキルとなるはずです!
- 複数データの関係性が一目でわかるグラフを作ろう
・平行座標図とは?
・Excelのフィルターより何がうれしい? - Pythonプログラミングの準備
・Pythonプログラミング環境の構築
・必要なライブラリのインストール - サンプルのExcelファイルについて
- Python×Excelで実践!
・最小構成で平行座標図をプロットする - 応用編!絞り込んだ結果を出力するPythonコード
・import文
・イベント処理・出力処理の準備
・選択範囲の読み取り
・絞り込んだ結果を表示させる
・表示の更新 - 全体のコードはこちらから
1.複数データの関係性が一目でわかるグラフを作ろう
■平行座標図とは?
平行座標図は、多変数データを一望するための可視化手法です。 下図に平行座標図の例を示します。
平行座標図は価格、量、カロリー…といったパラメータを平行に書き、それぞれのデータを線(ポリライン)で結ぶことでデータの関係性を一望できる可視化手法です。
多数のデータがあると線がより密になり、人が表データを見ながら関係性を分析するのは至難の業です。平行座標図を使うことで複雑なパラメータの組み合わせを俯瞰し、直感的に最適なデータを探すことが可能になります。
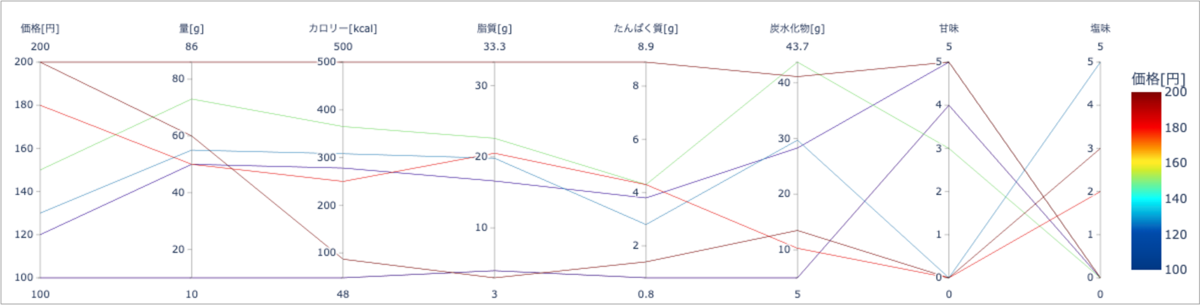
さらにPythonでPlotlyという外部ライブラリを使うことで誰でも簡単にインタラクティブなグラフを描くことができます。
ここでは実際にマウスでパラメータの範囲を調整しながら、結果がどうなっていくかをリアルタイムで確認する方法を紹介します。
■Excelのフィルターより何がうれしい?
Excelのオートフィルターでも似たようなパラメータの絞り込みはできます。しかし、次のような場面では少し面倒です。
- 複数の条件を行ったり来たりしながら調整したい
- 「AかつBかつC…」の複合条件で“全体感”を見ながら決めたい
- 条件に合わない候補がどの軸で落ちたのか、直感的に把握したい
平行座標図は、条件の調整と可視化が同じ画面で完結します。
候補を減らしながら「どこがボトルネックか?」を見られるので、パラメータ調整の効率が一段上がります。
2. Pythonプログラミングの準備
■Pythonプログラミング環境の構築
Pythonプログラミングの環境は「最速でPython環境を構築してプログラミングをはじめよう」を参照してください。リンク先にはPythonのインストール方法、プログラムの記述・実行方法、外部ライブラリのインストール方法をまとめています。
▼第0回:最速でPython環境を構築してプログラミングをはじめよう
■必要なライブラリのインストール
以下の5つの外部ライブラリをインストールしておきましょう。
(1)Pandas
PandasはPythonでExcelを扱うときに便利な外部ライブラリです。次のコマンドでインストールしましょう。 Pandasをインストールすると、依存ライブラリであるNumPyもインストールされます。 pip install pandas
(2)openpyxl
openpyxlはPandasでExcelを読み込むときに必要です。以下のコマンドでインストールしましょう。pip install openpyxl
(3)Plotly
PlotlyはWebブラウザ上で動く“操作できるグラフ”を描けるライブラリです。今回の平行座標図のプロットで使います。
以下のコマンドでインストールしましょう。 pip install plotly
(4)ipywidgets
ipywidgetsはJupyterLabのノートブック上で 動くウィジェットを提供する外部ライブラリです。今回はPlotlyの対話操作をPython側で受け取り、結果表示を更新するのに使います。
以下のコマンドでインストールしましょう。 pip install ipywidgets
(5) anywidget
本記事ではPlotlyのFigureWidgetクラスを使ってインタラクティブな操作を行いますが、Plotly 6.xからanywidgetを使うようになりました。
以下のコマンドでインストールしましょう。 pip install anywidget
外部ライブラリのインストールが終了したら、以下のコマンドを入力して、JupyterLabを立ち上げましょう。 立ち上がったら、Notebookと書かれている下にあるPython 3のアイコンをクリックします。

3. サンプルExcelのファイルについて
今回は「今日のおやつ」を題材にします。Excelに候補データを記録し、Pythonで読み込みます。
この記事のコードで使用できるサンプルファイルをダウンロードできるようにしましたので、必要な方はこちらからダウンロードしてご利用ください。
▼クリックするとファイルがダウンロードされます。
https://www.r-staffing.co.jp/rasisa/wp-content/uploads/2026/03/okashi_sample.csv
ファイルに記載のデータはExcelで入力し、csvファイルに変換しています。このファイルをプログラム実行フォルダの直下に置いてください。
本サンプルファイルはA列に「お菓子名」、B列「価格」、C列からG列に「カロリー」「脂質」「たんぱく質」「炭水化物」といった栄養素の数値が入力されています。また、H列とI列はそれぞれ「甘味」と「塩味」が5段階評価で入力されています。
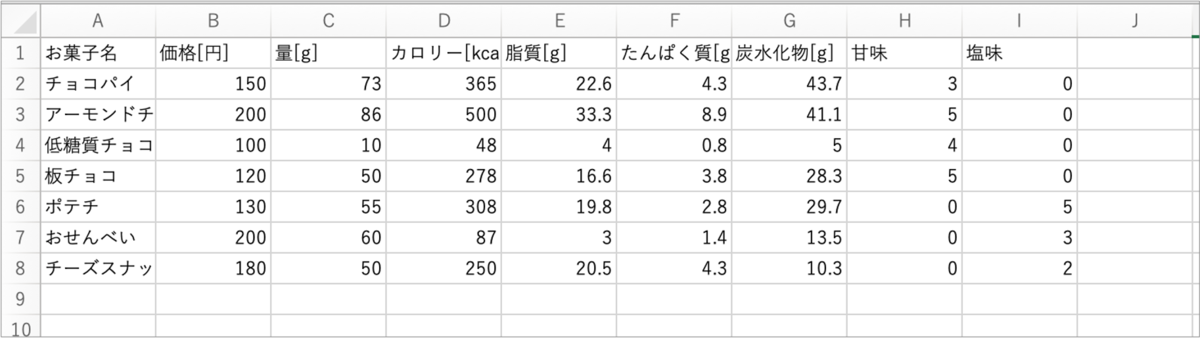
今回紹介するコードを使って、「量は多い方が良いけど、カロリーは抑えたいな」や「カロリーは抑えたいけど、しょっぱいお菓子が食べたいな」といった複数の条件を同時に満たすお菓子を探しましょう。
4. Python×Excelで実践!
ここからPythonで作っていきます。
最終的には、ブラウザで開けるHTMLファイルを生成し、そこでドラッグ操作による絞り込みを行います。
■最小構成で平行座標図をプロットする
より使いやすい処理を実装する前に、まずは最小構成で平行座標図をプロットするコードを紹介します。
次のコードをJupyter Labのセルにコピーして実行してみましょう。
import pandas as pd
import plotly.express as px
CSV_PATH = "okashi_sample.csv"
NAME_COL = "お菓子名"
COLOR_COL = "価格[円]"
# CSV読み込み
df = pd.read_csv(CSV_PATH, encoding="shift_jis")
# 平行座標図に使う列を決める(名前列以外を数値軸として扱う)
num_cols = [c for c in df.columns if c != NAME_COL]
# 平行座標図をプロット
fig = px.parallel_coordinates(
df,
dimensions=num_cols,
color=COLOR_COL,
color_continuous_scale="jet",
)
# 表示
fig.show()
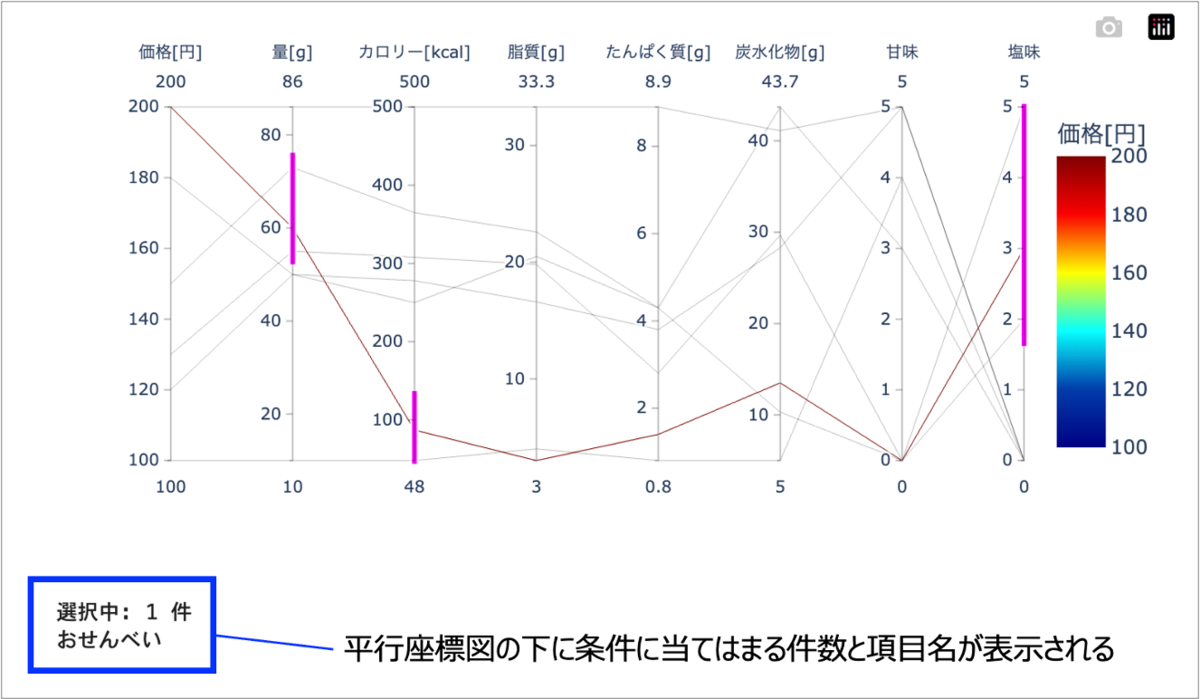
CSV_PATHはcsvファイルの名前を設定します。もし自分の好きなファイルがあればそのパスを記載してください。NAME_COLは名前列とする列名を設定します。今回のファイルでは「お菓子名」がA1セルに書かれており、その列を名前列としました。COLOR_COLは平行座標図で色を付けたい項目名です。上の方の画像に示しているように、今回のサンプルでは「価格」にカラーバーを設定しました。num_colsはPythonのリスト内包表記で書かれていますが、これはdfというデータフレーム(表データ全体)の内、先ほど設定した名前列以外の列をnum_colsというリストにまとめる処理をしています。dfでデータフレーム全体を引数として渡し、dimentionsに平行座標図に表示する列num_colsを設定します。そして色を付ける列COLOR_COLをcolorに設定し、色パターンをcolor_continuous_scaleに設定します。ここではjetというカラーマップを設定していますが、平行座標図の場合はviridisもよく使われます。コードを実行するとセル上に平行座標図が表示されます。次の図は「量」「カロリー」「塩味」の各軸をマウスでドラッグした結果です。青矢印の方向にドラッグすると、ピンク色の線が軸上に現れますが、この色の範囲がデータの範囲を意味しています。
各軸でドラッグをしていくと、ドラッグ範囲から外れたポリラインは色が薄くなります。つまり、最後まで残ったポリラインが条件に合致するデータということになります。
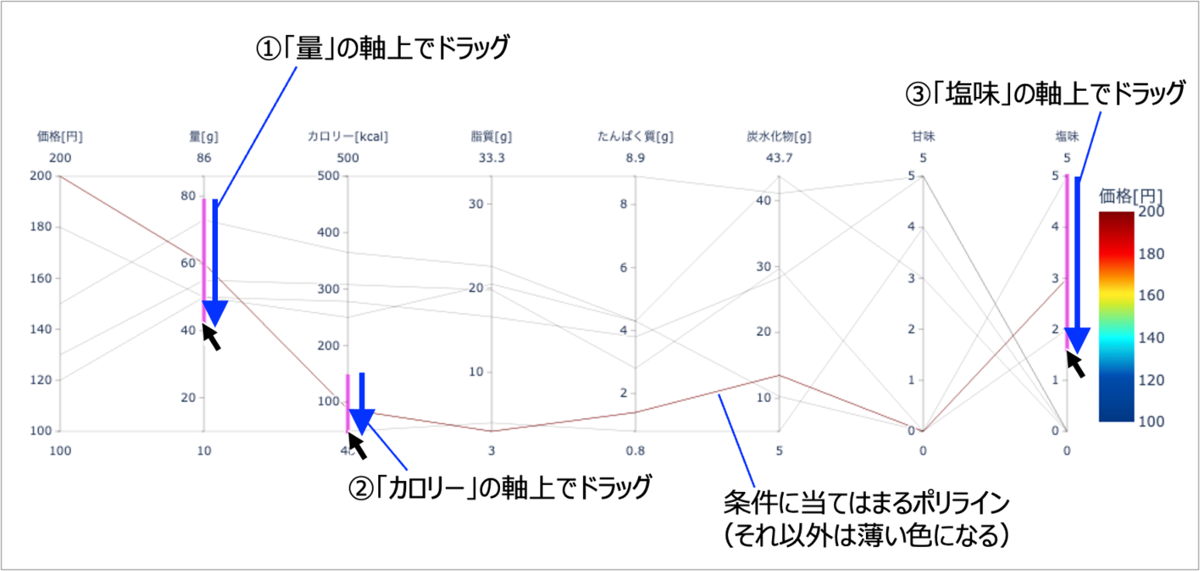
この操作は「量はこのくらい欲しい。でもカロリーは低めで、あとしょっぱいお菓子が食べたい!」という要望を可視化しています。
Plotlyでプロットした平行座標図はインタラクティブに操作できるため、データを見ながら絞り込み操作ができるので非常に便利です。
ちなみに一度ドラッグして設定した範囲は、もう一度ピンクのラインをワンクリックすればキャンセルされます。
5. 応用編!絞り込んだ結果を出力するPythonコード
先ほどまでのコードは平行座標図を表示してインタラクティブにデータを絞り込むことはできていましたが、残ったポリラインが何なのかは表示されていませんでした。
平行座標図で絞り込んだ結果は、最低限何が選ばれているかを出力したいところです。そのためここではリアルタイムに選択されている項目を表示する機能を実装する方法を紹介します。
■import文
まずはplotly.graph_object、IPythonからdisplay、また先ほどpip installしたipywidgetsをimportします。これらは、ノートブック上でPlotlyの対話操作(範囲変更など)をPython側で受け取って処理し、表示(出力)を更新するために必要です。
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go # 追加
from IPython.display import display # 追加
import ipywidgets as widgets # 追加
CSV_PATH = "okashi_sample.csv"
〜略〜
■イベント処理・出力処理の準備
Plotlyの対話操作をPythonで受け取れるようにするためにgo.FigureWidgetを、受け取った結果をノートブック上で表示(更新)するためにwidgets.Outputを用意します。
〜略〜
# 平行座標図をプロット
base_fig = px.parallel_coordinates(
df,
dimensions=num_cols,
color=COLOR_COL,
color_continuous_scale="jet",
)
# FigureWidget化 # ここから追加
fig = go.FigureWidget(base_fig)
# 選択中候補を表示する出力領域
out = widgets.Output() # ここまで追加
〜略〜
■選択範囲の読み取り
続いてユーザーがドラッグで選択した範囲を読み取るために、mask_from_fig関数を追加します。少々長いですが、POINTで解説します。
〜略〜
# FigureWidget化
fig = go.FigureWidget(base_fig)
# 選択中候補を表示する出力領域
out = widgets.Output()
def mask_from_fig(): # ここから追加
"""選択範囲を読み取る"""
# 最初は全行をTrueとしてスタート
mask = pd.Series(True, index=df.index)
# 平行座標図の各軸(dim)と、対応する列名(num_cols)をセットで処理する
for dim, col in zip(fig.data[0].dimensions, num_cols):
# 選択範囲の読み取り
cr = dim.constraintrange
# 絞り込み設定がされていない場合 -> 何もしない
if cr is None or cr == []:
continue
# 複数範囲の場合(複数範囲が結合されている場合も含む) -> [[lo,hi], [lo,hi], ...] 形式として処理
if isinstance(cr[0], (list, tuple)):
in_any = pd.Series(False, index=df.index)
for lo, hi in cr:
in_any |= df[col].between(lo, hi)
# 他の軸条件(mask)とも両方満たす必要があるので AND で合成
mask &= in_any
# その他:単一範囲の場合 -> [lo, hi] 範囲内の行だけ残す(ANDで合成)
else:
lo, hi = cr
mask &= df[col].between(lo, hi)
return mask # ここまで追加
最初のパターンはそもそも軸の範囲選択がされていない場合です。最初のif文がその処理をしていますが、ここでは何もしていません。
次の
if文は複数範囲の場合です。下図に示すように、平行座標図の軸は単一の範囲選択以外にも、ドラッグをしなおせば間をあけた複数範囲の設定も可能です。最後の
else文が単一選択の処理(同様に下図に示します)です。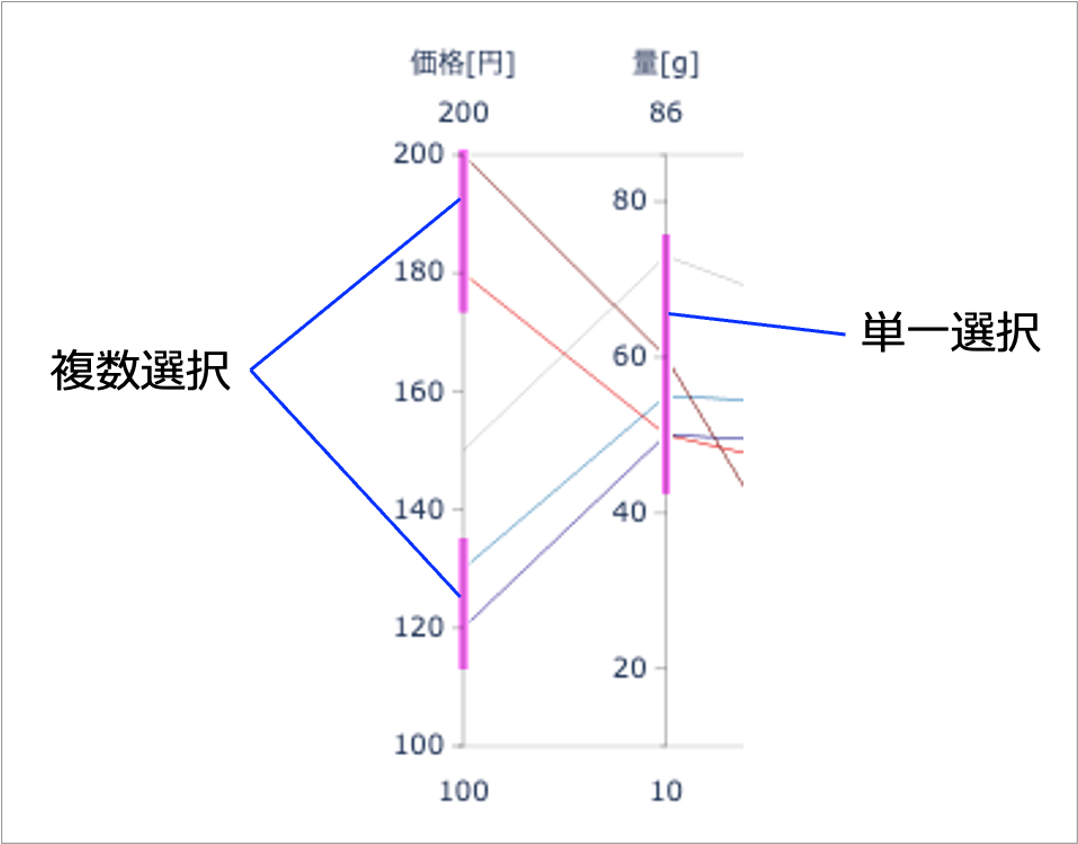
■絞り込んだ結果を表示させる
次に、絞り込んだ結果を表示させるupdate_output関数を追加しましょう。
〜略〜
return mask
def update_output(*_): # ここから追加
"""現在の絞り込み条件に合う候補名を Output に表示する。"""
mask = mask_from_fig()
names = df.loc[mask, NAME_COL].tolist()
with out:
out.clear_output()
print(f"選択中: {len(names)} 件")
for name in names:
print(name) # ここまで追加
〜略〜
*_が引数に設定されています。これは「引数は受け取るけど、使わない」という時によく使われる記法です。Plotlyからはコールバックと呼ばれる処理で情報を受け取りますが、この
update_output関数は場合によっては引数を受け取ることがあります。受け取り先のない引数を受け取ってしまうと関数はエラーを出すか、更新処理が正常に行われない現象になるので
*_を書いておきます。mask_from_fig関数を実行して、軸の選択範囲情報を受け取ります。 そして
df.loc[mask, NAME_COL].tolist()は名前列NAME_COLの列に対してmaskがTrueの行だけを抽出し、リストに変換します。 この時点でユーザーがドラッグで選択した範囲に当てはまる項目だけが抽出された状態になっています。
outはwidgets.Output()で作った “出力専用の枠” です。with out:の中でprintすると、その出力が ノートブックのウィジェット枠の中に表示されます。 withを使わないと、普通にセルの出力欄に出てしまいます。■表示の更新
最後に更新部分と表示部分を追加しましょう。これでコードは完成です。
〜略〜
for name in names:
print(name)
# 絞り込み変更時に候補一覧を更新
for dim in fig.data[0].dimensions:
dim.on_change(update_output, "constraintrange")
# 初回表示
update_output()
# 表示
display(fig, out)
コードを実行して条件を変更すると、リアルタイムで平行座標図の下に件数と条件に当てはまるお菓子の名前が表示されます。
6. 全体のコードはこちらから
この記事ではExcelで作成したcsvデータを読み込み、平行座標図を作成するPythonコードを紹介しました。
平行座標図は複数ある選択肢から最適なものを選び出す際に非常に有効な可視化手法です。選択肢やパラメータが多ければ多いほど大きな効果を出します。
今回はお菓子のデータでデモを行いましたが、実際のビジネスシーンでは製品の仕様決定、投資先の選定やマーケティング戦略の策定などさまざまな場面で活用できます。
最後に、この記事で紹介した全体のコードを載せます。パソコンで開ける方はぜひコピペして遊んでみてください。
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
from IPython.display import display
import ipywidgets as widgets
CSV_PATH = "okashi_sample.csv"
NAME_COL = "お菓子名"
COLOR_COL = "価格[円]"
# CSV読み込み
df = pd.read_csv(CSV_PATH, encoding="shift_jis")
# 平行座標図に使う列を決める(名前列以外を数値軸として扱う)
num_cols = [c for c in df.columns if c != NAME_COL]
# 平行座標図をプロット
base_fig = px.parallel_coordinates(
df,
dimensions=num_cols,
color=COLOR_COL,
color_continuous_scale="jet",
)
# FigureWidget化
fig = go.FigureWidget(base_fig)
# 選択中候補を表示する出力領域
out = widgets.Output()
def mask_from_fig():
"""選択範囲を読み取る"""
# 最初は全行をTrueとしてスタート
mask = pd.Series(True, index=df.index)
# 平行座標図の各軸(dim)と、対応する列名(num_cols)をセットで処理する
for dim, col in zip(fig.data[0].dimensions, num_cols):
# 選択範囲の読み取り
cr = dim.constraintrange
# 絞り込み設定がされていない場合 -> 何もしない
if cr is None or cr == []:
continue
# 複数範囲の場合(複数範囲が結合されている場合も含む) -> [[lo,hi], [lo,hi], ...] 形式として処理
if isinstance(cr[0], (list, tuple)):
in_any = pd.Series(False, index=df.index)
for lo, hi in cr:
in_any |= df[col].between(lo, hi)
# 他の軸条件(mask)とも両方満たす必要があるので AND で合成
mask &= in_any
# その他:単一範囲の場合 -> [lo, hi] 範囲内の行だけ残す(ANDで合成)
else:
lo, hi = cr
mask &= df[col].between(lo, hi)
return mask
def update_output(*_):
"""現在の絞り込み条件に合う候補名を Output に表示する。"""
mask = mask_from_fig()
names = df.loc[mask, NAME_COL].tolist()
with out:
out.clear_output()
print(f"選択中: {len(names)} 件")
for name in names:
print(name)
# 絞り込み変更時に候補一覧を更新
for dim in fig.data[0].dimensions:
dim.on_change(update_output, "constraintrange")
# 初回表示
update_output()
# 表示
display(fig, out)
メーカー勤務機械系エンジニア。WATLABブログ運営者。工学計算に関する知識の習得を目指し、Pythonの学習を2019年からはじめる。仕事以外にも、趣味のプログラミングやPythonコミュニティへの参加を行っている。また、月間数万PVのPythonブログ「WATLAB」を立ち上げ、初心者向けに図を多くしたわかりやすい記事を作成・公開している。著書は『いきなりプログラミング Python』(翔泳社)。
ブログ:https://watlab-blog.com/
※本記事に記載されている会社名、製品名はそれぞれ各社の商標および登録商標です。
※本稿に記載されている情報は2026年2月時点のものです。

