機械学習モデルの予測結果を返す簡単なAPIサーバーを作成する機会があったので、勉強も兼ねてPythonのFastAPIと、AWSのlambdaを使ってサーバレスな推論APIを作成してみました。
今回のコードはこちらになります。
GitHub - kojiro0208/ml-api-lambda
ディレクトリ構成
├── Dockerfile ├── README.md ├── app │ ├── app.py -- APIスクリプト │ └── train.py --モデル作成スクリプト └── requirements.txt
ネットワーク構成
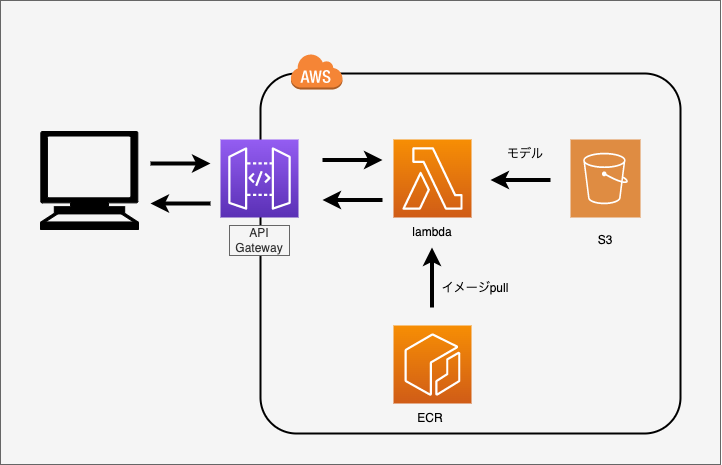
上記のような構成で作成しました。APIgatewayをトリガーにして、lambdaを起動します。lambdaはECRから、dockerイメージをpullし、機械学習モデルをS3から取得します。
リクエストがあったタイミングのみ実行されるため、常にサーバーを立ち上げておく必要がなく、サーバーレスな機械学習推論APIとなっています。
学習モデルの作成とS3へのアップロード
まずは、肝心の機械学習モデルを作成します。今回はシンプルに、部屋の広さ(RM)と築年数(AGE)から家賃を予測する重回帰モデルを作成しました。モデルをpickle形式で保存し、S3へアップロードしています。 実行には、AWSのアカウントとawscliの事前設定が必要です。
import pandas as pd import pickle import boto3 from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression def main(): boston = load_boston() X = pd.DataFrame(boston.data, columns=boston.feature_names) # 部屋の広さと築年数を使う X = X[["RM", "AGE"]] y = boston.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123) mod = LinearRegression() mod.fit(X_train, y_train) # モデルの保存 with open("boston.model", "wb") as f: pickle.dump(mod, f) # バケット作成 BUCKET_NAME = "my-boston-model" session = boto3.Session() s3_client = session.client("s3") location={'LocationConstraint': 'ap-northeast-1'} # バケットがすでにあればエラーになる。 try: s3_client.create_bucket(Bucket=BUCKET_NAME, CreateBucketConfiguration=location) except: pass # S3にアップロード s3_client.upload_file("boston.model", BUCKET_NAME, "boston.model") if __name__ == "__main__": main()
FastAPIでAPI作成
続いて、PyhotnでAPIを作成するためのライブラリFastAPIを使って、APIを作っていきます。FastAPIの使い方は公式チュートリアルがわかりやすいです!
動作確認のためのgetメソッドhealthと、家賃予測のためのpostメソッドpredictを作成しました。
import pickle import pandas as pd from fastapi import FastAPI from pydantic import BaseModel from mangum import Mangum from boto3 import Session from typing import List app = FastAPI() class Features(BaseModel): RM:float AGE:float @app.get("/health") async def get_health(): return {"message": "OK"} @app.post("/predict") async def post_predict(features:List[Features]): # S3からモデル読み込み session = Session() s3client = session.client("s3") model_obj = s3client.get_object(Bucket="my-boston-model", Key="boston.model") model = pickle.loads(model_obj["Body"].read()) # PUTされたjsonをpndasに整形 rm_list = [feature.RM for feature in features] age_list = [feature.AGE for feature in features] df_feature = pd.DataFrame({ "RM" :rm_list, "AGE":age_list }) # 予測結果をjsonに変換 pred = model.predict(df_feature) responce = [{"predict":p} for p in pred] return responce handler = Mangum(app)
FastAPIの良いところは、APIのドキュメントを自動で作成してくれるところにあります。
uvicornを使って以下のコマンドを実行し、http://127.0.0.1:8000/docsへアクセスすると、APIのドキュメントを見ることができます。
さらにドキュメントだけでなく、動作の確認を行うこともできます。
$ uvicorn app.app:app --reload

dockerイメージの作成
続いて、lambdaで、pythonを動作させるためにdockerイメージを作成します。 lambda-pythonのベースイメージもありますが、機械学習関連のライブラリーが動かないことがあるので、独自イメージを作成しました。 また、イメージサイズを小さくするため、マルチステージビルドを採用しています。(参考: Lambda コンテナイメージの作成 - AWS Lambda )
FROM python:3.8-buster AS builder
# 各種パッケージをインストール
COPY requirements.txt .
RUN pip install awslambdaric && \
pip install -r requirements.txt
# マルチステージビルドを使う。
FROM python:3.8-slim-buster
ARG APP_DIR="/home/app/"
# 実行スクリプトのコピー
COPY app/app.py ${APP_DIR}/app.py
WORKDIR ${APP_DIR}
COPY --from=builder /usr/local/lib/python3.8/site-packages /usr/local/lib/python3.8/site-packages/
ENTRYPOINT [ "/usr/local/bin/python", "-m", "awslambdaric" ]
CMD [ "app.handler" ]
dockerファイルを作成したら、ECRにプッシュします。ECRには予め、api-lambdaというリポジトリを作成しておきました。「プッシュコマンドの表示」というところから、コマンドの実行方法が確認できますので、その通りに実行します。

# {userid}はAWSのアカウントID
# ログイン
aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin {userid}.dkr.ecr.ap-northeast-1.amazonaws.com
# ビルド
$ docker build -t api-lambda .
$ docker tag api-lambda:latest {userid}.
dkr.ecr.ap-northeast-1.amazonaws.com/api-lambda:latest
# ecrへpush
$ docker push {userid}.dkr.ecr.ap-northeast-1.amazonaws.com/api-lambda:latest
lambdaとAPIgatewayの作成
ここまでできたら、あと一息です。lambdaをECRのコンテナイメージから作成し、APIgatewayをトリガーにします。
lambdaの作成や、APIgatewayの作成については、いろいろなところで解説がされているので省きます。(すみません、、)

実行テスト
pythonからrequestsを使って、実行テストしてみます。
import requests import pandas as pd url = "https://ya1azte7nl.execute-api.ap-northeast-1.amazonaws.com/api-lambda" get = "/health" post = "/predict" # getのテスト res = requests.get(url+get) print(res.text) >{"message":"OK"} # postテスト features = pd.DataFrame({"RM":[5, 10, 20], "AGE":[0, 20, 30]}) features_json = [{"RM":r, "AGE":a} for r, a in zip(features["RM"], features["AGE"])] res = requests.post(url+post, json=features_json) print(res.json()) >[{'predict': 16.24435278824622}, {'predict': 58.18648647429676}, {'predict': 144.2419374598331}]
うまくできていそうです!
まとめ
今回は、サーバレスな推論APIを作ってみました。簡単なAPIであれば、エンジニアでなくても簡単にできてしまうのがクラウドサービスを使うメリットですね!
※本記事は筆者が個人的に学んだこと感じたことをまとめた記事になります。所属する組織の意見・見解とは無関係です。
参考
FastAPI+AWS Lamndaでサーバレスアプリケーションの作成方法|Tech Press | テックプレス
【AWS Lambda】独自のコンテナイメージを超シンプルに使用する方法 - Qiita
