この記事はエムスリー Advent Calendar 2025 2日目 兼 マネジメントチームブログリレー9日目の記事です。

こんにちは、エンジニアリンググループ General Manager 兼 基盤チームリーダーの横本(@yokomotod)です。
今回はgoroutineについての自由研究です。
「軽量」「何万個も作れる」「並行処理が簡単に書ける」...そんなgoroutineの裏側はどうなっているんでしょうか。
- なぜOSスレッドより「軽い」の?
- グリーンスレッドとは違うの?
- なぜパフォーマンスが高いと言われるの?
この記事では、goroutineのようなランタイムをRustで自作することで、これらの疑問に答えることを目指しました。
ソースコードの全体は以下のリポジトリで公開しています。
なぜRust?
「Goの話なのになぜRust?」と思われるかもしれませんが
- GoはOSスレッドを(ほぼ)直接操作できない
- 自作スケジューラの下に、本物のGoスケジューラが動く、という状況を避ける
といった理由でRustを採用しました。
Rustのイディオムがわからなくても、雰囲気で「何をやっているか」は掴めるように書いたつもりなので、普段Rustは触っていない方もご安心ください*1。
また、ちょっとアセンブリも出てきますがインラインアセンブリを書きやすいのもRustの強みです。
なお動作確認はLinux/macOS (x86_64, aarch64) + Rust 2024 edition (v1.91.1)で行っています。
OSスレッドは重い、のおさらい
手始めに「goroutineは軽い」で対比される「OSスレッドは重い」をちょっと体感しておきましょう。
OSスレッドで10万個のタスクを作ってみます。
// examples/os_thread_many.rs use std::thread; use std::time::Duration; fn main() { let mut handles = vec![]; for i in 0..100_000 { // 10万個のスレッドを生成 let handle = thread::spawn(move || { let _ = i * 2; thread::sleep(Duration::from_secs(10)); }); handles.push(handle); } // 全スレッドの終了を待つ for handle in handles { handle.join().unwrap(); } }
実行してみると...
$ cargo run --release --example os_thread_many
[ 0.000s] Spawning many tasks with OS threads...
[ 0.479s] Spawned 1000 threads...
[ 1.038s] Spawned 2000 threads...
...
[ 18.862s] Spawned 18000 threads...
thread 'main' panicked at library/std/src/thread/mod.rs:727:29:
failed to spawn thread: Os { code: 11, kind: WouldBlock, message: "Resource temporarily unavailable" }
筆者の環境では18,000スレッドあたりでクラッシュしました*2。
OSスレッドが「重い」と言われる理由は主に以下の2つです。
- カーネル処理のオーバーヘッド: スレッド生成・破棄・切り替えのたびにカーネル空間への遷移が発生
- メモリ消費のオーバーヘッド: スレッドごとに数MB(Linuxでは通常スタックサイズは8MB)。10万スレッド × 8MB = 800GB…
「もっと軽量にたくさんのタスクを扱いたい」を解決するのが、カーネルに頼らずユーザー空間でスケジューリングを行うグリーンスレッドです。
グリーンスレッドを作ってみる
完成イメージ
goroutineっぽく、こんな風に使えるものを作ります。
// examples/m1_demo.rs use mygoroutine::m1::{go, gosched, start_runtime}; fn main() { go(|| { println!("Task 1: start"); gosched(); // 他のタスクに実行を譲る println!("Task 1: end"); }); go(|| { println!("Task 2: start"); gosched(); println!("Task 2: end"); }); go(|| { println!("Task 3: start"); gosched(); println!("Task 3: end"); }); start_runtime(); // 全タスクを実行 }
go() でタスクを登録し、start_runtime() で実行。gosched() を呼ぶと他のタスクに実行を譲ります*3。
$ cargo run --release --example m1_demo Starting runtime... Task 1: start Task 2: start Task 3: start Task 1: end Task 2: end Task 3: end All tasks completed!
タスクの途中で他のタスクが実行できています。
M:1モデル
最初につくるのは、すべて(M個)のタスクを1つのOSスレッドで実行するM:1モデルです。
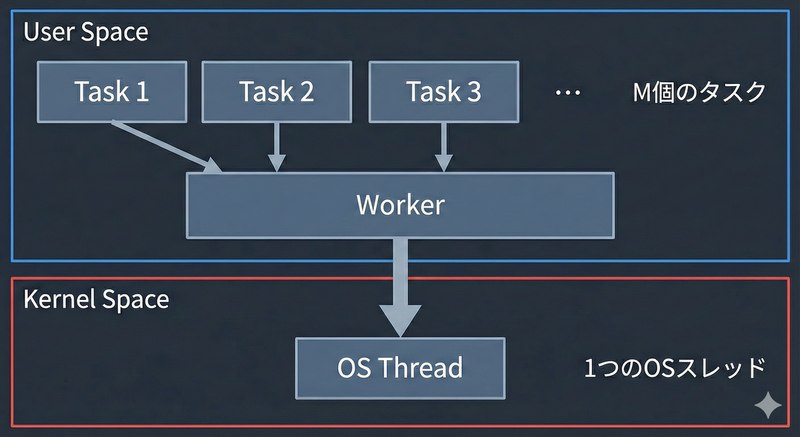
OSスレッドの生成コストを払わずに、ユーザー空間でタスクを切り替えるようにします。
さて、どうやって「タスクを切り替える」のでしょうか?
実装
コンテキストスイッチ
詳細に説明するとここだけで記事にできてしまうのでごく簡単にいきます*4。
タスクを切り替えるために必要なことは、「今どこまで実行して、どういう状態か」を保存しておいて、別のタスクの続きから再開することです。
そして「今どこまで実行して、どういう状態か」とはつまり「CPUレジスタの値」と「スタック領域の値」になります。
- レジスタの値(CPU上)
- スタックポインタ(rsp): 今のスタックの位置
- フレームポインタ(rbp): 現在のスタックフレームの基点
- 汎用レジスタ(rbx, r12〜r15): 計算途中の値
- スタック領域の値(RAM上)
- 関数のローカル変数・戻りアドレスなど
これらを保存して、保存しておいた別の状態を復元すれば、タスクを「途中で止めて、後で続きから再開」できるわけです。
ただしRustから直接レジスタは触れません。そこで インラインアセンブリ機能の出番です。
アセンブリが出てきますが、雰囲気で「なんかゴリッと入れ替えているな」とだけ理解してもらえれば大丈夫です*5。
// src/arch/x86_64.rs /// 保存するCPUコンテキスト #[repr(C)] pub struct Context { rsp: u64, // スタックポインタ rbp: u64, // フレームポインタ rbx: u64, // 以下汎用レジスタ r12: u64, r13: u64, r14: u64, r15: u64, } /// old のコンテキストを保存し、new のコンテキストに切り替える #[unsafe(naked)] pub extern "C" fn context_switch(_old: *mut Context, _new: *const Context) { // ここではrdi レジスタが第1引数、rsiが第2引数を表す // オフセットで構造体のフィールドを指定 // movはレジスタ間で値を移動する命令 naked_asm!( // 現在のレジスタを old に保存 "mov [rdi + 0x00], rsp", "mov [rdi + 0x08], rbp", "mov [rdi + 0x10], rbx", "mov [rdi + 0x18], r12", "mov [rdi + 0x20], r13", "mov [rdi + 0x28], r14", "mov [rdi + 0x30], r15", // new からレジスタを復元 "mov rsp, [rsi + 0x00]", "mov rbp, [rsi + 0x08]", "mov rbx, [rsi + 0x10]", "mov r12, [rsi + 0x18]", "mov r13, [rsi + 0x20]", "mov r14, [rsi + 0x28]", "mov r15, [rsi + 0x30]", // 復元先にジャンプする命令 "ret", ); }
これでもう「タスクAを止めて、タスクBの続きから再開」の土台ができました*6。
Task
コンテキストを保持する箱として Task 構造体を定義します。
// src/common.rs pub struct Task { pub context: Context, pub finished: bool, }
各タスクは自分の Context と終了フラグを持ちます。
Worker
タスクを管理してスケジューリングするのが Worker です。
// src/m1.rs struct Worker { tasks: VecDeque<Task>, // 実行待ちタスクのキュー current_task: Option<Task>, // 現在実行中のタスク context: Context, // スケジューラに戻るためのコンテキスト }
Workerは以下のようなメインループを動かします。
fn worker_loop() { loop { // キューから次のタスクを取り出す let Some(task) = worker.tasks.pop_front() else { break; // タスクがなくなったら終了 }; // タスクのコンテキストに切り替え! context_switch(&mut worker.context, &task.context); // 処理がタスクに移り、タスクからまたcontext_switchされたら続きが動く if task.finished { // タスク終了、破棄 } else { // タスクはまだ終わっていない、キューの末尾に戻す worker.tasks.push_back(task); } } } pub fn start_runtime() { worker_loop(); // (ここでは意味のない関数分割ですが、後述の進化版と揃えるためです) }
gosched() は「他のタスクに処理を移しても良いよ」と伝える関数です。
pub fn gosched() { // worker_loopとは逆に、現在のタスクのコンテキストを保存し、スケジューラに戻す context_switch(&mut current_task.context, &worker.context); }
これで M:1 の グリーンスレッド ができました。
10万タスク起動
さて、OSスレッドでは18,000で死んだ10万タスク、グリーンスレッドではどうでしょうか。
// examples/m1_many.rs let start = Instant::now(); for i in 0..100_000 { // 10万個のタスクを生成 go(move || { let _ = i * 2; gosched(); // 他のタスクに実行を譲る }); if (i + 1) % 10000 == 0 { println!( "[{:>8.3}s] Spawned {} tasks...", start.elapsed().as_secs_f64(), i + 1 ); } } start_runtime(); println!( "[{:>8.3}s] Done! All {} tasks completed.", start.elapsed().as_secs_f64(), task_count );
実行ログ:
$ cargo run --release --example m1_many [ 0.252s] Spawned 10000 tasks... ... [ 3.909s] Spawned 100000 tasks... [ 4.286s] Done! All 100000 tasks completed.
10万タスク完走!
自前でスケジューリングすることで、OSスレッドの重いコストを回避できました。
M:1モデルの限界
「軽量にたくさんのタスクを扱う」は実現できました。しかし1つのOSスレッドで動いているため、マルチコアは活かせません。
試しにCPUバウンドな処理をさせてみましょう。
// examples/m1_cpu_bound.rs // CPUに負荷をかけるためのダミー計算(sum += i * i を繰り返す。コンパイラの最適化を防ぐ書き方をしている) fn cpu_work(n: u64) -> u64 { let mut sum = 0u64; for i in 0..n { sum = sum.wrapping_add(black_box(i).wrapping_mul(black_box(i))); } sum } fn main() { for i in 0..8 { go(move || { let result = cpu_work(7_500_000_000); println!("Task {}: result = {}", i, result); }); } start_runtime(); }
実行ログ:
$ cargo run --release --example m1_cpu_bound Task 0: result = 14094119455108168832 Task 1: result = 14094119455108168832 ... Task 7: result = 14094119455108168832 Elapsed: 30.790867851s
約30秒。htop で見ると、1コアしか使えていないのがわかります。

M:Nモデル
M:Nモデルは、M個のタスクをN個のOSスレッドで実行するモデルです。
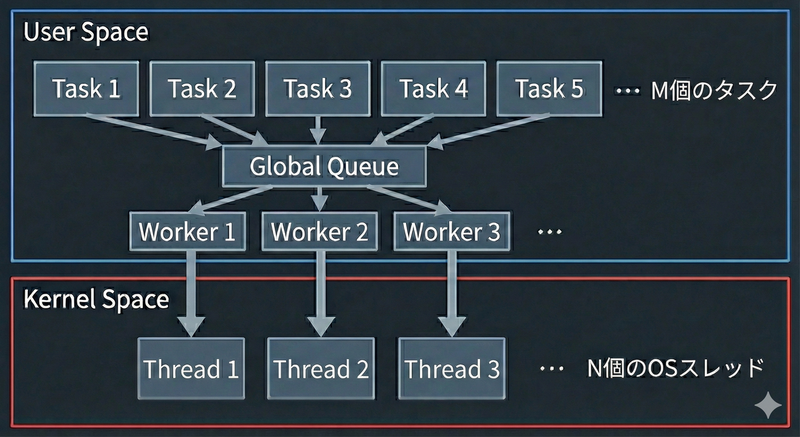
各ワーカー(OSスレッド)がキューからタスクを取り出して実行することでマルチコアを活用できるようにします。
実装
複数ワーカースレッド
M:1モデルではそのまま worker_loop() していましたが、複数のワーカー分をそれぞれスレッドで起動するようにします。
// src/mn.rs pub fn start_runtime(num_threads: usize) { let mut handles = Vec::new(); // 指定した数のワーカースレッドを起動 for worker_id in 0..num_threads { let handle = thread::spawn(move || { worker_loop(worker_id); }); handles.push(handle); } // 全ワーカーの終了を待つ for handle in handles { handle.join().unwrap(); } }
グローバルキューの分離と排他制御
全Workerが同じキューを共有するようにします*7。複数スレッドからアクセスするので、Mutex で排他制御も必要です。
// src/mn.rs // 全ワーカーで共有するタスクキュー struct GlobalQueue { tasks: VecDeque<Task>, // 実行待ちタスク } static GLOBAL_QUEUE: OnceLock<Mutex<GlobalQueue>> = OnceLock::new();
各ワーカーはロックを取ってタスクを取り出します。
// src/mn.rs fn worker_loop(worker_id: usize) { let queue = global_queue(); loop { // グローバルキューからタスクを取得 let task = { let mut q = queue.lock().unwrap(); if let Some(task) = q.tasks.pop_front() { task } else { break; // タスクがなくなったら終了 } }; // タスクを実行... worker.current_task = Some(task); context_switch(&mut worker.context, &task.context); // タスクから処理が戻ってきた if let Some(task) = worker.current_task.take() && !task.finished { // タスクはまだ終わっていない、キューの末尾に戻す queue.lock().unwrap().tasks.push_back(task); } } }
これでM:Nモデルに出来ました。
ただし、意外と簡単だったのには落とし穴があります。このままだと、利用者のコードが !thread_local を使ってスレッドに値を紐付けようとすると、Taskが別のワーカー/OSスレッドで再開されたときに値がおかしくなってしまいます。
Goは言語仕様としてOSスレッド、スレッドローカルの直接利用を提供しないことで問題を避けていますが、そうでない場合は非常に難しくなります*8。ここでの実装では、問題に目を瞑っています。
CPUバウンドな処理で比較
では、M:1モデルのときと同じCPUバウンドな処理を、今度はM:Nモデル版でスレッド数=4として実行してみましょう。
// examples/mn_cpu_bound.rs const NUM_THREADS: usize = 4; fn main() { for i in 0..8 { go(move || { let result = cpu_work(7_500_000_000); println!("Task {}: result = {}", i, result); }); } start_runtime(NUM_THREADS); }
実行ログ:
$ cargo run --release --example mn_cpu_bound Task 3: result = 14094119455108168832 Task 2: result = 14094119455108168832 Task 1: result = 14094119455108168832 Task 0: result = 14094119455108168832 Task 4: result = 14094119455108168832 Task 6: result = 14094119455108168832 Task 5: result = 14094119455108168832 Task 7: result = 14094119455108168832 Elapsed: 10.784397097s
約10秒! M:1モデルのときの30秒から約3倍の高速化です。
htop を見ると、今度は複数コアが使えています。

- M:1: 軽量だけど、マルチコアを使えない
- M:N: 軽量 かつ マルチコアを活用できる
goroutineが「(古典的なM:1モデルの)グリーンスレッドじゃない」と言われるところを感じられました。
ですが、「goroutineはM:Nモデルでマルチコアが活かせるグリーンスレッドなんだ」だけで話は終わりません。
M:Nモデルの限界
CPUバウンドな処理ではM:Nの威力を実感できました。では、I/O待ちが発生するタスクの場合はどうでしょうか?
// examples/mn_blocking.rs const NUM_THREADS: usize = 4; const NUM_TASKS: usize = 32; fn main() { for i in 0..NUM_TASKS { go(move || { // ブロッキングI/Oをシミュレート thread::sleep(Duration::from_millis(100)); println!("Task {} done", i); }); } start_runtime(NUM_THREADS); }
ここでは簡単にスリープしていますが、複数のgoroutineでAPIを呼び出すとかをイメージしてください。待ちの間に順次他のタスクを実行してほぼすべて並行に動き、100ms完了してほしいですよね。
しかし今の実装で実行してみると…
$ cargo run --release --example mn_blocking [ 0.001s] Task 0 started [ 0.001s] Task 1 started [ 0.001s] Task 2 started [ 0.001s] Task 3 started [ 0.101s] Task 0 done [ 0.101s] Task 4 started ... Total elapsed: 838.388215ms
32タスクを4スレッドで実行していますが、各タスクが100ms律儀にブロックするため、約800ms(1ワーカーあたり32/4=8回sleep)かかってしまっています。
本物のGoランタイム
ネットワークI/O待ちの解決策
さきほどのブロッキングの問題を解決する方法の1つがnetwork pollerです*9。
ネットワークI/O待ちでOSスレッドをブロックしない仕組みで、Linux では epoll、macOS では kqueue を使って実装されています。
今回の実装:
goroutineがI/O待ち → OSスレッドがブロック → 他のgoroutineが実行できない
netpoller:
goroutineがI/O待ち → netpollerに登録して「待機状態」に
→ OSスレッドは別のgoroutineを実行
→ I/O完了時にnetpollerが通知、goroutineを再開
これにより、少数のOSスレッドで大量の同時接続を効率的に処理できます*10。
これがgoroutineか
epoll などを使った効率的なネットワークI/OはnginxやNode.jsなどを始め広く利用されていますが、 async/await で修飾するなど、通常の関数呼び出しとは区別が必要なランタイムが多いです*11。
一方のGoは、1つのgoroutineがブロックされてもほかのgoroutineが動き続けてくれるおかげで、ブロックが発生する関数も区別なく書くことが出来ています。
- グリーンスレッドで軽量・高速起動
- M:Nモデルでマルチコアを駆使(代わりにOSスレッドをユーザから隠蔽)
- その土台の上でネットワークI/Oを効率的に扱うことで、通常の関数呼び出しと区別せずブロッキング処理も扱える
を実現したのがgoroutineである、と言えるのではないでしょうか。
まだ他にも
ここまで触れたこと以外にも、まだまだgoroutineが持つ機能があるので紹介します。
- スタック伸長
- 本物のgoroutineは2KBという小さなスタックから始まり、必要に応じて動的に伸長することでさらにオーバーヘッドを少なくする
- G-M-Pモデル
- 各OS スレッド(M)に対してProcessor(P)という概念を導入し、Pごとにローカルキューを持たせます。これにより、Mutex競合が大幅に削減
- Work-stealing
- 暇なProcessorが他のProcessorのローカルキューからタスクを「盗む」ことで偏りを防ぐ
- 非協調的プリエンプション(Go 1.14〜*12)
- 強制的にタスクを中断させる「非協調的プリエンプション」が導入。無限ループし続けるタスクがいても他タスクに切り替え可能に
興味がある方はぜひ調べてみてください*13。
まとめ
「グリーンスレッドで軽量」かつ「M:Nモデルでマルチコアを活用」し、「I/O待ちも効率的でしかもブロッキングを区別しなくていい」。この組み合わせが今回あらためて感じられたgoroutineの「凄さ」でした。
今回の自由研究や実装で、goroutineの解像度が高まったなら幸いです。network poller部分も自作してみたい。
興味が湧いた方は、ぜひソースコードも覗いてみてください。
We are hiring!
エムスリーでは「ブラックボックスの中身を理解しようとせずにいられないギークさ」を大切にしています。機能やライブラリをただ使うだけでなく、その裏側から議論できる仲間を募集中です。
興味のある方はぜひカジュアル面談にお越しください!
*1:Rustらしい安全な書き方はあえてしておらず unsafe も多用しています。もちろん本番環境での使用は想定していません
*2:ulimitやメモリ量に大きく依存します
*3:あまり直接使うことはありませんが、Goも runtime.Gosched() が用意されています
*4:詳細は例えば「並行プログラミング入門 ―Rust、C、アセンブリによる実装からのアプローチ」 https://www.oreilly.co.jp/books/9784873119595/ でM:1モデルの実装が解説されています
*5:アーキテクチャごとにアセンブリは異なり、載せているのはx86_64向けです。aarch64 (Apple Silicon) 向けはGitHub参照
*6:本当はメモリ上のスタック領域を確保し続けるための処理がもう少しあるんですが割愛しています。完全なコードはGitHub参照
*7:各ワーカーがローカルキューを持つ設計も可能で、実際にGo言語はそうなっています
*8:実際、Rustも当初はM:N グリーンスレッドをサポートしていましたが、この問題などを理由に1:1モデルに移行しました https://rust-lang.github.io/rfcs/0230-remove-runtime.html
*9:Scheduling In Go : Part II - Go Scheduler などで詳しく解説されています
*10:逆に言うと、ファイルI/Oなどnetwork pollerで扱えないブロッキング操作については、本家GoランタイムもOSスレッドを追加で起動して対処するようです
*11:この区別は「Function Coloring 問題」と呼ばれ、過去のブログでも解説されています https://www.m3tech.blog/entry/2025/10/28/100000
