こんにちは。エンジニアリンググループのAI・機械学習チームに所属している鴨田 です。弊チームでは毎週1時間の技術共有会を実施しており、各自が担当するプロダクトの技術や、最近読んだ論文を紹介しています。今週はAAAI2026が開催されていることもあり、同学会の論文読み会となりました。1セッションにつき1名が担当し、各自が選定した論文の詳細について解説を行いました。本ブログではその一部として、セッションごとの「推し論文」を紹介します。
まだ読んでいない方は前回のICCV2025の輪読会ブログも是非ご覧になってください

- CATP: Contextually Adaptive Token Pruning for Efficient and Enhanced Multimodal In-Context Learning
- Assessing the Capabilities of LLMs in Humor: A Multi-dimensional Analysis of Oogiri Generation and Evaluation
- SplatSSC: Decoupled Depth-Guided Gaussian Splatting for Semantic Scene Completion
- StyleDrive: Towards Driving-Style Aware Benchmarking of End-To-End Autonomous Driving
- We are hiring !!
CATP: Contextually Adaptive Token Pruning for Efficient and Enhanced Multimodal In-Context Learning
- セッション: Computer Vision 1 (CV)
- 著者: Yanshu Li, Jianjiang Yang, Zhennan Shen, Ligong Han, Haoyan Xu, Ruixiang Tang
- 論文リンク:https://arxiv.org/pdf/2508.07871
- 紹介者: 鴨田 (機械学習エンジニア)

Figure 1から引用 CATPはコンテキストが注視するポイントを考慮しトークン選択を実施 推しポイント
LLMサービスはテキスト以外にも画像入力が当たり前と思えるほど様々なサービスで大規模視覚言語モデル(LVLM)が普及しています。LVLMによって高度な推論が可能になりましたが、その代償としての計算コスト、特に画像トークンの爆発的な増加は実用上の大きな課題です。この論文は、複数の画像例示から学習する「マルチモーダル・インコンテキスト学習(ICL)」を題材に、視覚情報の効率的なpruningに焦点を当てています。
従来手法はAttention Scoreの高低で削除対象を決定する方法でしたが、CATPは画像トークンを「テキストとの整合性」や「クエリ画像との相互作用」といった文脈的な次元で分析し、LLMが本当に回答に必要な視覚情報だけを動的に残せるか、を検証しています。 検証した結果、整合性や相互作用を最適化するプロセス自体が一種のノイズ除去の役割となり、pruning後の推論結果のほうが精度が良い結果も観測されました。
CATPはpruningの最適化が成功した一方でpruning最適化処理自体に時間がかかり、トークン削減量と比較してそこまで推論速度が高速化されていないのが課題です。しかし、pruningの指針自体は示すことができて、あとは処理最適化をどうするかというフェーズに進めたというのも事実なのでこの論文の功績は大きいなと感じ推薦論文としました。
Assessing the Capabilities of LLMs in Humor: A Multi-dimensional Analysis of Oogiri Generation and Evaluation
- セッション: Natural Language Processing 4 (NLP)
- 著者: Ritsu Sakabe, Hwichan Kim, Tosho Hirasawa, Mamoru Komachi
- 論文リンク: https://arxiv.org/abs/2511.09133
- 紹介者: 氏家(機械学習エンジニア)
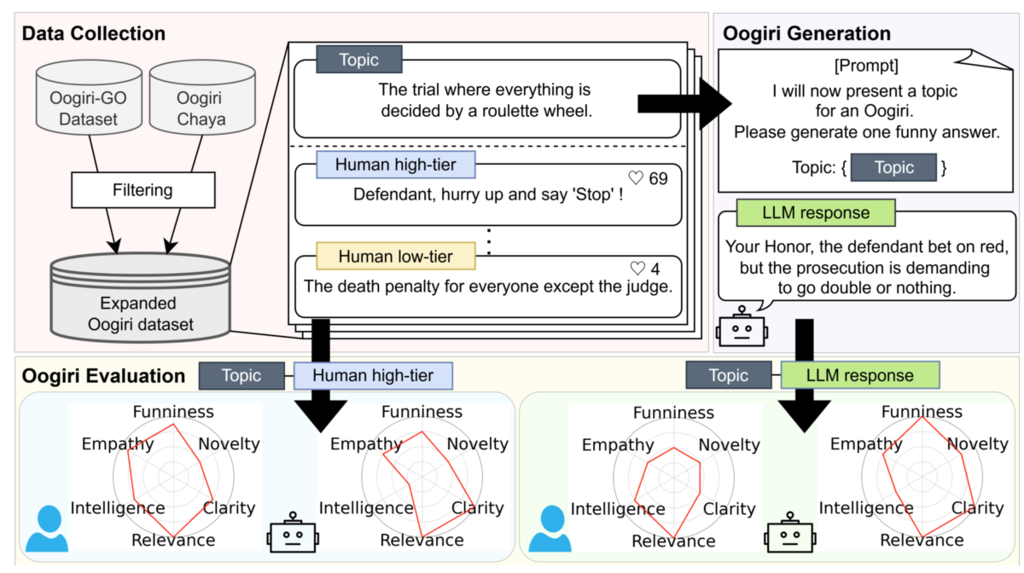
Figure 2から引用。データを集め、LLMに回答を作らせ、それを人間とLLMの双方が多角的に採点・比較する 推しポイント
昨今のLLMの有用さ、流暢性は言うまでもありませんが、知的でユーモアのある返答は人間らしいやりとりに必要な要素です。この論文は日本の「大喜利」を題材にLLMのユーモアへの能力に焦点を当てています。 単純に「面白いか否か」という1次元的な評価ではなく、大喜利の回答を「新規性」や「共感性」など6つの次元で分析し、LLMがユーモアのある回答を生成できるか、またユーモアをLLMが評価できるか、を検証しています。
GPT-4などの最新モデルは「意外なこと(新規性)」のスコアが高い一方で、人間がユーモアを評価する上で重要な「共感性(Empathy)」が欠けていることが実験的に示されました。文脈を共有する「あるある」感が不足しているため、人間の笑いのツボを捉えきれていないのです。また、自分に近いモデルを優遇するバイアス等、LLMによるユーモアの生成、評価の限界を示しています。
論文タイトルに惹かれて読み始めましたが、文脈理解を要する「共感性」がLLMにとっての鬼門であるという結果は、直感的にも納得感があり非常に興味深かったです。また、AIが自分に近いモデルを優遇してしまう傾向は、普段の業務での実感とも重なりました。ユーモア研究の枠を超えてLLM-as-a-Judgeが今後どう発展していくのか期待したいです。
推しポイント
SplatSSC: Decoupled Depth-Guided Gaussian Splatting for Semantic Scene Completion
- セッション: Computer Vision 14
- 著者: Rui Qian, Haozhi Cao, Tianchen Deng, Shenghai Yuan, Lihua Xie
- 論文リンク: https://arxiv.org/abs/2508.02261
- 紹介者: 伊吹 (ソフトウェアエンジニア)
推しポイント
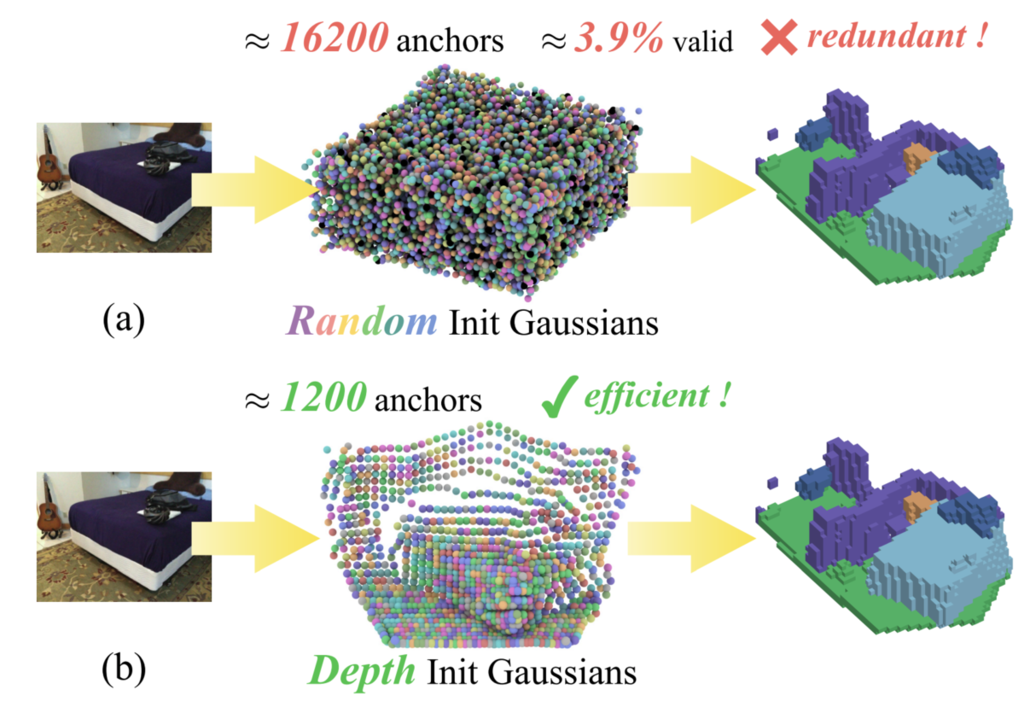
人間はある画像を見た時にその立体的な形や構造がどうなっているのかを推測できます。 それと同じように、この論文では単眼画像からの3D意味論的シーン補完という課題を解きます。 ここでは、単一のRGB画像という限定的な2次元画像から、可視領域だけではなく遮蔽(オクルージョン)により直接観測できない領域も含めたシーン全体の幾何学的構造と意味的ラベルを同時に推論します。難易度は高いですが、自動運転・ロボティクス・ARという応用分野においては重要なタスクと言えそうです。
3D再構成の分野は、Gaussian Splattingの登場により精度とレンダリング速度は大きく改善されましたが、今回のような課題の場合には「幾何学的手がかりが欠如した状態」での再構成が必要なため、より効率的な初期化と信頼性のある最適化が必要です。
2024年に登場したDepth-Anythingにより高精度な深度推定が可能になったことから、筆者たちはこれを初期化時の事前分布として機能させています。また、Gaussian Splattingでは外れ値の影響で「浮遊物」が再構成時に出現する課題がありますが、その領域の「意味」を判断する機構を工夫することでクリーンに再構成することを可能にしています。 評価実験でも既存手法に比べてIoUが6%以上改善しており、定量的にも優れていそうです。
学生時代にKinectを用いて深度計測をして人間の行動分類をする研究をしていたことがあったのですが、現在だと2次元画像からでも推定できるようになっており、進化の勢いを感じました(人間が2次元画像を見て奥行きを感じられるように、1画像でも推定できるのでは? と思っていたのが現実になっていることに、とても面白みを感じました) 自分がやや疎い分野であったのですが、論文の構成が3D再構成の歴史を辿っており、読み物としても面白かったのでこの論文を推薦します。
StyleDrive: Towards Driving-Style Aware Benchmarking of End-To-End Autonomous Driving
セッション: Computer Vision 5
著者: Ruiyang Hao; Bowen Jing; Haibao Yu; Zaiqing Nie
紹介者: 范 (機械学習エンジニア)
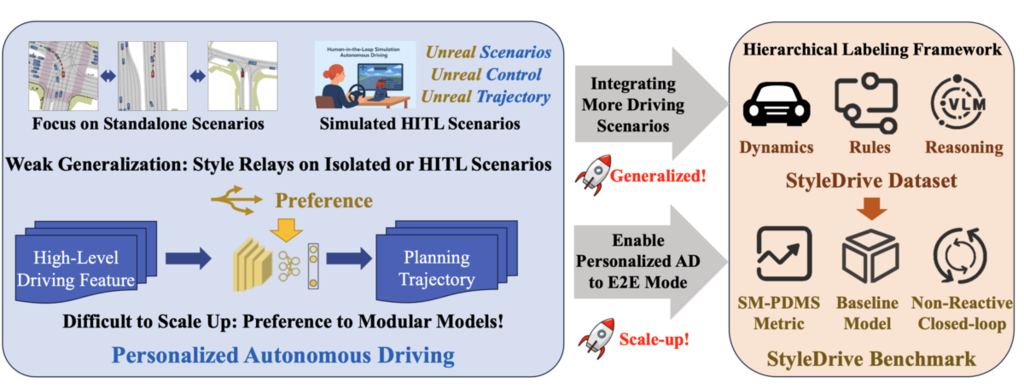
論文中Figure 1から引用。VLMや高度なアノテーション手法を統合した新しいデータセットおよびベンチマークの構想を示す
推しポイント
従来のエンドツーエンド自動運転(E2EAD)は、主に「目的地への到達」と「安全性」を目的に作られており、「運転スタイルの個別化」は考慮されていません。その結果、データが平均化される「平均への回帰」を招き、複雑な交通状況に対して挙動が優柔不断になりがちです。また、乗客が希望通りに自動運転のスタイルを指定できないため、期待と実際の車両挙動との不一致が生じ、システムへの信頼を損なう原因となります。したがって、自動運転システムに「個性」を付与することは極めて重要です。 本論文はそれを実現するために、Vision-Language Model(VLM)を活用して運転スタイルがタグ付けされた大規模な実世界データセットを構築し、新たな評価指標「Style-Modulated Predictive Driver Model Score (SM-PDMS)」を定義しました。さらに、非反応型シミュレーションに基づく評価環境「StyleDrive Benchmark」まで提案しています。 複数のモデルパラダイムにわたる広範な実験により、スタイル条件付け(Style Conditioning)が、基本的な運転能力(Core Driving Competence)を維持しつつ、行動の整合性を高める上で有効であることが実証されました。 (以下、選定理由のブラッシュアップ) 欧米と比較して、アジア諸国の交通状況は非常に複雑であり、国や地域ごとに大きな違いがあります。そのため、画一的な自動運転モデルをそのまま実装することは困難です。しかし、システムに「個性(スタイル)」を付与できれば、ユーザーの好みだけでなく、こうした地域ごとの交通文化の違いにも柔軟に適応できる可能性があります。この点に自動運転普及への大きな可能性を感じ、推薦論文とさせていただきました。
We are hiring !!
AAAIの論文の面白さにワクワクする皆さん、エムスリーAI・機械学習チームで一緒に機械学習エンジニアやりましょう! また、学生の皆さん向けには機械学習・MLOpsインターンも募集してます。ぜひ一緒にサービス開発していきましょう。
エムスリーでは、機械学習はもちろん、最新技術へのアンテナが高い仲間を歓迎しています。新卒・中途それぞれの採用、カジュアル面談やインターンも常時募集しています!
