はじめに
機械学習や統計学で登場する各種の確率分布について、「計算式の導出・計算のスクラッチ実装・計算過程や結果の可視化」などの「数式・プログラム・図」を用いた解説により、様々な角度から理解を目指すシリーズです。
この記事では、ガンマ分布の乱数とポアソン分布の関係についてR言語を使って確認します。
【前の内容】
【他の内容】
【今回の内容】
ガンマ分布からポアソン分布の生成
ガンマ分布(Gamma distribution)に従う乱数をパラメータとして用いることで、ポアソン分布(Poisson distribution)を生成します。この記事では、Rを利用して生成します。
各種の分布についてはそれぞれの「分布の定義式」、Pythonを利用する場合は「Python版」を参照してください。
利用するパッケージを読み込みます。
# 利用パッケージ library(tidyverse)
この記事では、基本的に パッケージ名::関数名() の記法を使うので、パッケージを読み込む必要はありません。ただし、作図コードについては(ごちゃごちゃしないように)パッケージ名を省略するため、ggplot2 を読み込む必要があります。
また、ネイティブパイプ(baseパイプ)演算子 |> を使います。(基本的には)magrittrパッケージのパイプ演算子 %>% に置き換えても処理できますが、その場合は magrittr を読み込む必要があります。
確率分布の生成
ガンマ分布からポアソン分布をサンプリングします。
数式の設定
形状パラメータ 、尺度パラメータ
のガンマ分布
をパラメータの生成分布とします。
生成分布からサンプル分布のパラメータ を生成します。
期待値パラメータ のポアソン分布
をサンプリングした確率分布とします。
生成分布の設定
ガンマ分布については「【R】ガンマ分布の作図 - からっぽのしょこ」や「【R】ガンマ分布の乱数生成 - からっぽのしょこ」を参照してください。
生成分布のパラメータ を設定します。
# ガンマ分布のパラメータを指定 a <- 5 b <- 2 a; b
[1] 5 [1] 2
形状に関するパラメータ(正の値) 、尺度に関するパラメータ(正の値)
を指定します。
サンプルサイズ を指定して、生成分布の乱数(サンプル分布のパラメータ)
を生成します。
# サンプルサイズを指定 N <- 6 # ガンマ分布の乱数を生成 lambda_n <- rgamma(n = N, shape = a, rate = b) |> sort() # 昇順に並べ替え # パラメータを格納 smp_data_df <- tibble::tibble( n = 1:N, # サンプル番号 lambda = lambda_n # サンプル値 ) smp_data_df
# A tibble: 10 × 2
n lambda
<int> <dbl>
1 1 1.05
2 2 1.77
3 3 1.83
4 4 1.94
5 5 2.07
6 6 2.45
7 7 2.92
8 8 4.10
9 9 4.76
10 10 5.90
サンプルサイズ(データ数) を指定します。
個のサンプル(ガンマ分布の乱数)
を作成して、サンプル分布(ポアソン分布)のパラメータ
として用います。
生成分布の確率変数 の作図範囲を設定します。
# λ軸の範囲を設定 lambda_min <- 0 #lambda_max <- 10 u <- 5 lambda_max <- (a/b) |> # 基準値を指定 (\(.) {. * 4})() |> # 倍率を指定 (\(.) {max(., lambda_n)})() |> # サンプルと比較 (\(.) {ceiling(. /u)*u})() # u単位で切り上げ # λ軸の値を作成 lambda_vec <- seq(from = lambda_min, to = lambda_max, length.out = 1001) lambda_min; lambda_max; head(lambda_vec)
[1] 0 [1] 10 [1] 0.00 0.01 0.02 0.03 0.04 0.05
この例では、変数の期待値 、またはサンプル
の最大値、の大きい方の値を使って、範囲を設定しています。
生成分布の確率密度 を計算します。
# ガンマ分布の確率密度を計算 gen_dens_df <- tidyr::tibble( lambda = lambda_vec, # 確率変数 dens = dgamma(x = lambda, shape = a, rate = b) # 確率密度 ) gen_dens_df
# A tibble: 1,001 × 2
lambda dens
<dbl> <dbl>
1 0 0
2 0.01 0.0000000131
3 0.02 0.000000205
4 0.03 0.00000102
5 0.04 0.00000315
6 0.05 0.00000754
7 0.06 0.0000153
8 0.07 0.0000278
9 0.08 0.0000465
10 0.09 0.0000731
# ℹ 991 more rows
確率密度を計算して、データフレームに格納します。
生成分布とサンプルのグラフを作成します。
# ラベル用の文字列を作成 gen_param_lbl <- paste0( "list(", "N == ", N, ", ", "a == ", a, ", ", "b == ", b, ")" ) |> parse(text = _) smp_data_lbl <- paste0( "lambda[", 1:N, "] == ", round(lambda_n, digits = 2) ) |> parse(text = _) # ガンマ分布を作図 ggplot() + geom_line( data = gen_dens_df, mapping = aes(x = lambda, y = dens), linewidth = 1 ) + # 生成分布 geom_point( data = smp_data_df, mapping = aes(x = lambda, y = 0, color = factor(n)), alpha = 0.5, size = 5 ) + # サンプル scale_color_hue(labels = smp_data_lbl) + # (凡例の表示用) guides( color = guide_legend(override.aes = list(alpha = 1, size = 4)) ) + labs( title = "Gamma distribution", subtitle = gen_param_lbl, color = "sample", x = expression(lambda), y = "density" )
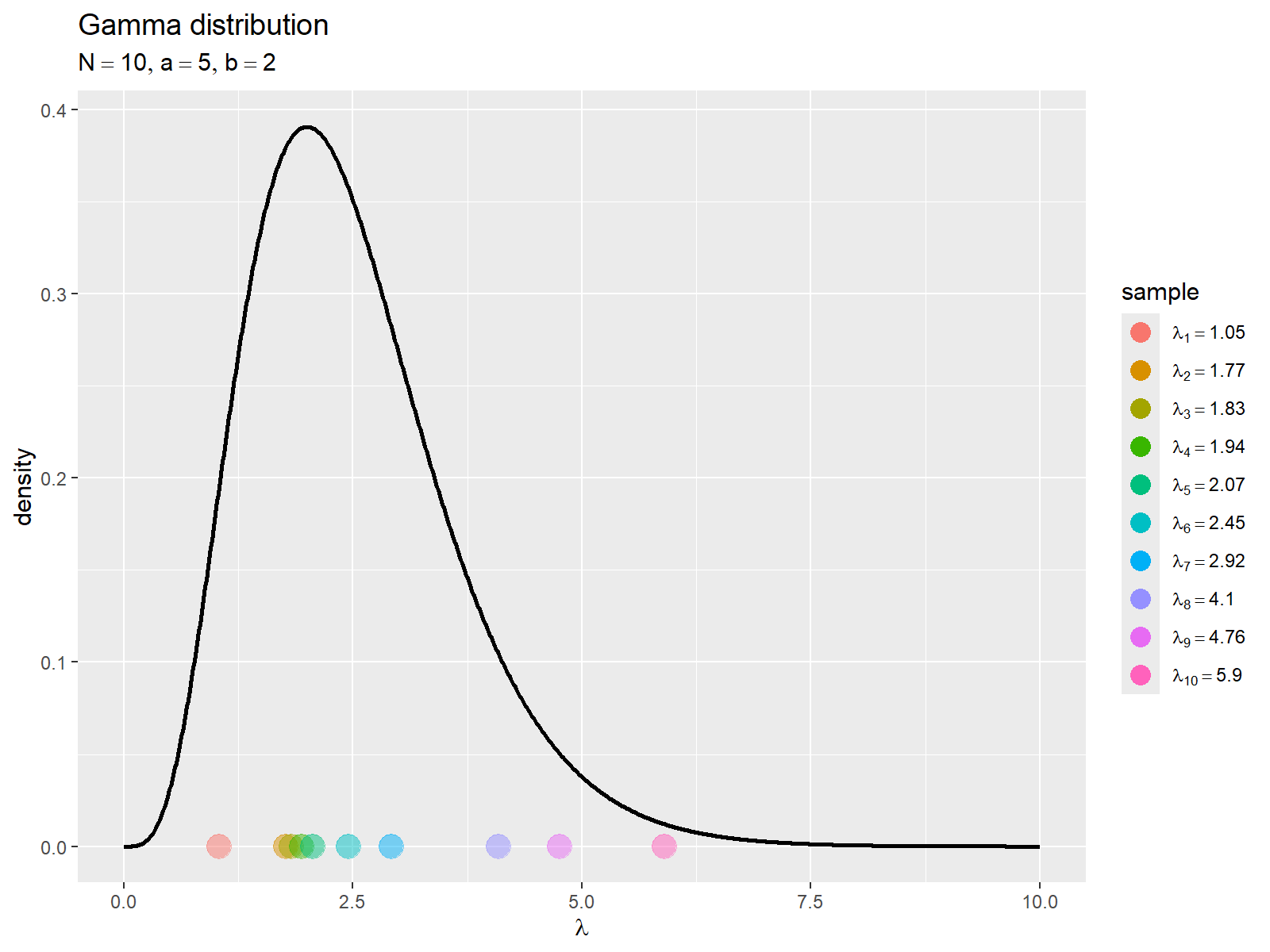
生成分布 を曲線、
個のサンプル
を色付けした点として描画します。
サンプル分布の作図
ポアソン分布については「【R】混合ポアソン分布の作図 - からっぽのしょこ」を参照してください。
サンプル分布の確率変数 の作図範囲を設定します。
# x軸の範囲を設定 x_min <- ceiling(lambda_min) x_max <- floor(lambda_max) # x軸の値を作成 x_vec <- seq(from = x_min, to = x_max, by = 1) x_min; x_max; head(x_vec)
[1] 0 [1] 10 [1] 0 1 2 3 4 5
作図の都合上、生成分布の確率変数 と近い範囲にします。
サンプル ごとにサンプル分布の確率密度
を計算します。
# ポアソン分布の確率を計算 smp_prob_df <- tidyr::expand_grid( n = 1:N, # サンプル番号 x = x_vec, # 確率変数 ) |> # サンプルごとに変数を複製 dplyr::mutate( lambda = lambda_n[n], # 期待値パラメータ prob = dpois(x = x, lambda = lambda) # 確率密度 ) smp_prob_df
# A tibble: 110 × 4
n x lambda prob
<int> <dbl> <dbl> <dbl>
1 1 0 1.05 0.352
2 1 1 1.05 0.368
3 1 2 1.05 0.192
4 1 3 1.05 0.0669
5 1 4 1.05 0.0175
6 1 5 1.05 0.00366
7 1 6 1.05 0.000637
8 1 7 1.05 0.0000951
9 1 8 1.05 0.0000124
10 1 9 1.05 0.00000144
# ℹ 100 more rows
expand_grid() により、 個のパラメータ
ごとに確率を計算して、データフレームに格納します。
サンプル分布のグラフを作成します。
# ラベル用の文字列を作成 smp_param_lbl <- paste0( "lambda[", 1:N, "] == ", round(lambda_n, digits = 2) ) |> parse(text = _) # ポアソン分布を作図 ggplot() + geom_line( data = smp_prob_df, mapping = aes(x = x, y = prob, color = factor(n)), linewidth = 1 ) + # サンプル分布 geom_point( data = smp_prob_df, mapping = aes(x = x, y = prob, color = factor(n)), size = 3 ) + # サンプル分布 scale_x_continuous(breaks = x_vec, minor_breaks = FALSE) + # x軸目盛 scale_color_hue(labels = smp_data_lbl) + # (凡例の表示用) guides( color = guide_legend(override.aes = list(linewidth = 0.5, size = 2)) ) + labs( title = "Poisson Distribution", subtitle = gen_param_lbl, color = "parameter", x = expression(x), y = "probability" )
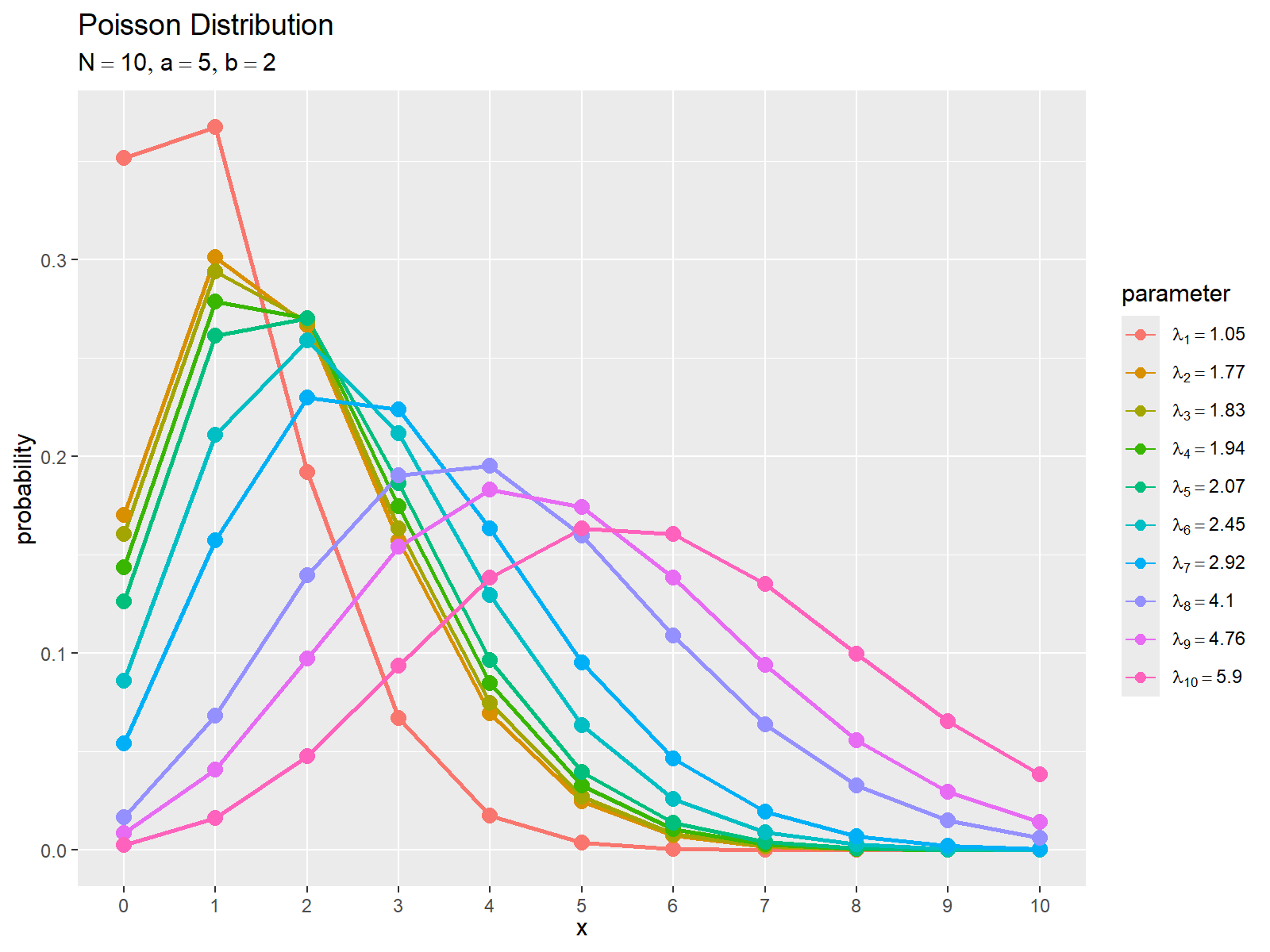
個のサンプル
を期待値パラメータとして用いたポアソン分布
を色付けした折れ線と点として描画します。
以上で、基本的な確率分布の生成の処理を確認しました。続いて、生成分布のサンプルとサンプル分布の関係を図で確認します。
スポンサードリンク
サンプルとパラメータの対応関係
生成分布とサンプル分布の対応関係を図で表します。
・作図コード(クリックで展開)
## 生成分布の作図 # 生成分布のラベルを作成 gen_param_lbl <- paste0( "list(", "a == ", a, ", ", "b == ", b, ")" ) |> parse(text = _) # サンプルのラベルを作成 smp_data_lbl <- paste0( "lambda[", 1:N, "]" ) |> parse(text = _) # 生成分布を作図 gen_graph <- ggplot() + geom_vline( data = smp_data_df, mapping = aes(xintercept = lambda, color = factor(n)), linewidth = 1, linetype = "dotted", show.legend = FALSE ) + # サンプルの位置 geom_line( data = gen_dens_df, mapping = aes(x = lambda, y = dens, linetype = "generator"), linewidth = 1 ) + # 生成分布 geom_point( data = smp_data_df, mapping = aes(x = lambda, y = 0, color = factor(n)), size = 5 ) + # サンプル scale_x_continuous( sec.axis = sec_axis( trans = ~ ., breaks = lambda_n, labels = smp_data_lbl, ) # サンプルのラベル ) + scale_linetype_manual( breaks = "generator", values = "solid", labels = gen_param_lbl, name = "generator" ) + # (凡例表示用) guides( color = "none", linetype = guide_legend(override.aes = list(linewidth = 0.5)) ) + coord_cartesian( xlim = c(lambda_min, lambda_max) ) + # (軸の対応用) labs( title = "Gamma distribution", subtitle = parse(text = paste0("N == ", N)), x = expression(lambda), y = expression(p(lambda ~"|"~ a, b)) ) ## サンプル分布の作図 # サンプル分布のラベルを作成 smp_param_lbl <- paste0( "lambda[", 1:N, "] == ", round(lambda_n, digits = 2) ) |> parse(text = _) # サンプル分布を作図 smp_graph <- ggplot() + geom_vline( data = smp_data_df, mapping = aes(xintercept = lambda, color = factor(n)), linewidth = 1, linetype = "dotted", show.legend = FALSE ) + # サンプルとの対応 geom_line( data = smp_prob_df, mapping = aes(x = x, y = prob, color = factor(n)), linewidth = 1 ) + # サンプル分布 geom_point( data = smp_prob_df, mapping = aes(x = x, y = prob, color = factor(n)), size = 3, shape = "circle open" ) + # サンプル分布 scale_x_continuous( breaks = x_vec, minor_breaks = FALSE, # x軸目盛 sec.axis = sec_axis( trans = ~ ., breaks = lambda_n, labels = smp_data_lbl, ) # サンプルのラベル ) + scale_color_hue(labels = smp_param_lbl) + # (凡例の表示用) guides( color = guide_legend(override.aes = list(linewidth = 0.5, size = 2)) ) + coord_cartesian( xlim = c(lambda_min, lambda_max) ) + # (軸の対応用) labs( title = "Gaussian distribution", color = "sample", x = expression(x), y = expression(p(x ~"|"~ lambda[n])) ) ## 対応関係の作図 # グラフを並べて描画 comb_graph <- cowplot::plot_grid( gen_graph, smp_graph, nrow = 2, ncol = 1, align = "hv" # (グラフ位置のズレ対策用) ) comb_graph
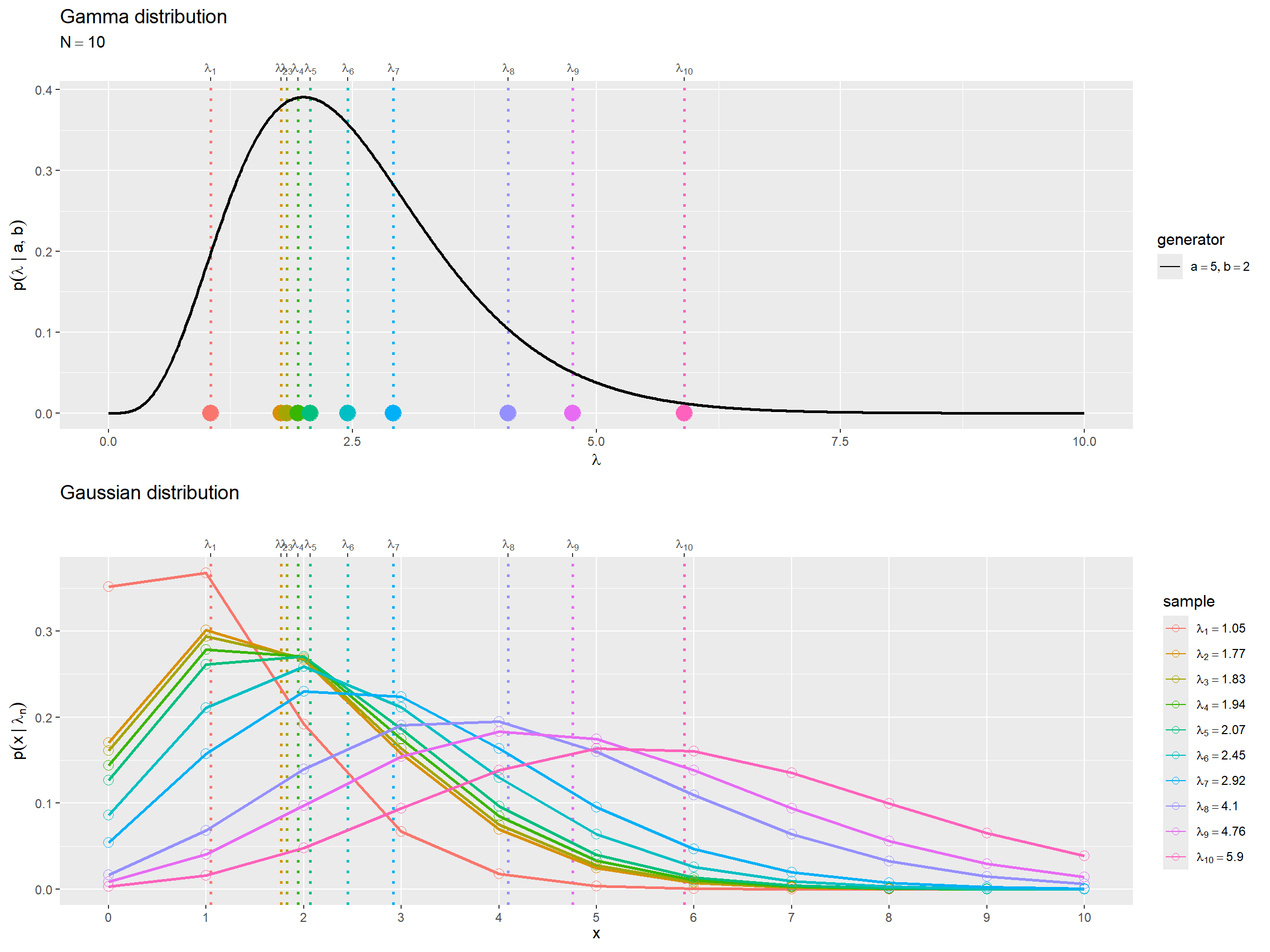
パラメータの生成分布(ガンマ分布)のサンプル と、サンプル分布(ポアソン分布)の期待値(期待値パラメータ)
が、一致するのを確認できます。
スポンサードリンク
ハイパーパラメータの影響
次は、生成分布のパラメータ(ハイパーパラメータ・超パラメータ)の値を少しずつ変化させて、生成分布とサンプル分布のグラフの変化をアニメーションで確認します。
作図コードについては「Probability-Distribution/code/gamma/generate_poisson.R at main · anemptyarchive/Probability-Distribution · GitHub」を参照してください。
ハイパーパラメータとサンプル分布の関係
生成分布(ガンマ分布) における累積確率が等間隔になるように
個のパラメータ(サンプル)
を作成し、それぞれを期待値パラメータとする
個のサンプル分布(ポアソン分布)
を描画して、ハイパーパラメータ
を変化させます。
また、生成分布の期待値と、期待値をパラメータとするサンプル分布を赤色の破線で示します。
形状パラメータ を変化させたときの生成分布とサンプル分布の変化をアニメーションにします。
が大きくなるほど、生成分布のサンプル・サンプル分布の期待値
が大きくなりやすくなるのが分かります。また
が大きくなるほど、サンプル分布の分散も大きくなるのが分かります。
尺度パラメータ による変化をアニメーションにします。
が大きくなるほど、生成分布のサンプル・サンプル分布の期待値
が小さくなりやすくなるのが分かります。
以上で、ハイパーパラメータの影響を確認しました。
この記事では、ガンマ分布からポアソン分布を生成しました、次の記事では、1次元ガウス分布を生成します。
参考文献
おわりに
- 2022.07.20:加筆修正の際に「ガンマ分布の作図」から記事を分割しました。
- 2025.11.04:加筆修正の際にこの記事から「ガンマ分布から1次元ガウス分布の精鋭」を分割しました。
内容的にはあまり変わっていませんが、patchwork から cowplot に変更したり、アニメーションを追加したり、作図周りで更新しました。
まぁ、分かりやすさというよりもほとんど趣味です。
【次の内容】
