はじめに
『ベイズ推論による機械学習入門』(MLSシリーズ)の独学時のノートです。各種のモデルやアルゴリズムについて「数式・プログラム・図」を用いて解説します。
本の補助として読んでください。
この記事では、平均が未知の1次元ガウス分布に対するベイズ推論をR言語でスクラッチ実装します。
【前節の内容】
【他の節の内容】
【この節の内容】
3.3.1 1次元ガウス分布のベイズ推論の実装:平均が未知の場合
1次元ガウスモデル(Gaussian model)に対するベイズ推論(Bayesian inference)を実装して、人工的に生成したデータを用いて、パラメータの学習と未知変数の予測を行う。この記事では、生成分布の平均パラメータ(mean parameter)が未知の場合を扱う。平均が未知の1次元ガウスモデルでは、尤度関数を1次元ガウス分布(Gaussian distribution・一変量正規分布・Normal distribution)、事前分布を1次元ガウス分布とする。この記事では、Rを利用して実装する。
1次元ガウスモデルについては「3.3.0:1次元ガウスモデルの生成モデルの導出【緑ベイズ入門のノート】 - からっぽのしょこ」、ベイズ推論については「3.3.1:1次元ガウス分布のベイズ推論の導出:平均が未知の場合【緑ベイズ入門のノート】 - からっぽのしょこ」、Pythonを利用する場合は「【Python】3.3.1:1次元ガウス分布の学習と予測:平均が未知の場合【緑ベイズ入門のノート】 - からっぽのしょこ」を参照のこと。
利用するパッケージを読み込む。
# 利用パッケージ library(tidyverse)
この記事では、基本的に パッケージ名::関数名() の記法を使うので、パッケージの読み込みは不要である。ただし、作図コードについては(ごちゃごちゃしないように)パッケージ名を省略するため、ggplot2 を読み込む必要がある。
また、ネイティブパイプ演算子 |> を使う。(基本的には)magrittrパッケージのパイプ演算子 %>% に置き換えられるが、その場合は magrittr を読み込む必要がある。
ベイズ推論の実装
まずは、平均が未知の1次元ガウス分布に対するベイズ推論における一連の処理を確認する。
生成モデル(平均が未知の1次元ガウスモデル)を設定して、モデルに従うデータ(トイデータ)を生成する。続いて、生成した観測データを用いて、事後分布の計算(パラメータの推定)を行う。さらに、事後分布のパラメータ(または観測データ)を用いて、予測分布の計算(未観測データの予測)を行う。
生成分布の設定
データの生成分布(真の分布・ガウス分布) のパラメータ(真のパラメータ)
を設定する。
は既知とする。
ガウス分布については「【R】1次元ガウス分布の作図 - からっぽのしょこ」を参照のこと。
生成分布のパラメータ を設定する。
# 真のパラメータを指定 mu_truth <- 25 # 既知のパラメータを指定 lambda <- 0.01 mu_truth; lambda; 1/sqrt(lambda)
[1] 25 [1] 0.01 [1] 10
ガウス分布の平均パラメータ(実数) 、精度パラメータ(正の値)
を指定する。
がガウスモデルにおける真のパラメータであり、この値を求めるのがここでの目的(学習)である。
生成分布の確率変数 の作図範囲を設定する。
# x軸の範囲を設定 #x_min <- -15 #x_max <- 65 k <- 4 u <- 5 x_size <- (1/sqrt(lambda)) |> # 基準値を指定 (\(.) {. * k})() |> # 定数倍 #(\(.) {max(., abs(x_n-mu_truth))})() |> # サンプルと比較 (\(.) {ceiling(. /u)*u})() # u単位で切り上げ x_min <- mu_truth - x_size x_max <- mu_truth + x_size # x軸の値を作成 x_vec <- seq(from = x_min, to = x_max, length.out = 1001) x_min; x_max; head(x_vec)
[1] -15 [1] 65 [1] -15.00 -14.92 -14.84 -14.76 -14.68 -14.60
この例では、指定したパラメータ(または生成したデータ)を使って、範囲を設定している。
生成分布の確率密度を計算する。
# 生成分布の確率密度を計算:式(2.64) model_df <- tibble::tibble( x = x_vec, # 確率変数 mu = mu_truth, # 平均パラメータ lambda = lambda, # 精度パラメータ sigma = 1/sqrt(lambda), # 標準偏差パラメータ dens = dnorm(x = x, mean = mu, sd = sigma) # 確率密度 ) model_df
# A tibble: 1,001 × 5
x mu lambda sigma dens
<dbl> <dbl> <dbl> <dbl> <dbl>
1 -15 25 0.01 10 0.0000134
2 -14.9 25 0.01 10 0.0000138
3 -14.8 25 0.01 10 0.0000143
4 -14.8 25 0.01 10 0.0000147
5 -14.7 25 0.01 10 0.0000152
6 -14.6 25 0.01 10 0.0000157
7 -14.5 25 0.01 10 0.0000162
8 -14.4 25 0.01 10 0.0000167
9 -14.4 25 0.01 10 0.0000173
10 -14.3 25 0.01 10 0.0000178
# ℹ 991 more rows
の値ごとに、ガウス分布に従う確率密度
を計算する。
ガウス分布の確率密度関数 dnorm() の確率変数の引数 x に 、平均の引数
mean に 、標準偏差の引数
sd に を指定する。
生成分布のグラフを作成する。
# 生成分布のラベルを作成 model_param_lbl <- paste0( "list(", "mu[truth] == ", round(mu_truth, digits = 2), ", ", "lambda == ", round(lambda, digits = 5), ")" ) |> parse(text = _) # 生成分布を作図 ggplot() + geom_line( data = model_df, mapping = aes(x = x, y = dens, color = "model"), linewidth = 1 ) + # 真の分布 scale_color_manual( breaks = "model", values = "red", labels = "true model", name = "" ) + # (凡例表示用) guides( color = guide_legend(override.aes = list(linewidth = 0.5)) ) + theme( legend.title = element_text(size = 0), legend.position = "inside", legend.position.inside = c(1, 1), legend.justification = c(1, 1), legend.background = element_rect(fill = alpha("white", alpha = 0.8)) ) + labs( title = "Gaussian distribution", subtitle = model_param_lbl, x = expression(x), y = "density" )
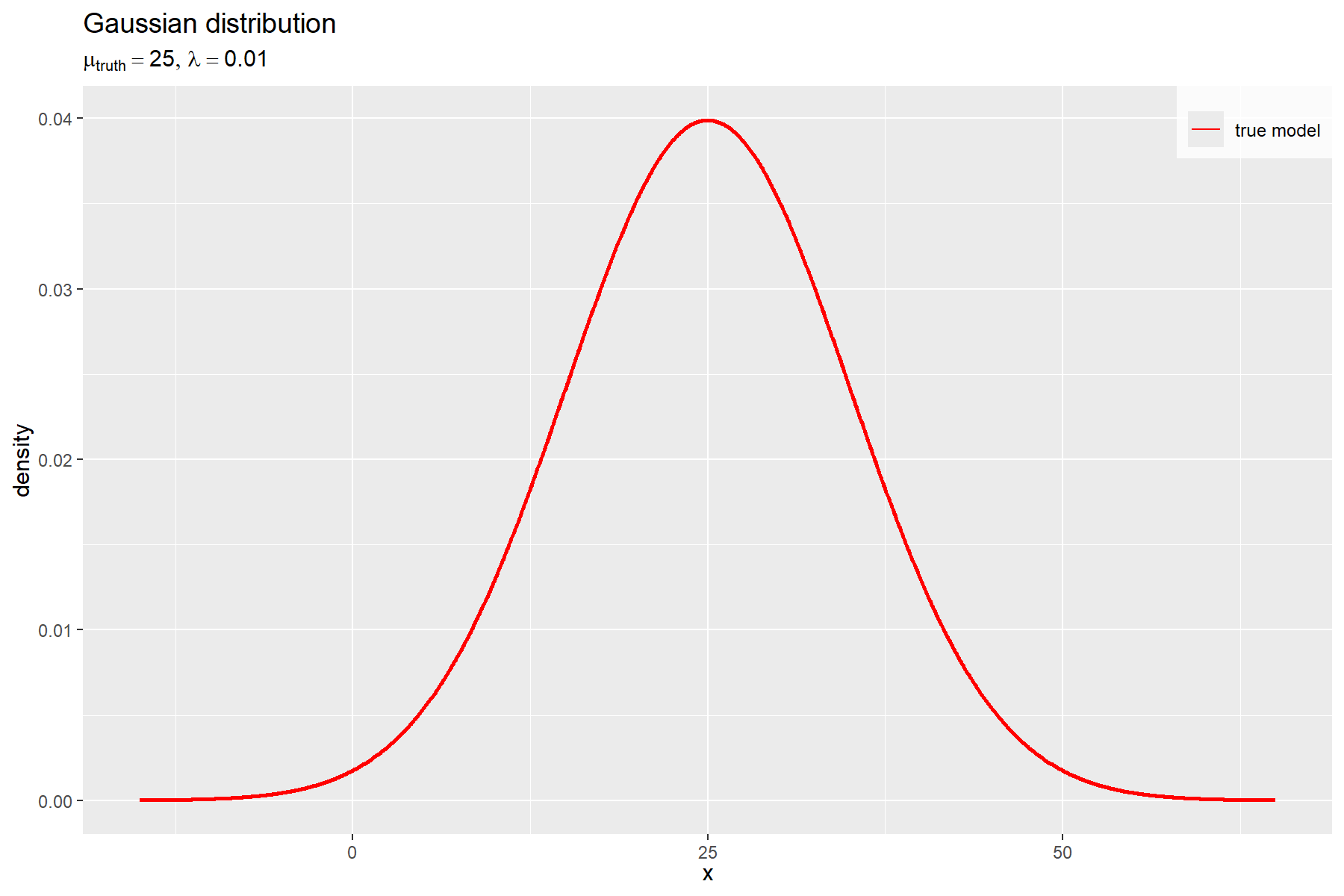
真の分布(ガウス分布)を赤色の曲線で示す。
真のパラメータ を求めることは、真の分布
を求めることを意味する。
データの生成
設定した生成分布(ガウス分布) に従うデータ(観測データ)
を作成する。
ガウスモデルのデータ生成については「【R】1次元ガウス分布の乱数生成 - からっぽのしょこ」を参照のこと。
生成分布からデータ を生成する。
# データ数を指定 N <- 100 # 観測データを生成 x_n <- rnorm(n = N , mean = mu_truth, sd = 1/sqrt(lambda)) head(x_n)
[1] 32.08796 37.95061 24.10967 20.70447 31.34342 17.30270
データ数 を指定して、ガウス分布に従う乱数
を生成する。
ガウス分布の乱数生成関数 rnorm() のサンプルサイズの引数 n に 、平均の引数
mean に 、標準偏差の引数
sd に を指定する。
観測データ を集計する。
# 階級数を指定 bin_num <- 40 # 階級幅を計算 bin_size <- (x_max - x_min) / bin_num # 境界値の範囲を設定 bin_min <- x_min - 0.5*bin_size bin_max <- x_max + 0.5*bin_size # 観測データを集計 obs_df <- tibble::tibble( x = x_n # サンプル値 ) |> dplyr::mutate( bin_i = (x - bin_min) %/% bin_size, # 階級番号 center = bin_min + (bin_i + 0.5) * bin_size # 階級値 ) |> dplyr::count( center, name = "freq" # 度数 ) |> dplyr::mutate( dens = freq / (bin_size * N) # 密度 ) |> tidyr::complete( center = seq(from = x_min, to = x_max, by = bin_size), fill = list(freq = 0, dens = 0) ) # 未観測値を補完 obs_df
# A tibble: 41 × 3
center freq dens
<dbl> <int> <dbl>
1 -15 0 0
2 -13 0 0
3 -11 0 0
4 -9 0 0
5 -7 0 0
6 -5 0 0
7 -3 0 0
8 -1 1 0.005
9 1 0 0
10 3 0 0
# ℹ 31 more rows
階級数を指定して、階級幅 を設定する。
の範囲で階級値を作成して、観測データ
x_n に含まれる要素数をカウントして、度数 と密度
を求める。
観測データ のグラフを作成する。
# 観測データのラベルを作成 obs_param_lbl <- paste0( "list(", "N == ", N, ", ", "mu[truth] == ", round(mu_truth, digits = 2), ", ", "lambda == ", round(lambda, digits = 5), ")" ) |> parse(text = _) # 観測データを作図 ggplot() + geom_line( data = model_df, mapping = aes(x = x, y = dens, linetype = "model"), color = "red", linewidth = 1 ) + # 生成分布 geom_bar( data = obs_df, mapping = aes(x = center, y = dens, linetype = "data"), stat = "identity", position = "identity", width = bin_size, fill = "hotpink", color = NA, alpha = 0.5 ) + # 観測データ scale_y_continuous( sec.axis = sec_axis(transform = ~ .*bin_size*N, name = "frequency") ) + # 度数軸目盛 scale_linetype_manual( breaks = c("model", "data"), values = c("dashed", "blank"), labels = c("true model\n(generation distribution)", "observation data"), name = "" ) + # (凡例表示用) guides( linetype = guide_legend(override.aes = list(linewidth = 0.5)) ) + theme( legend.title = element_text(size = 0), legend.position = "inside", legend.position.inside = c(1, 1), legend.justification = c(1, 1), legend.background = element_rect(fill = alpha("white", alpha = 0.8)) ) + labs( title = "Gaussian distribution", subtitle = obs_param_lbl, x = expression(x), y = "density" )
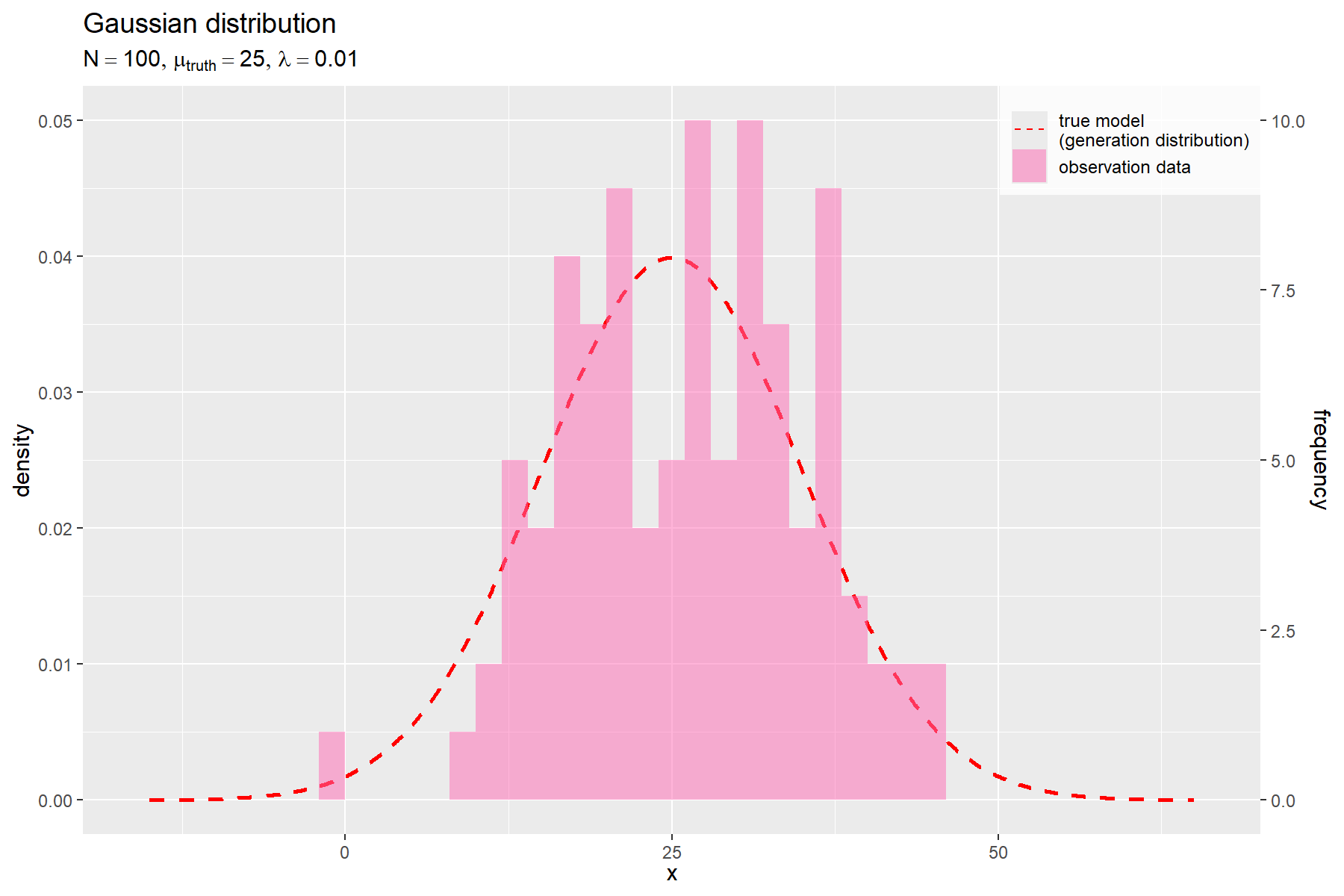
の値ごとの確率密度(生成分布)を赤色の曲線(破線)、観測データ
の度数
(密度
)を桃色の棒グラフ(実線)で示す。
データ数 が十分に大きいと、観測データ
のヒストグラムの形状が生成分布
に近付く。
事前分布の設定
パラメータ の事前分布(ガウス分布)
のパラメータ(超パラメータ)
を設定する。
事前分布のパラメータ を設定する。
# 事前分布のパラメータを指定 m <- 0 lambda_mu <- 0.001 m; lambda_mu
[1] 0 [1] 0.001
ガウス分布の平均パラメータ(実数) 、精度パラメータ(正の値)
を指定する。
事前分布の確率変数 の作図範囲を設定する。
# μ軸の範囲を設定 mu_min <- x_min mu_max <- x_max # μ軸の値を作成 mu_vec <- seq(from = mu_min, to = mu_max, length.out = 1001) mu_min; mu_max; head(mu_vec)
[1] -15 [1] 65 [1] -15.00 -14.92 -14.84 -14.76 -14.68 -14.60
この例では、生成分布の確率変数 の範囲を使っている。
事前分布の確率密度を計算する。
# 事前分布の確率密度を計算:式(2.64) prior_df <- tibble::tibble( mu = mu_vec, # 確率変数 m = m, # 平均パラメータ lambda_mu = lambda_mu, # 精度パラメータ sigma_mu = 1/sqrt(lambda_mu), # 標準偏差パラメータ dens = dnorm(x = mu, mean = m, sd = sigma_mu) # 確率密度 ) prior_df
# A tibble: 1,001 × 5
mu m lambda_mu sigma_mu dens
<dbl> <dbl> <dbl> <dbl> <dbl>
1 -15 0 0.001 31.6 0.0113
2 -14.9 0 0.001 31.6 0.0113
3 -14.8 0 0.001 31.6 0.0113
4 -14.8 0 0.001 31.6 0.0113
5 -14.7 0 0.001 31.6 0.0113
6 -14.6 0 0.001 31.6 0.0113
7 -14.5 0 0.001 31.6 0.0114
8 -14.4 0 0.001 31.6 0.0114
9 -14.4 0 0.001 31.6 0.0114
10 -14.3 0 0.001 31.6 0.0114
# ℹ 991 more rows
の値ごとに、ガウス分布に従う確率密度
を計算する。
ガウス分布の確率密度関数 dnorm() の確率変数の引数 x に 、平均の引数
mean に 、標準偏差の引数
sd に を指定する。
事前分布のグラフを作成する。
# 事前分布のラベルを作成 prior_param_lbl <- paste0( "list(", "mu[truth] == ", round(mu_truth, digits = 2), ", ", "m == ", round(m, digits = 2), ", ", "lambda[mu] == ", round(lambda_mu, digits = 5), ")" ) |> parse(text = _) # 事前分布を作図 ggplot() + geom_vline( mapping = aes(xintercept = mu_truth, linetype = "model"), color = "red", linewidth = 1 ) + # 真のパラメータ geom_line( data = prior_df, mapping = aes(x = mu, y = dens, linetype = "prior"), color = "purple", linewidth = 1 ) + # 事前分布 scale_x_continuous( sec.axis = sec_axis( transform = ~ ., breaks = mu_truth, labels = expression(mu[truth]) ) # パラメータラベル ) + scale_linetype_manual( breaks = c("model", "prior"), values = c("dashed", "solid"), labels = c("true parameter", "prior distribution"), name = "" ) + # (凡例表示用) guides( linetype = guide_legend(override.aes = list(linewidth = 0.5)) ) + theme( legend.title = element_text(size = 0), legend.position = "inside", legend.position.inside = c(1, 1), legend.justification = c(1, 1), legend.background = element_rect(fill = alpha("white", alpha = 0.8)) ) + labs( title = "Gaussian distribution", subtitle = prior_param_lbl, x = expression(mu), y = "density" )
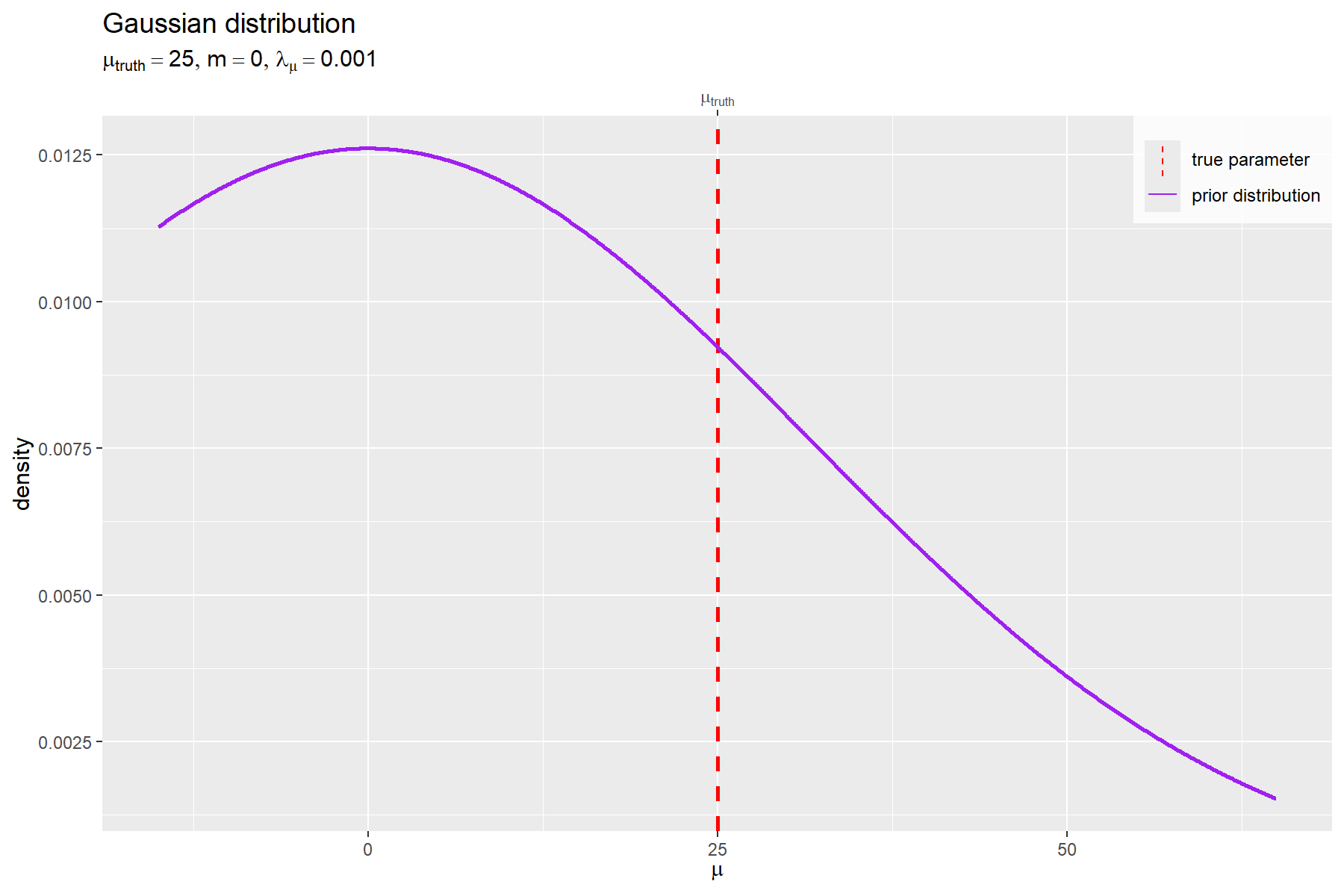
真のパラメータを赤色の垂直線(破線)、事前分布(ガウス分布)を紫色の曲線(実線)で示す。
真のパラメータ(真の分布のパラメータ) と、パラメータ
の事前分布
の位置関係を図で確認する。
事後分布の計算
観測データ から、パラメータ
の事後分布(ガウス分布)
のパラメータ(超パラメータ)
を求める(真のパラメータ
を分布推定する)。
事後分布のパラメータ を計算する。
# 事後分布のパラメータを計算:式(3.53, 3.54) lambda_mu_hat <- N * lambda + lambda_mu m_hat <- (sum(x_n) * lambda + m * lambda_mu) / lambda_mu_hat m_hat; lambda_mu_hat
[1] 26.34625 [1] 1.001
事後分布のパラメータは、観測データ を用いて、次の式で計算できる。
事後分布の確率密度を計算する。
# 事後分布の確率密度を計算:式(2.64) posterior_df <- tibble::tibble( mu = mu_vec, # 確率変数 m = m_hat, # 平均パラメータ lambda_mu = lambda_mu_hat, # 精度パラメータ sigma_mu = 1/sqrt(lambda_mu), # 標準偏差パラメータ dens = dnorm(x = mu, mean = m, sd = sigma_mu) # 確率密度 ) posterior_df
# A tibble: 1,001 × 5
mu m lambda_mu sigma_mu dens
<dbl> <dbl> <dbl> <dbl> <dbl>
1 -15 26.3 1.00 1.000 0
2 -14.9 26.3 1.00 1.000 0
3 -14.8 26.3 1.00 1.000 0
4 -14.8 26.3 1.00 1.000 0
5 -14.7 26.3 1.00 1.000 0
6 -14.6 26.3 1.00 1.000 0
7 -14.5 26.3 1.00 1.000 0
8 -14.4 26.3 1.00 1.000 0
9 -14.4 26.3 1.00 1.000 0
10 -14.3 26.3 1.00 1.000 0
# ℹ 991 more rows
事前分布のときと同様にして、ガウス分布に従う確率密度 を計算する。
事後分布のグラフを作成する。
# 事後分布のラベルを作成 posterior_param_lbl <- paste0( "list(", "N == ", N, ", ", "mu[truth] == ", round(mu_truth, digits = 2), ", ", "hat(m) == ", round(m_hat, digits = 2), ", ", "hat(lambda)[mu] == ", round(lambda_mu_hat, digits = 5), ")" ) |> parse(text = _) # 事後分布を作図 ggplot() + geom_vline( mapping = aes(xintercept = mu_truth, linetype = "model"), color = "red", linewidth = 1 ) + # 真のパラメータ geom_line( data = posterior_df, mapping = aes(x = mu, y = dens, linetype = "posterior"), color = "purple", linewidth = 1 ) + # 事後分布 scale_x_continuous( sec.axis = sec_axis( transform = ~ ., breaks = mu_truth, labels = expression(mu[truth]) ) # パラメータラベル ) + scale_linetype_manual( breaks = c("model", "posterior"), values = c("dashed", "solid"), labels = c("true parameter", "posterior distribution"), name = "" ) + # (凡例表示用) guides( linetype = guide_legend(override.aes = list(linewidth = 0.5)) ) + theme( legend.title = element_text(size = 0), legend.position = "inside", legend.position.inside = c(1, 1), legend.justification = c(1, 1), legend.background = element_rect(fill = alpha("white", alpha = 0.8)) ) + labs( title = "Gaussian distribution", subtitle = posterior_param_lbl, x = expression(mu), y = "density" )
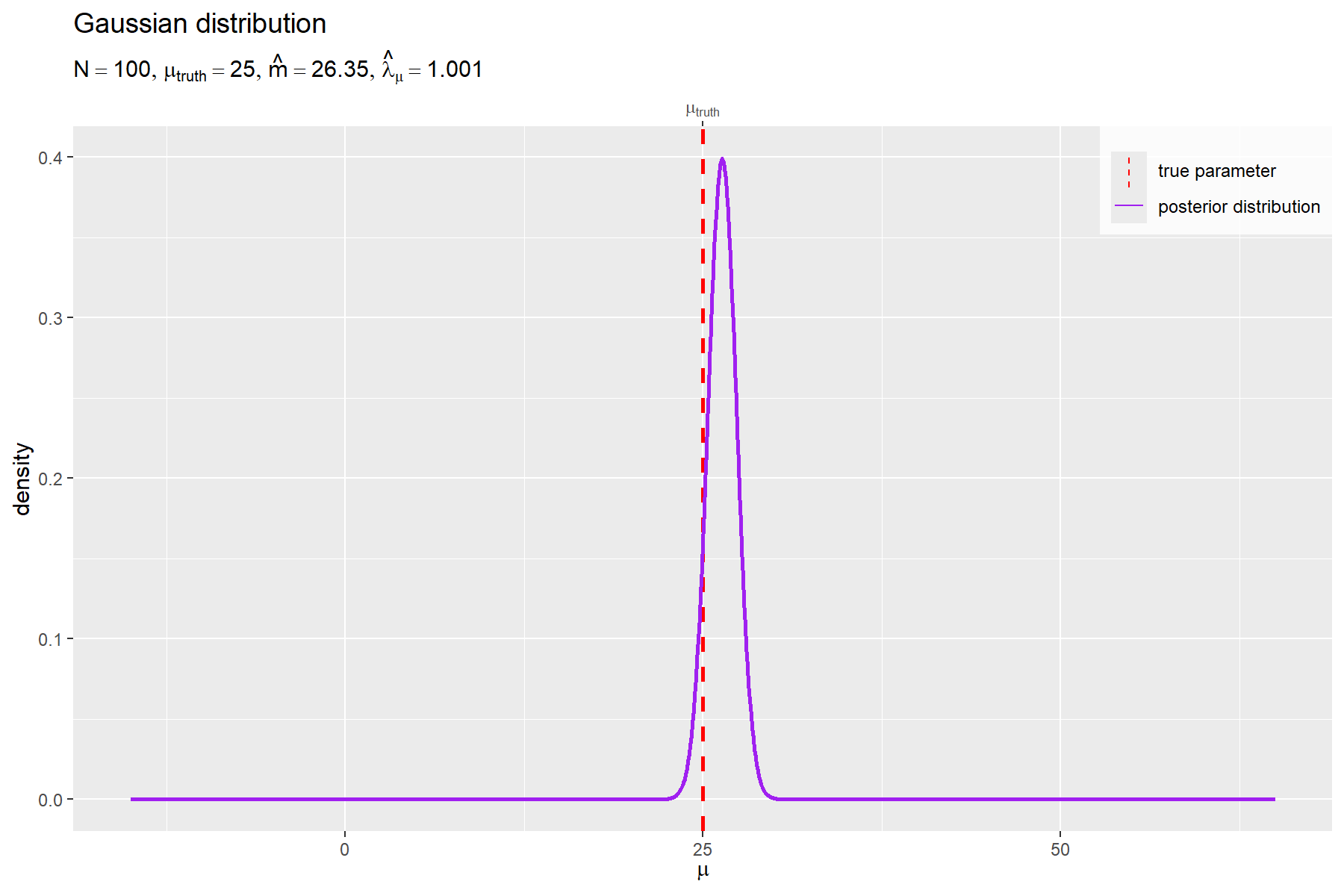
真のパラメータを赤色の垂直線(破線)、事後分布(ガウス分布)を紫色の曲線(実線)で示す。
データ数 が十分に大きいと、パラメータ
の事後分布
のピークが真のパラメータ
に近付く。
予測分布の計算
観測データ から、未観測データ
の予測分布(ガウス分布)
のパラメータ
を求める。
予測分布のパラメータ を計算する。
# 事後分布のパラメータにより予測分布のパラメータを計算:式(3.62') mu_star_hat <- m_hat lambda_star_hat <- lambda * lambda_mu_hat / (lambda + lambda_mu_hat) mu_star_hat; lambda_star_hat
[1] 26.34625 [1] 0.009901088
# 観測データにより予測分布のパラメータを計算:式(3.62') mu_star_hat <- (lambda * sum(x_n) + m * lambda_mu) / (N * lambda + lambda_mu) lambda_star_hat <- (N * lambda + lambda_mu) * lambda / ((N + 1) * lambda + lambda_mu) mu_star_hat; lambda_star_hat
[1] 26.34625 [1] 0.009901088
# 分散パラメータから精度パラメータを計算:式(3.63') sigma2_star_hat <- 1/lambda + 1/lambda_mu_hat lambda_star_hat <- 1/sigma2_star_hat sigma2_star_hat; lambda_star_hat
[1] 100.999 [1] 0.009901088
予測分布のパラメータは、事後分布のパラメータ または観測データ
を用いて、次の式で計算できる。
予測分布の確率密度を計算する。
# 予測分布の確率密度を計算:式(2.64) predict_df <- tibble::tibble( x = x_vec, # 確率変数 mu_star = mu_star_hat, # 平均パラメータ lambda_star = lambda_star_hat, # 精度パラメータ sigma_star = 1/sqrt(lambda_star), # 標準偏差パラメータ dens = dnorm(x = x, mean = mu_star, sd = sigma_star) # 確率密度 ) predict_df
# A tibble: 1,001 × 5
x mu_star lambda_star sigma_star dens
<dbl> <dbl> <dbl> <dbl> <dbl>
1 -15 26.3 0.00990 10.0 0.00000838
2 -14.9 26.3 0.00990 10.0 0.00000866
3 -14.8 26.3 0.00990 10.0 0.00000895
4 -14.8 26.3 0.00990 10.0 0.00000924
5 -14.7 26.3 0.00990 10.0 0.00000955
6 -14.6 26.3 0.00990 10.0 0.00000986
7 -14.5 26.3 0.00990 10.0 0.0000102
8 -14.4 26.3 0.00990 10.0 0.0000105
9 -14.4 26.3 0.00990 10.0 0.0000109
10 -14.3 26.3 0.00990 10.0 0.0000112
# ℹ 991 more rows
生成分布のときと同様にして、ガウス分布に従う確率密度 を計算する。
予測分布のグラフを作成する。
# 予測分布のラベルを作成 predict_param_lbl <- paste0( "list(", "N == ", N, ", ", "mu[truth] == ", round(mu_truth, digits = 2), ", ", "lambda == ", round(lambda, digits = 5), ", ", "hat(mu)['*'] == ", round(mu_star_hat, digits = 2), ", ", "hat(lambda)['*'] == ", round(lambda_star_hat, digits = 5), ")" ) |> parse(text = _) # 予測分布を作図 ggplot() + geom_line( data = model_df, mapping = aes(x = x, y = dens, linetype = "model"), color = "red", linewidth = 1 ) + # 真の分布 geom_line( data = predict_df, mapping = aes(x = x, y = dens, linetype = "predict"), color = "purple", linewidth = 1 ) + # 予測分布 scale_linetype_manual( breaks = c("model", "predict"), values = c("dashed", "solid"), labels = c("true model", "predict distribution"), name = "" ) + # (凡例表示用) guides( linetype = guide_legend(override.aes = list(linewidth = 0.5)) ) + theme( legend.title = element_text(size = 0), legend.position = "inside", legend.position.inside = c(1, 1), legend.justification = c(1, 1), legend.background = element_rect(fill = alpha("white", alpha = 0.8)) ) + labs( title = "Gaussian distribution", subtitle = predict_param_lbl, x = expression(x), y = "density" )
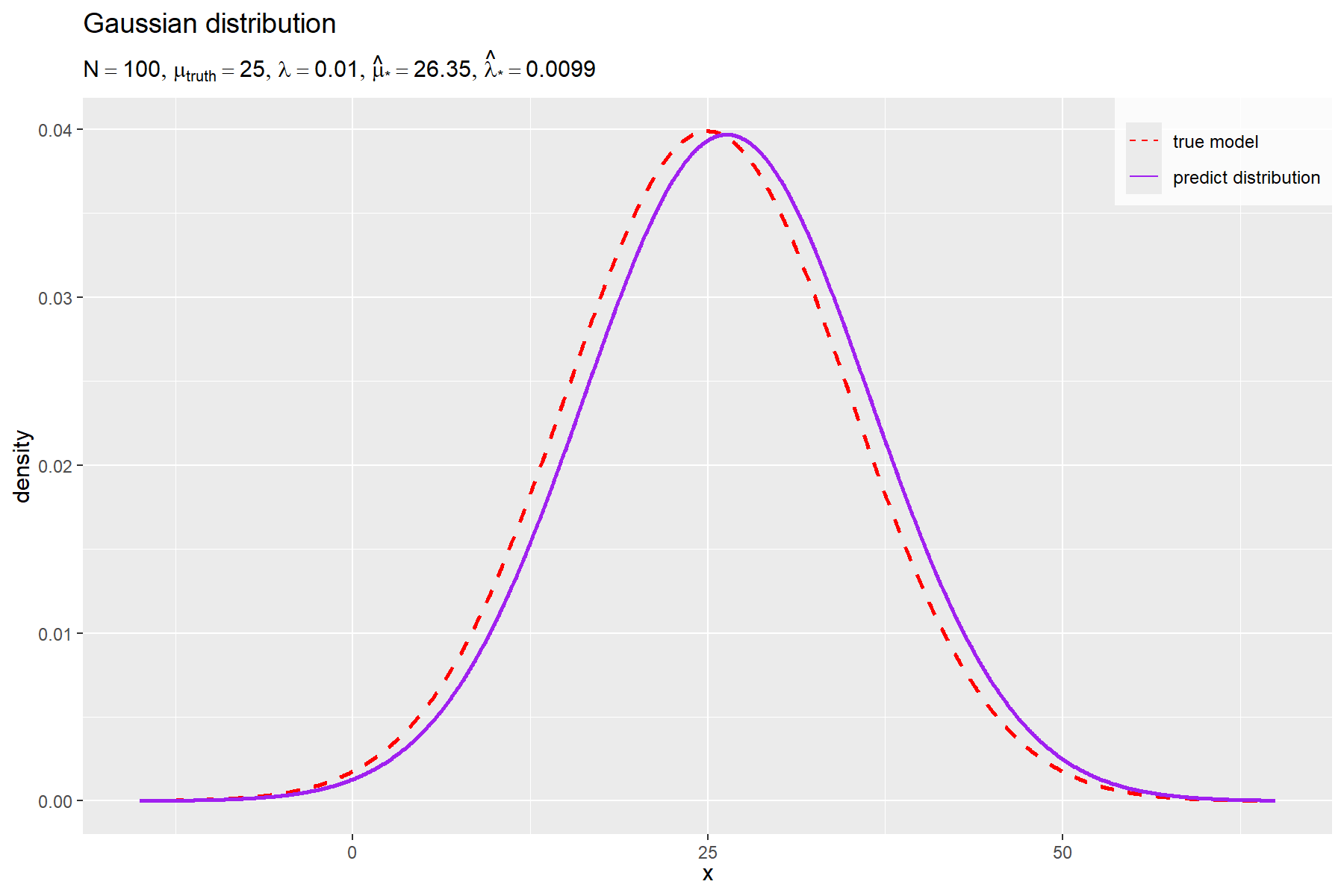
真の分布(ガウス分布)を赤色の曲線(破線)、予測分布(ガウス分布)を紫色の曲線(実線)で示す。
データ数 が十分に大きいと、未観測データ
の予測分布
の形状が真の分布
に近付く。
以上で、平均が未知の1次元ガウスモデルのベイズ推論を実装した。
スポンサードリンク
学習の推移
次は、平均が未知の1次元ガウス分布に対するベイズ推論を図で確認する。
データ数を増やして分布の変化をアニメーションで確認する。
作図コードについては「Suyama-Bayes/code/gaussian_model/bayesian_inference/plot_parameter_updates_unknown_mean.R at master · anemptyarchive/Suyama-Bayes · GitHub」を参照のこと。
データ数と分布の関係
データ数 を変化させたときの事後分布
の変化をアニメーションにする。
個のデータから求めた(
回更新した)事後分布(ガウス分布)
を紫色の曲線(実線)、
番目の観測データ
に対応する位置
を桃色の点で示す。
「ベイズ推論の実装」では、 個(複数)のデータ
を用いて、事後分布のパラメータ
を一括更新した。
番目(1つ)のデータ
を用いて逐次更新する場合、
回目の事後分布のパラメータ
は、次の式で計算できる。
超パラメータの初期値(1回目の更新における事前分布のパラメータ)を として、
は、
回目の更新における事後分布のパラメータであり、また
回目の更新における事前分布のパラメータを表す。
データ数 が大きくなるのに応じて、パラメータ
の事後分布
のピークが真のパラメータ
に近付いていくのを確認できる。
データ数 を変化させたときの予測分布
の変化をアニメーションにする。
個のデータから求めた(
回更新した)予測分布(ガウス分布)
を紫色の曲線(実線)、
番目の観測データ
を桃色の点で示す。
「ベイズ推論の実装」では、 個(複数)のデータ
を用いて、予測分布のパラメータ
を一括更新した。
番目(1つ)のデータ
を用いて逐次更新する場合、
回目の予測分布のパラメータ
は、次の式で計算できる。
超パラメータの初期値 を用いて求めたパラメータを
として、
は
回目の更新値を表す。
データ数 が大きくなるのに応じて、未観測データ
の予測分布
の形状が真の分布
に近付いていくのを確認できる。
観測データと分布の関係
データ数 の変化による観測データと事後分布、予測分布の関係をアニメーションにする。
真の分布の期待値 と真のパラメータ
の各図(分布)に対応する位置を赤色の垂直線(破線)、観測データの標本平均
を桃色の垂直線(破線)、事後分布の期待値
と予測分布の期待値
を紫色の垂直線(破線)で示す。
生成分布(ガウス分布)、事後分布(ガウス分布)、予測分布(ガウス分布)の期待値は、それぞれ次の式で計算できる。
真の分布 や真のパラメータ
と、観測データ
、事後分布
、予測分布
、またそれぞれの統計量の対応関係を確認できる。
以上で、平均が未知の1次元ガウスモデルのベイズ推論における学習推移を確認した。
この記事では、平均が未知の場合の1次元ガウス分布に対するベイズ推論を扱った。次の記事では、精度が未知の場合を扱う。
参考文献
おわりに
- 2021.03.16:加筆修正の際に、数式読解編とRで実装編に記事を分割しました。
推論結果だけでなく何がどうなったかを明確にするためにそれなりに加筆しました。それによって自分の中ではかなり整理できたのですが、その結果文量が多くなってしまって読みにくくなった気がしなくもない。
2022.08.08:加筆修正しました。
2026.01.16:加筆修正しました。
その後、1つの記事にアレコレ盛り込んで書いていたのを改め、1記事で扱うテーマを絞ってそれぞれ別記事として加筆修正していったので、読みやすくなったと思います。
興味が湧いたら記事中にリンクしてある記事もあわせて読んでみてください。
最後に、えびちゅうのライブ映像を1曲をどうぞ♪
よく見たらこれ私が観に行った公演の映像だった!それもえびちゅうの単独公演としては初めて観に行った大阪2DAYSの2日目(つまり初めてではない)のライブだ!(そんなことを確認してたら動画の説明文の日付が間違ってることに気付いてしまった。)
判別できないけど画角的に私も映ってるはずです。
特に思い入れがあった訳ではないのですが、ライブ後に一番と言っていいほど耳に残った曲でした。もう懐かしいなぁ。
【次節の内容】
- 数式読解編
1次元ガウスモデルに対するベイズ推論を数式で確認します。
- スクラッチ実装編
1次元ガウスモデルに対するベイズ推論をプログラムで確認します。
