はじめに
『トピックモデル』(MLPシリーズ)の勉強会資料のまとめです。各種モデルやアルゴリズムを「数式」と「プログラム」を用いて解説します。
本の補助として読んでください。
この記事では、トピック追跡モデルで登場する数式の行間を埋めます。
【前節の内容】
【他の節の内容】
【この節の内容】
5.5 トピック追跡モデルの生成モデルの導出
トピック追跡モデル(TTM・topic tracking model)の定義(仮定)を確認する。トピック追跡モデルでは、時間により変化する文書集合(単語情報)やパラメータとして時間情報(補助情報)を扱う。
トピックモデル(LDA・latent Dirichlet allocation)の定義や共通する記号類については「4.1:トピックモデルの生成モデルの導出【青トピックモデルのノート】 - からっぽのしょこ」を参照のこと。
生成過程の設定
まずは、トピック追跡モデルの生成過程(generative process)を数式で確認する。ただし、基本形のトピックモデルと共通する内容については省略する。アルゴリズムについては図5.14を参照のこと。
時刻数(総時刻)を 、時刻番号(インデックス)を
とする。
文書数(著者数)を として、各時刻において著者ごとに1つの文書が生成されるとする。
時刻 における文書
(
番目の著者による文書)を
で表す。各文書を「著者
の文書」などとも呼ぶ。
同様に、時刻 におけるパラメータや単語数なども
と表記する。
1時刻のパラメータを利用する場合
1時刻前のパラメータの推定値をハイパーパラメータとして利用する場合の設定を確認する。
時刻 における各文書(著者)のトピック分布のパラメータ
は、時刻
における(1時刻前の)トピック分布のパラメータの推定値
を用いて
をパラメータとするディリクレ分布に従って独立に生成されると仮定する。
はディリクレ分布のパラメータなので、各要素は正の値の条件を満たす必要がある。
はカテゴリ分布のパラメータなので、各要素は非負の値であり、総和(全てのトピックに関する和)が1になる条件
を満たすので、係数 は、正の値の条件を満たす必要がある。
を、時刻
におけるトピック分布のハイパーパラメータ(超パラメータ)と呼ぶ。
文書(著者)ごとにトピック分布のハイパーパラメータを持ち、 個のハイパーパラメータを集合
として扱い、トピック分布のハイパーパラメータ集合と呼ぶ。
の計算式などについては「5.5:トピック追跡モデルの崩壊型ギブズサンプリングの導出:1時刻のパラメータの場合【青トピックモデルのノート】 - からっぽのしょこ」を参照のこと。
時刻 における各トピックの単語分布のパラメータ
は、時刻
における(1時刻前の)単語分布のパラメータの推定値
を用いて
をパラメータとするディリクレ分布に従って独立に生成されると仮定する。
の各要素は、ディリクレ分布のパラメータの条件(正の値)を満たす必要がある。
はカテゴリ分布のパラメータなので、各要素は非負の値であり、総和(全ての語彙に関する和)が1になる条件
を満たすので、係数 は、正の値の条件を満たす必要がある。
を、時刻
における単語分布のハイパーパラメータと呼ぶ。
トピックごとに単語分布のハイパーパラメータを持ち、 個のハイパーパラメータを集合
として扱い、単語分布のハイパーパラメータ集合と呼ぶ。
の計算式などについては「トピック追跡モデルの崩壊型ギブズサンプリングの導出:1時刻のパラメータの場合」を参照のこと。
複数時刻のパラメータを利用する場合
複数時刻前からのパラメータの推定値をハイパーパラメータとして利用する場合の設定を確認する。
事前分布のパラメータ(ハイパーパラメータ)として利用する過去情報(パラメータの推定値)の時刻数を 、過去時刻インデックス(番号)を
とする。「1時刻版」は
の場合と言える。
次元ベクトル
を、時刻
における文書(著者)
のトピック分布のハイパーパラメータとする。
個の値
はそれぞれ過去時刻(
時刻前)のトピック分布のパラメータの推定値
に対応する。
時刻 (
時刻前)から時刻
(
時刻前)における(過去
時刻分の)文書(著者)
のトピック分布のパラメータの推定値を集合
として扱い、次のように表記する。
時刻 における各文書(著者)のトピック分布のパラメータ
は、過去
時刻分のトピック分布のパラメータの推定値
を用いて
途中式の途中式(クリックで展開)
を
次元の横ベクトル、
を
行
列の行列として扱うと、次のベクトルと行列の積で表せる。
計算結果は 次元ベクトルになり、各要素はベクトルと各列の内積(要素ごとの積の和)である。
各トピックに対応する 個の値を集合
として扱う。
をパラメータとするディリクレ分布に従って独立に生成されると仮定する。
はディリクレ分布のパラメータなので、各要素は正の値の条件を満たす必要がある。
はカテゴリ分布のパラメータなので、各要素は非負の値であり、総和(全てのトピックに関する和)が1になる条件
を満たすので、係数 (
の各要素)は、正の値の条件を満たす必要がある。
文書(著者)ごとにトピック分布のハイパーパラメータを持ち、 個のハイパーパラメータを集合
として扱い、トピック分布のハイパーパラメータ集合と呼ぶ。
過去 時刻分(の全ての文書(著者))のトピック分布のパラメータの推定値を集合
として扱い、次のように表記する。
の計算式などについては「5.5:トピック追跡モデルの崩壊型ギブズサンプリングの導出:複数時刻のパラメータの場合【青トピックモデルのノート】 - からっぽのしょこ」を参照のこと。
次元ベクトル
を、時刻
におけるトピック
の単語分布のハイパーパラメータとする。
個の値
はそれぞれ過去時刻(
時刻前)の単語分布のパラメータの推定値
に対応する。
時刻 から
におけるトピック
の単語分布のパラメータの推定値を集合
として扱い、次のように表記する。
時刻 における各トピックの単語分布のパラメータ
は、過去
時刻分の単語分布のパラメータの推定値
を用いて
途中式の途中式(クリックで展開)
を
次元の横ベクトル、
を
行
列の行列として扱うと、次のベクトルと行列の積で表せる。
計算結果は 次元ベクトルになり、各要素はベクトルと各列の内積(要素ごとの積の和)である。
各語彙に対応する 個の値を集合
として扱う。
をパラメータとするディリクレ分布に従って独立に生成されると仮定する。
は、ディリクレ分布のパラメータの条件(正の値)を満たす必要がある。
はカテゴリ分布のパラメータなので、各要素は非負の値であり、総和(全ての語彙に関する和)が1になる条件
を満たすので、係数 (
の各要素)は、正の値の条件を満たす必要がある。
トピックごとに単語分布のハイパーパラメータを持ち、 個のハイパーパラメータを集合
として扱い、単語分布のハイパーパラメータ集合と呼ぶ。
過去 時刻分(の全てのトピック)の単語分布のパラメータの推定値を集合
として扱い、次のように表記する。
の計算式などについては「トピック追跡モデルの崩壊型ギブズサンプリングの導出:複数時刻のパラメータの場合」を参照のこと。
以上で、トピック追跡モデルの生成過程(定義・仮定)を確認した。生成過程は、変数やパラメータ間の依存関係であり、生成モデルや推論アルゴリズムの導出でも用いる。
スポンサードリンク
記号一覧
続いて、トピックモデル(4.1節)に加えてトピック追跡モデル(5.5節)で用いる記号類を表にまとめる。
| 記号 | 意味 | 制約・関係性 |
|---|---|---|
| |
時刻数 | |
| |
文書数(著者数) | |
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
| |
時刻 |
|
トピックモデル(基本形)やこれまでの拡張版モデルと異なり、トピック分布は( トピックごと ではなく)文書ごと
に、単語分布は(語彙ごと
ではなく)トピックごと
に値を持つ点に注意。
以上の記号を用いて、トピック追跡モデルやその推論アルゴリズムを定義する。
スポンサードリンク
ハイパーパラメータとパラメータの関係
ハイパーパラメータ(ハイパーパラメータの係数・前時刻のパラメータの推定値)とパラメータ(現時刻のパラメータの未知の値)の統計量の関係を数式とグラフで確認する。
パラメータ(ディリクレ分布の変数・カテゴリ分布のパラメータ)の条件より、ハイパーパラメータ(ディリクレ分布のパラメータ) の総和(全ての語彙に関する和)を求める。
途中式の途中式(クリックで展開)
- 1:
と無関係な
を
の外に出す。
- 2: カテゴリ分布
、ディリクレ分布
のときパラメータの条件
より、推定値の総和の項が消える。
係数 になることが分かった。
ディリクレ分布の期待値より、パラメータ(ディリクレ分布の変数)の の期待値を求める。
途中式の途中式(クリックで展開)
- 1: ディリクレ分布
より、期待値の式を立てる。
- 2: (ハイパー)パラメータの総和の式(1)で置き換える。
推定値 になることが分かった。
ディリクレ分布の分散より、パラメータ(ディリクレ分布の変数)の の分散を求める。
途中式の途中式(クリックで展開)
- 1: ディリクレ分布
より、分散の式を立てる。
- 2: (ハイパー)パラメータの総和の式(1)で置き換える。
- 3: 分子の項について、
係数 を分母に持つ式になることが分かった。
分散の逆数より、パラメータ(ディリクレ分布の変数)の の精度を求める。
途中式の途中式(クリックで展開)
- 1: 精度の定義
より、分散の逆数の式を立てる。
- 2: 分母に分散の式を代入する。
係数 を分子に持つ式になることが分かった。
パラメータの推定値 を固定して係数
を変化させたときのパラメータの各種統計量の変化をグラフで示す。
作図コード(クリックで展開)
パッケージを読み込む。
# 利用パッケージ library(tidyverse) library(patchwork)
係数を指定して、統計量を計算する。
# パラメータの推定値を指定 phi_hat_v <- c(0.2, 0.3, 0.5) # ハイパーパラメータの係数の範囲を指定 beta_vals <- seq(from = 0.01, to = 10, by = 0.01) # 統計量を計算 stats_df <- tidyr::expand_grid( v = 1:length(phi_hat_v) |> factor(), # 語彙番号 beta = beta_vals # 係数 ) |> # 語彙ごとに係数を複製 dplyr::mutate( phi_hat = phi_hat_v[v], # 推定値 E_phi = phi_hat, # 期待値 V_phi = phi_hat * (1 - phi_hat) / (beta + 1), # 分散 invV_phi = 1 / V_phi, # 精度 .by = beta ) stats_df
# A tibble: 3,000 × 6 v beta phi_hat E_phi V_phi invV_phi <fct> <dbl> <dbl> <dbl> <dbl> <dbl> 1 1 0.01 0.2 0.2 0.158 6.31 2 1 0.02 0.2 0.2 0.157 6.37 3 1 0.03 0.2 0.2 0.155 6.44 4 1 0.04 0.2 0.2 0.154 6.5 5 1 0.05 0.2 0.2 0.152 6.56 6 1 0.06 0.2 0.2 0.151 6.62 7 1 0.07 0.2 0.2 0.150 6.69 8 1 0.08 0.2 0.2 0.148 6.75 9 1 0.09 0.2 0.2 0.147 6.81 10 1 0.1 0.2 0.2 0.145 6.87 # ℹ 2,990 more rows
係数と統計量の関係のグラフを作成する。
# ラベル用の文字列を作成 param_lbl <- paste0("hat(phi) == (list(", paste0(phi_hat_v, collapse = ", "), "))") p_lbl <- "Dirichlet(phi ~'|'~ beta * hat(phi))" E_lbl <- "E(phi[v]) == hat(phi)[v]" V_lbl <- "Var(phi[v]) == frac(hat(phi)[v] * (1 - hat(phi)[v]), beta + 1)" invV_lbl <- "paste(inv~Var(phi[v]) == frac(1, Var(phi[v])), {} == frac(beta + 1, hat(phi)[v] * (1 - hat(phi)[v])))" # 係数と期待値の関係を作図 E_graph <- ggplot() + geom_line( data = stats_df, mapping = aes(x = beta, y = E_phi, color = v) ) + # 係数との関係 geom_label( mapping = aes(x = -Inf, y = Inf, label = param_lbl), parse = TRUE, hjust = 0, vjust = 1 ) + # 推定値ラベル coord_cartesian(ylim = c(0, 1)) + # 描画範囲 labs( title = parse(text = p_lbl), subtitle = parse(text = E_lbl), color = expression(v), x = expression(beta), y = expression(E(phi[v])) ) # 係数と分散の関係を作図 V_graph <- ggplot() + geom_line( data = stats_df, mapping = aes(x = beta, y = V_phi, color = v) ) + # 係数との関係 labs( subtitle = parse(text = V_lbl), color = expression(v), x = expression(beta), y = expression(Var(phi[v])) ) # 係数と精度の関係を作図 inv_V_graph <- ggplot() + geom_line( data = stats_df, mapping = aes(x = beta, y = invV_phi, color = v) ) + # 係数との関係 labs( subtitle = parse(text = invV_lbl), color = expression(v), x = expression(beta), y = expression(inv~Var(phi[v])) ) # グラフを結合 wrap_graph <- patchwork::wrap_plots( E_graph, V_graph, inv_V_graph, ncol = 1, guides = "collect" ) wrap_graph

1枚目の図は、係数 とパラメータ
の各項の期待値
の関係である。期待値は係数と無関係であり、係数の影響を受けずに期待値が推定値
になる(期待値が推定値で一定になる)のを確認できる。
2枚目の図は、係数 とパラメータ
の各項の分散
の関係である。精度は係数と反比例のような関係であり、係数が大きくなるほど分散が小さくなるのを確認できる。つまり、
が大きいほど変数
が期待値
の付近に分布する。
3枚目の図は、係数 とパラメータ
の各項の精度
の関係である。精度は係数と比例のような関係であり、係数が大きくなるほど精度が大きくなるのを確認できる。精度が大きいのは分散が小さいのと同じことである。よって、
は精度ハイパーパラメータとも呼ばれる。
以上で、ハイパーパラメータの設定について追加で確認した。
スポンサードリンク
尤度関数の導出
次は、トピック追跡モデルにおける尤度関数(likelihood function)を数式で確認する。
時刻 において、パラメータ
が与えられた(条件とする)ときの観測データ
の生成確率(結合分布)は、生成過程(依存関係)に従い次のように変形できる。
途中式の途中式(クリックで展開)
- 1: 文書(著者)ごとの積に分解する。
- 2: 単語ごとの積に分解する。
- 3: 周辺化された潜在変数
を明示する。
- 4: 観測・潜在変数
の項を分解する。
具体的な式に置き換えて、式を整理する。
途中式の途中式(クリックで展開)
- 1: それぞれカテゴリ分布を仮定しているので、各変数がとる値(インデックス)のパラメータが生成確率に対応する。
- 2: 単語番号
を用いた式から、語彙番号
個の単語に対応するパラメータ
について、各単語に割り当てられた語彙番号
を用いてトピックごとにまとめると、
個の
に置き換えられる。
トピック分布・単語分布のパラメータ(と語彙頻度)を用いた式が得られた。
スポンサードリンク
生成モデルの導出
続いて、トピック追跡モデルの生成モデル(generative model)を数式で確認する。
時刻 において、観測変数
、潜在変数
、パラメータ
、ハイパーパラメータ
また前時刻(時刻
)のパラメータの推定値
をそれぞれ確率変数とする結合分布は、生成過程(依存関係)に従い次のように変形できる。
途中式の途中式(クリックで展開)
- 1: 変数やパラメータごとの項に分割する。
観測変数、潜在変数、パラメータ、ハイパーパラメータごとに項を分割する。
さらに3つ目の項の、独立なパラメータの項を分割する。
4つ目の項の、独立なハイパーパラメータの項を分割する。
確率変数と依存関係のない条件を適宜省いている。
- 2: 文書・トピックごとの積に分解する。
- 3: 単語ごとの積に分解する。
「複数時刻版」の式も同様にして変形できる。
この式自体が変数やパラメータ間の依存関係を表している。
スポンサードリンク
グラフィカルモデル
最後は、トピック追跡モデルの生成モデルをグラフィカルモデル表現(graphical model representation)で確認する。
1時刻のパラメータを利用する場合
トピック追跡モデルの生成モデルは、次の式に分解できた。
この式をグラフィカルモデルにすると、次の図になる。
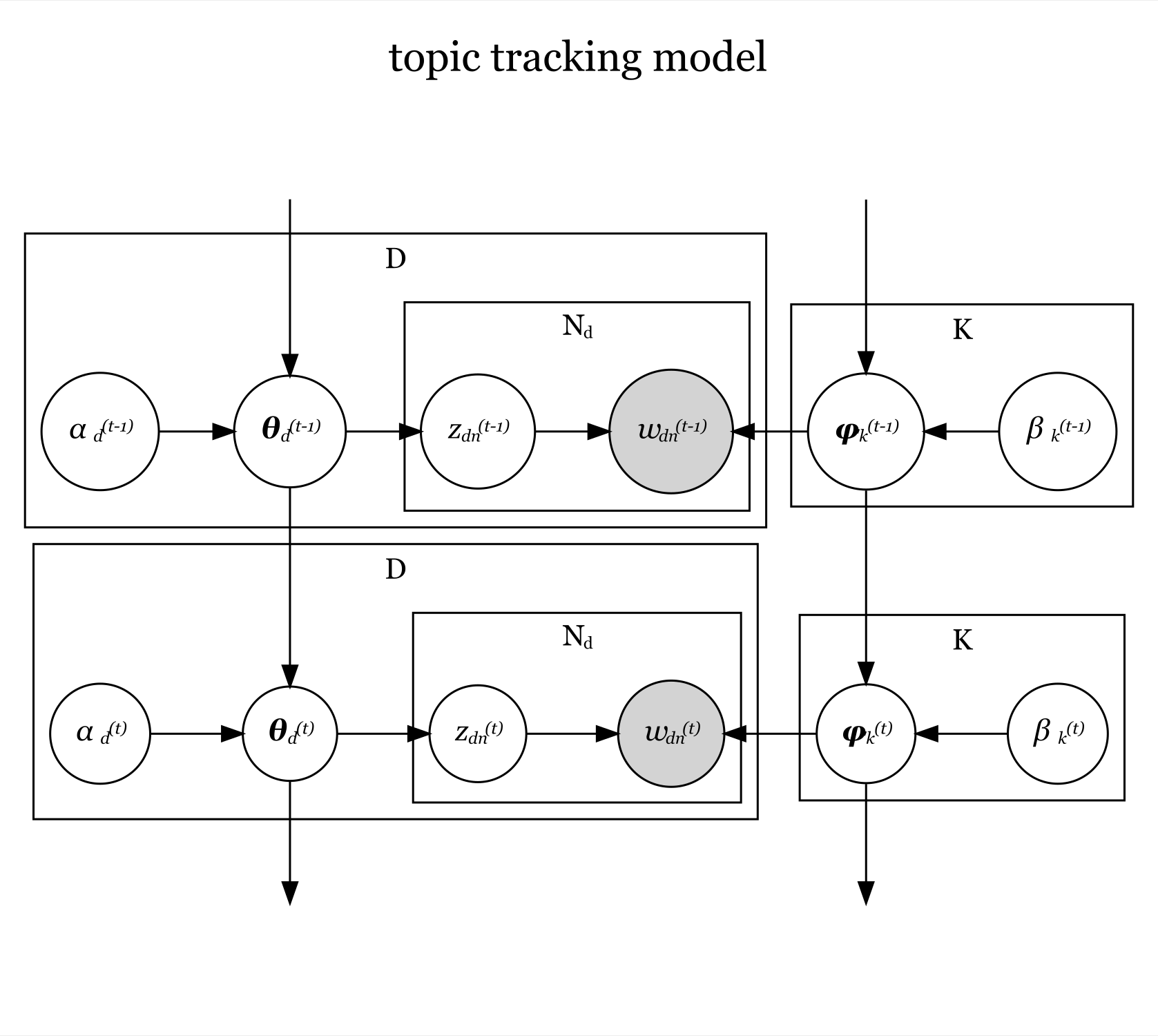
「 」と「
」が、各時刻におけるトピック分布のパラメータの事前分布
に対応し、事前分布(のパラメータ)と前時刻の推定パラメータに従ってパラメータ
が生成されることを示している。
「 」と「
」が、各時刻における単語分布のパラメータの事前分布
に対応し、事前分布(のパラメータ)と前時刻の推定パラメータに従ってパラメータ
が生成されることを示している。
トピックモデル(基本形)と異なり、 に対応する「
」のプレートにトピック分布のハイパーパラメータ
が含まれ、
個の文書(著者)それぞれが値を持つことを示している。
同様に、 に対応する「
」のプレートに単語分布のハイパーパラメータ
が含まれ、
個のトピックそれぞれが値を持つことを示している。
各時刻におけるその他の関係(ノードとエッジ)についてはトピックモデル(4.1節)と同じである。
複数時刻のパラメータを利用する場合
トピック追跡モデルの生成モデルは、次の式に分解できる。
この式をグラフィカルモデルにすると、次の図になる。
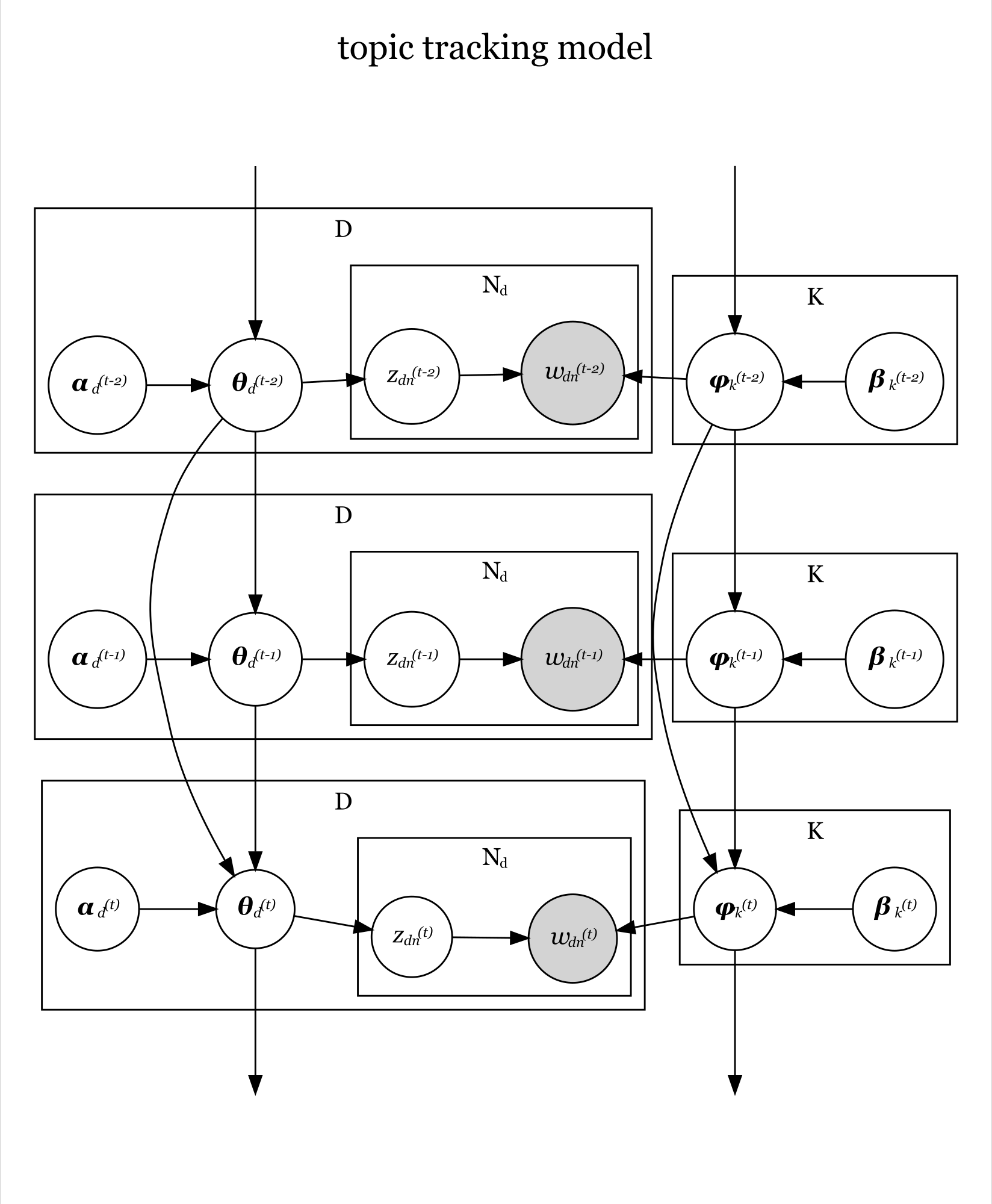
「 」と「
、
」が、各時刻におけるトピック分布のパラメータの事前分布
に対応し、事前分布(のパラメータ)と過去の複数時刻の推定パラメータに従ってパラメータ
が生成されることを示している。
「 」と「
、
」が、各時刻における単語分布のパラメータの事前分布
に対応し、事前分布(のパラメータ)と過去の複数時刻の推定パラメータに従ってパラメータ
が生成されることを示している。
各時刻におけるその他の関係(ノードとエッジ)についてはトピックモデル(4.1節)と同じである。
この記事では、トピック追跡モデルで用いる記号や定義を確認した。次の記事では、崩壊型ギブスサンプリングによるパラメータの計算式を導出する。
参考書籍
おわりに
上にも下にも添字が煩いですね。私はもう慣れました。
これにて5章完了!いやぁ感無量。
ところで
平均が前の時刻のトピック分布の推定値
のディリクレ分布
から生成されるとします.パラメータ
は,分散の逆数である精度と相関します.
ってどういう意味ですか?(2025.05.19追記:分かったので解説を追加しました。)
2020年11月5日は、つばきファクトリーのサブリーダー小片リサさんの22歳のお誕生日!
りさまるのパフォーマンス早く観たいーーー。
さらにBEYOOOOONDSの山﨑夢羽さんの18歳のお誕生日!
おめでとうございまーーーーーす。
- 2025.05.19:加筆修正しました。その際に「トピック追跡モデルの崩壊型ギブズサンプリング:1時刻のパラメータの場合」を記事から独立しました。
推論編の記事を先に書き終えたので、作業的にはこの記事が5章の加筆修正の最後となりました。実装編もやりたい気持ちはありますが、他のアレコレが溜まっており優先順位はかなり低いです…。
今回の加筆修正では、各種モデルの設計上の違いが数式上でどう変わってくるのかを整理できたと思います。(ダレていた期間も含めて)かな~り時間がかかりましたが分かった感が強いです。
それと一番成長したのが DiagrammeR パッケージの使い方で、複雑なグラフィカルモデルを意図通りに作れるようになりました。ノードの配置が縦方向に微妙にズレてしまうことがあるのが悔しいです。これも忘れる前に記事にしておきたい。
【次節の内容】
- 数式読解編
トピック追跡モデルに対する周辺化ギブズサンプリングを数式で確認します。
