はじめに
『トピックモデル』(MLPシリーズ)の勉強会資料のまとめです。各種モデルやアルゴリズムを「数式」と「プログラム」を用いて解説します。
本の補助として読んでください。
この記事では、対応トピックモデルで登場する数式の行間を埋めます。
【前節の内容】
【他の節の内容】
【この節の内容】
5.2 対応トピックモデルの生成モデルの導出
対応トピックモデル(Corr-LDA・correspondence topic model)の定義(仮定)を確認する。対応トピックモデルでは、文書集合(単語情報)と依存関係のある補助情報を扱う。
トピックモデル(LDA・latent Dirichlet allocation)の定義や共通する記号類については「4.1:トピックモデルの生成モデルの導出【青トピックモデルのノート】 - からっぽのしょこ」、依存関係のない場合については「5.1:結合トピックモデルの生成モデルの導出【青トピックモデルのノート】 - からっぽのしょこ」を参照のこと。
生成過程の設定
まずは、対応トピックモデルの生成過程(generative process)を数式で確認する。ただし、基本形のトピックモデルと共通する内容については省略する。アルゴリズムについては図5.5を参照のこと。
文書 の補助情報数を
、補助情報番号(インデックス)を
とする。
補助情報の種類数(ユニーク補助情報数)を 、種類番号を
とする。
文書 に含まれる(出現した)
番目の補助情報を
で表す。各補助情報
の値として種類番号
をとることで、その補助情報の種類を表す。
また、補助情報 が種類
であることを明示的に
と書くこともある。各補助情報を「文書
の
番目の補助情報」や「補助情報
」などと呼ぶ。
各文書の 個の補助情報を集合
として扱い、文書
の補助情報集合と呼ぶ。
文書ごとに補助情報集合を持ち、 個の補助情報集合を集合
として扱い、補助情報集合と呼ぶ。
補助情報 が持つ(割り当てられた)トピックを
で表す。各補助情報のトピック
の値としてトピック番号
をとることで、その補助情報のトピックを表す。
また、補助情報のトピック が
であることを明示的に
と書くこともある。各補助情報のトピックを「補助情報
のトピック」や「トピック
」などと呼ぶ。
文書 の
個の補助情報のトピックを集合
として扱い、文書
の補助情報トピック集合と呼ぶ。
文書ごとに補助情報トピック集合を持ち、 個の補助情報トピック集合を集合
として扱い、補助情報トピック集合と呼ぶ。
トピックは観測できないデータであるため潜在変数や潜在トピックとも呼ばれる。
各文書の単語トピック集合 (
個の単語に割り当てられたトピック)におけるトピックごとの割合をまとめて、
次元ベクトル
とする。
は、文書
の補助情報にトピック
が生成される(割り当てられる)確率に対応する。
は文書
の補助情報トピック分布のパラメータと言え、カテゴリ分布のパラメータとして用いる。
の各要素は、非負の分子(各トピックの単語数)の総和が分母(全トピックの単語数)と一致
するので、カテゴリ分布のパラメータの条件(非負の値で総和が1になる値)を満たす。
各補助情報のトピック は、文書に応じた
をパラメータとするカテゴリ分布に従って独立に生成されると仮定する。
文書中の単語に割り当てられなかった( の)トピック
は、対応するパラメータ(生成確率)が
になるので、補助情報のトピックとして生成されない。単語トピックとして割り当てられた数が多いほど、パラメータが大きく(生成確率が高く)なるので、補助情報トピックとして生成されやすくなる。
トピック の補助情報に対して種類(内容)
が生成される(出現する)確率を
で表す。
各種類に対応する 個の生成確率をまとめて、
次元ベクトル
で表す。
をトピック
の補助情報分布のパラメータと呼び、カテゴリ分布のパラメータとして用いる。
はカテゴリ分布のパラメータなので、各要素は非負の値であり、総和(全ての種類に関する和)が1になる条件を満たす必要がある。
トピックごとに補助情報分布(のパラメータ)を持ち、 個のパラメータを集合
として扱い、補助情報分布のパラメータ集合と呼ぶ。
また、各トピックの補助情報分布のパラメータ (
の各要素)は、(トピックに関わらず)
をパラメータとするディリクレ分布に従って独立に生成されると仮定する。
ディリクレ分布の確率変数は、カテゴリ分布のパラメータの条件(非負の値で総和が1になる値)を満たす。
は
次元ベクトルであり、補助情報分布のハイパーパラメータ(超パラメータ)と呼ぶ。
はディリクレ分布のパラメータなので、各要素は正の値の条件を満たす必要がある。
は
に影響する。
各補助情報 の種類(内容)は、補助情報に割り当てられたトピックに応じた
をパラメータとするカテゴリ分布に従って独立に生成されると仮定する。
文書集合 とも独立して生成される。
以上で、対応トピックモデルの生成過程(定義・仮定)を確認した。生成過程は、変数やパラメータ間の依存関係であり、生成モデルや推論アルゴリズムの導出でも用いる。
スポンサードリンク
記号一覧
続いて、トピックモデル(4章)に加えて対応トピックモデル(5.2節)で用いる記号類を表にまとめる。
| 記号 | 意味 | 制約・関係性 |
|---|---|---|
| |
補助情報の種類数 | |
| |
補助情報の種類(ユニーク補助情報)インデックス | |
| |
文書 |
|
| |
全文書におけるトピック |
|
| |
文書 |
|
| |
トピック |
|
| |
文書 |
|
| |
補助情報集合 | |
| |
文書 |
|
| |
文書 |
|
| |
補助情報トピック集合 | |
| |
文書 |
|
| |
補助情報 |
|
| |
文書 |
|
| |
文書 |
|
| |
補助情報分布のパラメータ集合 | |
| |
トピック |
|
| |
トピック |
|
| |
補助情報分布のハイパーパラメータ | |
| |
|
|
ハイパーパラメータ が一様な(全て同じ)値の場合
は、
次元ベクトル
をスカラ
で表す。
補助情報トピック集合 に対して、
を単語トピック集合と呼ぶ。
以上の記号を用いて、対応トピックモデルやその推論アルゴリズムを定義する。
スポンサードリンク
尤度関数の導出
次は、対応トピックモデルにおける尤度関数(likelihood function)を数式で確認する。
パラメータ が与えられた(条件とする)ときの観測データ
の生成確率(結合分布)は、生成過程(依存関係)に従い次のように変形できる。
途中式の途中式(クリックで展開)
- 1: 文書ごとの積に分解する。
- 2: 周辺化された潜在変数
を明示する。
- 3: 観測・潜在変数
の項を分割する。
- 4: 単語・補助情報ごとの積に分解する。
- 5: 周辺化された潜在変数
を明示する。
- 6: 補助情報に関する変数
の項を分割する。
さらに、具体的な式に置き換えて、式を整理する。
途中式の途中式(クリックで展開)
- 1: それぞれカテゴリ分布を仮定しているので、各変数がとる値(インデックス)のパラメータが生成確率に対応する。
- 2: 単語番号
を用いた式から、語彙番号
を用いた式に変換する。
個の単語に対応するパラメータ
について、各単語に割り当てられた語彙番号
を用いて語彙ごとにまとめると、
個の
に置き換えられる。
- 2: 補助情報番号
を用いた式から、補助情報の種類番号
を用いた式に変換する。
個の補助情報に対応するパラメータ
について、各補助情報に割り当てられた種類番号
を用いて種類ごとにまとめると、
個の
に置き換えられる。
ここで、 は、全ての単語トピックの組み合わせに関する和を表す。
トピック分布・単語分布・補助情報分布のパラメータ(と語彙頻度・補助情報頻度)を用いた式が得られた。
スポンサードリンク
生成モデルの導出
続いて、対応トピックモデルの生成モデル(generative model)を数式で確認する。
観測変数 、潜在変数
、パラメータ
、ハイパーパラメータ
をそれぞれ確率変数とする結合分布(同時分布)は、生成過程(依存関係)に従い次のように変形できる。
途中式の途中式(クリックで展開)
- 1: 変数やパラメータごとの項に分割する。
観測変数、潜在変数、パラメータ、ハイパーパラメータごとに項を分割する。
さらに1つ目の項の、独立な観測変数の項を分割する。
2つ目の項の、依存関係のある潜在変数の項を分割する。
3つ目の項の、独立なパラメータの項を分割する。
4つ目の項の、独立なハイパーパラメータの項を分割する。
確率変数と依存関係のない条件を適宜省いている。
- 2: 文書・トピックごとの積に分解する。
- 3: 単語・補助情報ごとの積に分解する。
この式自体が変数やパラメータ間の依存関係を表している。
スポンサードリンク
グラフィカルモデル
最後は、対応トピックモデルの生成モデルをグラフィカルモデル表現(graphical model representation)で確認する。
対応トピックモデルの生成モデルは、次の式に分解できた。
この式をグラフィカルモデルにすると、次の図になる。
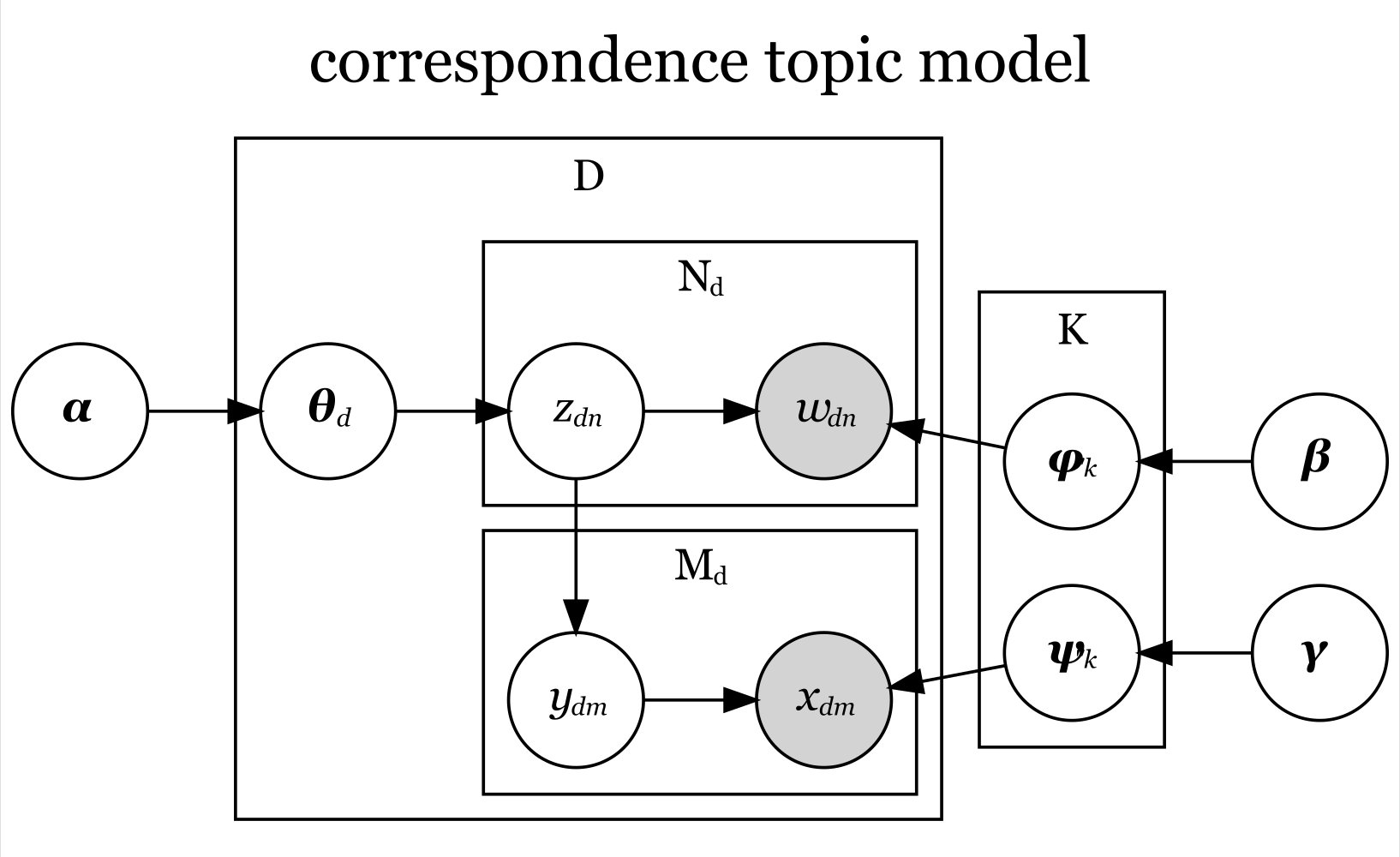
「 」が、各文書の補助情報に対するトピック分布
に対応し、単語トピック集合(の各トピックの割合)に従って各補助情報のトピック
が生成されることを示している。
「 」と「
」が、補助情報に割り当てられたトピックの補助情報分布
に対応し、補助情報分布(のパラメータ)に従って各補助情報(の種類)
が生成されることを示している。
「 」が、補助情報分布のパラメータの事前分布
に対応し、事前分布(のパラメータ)に従って補助情報分布のパラメータ
が生成されることを示している。
「 」のプレートが、
に対応し、
個の単語分布と補助情報分布のパラメータ
が繰り返し生成されることを示している。
「 」のプレートが、
に対応し、
個のトピック
と補助情報
が繰り返し生成されることを示している。
「 」のプレートが、
に対応し、
個のトピック集合
と単語集合
、補助情報集合
、またトピック分布のパラメータ
が繰り返し生成されることを示している。
その他の関係(ノードとエッジ)についてはトピックモデル(4.1節)と同じである。
この記事では、対応トピックモデルで用いる記号や定義を確認した。次の記事では、崩壊型ギブスサンプリングによるパラメータの計算式を導出する。
参考書籍
おわりに
丸1日で解けました!いやぁ気持ちいい。前節のは1週間ほど唸ってました。まぁ理解してみれば前節とそう変わらないから当然と言えば当然なんですがね。でも変わらないことを理解するのに半日、違うところへの理解を深めるのに半日かかるんですよ。
さて次節はこれを更に複雑にしたものですが、どれくらいかかるでしょうか。
2020年10月6日は、アンジュルムの橋迫鈴ちゃんのお誕生日!夢見る15歳♪
(ちなみにサムネの方ではないです。)
- 2024.10.04:加筆修正の際に「対応トピックモデルの崩壊型ギブスサンプリングの導出:一様なハイパーパラメータの場合」を記事から独立しました。
解けました!って言ってるのは主に次の記事の内容です。
【次節の内容】
- 数式読解編
対応トピックモデルに対する周辺化ギブズサンプリングを数式で確認します。
ノイズあり対応トピックモデルの生成モデルを数式で確認します。
