はじめに
『トピックモデル』(MLPシリーズ)の勉強会資料のまとめです。各種モデルやアルゴリズムを「数式」と「プログラム」を用いて解説します。
本の補助として読んでください。
この記事では、ユニグラムモデルで登場する数式の行間を埋めます。
【前節の内容】
【他の節の内容】
【この節の内容】
2.2 ユニグラムモデルの生成モデルの導出
ユニグラムモデル(unigram model)の定義(仮定)を確認する。
文書集合(語彙頻度データ)については「2.1:トピックモデルの文書表現【青トピックモデルのノート】 - からっぽのしょこ」を参照のこと。
生成過程の設定
まずは、ユニグラムモデルの生成過程(generative process)を数式で確認する。アルゴリズムについては図2.2を参照のこと。
語彙数を 、語彙番号(インデックス)を
とする。
文書中に語彙 が生成される(出現する)確率を
で表す。
各語彙に対応する 個(全て)の生成確率まとめて、
次元ベクトル
で表す。
を単語分布のパラメータと呼び、カテゴリ分布のパラメータとして用いる。(語意的には語彙分布と呼ぶ方が分かりやすいかもしれない。)
はカテゴリ分布のパラメータなので、各要素は非負の値であり、総和(全ての語彙に関する和)が1になる条件を満たす必要がある。
ある単語 として出現した語彙の生成(出現)確率を
と書くこともある。例えば、文書
の
番目の単語として語彙
が観測された(出現した)
のとき、対応するパラメータ(確率)は
である。
また、単語分布のパラメータ は、
をパラメータとするディリクレ分布に従って生成されると仮定する。
ディリクレ分布の確率変数は、カテゴリ分布のパラメータの条件(非負の値で総和が1になる値)を満たす。
は
次元ベクトルであり、単語分布のハイパーパラメータと呼ぶ。パラメータのパラメータをハイパーパラメータ(超パラメータ)と言う。
はディリクレ分布のパラメータなので、各要素は正の値の条件を満たす必要がある。
は
に影響する。
各単語 の語彙は、(文書や単語に関わらず)
をパラメータとするカテゴリ分布に従って独立に生成されると仮定する。
トピックモデル(などの各種モデル)では、各単語はカテゴリ分布の確率変数として扱い、単語の語彙(確率変数の実現値)は文脈を考慮せずに 面の歪んだサイコロを振った出目のように決まる(生成される)とする。
以上で、ユニグラムモデルの生成過程(定義・仮定)を確認した。生成過程は、変数やパラメータ間の依存関係であり、生成モデルや推論アルゴリズムの導出でも用いる。
スポンサードリンク
記号一覧
続いて、ユニグラムモデル(2章)で用いる記号類を表にまとめる。
| 記号 | 意味 | 制約・関係性 |
|---|---|---|
| |
文書数 | |
| |
文書インデックス | |
| |
語彙数(単語の種類数) | |
| |
語彙インデックス | |
| |
全文書の単語数 | |
| |
文書 |
|
| |
全文書における語彙 |
|
| |
文書 |
|
| |
文書 |
|
| |
文書集合 | |
| |
文書 |
|
| |
文書 |
|
| |
単語分布のパラメータ | |
| |
語彙 |
|
| |
単語分布のハイパーパラメータ | |
| |
|
|
ハイパーパラメータ が一様な(全て同じ)値の場合
は、
次元ベクトル
をスカラ
で表す。
以上の記号を用いて、ユニグラムモデルやその推論アルゴリズムを定義する。
スポンサードリンク
尤度関数の導出
次は、ユニグラムモデルにおける尤度関数(likelihood function)を数式で確認する。パラメータが与えられたときのデータの生成確率(観測された全ての単語の同時確率)を尤度と呼ぶ。尤度については2.3節、事前分布(事前確率)については2.4節を参照のこと。
尤度の場合
最尤推定(2.3節)では、事前分布を導入せずに、尤度関数を扱う。
パラメータ が与えられた(条件とする)ときの観測データ
の生成確率
は、生成過程(依存関係)に従い次のように変形できる。
途中式の途中式(クリックで展開)
依存関係のない場合は条件付き独立 により、式を変形していく。
- 1:
個の文書は独立(互いに影響せず)に生成されることから、文書集合
の生成確率は、各文書
の生成確率の積に分解できる。
- 2: 各文書(単語集合)の
個の単語は独立(前後の文脈などを考慮せず)に生成されることから、単語集合
の生成確率の積に分解できる。
さらに、確率分布を具体的な式に置き換えて、式を整理する。
途中式の途中式(クリックで展開)
- 1: 各単語の語彙
- 2: 各単語の語彙
と全文書での各語彙の出現回数
を用いて、文書番号
と単語番号
を用いた式(表現)から、語彙番号
を用いた式(表現)に変換する。
添字に具体的な値を入れると の区別ができなくなるので、
を
、
を
としている。
各単語の語彙 に対応する
個の
を、文書番号
と単語番号
の順番に並んだ状態(2行目)から、語彙番号
の順番に並べ替えて(3行目)、語彙ごとに(同じ語彙が出現した
個の要素を)まとめて(4行目)いる。
なので、全体の要素数は変わっていない。
単語は、重複を許す表現であり、同じ語彙でも別の語として扱う。そのため、 個(全ての単語)の確率値
の添字が全て異なり、文書ごとに
個の積を
で表せる。同じ語彙の確率であれば値は同じである。
一方で語彙は、重複を許さない表現であり、同じ語彙(同じ文字列の語)を同じ語として扱う。そのため、 個の確率値
について同じ語彙であれば添字が同じであり、語彙ごとに
個の積を
で表せる。
例えば、文書1の1番目と8番目の単語 と文書3の5番目の単語
が同じ語彙
だったとする。これは、1番目の語彙
が
回出現した言える。このとき、(他の単語は除いた)3単語の生成確率は、次のように表せる
単語分布のパラメータと語彙頻度を用いた式が得られた。
周辺尤度の場合
ハイパーパラメータ推定(2.7節)では、事前分布を導入して、尤度関数のパラメータを周辺化した周辺尤度関数(marginal likelihood function)として扱う。
ハイパーパラメータ が与えられた(条件とする)ときのパラメータ
を周辺化した観測データ
の生成確率
は、生成過程(依存関係)に従い次のように変形できる。
途中式の途中式(クリックで展開)
- 1: 周辺化された単語分布のパラメータ
を明示する。
- 2:
の項に分割する。
詳しくは「生成モデルの導出」で確認する。
- 3-4: 「尤度の場合」と同様にして、尤度を分解する。
さらに、確率分布を具体的な式に置き換えて、式を整理する。
途中式の途中式(クリックで展開)
- 1: 各単語の語彙
- 2:
の外に出す。
- 2: 「尤度の場合」と同様にして、
の項を
の項に変換する。
- 3:
をまとめる。
- 4: 指数法則
より、
- 6: ディリクレ分布の正規化項(1.2.4項)より、積分全体を正規化項の逆数に置き換える。
- 7: 分母を入れ替えて
の項をそれぞれまとめる。
- 7: 各語彙の出現回数
の関係より、
である。
事前分布を導入した場合は、ポリヤ分布の式が得られた。
スポンサードリンク
生成モデルの導出
続いて、ユニグラムモデルの生成モデル(generative model)を数式で確認する。文書集合やパラメータを全て確率変数とみなした結合分布(同時分布)を生成モデルと呼ぶ。
事前分布を設定しない場合
先に、事前分布を含めない場合を考える。ただし以降の節では、こちらの式は使わない。
観測変数 とパラメータ
をそれぞれ確率変数とする結合分布は、生成過程(依存関係)に従い次のように変形できる。
途中式の途中式(クリックで展開)
- 1: 乗法定理
より、依存関係のある変数とパラメータの項を分割する。
- 2-3: 「尤度関数の導出」のときと同様にして、尤度を分解する。
単語レベルに分解した。
事前分布を設定する場合
最大事後確率推定(2.4節)とベイズ推定(2.5節)では、事前分布を導入する。
観測変数 とパラメータ
、ハイパーパラメータ
をそれぞれ確率変数とする結合分布は、生成過程(依存関係)に従い次のように変形できる。
途中式の途中式(クリックで展開)
依存関係のない場合は条件付き独立 、依存関係のある場合は条件付きの乗法定理
により、式を変形していく。
- 1: 変数やパラメータごとの項に分割する。
依存関係のある変数・パラメータとハイパーパラメータの項を分割する。
さらに前の項の、依存関係のある変数とパラメータの項を分割する。
と
は無関係なので条件から省ける。
- 2-3: 「尤度関数の導出」のときと同様にして、尤度を分解する。
この式自体が変数やパラメータ間の依存関係を表している。
スポンサードリンク
グラフィカルモデルの確認
最後は、ユニグラムモデルの生成モデルをグラフィカルモデル表現(graphical model representation)で確認する。グラフィカルモデルについては4.2節(図4.3)を参照のこと。
事前分布なしの場合
最尤推定(2.3節)では、こちらのモデルが対応する。
事前分布を設定しない場合のユニグラムモデルの生成モデルは、次の式に分解できた。
この式をグラフィカルモデルにすると、次の図になる。
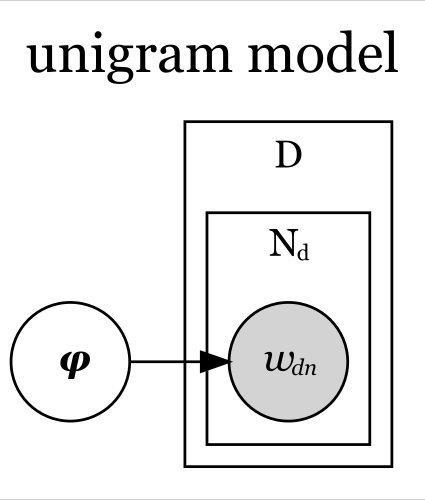
「 」が、単語分布
に対応し、単語分布(のパラメータ)
に従って各単語(の語彙)
が生成されることを示している。
「 」のプレートが、
に対応し、
個の単語
が繰り返し生成されることを示している。
「 」のプレートが、
に対応し、
個の文書
が繰り返し生成されることを示している。
事前分布ありの場合
最大事後確率推定(2.4節)とベイズ推定(2.5節)では、こちらのモデルが対応する。
事前分布を設定する場合は、次の式になった。
この式をグラフィカルモデルにすると、次の図になる。
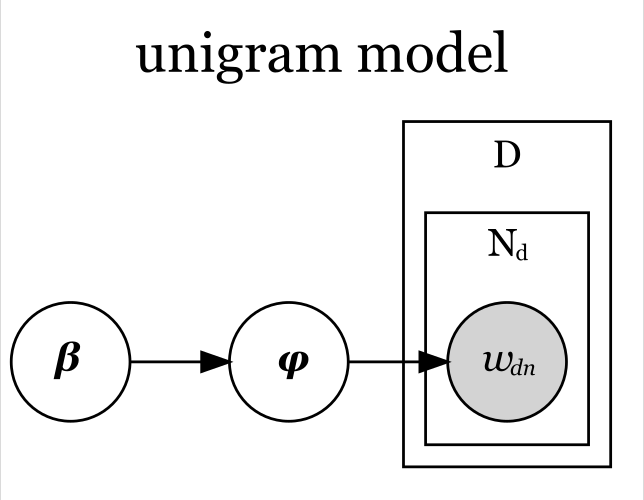
「 」が、単語分布のパラメータの事前分布
に対応し、事前分布(のパラメータ)に従ってパラメータ
が生成されることを示している。
この記事では、ユニグラムモデルで用いる記号や定義を確認した。次の記事では、生成モデルを実装して、各種推論アルゴリズムに用いる人工データを作成する。
参考書籍
おわりに
2020/07/01:加筆修正の際に「ユニグラムモデルの最尤推定」から記事を分割しました。
この一連の記事は、勉強会の中で作った資料を1節ずつくらいの目安で転載したものです。なので何となく1章から順番に読まれることを想定していました(というか、数学分からーんってめちゃくちゃ困ってる人(1年ちょっと前の私)がこのブログに流れ付いて攻略本的に使ってもらうイメージでした)。なので例えばこの表記やモデルの説明の節だと、それを使った具体例として次節の最尤法とセットにしてユニグラムモデルの最尤推定というタイトルにしていました。
しかし(いや当然)、何らかのキーワードで検索に引っかかったその記事だけ読む(あるいは読まない)わけです。となると、次々節のMAP法やその次のベイズ推定の節を読むときにモデルを確認したくなったら、最尤推定の記事の前半だけ読むことになるわけです。これは分かり辛いよなーと分割した次第です。
あと関係ないですが、箇条書きの数字を2とか3から始めても1からにしちゃうのははてなさんの仕様ですか?何とかする方法はありませんかね?
- 2024.04.26:加筆修正の際に記事から「トピックモデルの文書表現」を分割しました。
1つ前の記事(分割した記事)のあとがきに(作業的には数分前に)一歩ずつ段階を踏んで着実に進めましょうと書いたのですが、この記事では筆がノって色々書き足しました。文量がとても増えました。
面白そうだから事前分布あり版の尤度の数式も見てみよう、とノリで書いたところほぼ同じ式展開を2.7節にてn年前に書いてました。
あとがきに書くのもアレですが、事前分布の話などは本編で登場した段階で必要な分だけを辞書的に読んでもらい、2章を読み終えた段階で3手法のモデル(事前分布の有り無し)の比較のために読み返してもらい、さらに4章まで読み終わったらモデル(混合化や階層化)の比較のために各モデルの記事(この記事に相当する記事)を読み比べてもらえば分かりやすいだろうという意図で再構成しました。
他の記事の修正状況は、終わってたり途中だったりメンドそうで飛ばしてたりします。
数字付きの箇条書きを使うのは諦めて(ダサいけど)数字付き風に書くことにしました。
現在は表を横スクロールできるようにしようと思ったら、markdown記法と併用できないらしく悩み中です。
【次節の内容】
- スクラッチ実装編
ユニグラムモデルの生成モデルをプログラムで確認します。
- 数式読解編
ユニグラムモデルに対する最尤推定を数式で確認します。
混合ユニグラムモデルの生成モデルを数式で確認します。
