はじめに
昨日のAWS Trainium 3の記事に続いて、Trainium 3の詳細を Document から探っていきます。
Trainium3 Architecture
awsdocs-neuron.readthedocs-hosted.com
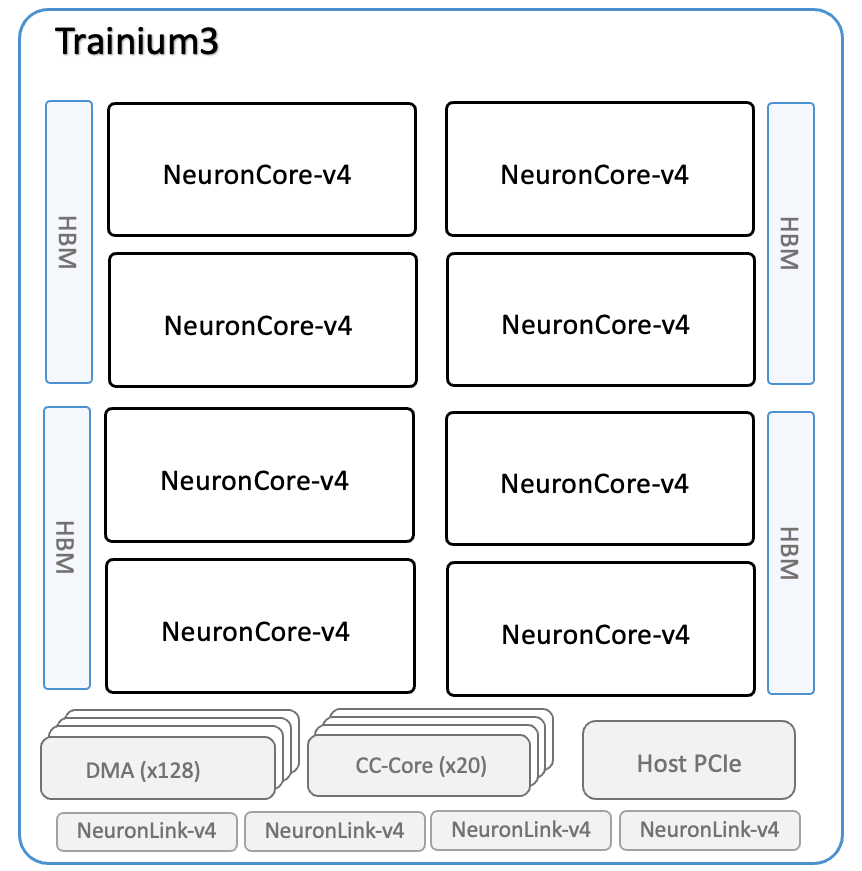
の内容から、下記の図を引用します。
Trainium 2 と並べてみたが、全く変わらない。
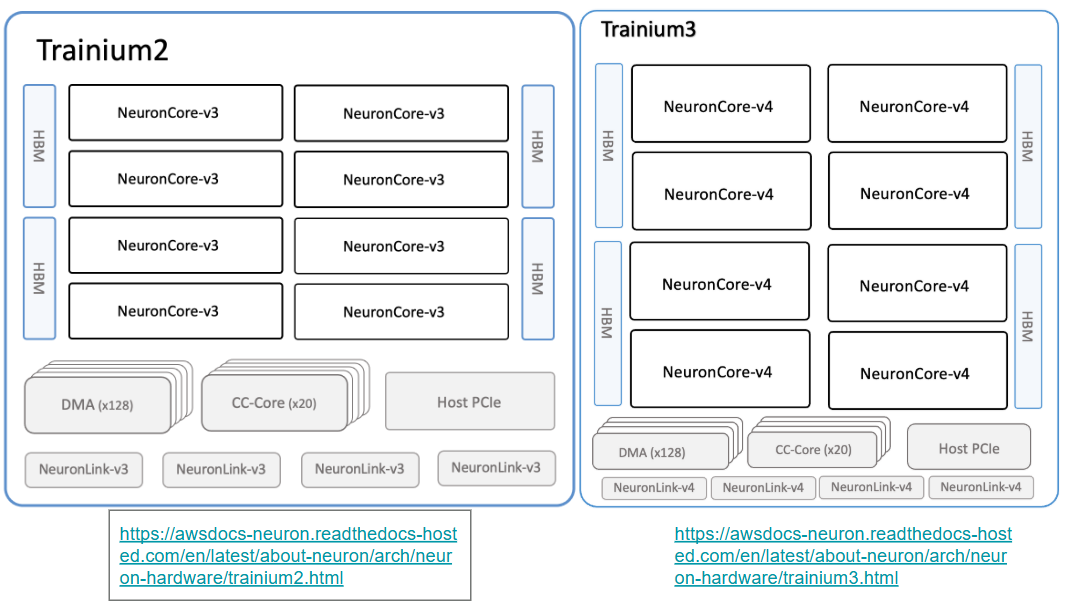
NeuronCore v3 (Trainium 2)
- 1,299 FP8 TFLOPS
- 667 BF16/FP16/TF32 TFLOPS
- 2,563 FP8/FP16/BF16/TF32 sparse TFLOPS
- 181 FP32 TFLOPS
- 96 GiB of device memory with 2.9 TB/sec of bandwidth
- 3.5 TB/sec of DMA bandwidth, with inline memory compression and decompression
- NeuronLink-v3 for chip-to-chip interconnect provides 1.28 TB/sec bandwidth per chip. It allows for efficient scale-out training and inference, as well as memory pooling between Trainium2 chips.
NeuronCore v4 (Trainium 3)
- 2,517 MXFP8/MXFP4 TFLOPS
- 671 BF16/FP16/TF32 TFLOPS
- 2,517 FP16/BF16/TF32 sparse TFLOPS
- 183 FP32 TFLOPS
- 144 GiB of device memory, with 4.9 TB/sec of bandwidth.
- 4.9 TB/sec of DMA bandwidth, with inline computation
- NeuronLink-v4 for device-to-device interconnect provides 2.56 TB/sec bandwidth per device. It enables efficient scale-out training, as well as memory pooling between the different Trainium3 devices.
NeuronCore v4
- Each NeuronCore-v4 has a total of 32MiB of on-chip SRAM (v3 は、28MB)
Tensor Engines support mixed-precision computations, including MXFP8/MXFP4, FP16, BF16, TF32, and FP32 inputs. The output data type can either be FP32 or BF16. (v3 は、cFP8, FP16, BF16, TF32, and FP32)
Vector Engines are highly parallelized, and deliver a total of 1.2 TFLOPS of FP32 computations (v3 は、1 TFLOPS)
おわりに
Trainium 3は、Trainium 2 の 強化版、MXFP8/MXFP4 で Trainium 2 の2倍。メモリ容量 1.5倍。メモリ帯域2倍弱。って感じですね。
