Windowsでのllama.cppのインストールに関して自分用にまとめておこうと思います。OllamaやLM Studioはインストーラーがありますが、llama.cppはインストールがないので、一旦まとめておきます。 これは、動作させる環境がCPUのみ、CUDAあり、その他環境もありと場合分けもあるためです。Linuxではバイナリのビルドを行えばいいのですが、Windowsでは開発環境がデフォルトではないのでまとめておきます。
このドキュメントの注意点
先ほども書いたのですが、今回は動作環境が複雑なので行う各手順について、対象となる環境を示す絵文字を付けています。 自分の環境に該当する絵文字が付いた手順のみを実行してください。
| 絵文字 | 対象環境 | 説明 |
|---|---|---|
| 🔵 | すべての環境 | 全員が実行する共通手順 |
| 🟢 | NVIDIA GPU(CUDA) | NVIDIA GeForce / RTX シリーズを使う場合 |
| 🟠 | AMD / Intel GPU(Vulkan) | AMD Radeon や Intel Arc を使う場合 |
| ⚪ | CPUのみ | GPU を使わず CPU だけで動かす場合 |
⚠️ 自分の環境がわからない場合 タスクマネージャー(Ctrl+Shift+Esc)→「パフォーマンス」タブ → 「GPU」で確認できます。GPU が「NVIDIA GeForce ~」なら 🟢、「AMD Radeon ~」や「Intel Arc ~」なら 🟠、GPU の項目がなければ ⚪ になると思います。
動作環境について
- Windows 10/11(64bit)
- 管理者権限があること
- インターネット接続
- このドキュメントの注意点
- 動作環境について
- 手順1 🔵: llama.cppのダウンロード
- 手順2 🔵: ファイルの展開と配置
- 手順3 🔵: 環境変数PATHの設定
- 手順4 🔵: モデルの入手と実行
- 手順5 🔵: 対話モードでの使い方
- 補足1 🔵: OpenAI互換APIサーバーとして使う
- 補足2 🟠: Vulkan環境の補足情報
- トラブルシューティング
手順1 🔵: llama.cppのダウンロード
1-1. GitHubリリースページを開く
以下のURLにアクセスします。
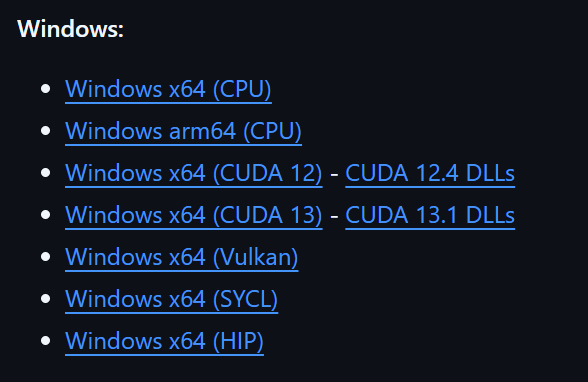
1-2. 自分の環境に合ったバイナリをダウンロード
最新リリース(例: b8123)の「Assets」セクションを展開し、自分の環境の絵文字に対応するファイルをダウンロードします。
| 絵文字 | ダウンロードするファイル | 備考 |
|---|---|---|
| 🟢 | llama-b8123-bin-win-cuda-12.4-x64.zip |
CUDA 12.x 用 |
| 🟢 | cudart-llama-bin-win-cuda-12.4-x64.zip |
↑ とセットで必要 |
| 🟠 | llama-b8123-bin-win-vulkan-x64.zip |
AMD / Intel GPU 用 |
| ⚪ | llama-b8123-bin-win-cpu-x64.zip |
CPUのみ |

⚠️ バージョン番号(b8123)はリリースごとに変わります。ページ上の最新版をダウンロードしてください。
🟢 CUDAバージョンの確認方法 コマンドプロンプトで
nvidia-smiを実行すると、右上に「CUDA Version: 12.x」のように表示されます。CUDA 13.x の場合はwin-cuda-13.1-x64を選んでください。
手順2 🔵: ファイルの展開と配置
2-1 🔵: 本体ZIPファイルを展開
ダウンロードした llama-bXXXX-bin-win-***.zip を右クリック →「すべて展開」で解凍します。
2-2 🔵: フォルダを配置
展開されたフォルダを任意の場所に移動します。以下はおすすめの配置例です。
C:\Program Files\llama-cpp
フォルダ名はわかりやすくリネームしてOKです(例:
llama-cpp)。
2-3 🟢: CUDA DLLのコピー
⚠️ この手順は 🟢 NVIDIA GPU(CUDA)環境のみ必要です。🟠 Vulkan や ⚪ CPU の方は手順3へ進んでください。
CUDA DLLのZIPファイル(cudart-llama-bin-win-cuda-*.zip)も展開し、中に入っている すべてのDLLファイル を、手順2-2で配置した llama.cpp のフォルダにコピーします。
コピー元: cudart-llama-bin-win-cuda-12.4-x64/ 内のすべての .dll ファイル コピー先: C:\Program Files\llama-cpp\
⚠️ この手順を忘れるとGPU(CUDA)が使えず、エラーになります。
手順3 🔵: 環境変数PATHの設定
llama.cppのコマンドをどこからでも実行できるように、PATHに追加します。
3-1. 配置フォルダのパスをコピー
エクスプローラーでllama.cppを配置したフォルダを開き、アドレスバーのパスをコピーします。
例: C:\Program Files\llama-cpp
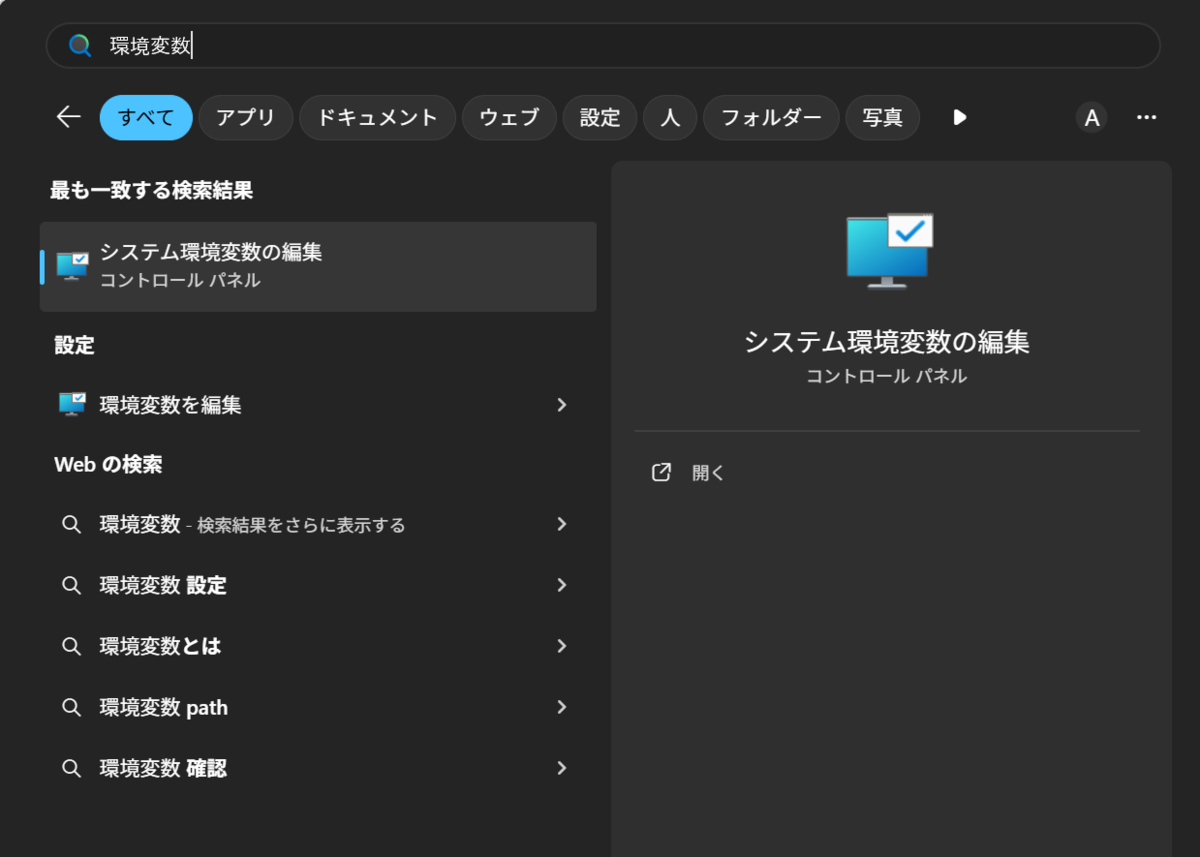
3-2. 環境変数の設定画面を開く
- Windowsキーを押して 「環境変数」 と検索
- 「システム環境変数の編集」をクリック
- 「環境変数(N)...」ボタンをクリック
3-3. PATHに追加
- 「システム環境変数」セクションの
Pathを選択し、「編集(I)...」をクリック - 「新規(N)」をクリック
- コピーしたパス(例:
C:\Program Files\llama-cpp)を貼り付け - 「OK」を3回押してすべてのダイアログを閉じる



⚠️ 管理者権限が必要です。ユーザー環境変数の Path に追加しても動作します。
3-4. 動作確認
新しいコマンドプロンプトを開き(既に開いているものは環境変数が反映されていません)、以下を実行します。
> llama-cli --version
バージョン情報が表示されれば、PATH設定は成功です。

手順4 🔵: モデルの入手と実行
llama.cppで推論を行うには、GGUF形式のモデルファイルが必要です。
方法A Hugging Faceから直接ダウンロード&実行(推奨・簡単)
最新のllama.cppでは -hf オプションで Hugging Face から直接モデルをダウンロードして実行できます。手動ダウンロード不要で最も簡単です。
👉モデルファイルはC:\Users\【ユーザー名】\AppData\Local\llama.cpp\に格納されます。
> llama-cli -hf ggml-org/gemma-3-1b-it-GGUF
初回実行時にモデルが自動でダウンロード・キャッシュされます、そのため時間がかかりますが、2回目以降はキャッシュから読み込まれるので即利用可能になります。

テスト用のおすすめの軽量モデル
| モデル | コマンド | 特徴 |
|---|---|---|
| Gemma 3 1B | llama-cli -hf ggml-org/gemma-3-1b-it-GGUF |
軽量、初心者向け |
| Llama 3.2 3B | llama-cli -hf bartowski/Llama-3.2-3B-Instruct-GGUF |
バランス型 |

⚠️ -hf の後に ユーザー名/リポジトリ名 を指定するだけで、自動的に適切な量子化バージョンが選択されます。特定の量子化レベルを指定したい場合は ユーザー名/リポジトリ名:Q4_K_M のようにコロンでも指定できます。
方法B GGUFファイルを手動ダウンロードして実行
- Hugging Face(https://huggingface.co)でGGUF形式のモデルを検索・ダウンロード
- ダウンロードしたファイルを任意のフォルダに保存(例:
C:\Users\【ユーザー名】\Documents\models\) - コマンドプロンプトで以下を実行
> llama-cli -m C:\Users\ユーザー名\Documents\models\モデル名.gguf
手順5 🔵: 対話モードでの使い方
上記コマンドを実行すると、モデルが読み込まれ、対話プロンプトが表示されます。
> こんにちは、あなたは誰ですか?
のように質問を入力して【Enter】キーを押すと、AIが回答を生成します。

よく使うオプション
🟢🟠 GPU環境向け
# GPU レイヤー数を指定(多いほどGPU活用、99で全レイヤーGPU) > llama-cli -hf ggml-org/gemma-3-1b-it-GGUF -ngl 99
⚪ CPU環境向け
# スレッド数を指定(CPUコア数に合わせて調整) > llama-cli -hf ggml-org/gemma-3-1b-it-GGUF -t 4
🔵 共通
# コンテキスト長を指定 > llama-cli -hf ggml-org/gemma-3-1b-it-GGUF -c 4096
終了方法
【Ctrl + C】を押下または、/exitを入力すると終了します。
補足1 🔵: OpenAI互換APIサーバーとして使う
llama.cppにはOpenAI互換のAPIサーバー機能もあります。他のアプリケーションと連携したい場合に便利です。
> llama-server -hf ggml-org/gemma-3-1b-it-GGUF --port 8080
ブラウザで http://localhost:8080 にアクセスすると、Web UIが表示されます。APIエンドポイントは http://localhost:8080/v1/chat/completions で、OpenAI互換のリクエストを受け付けます。


補足2 🟠: Vulkan環境の補足情報
Vulkanは以下のような環境で利用できます。
- AMD Radeon … RX 500シリーズ以降(RX 580などの古い世代も可)、RDNA / RDNA2 / RDNA3 / RDNA4
- AMD APU 内蔵GPU … Radeon 680M(Rembrandt)、Radeon 8060S(Strix Halo)など。ROCm非対応の内蔵GPUでもVulkanなら動作
- Intel Arc … Intel Arc GPU
- NVIDIA GeForce … 動作はするが、高性能なCUDAを推奨
⚠️ Intel GPU(Mesaドライバ)では一部の機能に問題が出る場合があります。その場合は環境変数 GGML_VK_DISABLE_INTEGER_DOT_PRODUCT=1 を設定を試してください。
トラブルシューティング
🔵 「llama-cli は認識されていません」と表示される
- 環境変数PATHの設定後、新しいコマンドプロンプトを開いていますか?
- PATHに正しいフォルダパスが登録されているか確認してください
🟢 CUDAエラーが出る
- CUDA DLLファイルがllama.cppフォルダにコピーされていますか?(手順2-3 🟢)
nvidia-smiでGPUが認識されているか確認してください- CUDAバージョンが合っているか確認してください(12.x → CUDA 12用バイナリ)
🔵 メモリ不足(Out of Memory)エラー
- より小さい量子化レベルのモデルを試してください(Q8_0 → Q4_K_M → Q2_K の順に小さくなります)
- 🟢🟠 GPU環境 …
-nglオプションの値を小さくして、GPUに載せるレイヤー数を減らしてください
🔵 モデルのダウンロードが遅い・失敗する
- Hugging Face へのアクセスに問題がある場合は、手動でGGUFファイルをダウンロードし、上記の方法Bで実行してください
- 環境変数
LLAMA_CACHEでキャッシュフォルダの場所を変更できます
参考リンク
- llama.cpp GitHub: https://github.com/ggml-org/llama.cpp
- llama.cpp リリースページ: https://github.com/ggml-org/llama.cpp/releases
- Hugging Face GGUF モデル検索: https://huggingface.co/models?library=gguf
- GGUF 利用ガイド: https://huggingface.co/docs/hub/en/gguf-llamacpp
