以前のエントリなどでも触れていましたが、Raspberry Pi 5(8GB RAM)でリアルタイム対話可能な日本語LLMは実現可能となりつつあります。それも、特別なハードウェアを使用することなしにです。 これは、1B〜3Bパラメータのモデルでもかなり優秀になってきているからです。そのなかでもGemma3:1b、TinySwallow-1.5B(日本語特化)、Qwen2.5:1.5b〜3bといったモデルが有力な候補となるでしょう。 (7Bクラスは動作はしますがかなり遅く実用性に難あり)
また、プラットフォーム的な話としては、llama.cppはOllamaより10〜20%高速ですが、セットアップの容易さではOllamaが優れています。Ollamaで試してみて、更なる高速化が必要となればllama.cppに乗り換えるというのがいいかもしれません。
今回想定しているハードウェア・OSの要件
- Raspberry Pi 5 8GB RAM
- アクティブ冷却ソリューション(ファン付きヒートシンク)
- NVMe SSD(PCIe HAT経由)
- 5V/5A電源(3Aは最低限、5A推奨)
- Raspberry Pi OS 64-bit Bookworm

1. 推奨されそうなモデルの評価
日本語対応かつRaspberry Pi 5(8GB RAM)(以降RPi5)で快適に動作しそうなものは以下になるでしょう。
推奨されるモデル
| モデル名 | パラメータ | 量子化 | 推論速度 | RAM使用量 |
|---|---|---|---|---|
| TinySwallow-1.5B | 1.5B | Q5_K_M | 8-10 tok/s | ~1.5GB |
| Gemma-2-2B-JPN-IT | 2B | Q4_K_M | 10-15 tok/s | ~1.5GB |
| LFM2.5-1.2B-JP | 1.2B | Q4_K_M | 10-15 tok/s | ~0.8GB |
| RakutenAI-2.0-mini | 1.5B | Q4_K_M | 20-30 tok/s | ~2GB |
| Sarashina-2.2 | 1B/3B | Q4_K_M | 10-15 tok/s | 1.5-4GB |
| llm-jp-3-1.8b-instruct | 1.8B | Q4_K_M | 12-20 tok/s | ~2.5GB |
| plamo-2-1b | 1B | Q4_K_M | 15-25 tok/s | ~1.5GB |
| Qwen2.5:3b | 3B | Q4_K_M | 4-6 tok/s | ~3.0GB |
| Gemma3:1b | 1B | Q8_0 | 11-12 tok/s | ~1.2GB |
| ELYZA-JP-8B | 8B | Q4_K_M | 1-3 tok/s | ~5.0GB |
- TinySwallow-1.5Bは、Sakana AIがQwen2.5-32Bから蒸留して作成した日本語特化モデルで、1.5Bという小さなサイズながら高い日本語品質となっています。
- LFM2.5-1.2B-JPはLiquid AIが開発したエッジデバイス向けモデルの日本語特化版で、1.2Bパラメータながら日本語の知識と指示追従において高い性能があります。
- Gemma-2-2B-JPN-ITはGoogleが公式に日本語ファインチューニングしたモデルで、信頼性が高いです。
- RakutenAI-2.0-miniは楽天が開発した日本語最適化モデルで、1.5Bながら高速な推論が可能です。
- Sarashina-2.2はソフトバンク(SB Intuitions)による日本語特化シリーズで、0.5B/1B/3Bの複数サイズが用意されています。
- llm-jp-3-1.8b-instructはLLM-jpプロジェクトによる純国産モデルで、自然な日本語生成に優れています。
- plamo-2-1bはPFN(Preferred Networks)の日本語特化モデルで、日本語imatrixを使用して最適化されています。
検討されそうな候補
| モデル名 | パラメータ | 量子化 | 推論速度 | RAM使用量 | 日本語性能 | 備考 |
|---|---|---|---|---|---|---|
| Qwen2.5:1.5b | 1.5B | Q4_K_M | 8-10 tok/s | ~1.5GB | ○ 良好 | 3b版がギリギリなら検討 |
| Gemma3-1B 日本語FT | 1B | Q8_0 | 10-12 tok/s | ~1.2GB | ○ 良好 | コミュニティ版、要実測 |
| gemma2:2b | 2B | Q4_K_M | 15-20 tok/s | ~2.5GB | ○ 良好 | Gemma2の小型版、日本語流暢 |
- DeepSeek-R1-Distill 1.5Bは英語寄りではありますが多言語対応で日本語もそこそこ扱えるため、推論速度を優先したい場合に使えるかもしれません。
- Qwen2.5:1.5bは3b版よりコンパクトです。Gemma3-1B 日本語FTはコミュニティによる日本語ファインチューン版で、元になったGemma3:1bより日本語性能が向上している可能性があるとのことです(要検証)。
- gemma2:2bはGoogle Gemma2の小型版で、日本語も流暢に扱えます。
- Llama 3.x系(3B/8B)は、英語中心のモデルであるため本記事では候補からはずしています。
2. Ollamaでの動作モデルと導入方法
Ollamaは最も簡単にLLMを導入できるツールで、RPi5のARM64アーキテクチャにも対応しています。 インストールは以下のように行います。
2.1 インストール手順
# Ollamaのインストール(ARM64を自動検出します) $ curl -fsSL https://ollama.com/install.sh | sh

2.2 モデルインストール方法(2025年末時点)
先程のモデルの中でもOllamaで動作確認が取れているモデルのみをピックアップしています。
| モデル | ディスクサイズ | RAM使用量 | 推論速度 | コマンド |
|---|---|---|---|---|
| gemma3:270m | ~300MB | ~500MB | 25-27 tok/s | ollama run gemma3:270m |
| tinyllama | 638MB | 1.1GB | 17 tok/s | ollama run tinyllama |
| gemma3:1b | 815MB | 1.2GB | 11-12 tok/s | ollama run gemma3:1b |
| gemma2:2b | ~1.6GB | ~2.5GB | 15-20 tok/s | ollama run gemma2:2b |
| llama3.2:1b | ~700MB | 1.3GB | 10-11 tok/s | ollama run llama3.2:1b |
| qwen2.5:1.5b | 988MB | 1.5GB | 8-10 tok/s | ollama run qwen2.5:1.5b |
| llama3.2:3b | 2.0GB | 3.5GB | 4-6 tok/s | ollama run llama3.2:3b |
| qwen2.5:3b | 1.9GB | 2.9GB | 4-5 tok/s | ollama run qwen2.5:3b |
| mistral:7b | 4.1GB | 5-6GB | 0.7-3 tok/s | ollama run mistral:7b |
動作例
gemma3:270m
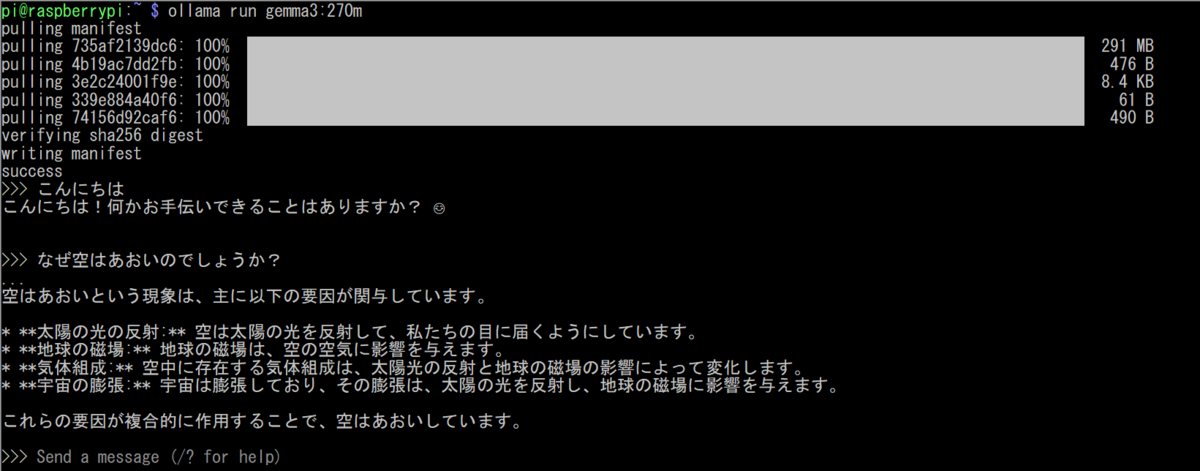
gemma3:1b

llama3.2:1b

qwen2.5:1.5b

※ RakutenAI-2.0-mini、Sarashina-2.2、llm-jp-3などは非公式/コミュニティ版のため、Ollama公式ライブラリには含まれていません。
2.3 WebUIの導入
ブラウザからChatGPTライクなUIでチャットしたい場合は、Open WebUIを導入できます。 WindowsやMacではOllama導入とともにネイティブなWebUIが導入されるのですが、Linux版ではないようです。 そのため、以下のようにOpen WebUIを別途導入します。※Dockerでも導入できます。
# uvのインストール(未導入の場合) $ curl -LsSf https://astral.sh/uv/install.sh | sh $ source $HOME/.local/bin/env # Open WebUIの起動 $ uvx --python 3.11 open-webui serve
ブラウザで http://localhost:8080 にアクセスすると、WebUI上でOllamaと対話が可能です。
⚠️初回起動時は依存関係のダウンロードに時間がかかります。また、Ollamaが起動している必要があります。
※ Python 3.13では依存関係の問題で動作しないため、今回は3.11を指定しています。 ※ 初回起動時は依存関係のダウンロードに時間がかかります。また、Ollamaが起動している必要があります。



ここでは扱いませんが、Open WebUIはDockerでも動作させることも可能です。
参考
# Open WebUIをDockerで起動する例 $ docker run -d -p 3000:8080 \ --add-host=host.docker.internal:host-gateway \ -v open-webui:/app/backend/data \ --name open-webui \ ghcr.io/open-webui/open-webui:main
3. llama.cppでの動作とGGUF量子化モデルの導入
llama.cppは先程のOllamaより10〜20%高速で、より細かなパラメータ制御が可能です。ただし、使用する前にビルド作業が必要となります。
3.1 ビルド手順(OpenBLAS利用)
# 依存パッケージのインストール $ sudo apt update $ sudo apt install -y git build-essential cmake libopenblas-dev # llama.cppのクローンとビルド $ git clone https://github.com/ggml-org/llama.cpp $ cd llama.cpp $ cmake -B build -DGGML_BLAS=ON -DGGML_BLAS_VENDOR=OpenBLAS $ cmake --build build --config Release -j$(nproc)
※RPi5ではARM NEONによる最適化も自動で効くため、OpenBLASの効果は限定的かもしれません。
3.2 モデル実行コマンド例
# モデルダウンロード(汎用モデルの例) $ wget https://huggingface.co/bartowski/Llama-3.2-3B-Instruct-GGUF/resolve/main/Llama-3.2-3B-Instruct-Q4_K_M.gguf # 日本語モデルのダウンロード例 $ wget https://huggingface.co/LiquidAI/LFM2.5-1.2B-JP-GGUF/resolve/main/LFM2.5-1.2B-JP-Q4_K_M.gguf # CLI対話モード $ ./build/bin/llama-cli -m LFM2.5-1.2B-JP-Q4_K_M.gguf \ -p "日本の首都について教えてください" \ -n 256 --ctx-size 1024 --temp 0.7 -t 4 [f:id:ueponx:20260203224704p:plain] # APIサーバーモード $ ./build/bin/llama-server -m LFM2.5-1.2B-JP-Q4_K_M.gguf --host 0.0.0.0 --port 8080 --ctx-size 1024 -t 4
LFM2.5-1.2B-JP-Q4_K_M.gguf


3.3 Hugging Face GGUFリポジトリ
| モデル | リポジトリ |
|---|---|
| LFM2.5-1.2B-JP | LiquidAI/LFM2.5-1.2B-JP-GGUF |
| LFM2.5-1.2B-Instruct | LiquidAI/LFM2.5-1.2B-Instruct-GGUF |
| TinySwallow-1.5B | SakanaAI/TinySwallow-1.5B-Instruct-GGUF |
| Gemma-2-2B-JPN | QuantFactory/gemma-2-2b-jpn-it-GGUF |
| Qwen2.5各サイズ | Qwen/Qwen2.5-{size}-Instruct-GGUF |
| llm-jp-3-1.8b-instruct | alfredplpl/llm-jp-3-1.8b-instruct-gguf |
動作例
TinySwallow-1.5B

Gemma-2-2B-JPN

llm-jp-3-1.8b-instruct

※ RakutenAI-2.0-mini、Sarashina-2.2はHugging FaceでRakutenAI-2.0-mini GGUF、Sarashina GGUFなどで検索してください。
4. おわりに
調べても調べても新しい情報が出てくるAI分野ですが、Raspberry Pi 5 8GB RAMで動作する日本語対応軽量LLMの選択肢は着実に増えています。今回紹介したモデルやツールを活用して、ぜひ自分に合ったLLM環境を構築してみてください。
