すでに一ヶ月ほど経ってしまっていますが、生成AIを使ったアプリ開発、入門編 〜watsonx.ai Dojo #2〜に参加しましたので、そのハンズオン内容の復習レポートとして記してみたいと思います。
参考
前回は概論的な予備知識的な内容でしたが、今回はクラウド上のwatsonx.aiでチャットやPythonのコードを使用した実装を行う内容のハンズオンでした。以前、チャットでの実験は行っていましたが、Pythonコードからの実行はまだできていませんでした。今回のハンズオンでようやくそれを実現することができた形です。
イベントページ
次回は明日開催されます。夏休みの宿題を最終日に片付けるような感覚だったのは秘密です…🤔

次回はプロンプト・エンジニアリングなんですよね。もちろん参加する予定です。
今回の資料はConnpassページにもありますが、念の為こちらにも掲載しておきます。また、最後のPythonでのコードの実行に関しては、初回参加時のエントリーで行った準備作業が必要になります。自分もやってみようという方はそちらも参考にしてください。
資料
目次
- ハンズオンの流れ
- 0)IBM watsonx.aiを使用するための事前準備
- 1)言語モデルを使ったチャット機能を試す
- 2)文書と言語モデルを利用したチャット
- 3)プロンプト・ラボの利用とPythonによるプロンプトの実行
- おわりに
ハンズオンの流れ
今回は大きくわけて3つの部分から構成されていました。
- 言語モデルを使ったチャット機能を試す(watsonx.aiのチャットを使用する)
- 文書と言語モデルを利用したチャット(RAGのような形で情報参照を行うチャット)
- プロンプト・ラボの利用とPythonによるプロンプトの実行(プロンプト・ラボが生成したPythonによる実行)
さらに、IBM Cloudを実行するにあたっての事前準備も必要です。 資料では色々な実行形態がありますが、私は一般的なIBM Cloudのライセンスで行います。
0)IBM watsonx.aiを使用するための事前準備
以降はIBM Cloudのログインが必要になるので、アカウントの発行などを行いログインをお願いします。 ログイン後であれば、説明内のURLをクリックするとその設定ページにいくことができます。
ログイン画面

ログイン後のダッシュボード画面

今回必要になる作業は以下の4つになります。
Cloud Object Storageの作成Watson Studioの作成Watson Machine Learningの作成watsonx.aiのプロジェクトの作成

作成済みかどうかわからない場合は、以下のリンクから確認することができます。
リソース・リスト https://cloud.ibm.com/resources
リスト内の【ストレージ】と【AI/機械学習】の項目が以下の状態になっていなかったら設定が必要です。普段使用している方は、多分分かると思うので、そのあたりは察して操作してください。

0-1)Cloud Object Storageの作成
以下のリンクをクリックしてCloud Object Storageを作成します。
ページリンク
操作
- 【料金プラン】…Standard
- 【作成】ボタンをクリック

作成後の画面

これでCloud Object Storageの作成作業は終了です。
0-2)Watson Studioの作成
以下のリンクをクリックしてWatson Studioを作成します。
ページリンク
操作
- 【ロケーション】… 東京(jp-tok)
- 【プラン】…ライト
- 【以下のご使用条件を読み、同意します】…チェックする
- 【作成】ボタンをクリック

作成後の画面

これでWatson Studioの作成作業は終了です。
0-3)Watson Machine Learningの作成
以下のリンクをクリックしてWatson Machine Learningを作成します。
ページリンク
- 【ロケーション】…東京(jp-tok)
- 【プラン】ライト
- 【以下のご使用条件を読み、同意します】…チェックする
- 【作成】ボタンをクリック

作成後の画面

これでWatson Machine Learningの作成作業は終了です。
設定後にリソース・リストが以下の様になっていれば大丈夫です。
リソース・リスト https://cloud.ibm.com/resources

0-4)IBM watsonx.aiの新規プロジェクト作成
参考 github.com
ここで、watsonx.aiの設定画面にどのように遷移すればいいのか、少し操作に迷ってしまいました⚠️これが正解かよくわからないですが書いておきます。
リソース・リストのWatson Studioをクリックし以下の画面に遷移します。そして、【Launch in】ボタンのプルダウンから【IBM watsonx】を選択します。

すると、watsonx.aiの設定画面にいくことができました。

ボタンのプルダウンではなく、リソース・リストから直接watsonx.aiにアクセスできるリンクがあると便利ですね🙄
また、画面左上のが必ずwatsonx.aiになっているか確認してください。(このあたりUIが結構わかりにくいかな)
画面をスクロールさせて【プロジェクトの作成+】ボタンをクリックします。

【名前】にプロジェクト名を入力して、【作成】ボタンをクリックします。

プロジェクトが作成されると以下のような画面が表示されます。

その画面で【管理】タブを選択し、プロジェクトIDをコピーしておきます。

さらに、画面左側の【サービスおよび統合】を選択し、【サービスの関連付け+】をクリックします。

作成済のWatson Machine Learningのチェックボックスにチェックを入れて【アソシエイト】ボタンをクリックします。

処理後、以下のように表示が行われていればOK設定完了です。

これでIBM watsonx.aiの新規プロジェクト作成が完了しました。これで設定関連はほぼ終わりです。お疲れ様でした(終わってませんが)
1)言語モデルを使ったチャット機能を試す
ようやくwatsonx.aiが使用できるようになりました。以下を参考に試してみましょう。
watsonx.aiのプロジェクト画面から

先ほど作成したプロジェクトをクリックします。

【概要】タブをクリックし、【ファウンデーションァウンデーション・モデルを使用したチャットとプロンプトの作成】をクリックします。

初めてだと、プロンプト・ラボのツアーのダイアログが表示されますので、すべての項目にチェックを入れて【スキップ】ボタンをクリックをしてください。

続いて以下の表示も【完了】ボタンをクリックします。

チャット画面が開いたら、

質問の候補を選んでみるとチャットが始まります。今回はこちらを選択。

英語の回答がありました。

日本語で教えてくれるようにお願いするとちゃんと日本語で答えてくれます。


韓国語でも教えてくれます。

今回のチャットはLLMとして、llama-3-1-70b-instructを使用して応答を行ってくれています。
このチャットはクリアしたり、履歴から復帰させたり、保存することができます。 そのあたりは資料をみていただけばできると思います。
2)文書と言語モデルを利用したチャット
つづいてはチャットの参照情報として事前に資料(PDFファイル)を入力したパターンになります。RAGみたいな感じになるのでしょうか。
今回は以下のサイトからPDFファイルをダウンロードして使用します。
IBM RedbooksのサイトからTransitioning to Quantum-Safe Cryptography on IBM ZのPDFをダウンロードし、PDFをローカル・コンピューター上に保存します。
IBM Redbooksへのリンク
↓ PDFファイルの直リンク
https://www.redbooks.ibm.com/redbooks/pdfs/sg248525.pdf

改めてプロジェクトの【概要】タブから【ファウンデーション・モデルを使用したチャットとプロンプトの作成】をクリックして、

チャット画面が表示されます。チャットのテキストボックスの左側にある【文書のアップロード】ボタンをクリックして、

ドキュメントの追加を行います。ファイルの追加のエリアに今回使用するPDFファイルをドロップします。

ダイアログ右側の【拡張設定】のプルダウンを開き、

【埋め込みモデル】がall-MiniLM-L6-v2であるか確認し、【作成】ボタンをクリック。

チャット画面に戻り、PDFファイルとのチャットの表示に切り替わります。

ここで、LLMモデルを切り替えます。下の図の箇所をクリックしプルダウンから【すべての基盤モデルを表示】するをクリックし、

基盤モデルの選択ダイアログから

mixtral-8x7b-instruct-v01を選択します。

【モデルの選択】ボタンをクリックします。

あとはチャットでこのPDFに基づいた質問の応答を行ってくれます。PDFの情報を参照するのでハルシネーションに関してもあまり気にしなくて良さそうです。GoogleのNotebookLMに似ている機能ですね。



3)プロンプト・ラボの利用とPythonによるプロンプトの実行
続いてはようやくPythonからの処理を行います。プロンプト・ラボではcurl、Python、Node.jsと行った言語の処理の雛形を作成してくれるのでそれを活用することができます。といっても、ほぼプログラミングをしなくてもアクセス・トークンを埋め込むだけで動作してしまいます。
今回もプロジェクトの【概要】タブから【ファウンデーション・モデルを使用したチャットとプロンプトの作成】をクリックして、
【チャット】タブから【構造化】タブに移動します。

そして、画面左上にあるボタン(下図参照)をクリックして、

【サンプル・プロンプト】を開きます。

【サンプル・プロンプト】の一覧の【質問への回答】グループの【すべて表示】ボタンをクリックして、

【日本語での質問】を選択します。

するとプロンプトの画面がサンプルに合わせて以下のように変更されます。

ここで【生成】ボタンをクリックすると、プロンプトの回答が画面に表示されます。今回はこのプロンプトをPythonのコードを使用して実行していきます。

では、一旦ここで今生成された結果をクリアしておきます。生成されたコードにこの結果が含まれてしまうので、必ずクリアしておいてください。(実行に影響のある可能性があります)生成ボタンの隣の【出力のクリア】ボタンをクリックしてください。生成結果のみがクリアされます。

では、生成されたコードを確認してみたいと思います。画面の右上の【(コードの表示)】ボタンをクリックします。
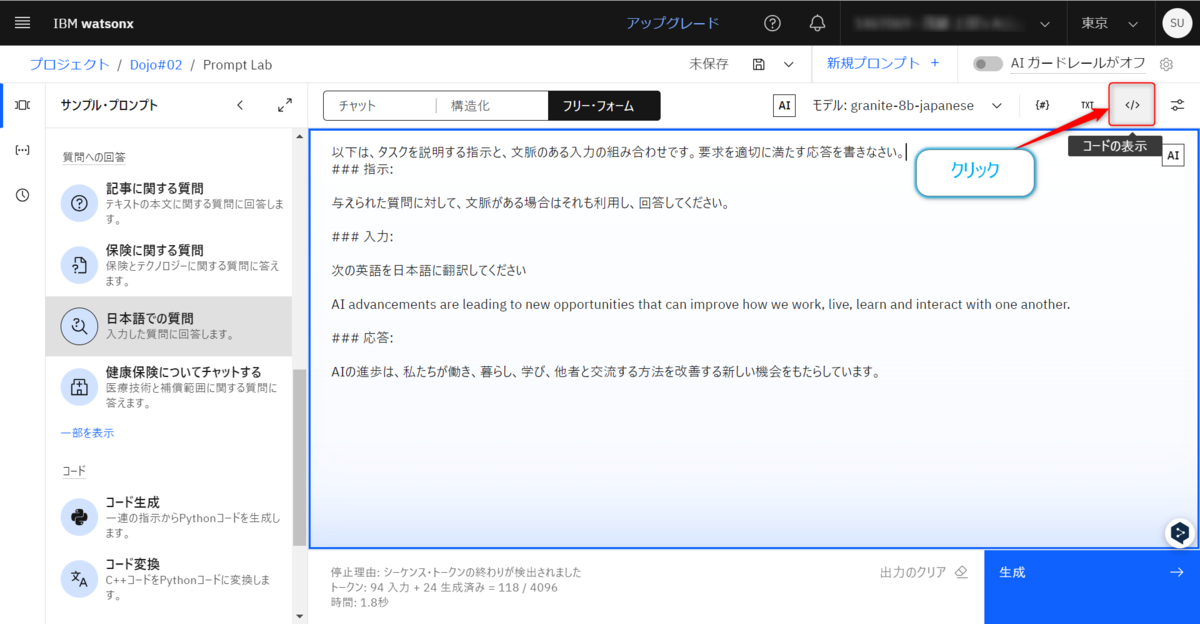
そして、【Python】のタブをクリックします。このコードをコピーして使用していきます。

以下は生成されたPythonのコードとなります(ただし、そのままでは動作しません)。
(重要)このPythonコードは、"YOUR_ACCESS_TOKEN"という部分にIBM Cloudのアクセス・トークンを入力すれば、実行できます。アクセス・トークンはIBM Cloud のAPIキーから生成できますが、APIキーそのものではないことにご注意ください。また、アクセス・トークンは生成後3,600秒で無効化されます。アクセス・トークンの生成方法とアクセス・トークンをPythonから生成する方法は後述。
(重要) このままでは実行時結果が出力がされないため、最後にprint(data)を追加してください。
pl01.py
import requests url = "https://jp-tok.ml.cloud.ibm.com/ml/v1/text/generation?version=2023-05-29" body = { "input": """以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。 ### 指示: 与えられた質問に対して、文脈がある場合はそれも利用し、回答してください。 ### 入力: 次の英語を日本語に翻訳してください AI advancements are leading to new opportunities that can improve how we work, live, learn and interact with one another. ### 応答: """, "parameters": { "decoding_method": "greedy", "max_new_tokens": 200, "min_new_tokens": 1, "stop_sequences": ["</s>"], "repetition_penalty": 1 }, "model_id": "ibm/granite-8b-japanese", "project_id": "50e1164d-06f1-4670-8482-4e50a46d6411" } headers = { "Accept": "application/json", "Content-Type": "application/json", "Authorization": "Bearer YOUR_ACCESS_TOKEN" } response = requests.post( url, headers=headers, json=body ) if response.status_code != 200: raise Exception("Non-200 response: " + str(response.text)) data = response.json() print(data) #これがないと結果が表示されません。
手動でアクセス・トークンを生成する方法
先ほども触れましたが、先程のPythonのコードはそのままでは動作しません。
(再掲)このPythonコードは、"YOUR_ACCESS_TOKEN"という部分にIBM Cloudのアクセス・トークンを入力すれば、実行できます。アクセス・トークンはIBM CloudのAPIキーから生成できますが、APIキーそのものではないことにご注意ください。また、アクセス・トークンは生成後3,600秒で無効化されます。
まずはアクセス・トークンを手動で生成して、コードに埋め込んで見たいと思います。
ブラウザで次のリンクへアクセスしてIBMCloudのIAMのページ行きます。
https://cloud.ibm.com/iam/overview
IAMページの右ペインにある、【APIキー】をクリックして

【APIキー】に【名前】をつけて【作成】ボタンをクリックします。名前はわかりやすいものにしておくと良いでしょう。

APIキーが生成されると以下のような表示が行われるので【ダウンロード】ボタンをクリックして保存をしておきましょう。

ダウンロードしたAPIキーのファイル
{ "name": "wxdojo", "description": "", "createdAt": "2024-09-14T17:51+0000", "apikey": "<ここに表示されている内容がAPIキーとなります>" }
ファイルに格納されたapikeyを使用して次の作業に移ります。curlコマンドで以下のように実行することで、アクセス・トークンを取得出来ます。コマンドの最後にapikeyをいれて実行してください。
$ curl -X POST 'https://iam.cloud.ibm.com/identity/token' -H 'Content-Type: application/x-www-form-urlencoded' -d 'grant_type=urn:ibm:params:oauth:grant-type:apikey&apikey=<ここに上記のAPIキーの値をコピーします>'
実行すると以下のように表示されます。アクセス・トークンはかなり長い文字列になります。
実行結果

{ "access_token":"この部分がアクセス・トークンで、とても長い文字列が表示されます", "refresh_token":"not_supported","ims_user_id":<ユーザーID>, "token_type":"Bearer", "expires_in":3600, "expiration":1726342370, "scope":"ibm openid" }
生成されたaccess_tokenの値を先程のPythonのソースコードの"YOUR_ACCESS_TOKEN"という部分と入れ替えて実行します。
# WSL(Ubuntu)上で実行 $ cd ~/wxai $ source venv/bin/activate # 初回のみrequestsライブラリをインストール (venv) $ pip install requests (venv) $ code pl01.py
チャットの結果

Pythonのコードからプロンプトを送信して、LLMに回答してもらうことが出来ました。
Pythonのコード上でアクセス・トークンを取得して実行する方法
先ほどはアクセス・トークンをcurlコマンドを使用して取得していましたが、これではかなり手間です。また、このアクセス・トークンも時間制限があり、長時間連続して使用するには問題があります。
そこで、先ほどのPythonのコードを改良して、実行時にアクセス・トークンを取得して実行するようにします。
変更時は以下の部分は必ず自身で取得したAPIキーを格納してください。(注意)アクセス・トークンではありません
ダウンロードしたJSONファイル内にあるapi_keyを使用します
{ "name": "wxdojo", "description": "", "createdAt": "2024-09-14T17:51+0000", "apikey": "<ここに表示されている内容がAPIキーとなります>" #←これを使用します }
Pythonのソースコードの冒頭部分とアクセス・トークンの差しかえ部分を修正しています。
pl01.py修正版
import requests # 追加・修正部分開始 import json from ibm_cloud_sdk_core import IAMTokenManager api_key = "<取得したAPIキーを入れてください>" def get_auth_token(): # Access token is required for REST invocation of the LLM access_token = IAMTokenManager(apikey=api_key,url="https://iam.cloud.ibm.com/identity/token").get_token() return access_token # 追加・修正部分終了 url = "https://jp-tok.ml.cloud.ibm.com/ml/v1/text/generation?version=2023-05-29" body = { "input": """以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。 ### 指示: 与えられた質問に対して、文脈がある場合はそれも利用し、回答してください。 ### 入力: 次の英語を日本語に翻訳してください AI advancements are leading to new opportunities that can improve how we work, live, learn and interact with one another. ### 応答: """, "parameters": { "decoding_method": "greedy", "max_new_tokens": 200, "min_new_tokens": 1, "stop_sequences": ["</s>"], "repetition_penalty": 1 }, "model_id": "ibm/granite-8b-japanese", "project_id": "50e1164d-06f1-4670-8482-4e50a46d6411" } # 追加・修正部分開始 headers = { "Accept": "application/json", "Content-Type": "application/json", "Authorization": "Bearer "+get_auth_token() } # 追加・修正部分終了 response = requests.post( url, headers=headers, json=body ) if response.status_code != 200: raise Exception("Non-200 response: " + str(response.text)) data = response.json() print(data) #これがないと結果が表示されません。
ソースコード変更後に以下のように実行します。
アクセス・トークンとPythonのソースコードを使用して以下のように実行します。
APIキーからアクセス・トークンを取得するのにibm_cloud_sdk_coreライブラリを使用しているのでpipコマンドでインストールしている点に注意してください。
$ cd ~/wxai $ source venv/bin/activate # requestsライブラリをインストール (venv) $ pip install requests # ibm_cloud_sdk_coreライブラリをインストール (venv) $ pip install ibm_cloud_sdk_core (venv) $ python pl01.py
実行結果

おわりに
今回のハンズオンを通じて、watsonx.aiを活用したアプリケーション開発の基礎を学ぶことができました。チャット機能の試用や、Pythonを用いたプロンプトの実行など、知らなかったスキルも身につけることができたような気がします。次回のプロンプト・エンジニアリングの内容も非常に楽しみです。次回はもう少し余裕を持ってやれるといいですね🙂
