「最小二乗法」とは、データ点をうまく表現するような直線を求めるための方法です。
統計学における一手法として計算的な側面が紹介されることが多いですが、その背景には実は幾何学的な面白い解釈があるという話を紹介したいと思います。
世の中には相関があるデータが山ほどあります。
ここで一つ、なにやら相関のありそうな変数 について、
点データをとってみてグラフに表してみたときに、こんな関係があったとします。

このようなデータに対しては、データ点に近しいところを通る直線 を「えいっ」と引きたくなりますよね。
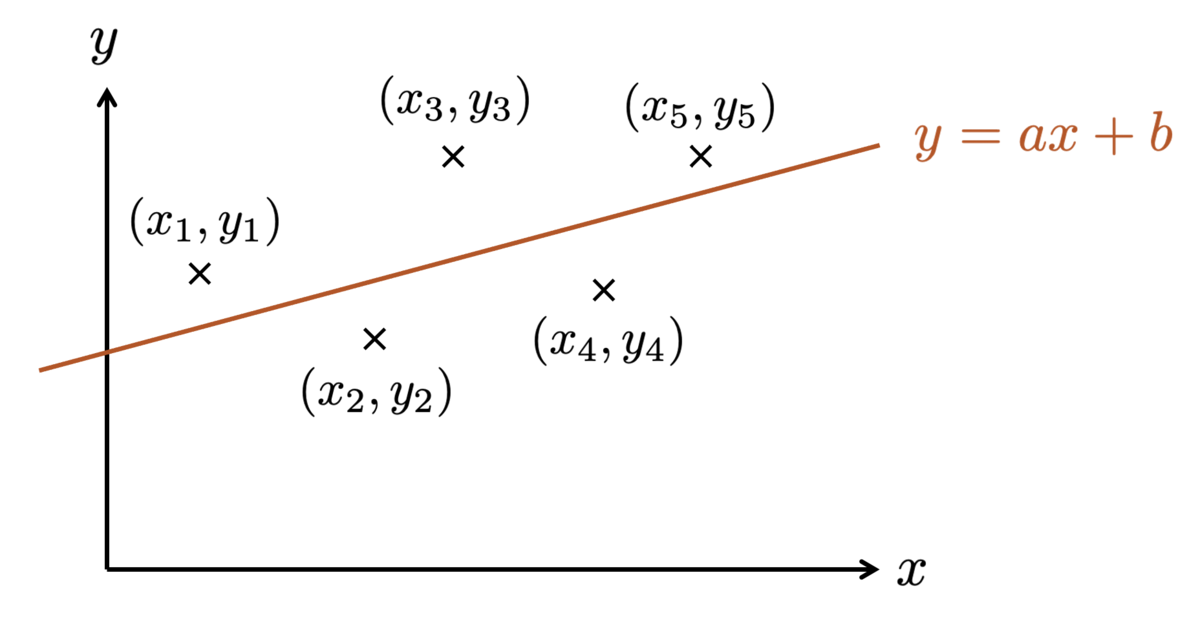
ところで、この直線 の係数
としては、どのようなものを選ぶのが 妥当 なのでしょうか?
ちなみに、エクセルさんはとても賢くて、散布図のデータ点を右クリックして、「近似曲線を追加」を選ぶと一発で最適な直線を引いてくれます。

今回の話は、このエクセルさんの背景にある数学のお話しです。
最小二乗法とは
妥当な の決定方法として、「誤差の二乗の総和を最小化」するというのが一つの有望な考え方です。
すなわち、直線とデータ点 の差として
という値(偏差)を考えます。図で表すと、緑色の波線の長さを正負の符号込みで考えていることになります:

この たちの二乗の総和(の1/2)
を最小化するような を妥当な係数としましょうという方針です。
二乗の総和を最小化するので、最小二乗法 といいます。
なんで二乗をとるのかということについて簡単に触れておきます。単に を足した
を計算すると、偏差の
が相殺されてほとんど消えてしまうからです。
では、絶対値でもいいじゃんと思うわけですが、二乗にしておくことで、後に微分するときに計算が簡単になるのです。
なぜ をするのかということについても、後で微分するときの事情です。
さて、式 の
を最小化するような
を求めよという問題を考えましょう。
答えは簡単で、 を
でそれぞれ偏微分して、
となるような
の組を求めればよいです。
まず、 を
で偏微分してみます。
次に、 を
で偏微分します。
よって、 とすると
なる連立方程式が得られます。
一見複雑に見えますが、係数がややこしいだけで、ただの を変数とする連立一次方程式です。
行列で表すと、次のようになります:
この連立方程式を 正規方程式 といいます。何で「正規」なのかは後で分かります。
あとは連立方程式を解くだけなので、ここまでで最小二乗法は完了ということになりますが、係数行列の部分はいったい何の行列なのかということが疑問に湧くと思います。この辺をもう少し深掘りしてみましょう。
行列を使って解く
正規方程式の謎を解くには、最小二乗法をベクトルと行列を用いて表現し直すことが鍵です。
以下の4つの行列を用意します:
すると、最初の偏差の定義 は、まとめて
と表せます。 の部分が少しトリッキーですが、行列の積をよくよく考えると分かります。
これによって、最小二乗法はベクトルのノルムを用いて
を最小化する を求める問題だと言い換えられます。
これを で偏微分すればよいわけですが、まとめて
という演算子を考えます(これをナブラ演算子といいます)。
ナブラ演算子を に適用して
を解けば最適な係数 が得られるという寸法です。
ここでベクトルのノルムは内積によって次のように変形できることに注意します:
これを用いて以下のように式変形します。
最後の式変形は、 はスカラーであり、スカラーは転置操作に対して不変であることから分かります。
この最後の式に対して、ナブラによる微分を計算するには、次のような公式が活用できます:
(
は定数)
は対称行列(
)であることから
が得られます。
ここで から次の式が得られます:
実は、この式 こそが正規方程式です。
実際、次のように計算できることから、式 が復元されます。
正規方程式はただの2元連立一次方程式なので、普通に解いたらよいのですが、 が正則行列であれば(逆行列を持てば)
のように直接的に解を表示することができます。
幾何的な解釈
正規方程式
の意味は一体何なのでしょうか。ここからが今回の本題です。
そもそもこの方程式の解は、二乗誤差を最小化する係数ベクトル なので、これを
と置くことにしましょう。
右辺を移項させると
となります。左辺を で括ると
となります。実はこの等式は幾何的に解釈できます。
は偏差を表すベクトルなのでした。
ここで はデータ点の
座標、
は対応する直線の点の
座標がなす
次元ベクトルでした。

の図形的な解釈のために、行列を展開して考えます:
ここで、 は、
の縦ベクトルです。
上の式から、 の全体は、(
次元空間の中で)縦ベクトル
が張る平面だということができます。ベクトル
はこの平面の基底ベクトルです。

言い換えると、この平面は(正解データの 座標を固定して)パラメータ
を動かしたときに「直線モデルの
座標の組が実現できる領域」を表している平面だということになります。
モデルが実現できる平面なので、「モデル平面」と呼ぶことにしましょう。
このように解釈すると、式 の意味が見えてきます。
とおくと、式
は
と置き換えられます。これを成分ごとに分けると
となります。
これは基底ベクトル と、偏差ベクトル
の内積が、どちらも
だということです。
つまり、これらのベクトルは直交しているということですね。
したがって、偏差ベクトル とモデル平面は直交することになります。
図で表すとこのようになります。

は近似したい正解データを表すベクトルであり、モデル平面は(正解データの
座標を固定して)パラメータ
を動かしたときに「直線の
座標の組が実現できる領域」を表している平面だということになります。
平面上の点で、正解データ にもっとも「近い」点は、
からモデル平面に下ろした垂線の足だと思うことができます。これこそが最小二乗法の解
による
だというわけです。
最小二乗法とは、正解データのモデル平面への正射影だった というわけです。こんなふうに幾何的な解釈ができるというのは面白いですね!
ところで、最小二乗法の解 を求めるには、正規方程式
これはまさに「直交条件」を表していたということが分かったわけです。
そして、正規方程式は英語では "normal equation" ですが、"normal" は「法線」も意味しますね。要するに、偏差ベクトルが平面に対する法線ベクトルである条件を表す式だったというわけです。
このように考えると、正規方程式は「法線方程式」あるいは「直交方程式」と呼んだ方が適切かもしれないなと思いました。
そして情報幾何へ…
実は今回の話を展開しようと思ったのは、情報幾何 という分野に興味があるからなんです。
情報幾何とは、統計的分布をまとめた集合に幾何的な構造を入れようという学問です。今回の話と接点があるので、それを簡単に説明してみたいと思います。
今回の最小二乗法では、パラメータ 全体を動かしたときの
を「モデル平面」と称していました。
情報幾何においては、モデル平面の代わりに、モデルが作る「確率分布全体」の空間を考えるのです。

単なるパラメータのなす平面ではなく、確率分布同士の「距離」を適切に考える必要が出てきます。
すると、必然的に確率分布全体の空間も曲がった空間になります。これを表現する数学的なバックグラウンドは「リーマン幾何学」です。
一方で、データ点が定める自然な確率分布があります。
最小二乗法のような問題は、一般化すれば「データ点のなす確率分布から、モデルのなす空間に対する射影」だと考えられます。最適解は曲がった空間に沿って進む「測地線」によって得られます。
このように確率分布に自然に入る幾何的な構造を考える学問が情報幾何なのだそうです。
とても面白そうですね!
tsujimotterもいつか解説できる日がくればと思っています。
