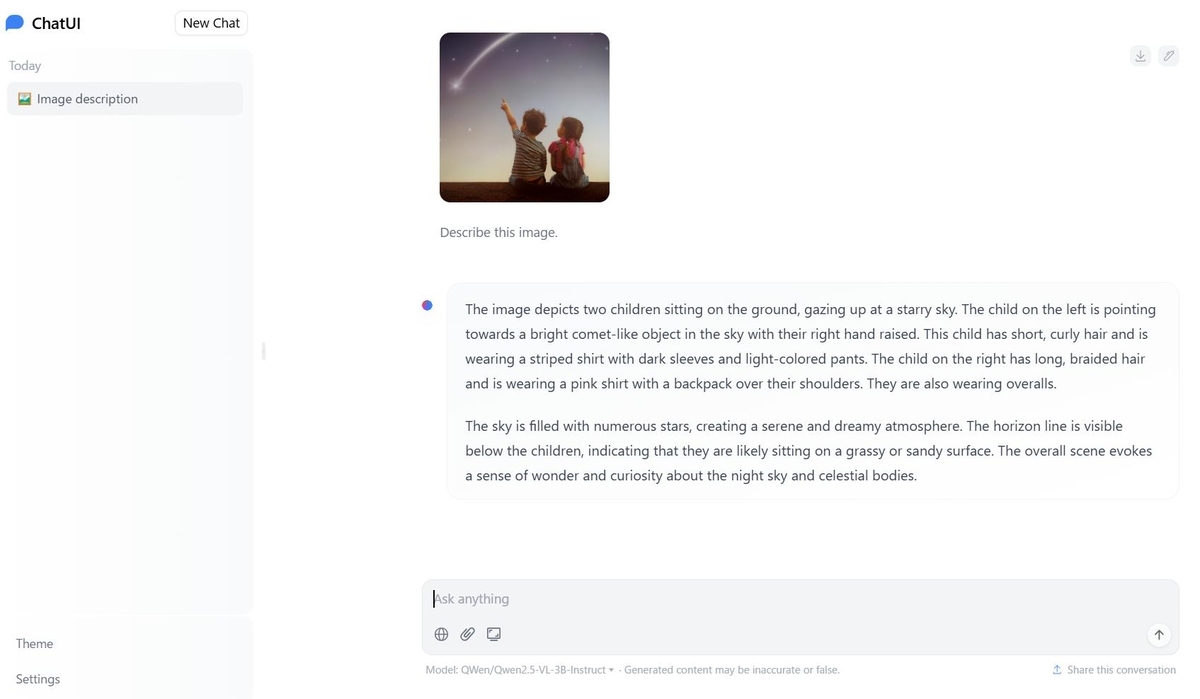
Vision&LanguageモデルをChatUIで使うのは初めてでしたが画像のアップロードなどもうまくいきました。
はじめに
以前Transformersを使って「Qwen2.5-VL-3B-Instruct」を使いました。touch-sp.hatenablog.com
今回は「vLLM」と「ChatUI」の組み合わせで使ってみます。
方法
vLLM側の操作
WSL2を使っています。vllm serve Qwen/Qwen2.5-VL-3B-Instruct --max_model_len 4096
ChatUI側の操作
こちらを参照して下さい。キモは「.evn.local」の記述です。こちらを参考にこのようにしました。
MODELS=`[ { "name": "QWen/Qwen2.5-VL-3B-Instruct", "id": "Qwen/Qwen2.5-VL-3B-Instruct", "multimodal": true, "parameters": { "stop": ["<|im_end|>", "<|endoftext|>"], "temperature": 0.7, "truncate": 4096, "max_new_tokens": 1024 }, "endpoints": [ { "type": "openai", "baseURL": "http://localhost:8000/v1", "multimodal": { "image": { "maxSizeInMB": 10, "maxWidth": 1280, "maxHeight": 1280, "supportedMimeTypes": ["image/png", "image/jpeg", "image/webp"], "preferredMimeType": "image/webp" }, } } ] }]` MONGODB_URL=mongodb://localhost:27017
