
広告・マーケティング分析におけるMMM (Media/Marketing Mix Models)と言えば、このブログでも過去に何度か手を替え品を替え取り上げてきたテーマです。これまでは個々の技術的側面に着目した断片的な内容の記事を多く上げてきましたが、近年明らかにその注目度が高まってきておりますので、満を持して包括的に議論する記事を書いてみようかと思います。
ただ、記事中でも指摘しているようにMMMとはどちらかというとscienceというよりpoliticsに近い性質を持つ分析手法です。よってこの記事の内容もまたpoliticalな要素を含むものであり、是非読者の皆様からの忌憚のない指摘や批判をいただければと思います。
- MMMは本質的には「ただの回帰分析」
- 回帰分析における注意事項は全てMMMにも当てはまる
- MMMは時系列モデルでもあり、ドメイン知識をも踏まえた複雑さがネックになる
- 因果推論には注意を払うべき、だが拘り過ぎてもいけない
- MMMはscienceではなくpoliticsに近いと割り切るべし
- 適切に条件統制されたマーケティング実験を必ずMMMと併用するべし
MMMは本質的には「ただの回帰分析」

上の式はJin et al. (2017)から取ってきたベイジアンMMMのモデル表現そのものですが、書き方の問題であって本質的には見慣れたの形式に帰着させられます。即ち、これはただの回帰分析と同じなんですね。
詳細は後述しますが、実際には回帰分析の説明変数に対してメディア変数であればドメイン知識ベースの非線形要因が乗り、加えてメディア変数の回帰係数には非負制約が課せられ*1、さらには季節調整やトレンドといった成分も乗ってくるため、単なる線形回帰モデル(重回帰分析)では表現できません。しかしながら、ベースとなっているのはシンプルな回帰分析であるということを最初に強調しておきます。
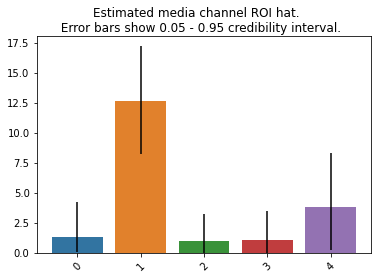
過去にはMMMは様々な使われ方をしていたようですが、現在ではほぼ100%「メディアのROI / ROAS(費用対効果)を推定する」「その数値をもとに予算総額の最適配分を(最適化計画を解くことで)決定する」目的で使われているようです。そのため、MMMは「説明」のための回帰分析として、回帰係数の具体的な値を求めるために行われるものと見て良いかと思います。
回帰分析における注意事項は全てMMMにも当てはまる
MMMが回帰分析である以上、当然の帰結ですが回帰分析における注意事項が全て当てはまります。その一般的な内容は、例えば佐和本あたりを読めば一通り網羅できるかと思いますし、ちょっと前の記事でも実務面に着目してまとめてありますが、MMMという文脈に即して簡単に再掲しておきます。
「説明」「意思決定」に適したモデルを選ぶ
機械学習系の「予測」を目的としたモデルでは個々の説明変数の意味や操作可能性は気にしなくても問題ないことが多いですが、「説明」を目的とした回帰分析ではケースバイケースであり、特に回帰係数などの値をダイレクトに求めて意思決定に用いることが期待されるMMMでは「全ての説明変数の定義や意味が明確」で尚且つ「可能な限り多くの説明変数が操作(介入)可能」であることが求められる、と言って良いかと思います。
概して、MMMのような大掛かりなマーケティング分析ではとかく「少しでも多くの説明要因をモデルに盛り込みたい」ということでありったけのデータをあれもこれもと説明変数に突っ込んでしまいがちな現場が多いようです。しかし、その結果として得られるMMMが説明・解釈の困難なゲテモノになってしまっては本末転倒ですし、介入不可能な変数ばかりが重要だということになってしまってはマーケティング上の意思決定のしようがなく、元も子もありません。
よって、MMMを実施する際には「全ての定義と意味を把握できる範囲に説明変数を絞る」「可能な限り介入可能な説明変数だけに絞る」ことを個人的には推奨しています。後述するように、そう対処すること自体が既に恣意性を含んでいることは否めませんが、何にも使えないモデルが出来上がるよりはマシでしょう。
なお余談ながら、MMMでは「入れ子モデル」などの複雑なモデルが用いられることがあるようですが、汎化性能の評価が難しかったり、そもそも後述するような系列相関を伴う時系列データにおける適用可能性が曖昧だったり、その分析結果に基づいて考えられた介入施策が過剰に複雑になりがちなので、個人的にはお薦めしていないです。
過学習を避け、汎化性能を意識する
これは以前にもまとめたことがある話で、一般には「過学習は『予測』に害をなす」と思われがちですが、実は「説明」にとっても有害だということを指摘しておきたいと思います。理由は極めて単純で「過学習しているモデルでは回帰係数にもバイアスが乗ってしまい『説明』を誤らせる」からです。以下に簡単な例を示しておきます。

説明変数x1-3が共通する2つのモデルを用意します。1つはオリジナルの説明変数x1-3のみで目的変数に適合させたモデル且つ実際に目的変数の生成に用いた真のモデルで、もう1つは目的変数とは無関係に乱数生成した説明変数x4-9を追加したモデルです。試しに時系列プロットを描いてみると、前者のモデルは学習データにも交差検証データにもほどほどにフィットしている一方で、後者のモデルは学習データにぴったりフィットしながらも交差検証データからは大きく逸脱しています。

で、回帰係数を見てみるとこうなります。前者のモデルは(真のモデルなので)事前に設定した真の値に近い回帰係数をx1-3とも示していますが、後者のモデルでは過学習した結果としてx4-9がデタラメなのに加えてx1-3までもがおかしな結果になっています。
ということで、MMMがいかな「説明」にしか用いられないといえども、一般的な統計的学習モデル同様に過学習を可能な限り避け、交差検証を用いて汎化性能を確保することを意識するべきです。
多重共線性には適切に対処する
これまた前回の記事で論じたばかりなので繰り返しになってしまいますが、「説明」を目的とする回帰分析で尚且つ「個々の回帰係数に興味がある」のが典型的なMMMなので、多重共線性には適切に対処しなければなりません。特にROI/ROASを比較したいメディア変数と多重共線関係にある変数が混じっている場合は尚更です。
特に、MMMで扱う広告・マーケティングデータは「キャンペーンごとに同一カテゴリの全広告を同時出稿&同時引き上げ」みたいな究極の多重共線関係を抱えていることが少なくなく*2、多重共線性のチェックは欠かせません。
対処法は前回の記事でも述べたように、「相関係数とVIFをベースとして多重共線関係にある変数を特定する」「その上でドメイン知識とMMMの分析目的に即して説明変数を削除orマージする」のが鉄則です。MMMだとspike-and-slab事前分布を用いてLasso的に変数削減する方法もあり得ますが、Lasso同様にドメイン知識や変数の生成過程を無視してアルゴリズミックに削ってしまうので推奨しません。
ちなみに、MMMという分析が一般に広告・マーケティング戦略立案に使われるものであるということを鑑みれば、普段から多重共線性が生じないように全てのメディアや施策を互いの相関が低くなるよう「適度にバラけさせながら打つ」というのがあるべき姿であろうと考えています。
MMMは時系列モデルでもあり、ドメイン知識をも踏まえた複雑さがネックになる
基本的に、MMMに与えるデータは時系列です。よって、MMMは回帰分析であると同時に時系列モデルでもあります。そして、MMMで扱うデータは経済学・社会学的マーケティングデータであるがゆえに系列相関を伴います。このため、それらの特性に応じた工夫が必要になります。
遅延効果と飽和効果
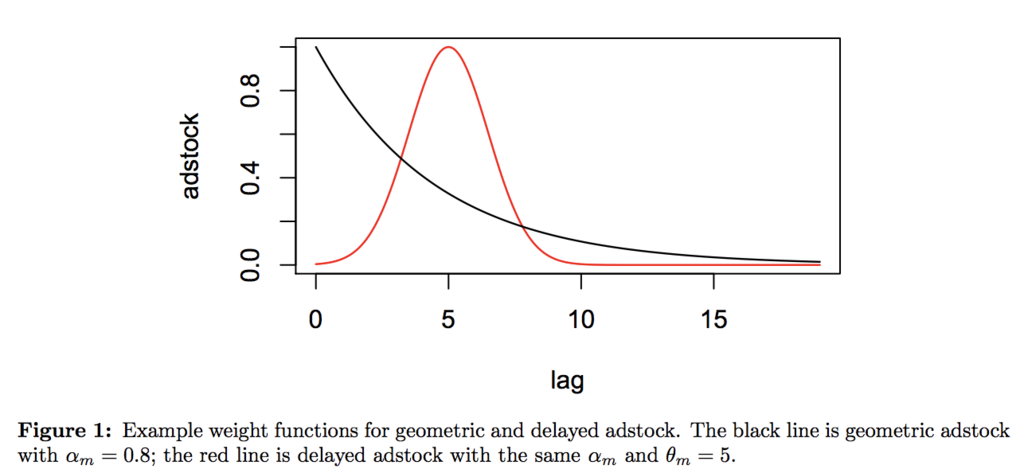

近年のMMMでは、Jin et al. (2017)で提唱された遅延効果(adstock)と飽和効果(response curve)を盛り込むことが、半ばデフォルトの考え方となっています。モデル式で書くと難解そうに見えますが、StanでもNumPyroでもコードで書けばそれほど難しくはない*3ので、OSSの実装ではほぼ全てで使われています。
トレンドや季節調整などの系列相関への対処
MMMで用いるデータは典型的な経済学的・社会学的時系列データなので、系列相関としての長期トレンド(うねり)が回帰で説明できる以外の要因として乗ってくる上に、例えばdaily(日次)データであれば曜日に由来する7日周期の季節調整が必要になります。長期トレンドの推定には様々な方式がありますが、かつては二階差分トレンドや指数トレンドが一般的でした。最近は一般化加法モデルというアプローチもあるようです*4。季節調整も色々な流儀があり、総和をゼロ(平均ゼロの正規分布)でサンプリングするというやり方が簡単ですが、フーリエ近似するケースもあったりします。
なお、これらの系列相関に由来する非線形要因のパラメータ推定が複雑になることから、近年のMMM実装の多くがベイズ構造時系列モデルを採用しているようです。実際、頻度論的なアプローチで山ほどグリッドサーチするよりは、MCMCで一括でパラメータをサンプリングした方が手っ取り早いかと思われます。
交差検証には技術的なチャレンジがある

以前このブログでも何回かコメントしたことがありますが、時系列モデルの交差検証はpast-and-future split即ち「trainデータの未来方向にtestデータを一括して用意する」ことが原則とされます。

理由はシンプルで、random splitするとトレンドや季節調整などの系列相関が前後のサンプルから入り込んでleakageになってしまい、正しくない交差検証結果を返す恐れがあるからです。実際、過去にそれが原因で大炎上した時系列モデル研究論文*5があり、ご記憶の方もいらっしゃるかと思います。
他方で、最近では「MMMのような時系列回帰分析ではpast-and-future splitでholdoutを取るべきではない」という意見もあるようです。理由は幾つかあるようで、主要なものとしては「そもそもトレンドや季節調整の影響の方が強いデータに対して説明変数に基づく『未来予測』型の交差検証をするのは適さない」「MMMだと説明変数が時系列的にスパースであることが多くごく少数の説明変数の値をもって『未来予測』させる交差検証は意義が薄い」といったものがあります。このため、若干奇異に聞こえますが「random splitでtrain/testを分けた上でtrainデータで欠損値補完型*6のモデル学習を行い、素朴に欠損値としてのtestデータへの交差検証(補完性能の検証)を行う」というアプローチも出てきているようです。
しかし、僕も個人的に懇意にさせていただいているマクリン謙一郎さんも指摘されているように*7、「そもそも時系列モデル*8で尚且つ『真のモデルが分からない』のであれば『未来予測性能』で暫定的にモデル比較&選択を行うの妥当」という考え方もあります。勿論、MMMといえども説明変数がスパースではないケースもあり、そういう時はpast-and-future splitで交差検証する方が適切でしょう。
いずれにせよ、MMMが時系列モデルであり尚且つ回帰分析でもあるという特徴がゆえに、その交差検証の方式には技術的なチャレンジがあるという点は留意しておくべきだというのが、僕の意見です。
因果推論には注意を払うべき、だが拘り過ぎてもいけない
ここ最近のMMMにおける流行りの一つが「(Pearl流)因果推論」です。確かに、その気持ちは分かります。MMMが複雑な回帰分析である以上、可能な限り交絡因子を調整してバイアスは最小限に留めたい……というのは、ある意味当たり前の願望です。

これはズバリ「MMMにおけるバイアスを調整する」ことを主眼とした研究であるChen et al. (2018)から引用したDAGですが、「ドメイン知識に基づく経験上こんな感じのDAGが描ける」というのであれば、ある程度はPearl流の因果推論のコンセプトに基づいてバイアスの調整はできることでしょう。
しかしながら、『計量経済学』(日本評論社)の著者であられる末石先生もコメントされていた通りで*9、そもそも「正しい因果推論」というものが存在するのか?という論点に注意が必要だと僕個人は考えます。実際、上掲のDAGが「真のDAG」かというと個人的にはそんなことはないと思いますし、何なら遥かに複雑なDAGすら描けることでしょう。むしろ「真のDAG」なるものが、この複雑な現実社会のマーケティングにおいて描けるかというと、果てしなく疑問に思われます。例えばですが、「ある商品のTVCMの『〇〇で検索!』というメッセージを見て検索したら検索広告が出てきたがそこでクリックせずにインスタを開いたらそこに同じ商品の動画広告が出てきて……」という生活者ジャーニーを、適切に表現できるDAGなど存在しないはずです。
もっと言ってしまえば、MMMはその性質上内生性が否定できないことが少なくありません。例えば、ある商品の広告を打った場合に「期待していた以上に商品が売れたので気を良くしてさらに広告出稿を増やした」というような、絵に描いたような内生性が生じることは想像に難くないでしょう*10。これをMMMにおいてある程度以上厳密に調整する、あるいは回避する方法は、僕の知る範囲では未だ提案されていません。
よって、MMMにおける因果推論は「注意を払うべきだが拘り過ぎてもいけない」というのが妥当な態度かなと思います。少なくとも「今すぐデータが入手できる」変数で交絡の調整ができるのであればやるべきですし、一方で「データの入手が難しい上に交絡因子かどうかもはっきりしない」変数をわざわざ考慮する必要はない、のではないかなと。Boxの格言に従って「usefulなモデル」を得ることに徹するべきでしょう。
MMMはscienceではなくpoliticsに近いと割り切るべし
実は、この論点については既に英語圏で極めて優れたcritic reviewが書かれており、業界における後輩のid:kinuitくんが著者の許諾を得た上で日本語訳記事を出してくれています。興味がおありの方はぜひご一読ください。
……で、あえてこの記事の内容に触れないでおいてぶっちゃけた話を書くと、MMMは確かにscienceではなくむしろpoliticsと言った方が正しい代物です。往々にしてそれは「ステークホルダーが『欲しい』結果を出す」ことが求められる代物ですし、それこそステークホルダーが重要視したい要因の貢献度がより高く見えるようにMMMのモデル推定アルゴリズムに手が入れられることすらあります。それが全てだとまでは言いませんが、MMMに関する研究論文が査読誌に通るケースは少ないという現状には、恐らくその辺の事情も反映されているのでしょう。特定の事前分布パラメータを用いないと綺麗な結果が出ないMMMなる統計モデリングを、scienceと称するのは確かに難しいかもしれません。
その上でポジショントークと受け取られることを承知の上でコメントするならば、「そんなpoliticsに過ぎないMMMであっても客観的な信頼に値する結果を返す『こともある』」というのが、個人的な意見です。MMMがpoliticsであると分かっていても、それでも可能な限りscienceにこだわって再現性をある程度担保し得るモデリングを行い、その分析結果に基づいて合理的な意思決定が行われることを目指す、というのがあるべき姿であろうと考えています。
適切に条件統制されたマーケティング実験を必ずMMMと併用するべし
では、どうやってMMMの分析結果の再現性を担保すれば良いのでしょうか? 事前・事後のどちらで行うかはケースバイケースですが、「適切に条件統制されたマーケティング実験をMMMとセットで行う」のが無難なソリューションでしょう。これは僕も以前ブログ記事にまとめたことがありますし、前出のcritic reviewでも述べられている論点です。
なお、個人的には「事後のマーケティング実験」を実施して、MMMで得られた分析結果をreconfirmすることをお薦めしています。大事なことは「MMMは事後マーケティング実験のための仮説出し」に使うことであり、マーケティング実験でダメ押しするところまでを一体化された分析プロセスと捉えることだと考えています。
Declaring Conflicts of Interest
