



はじめに
こんにちは、データサイエンス部コーディネートサイエンスブロックの大川です。私たちは、WEARにおける「似合う」をユーザーに届けるため、LLMやマルチモーダルAIを活用してコーディネートの特徴抽出や似合うに関する独自の判定処理のR&Dを行っています。
LLMが台頭して以降、LLMに構造化出力を要求するタスクは増えています。数百件のテストでは問題なく動いていたシステムが、本番運用で10万件・100万件規模の推論を回すと思わぬエラーに直面することがあります。
本記事では、ファッション画像から柄の特徴を抽出するタスクを本番運用する過程で直面した課題と、その解決策を共有します。具体的には、エラー内容をプロンプトにフィードバックしてリトライする手法により、87%のエラー削減を達成しました。この手法はLLMの構造化出力タスク全般に応用可能です。
目次
サマリー
- LLMの構造化出力で発生する「不正な値の出力」と「トークン繰り返し」問題に対し、バリデーション+エラーフィードバックプロンプトで87%のエラー削減を達成(68件→9件)
- エラー内容だけでなく、リトライ回数とtemperatureもフィードバックに含めると効果が大きい(21件→9件)
- F1スコアへの影響は約0.02の低下にとどまり、安心して導入できる
前提条件
前提条件を揃えるため、タスク内容とLLMの仕様を共有します。
| 項目 | 内容 |
|---|---|
| タスク | ファッション画像から複数の柄の特徴を抽出するタスク(マルチラベル分類) |
| 推論規模 | 約10万件の全身コーディネート画像 |
| 使用モデル | gemini-2.5-flash-lite |
| 出力形式 | JSON(許可された値のリストから選択) |
| リトライ | 最大3回 |
構造化出力では、柄の種類(pattern_type)などの特徴に対して、事前定義された値のみを出力するようLLMに指示しています。例えば、ニュアンス柄(nuance_pattern)やグレンチェック柄(glen_check_pattern)などが定義済みの値です。この制約の実装にはGemini APIのresponse_schemaパラメータを利用しています1。
ただし、response_schemaはJSONの構文的な正しさ(型やフィールド名)は保証しますが、値の意味的な正しさは保証しません。公式ドキュメントでも「最終的な出力は、使用する前に必ずアプリケーションコードで検証してください」と明記されています2。この仕様上の限界が、後述する「不正な出力」問題の背景にあります。
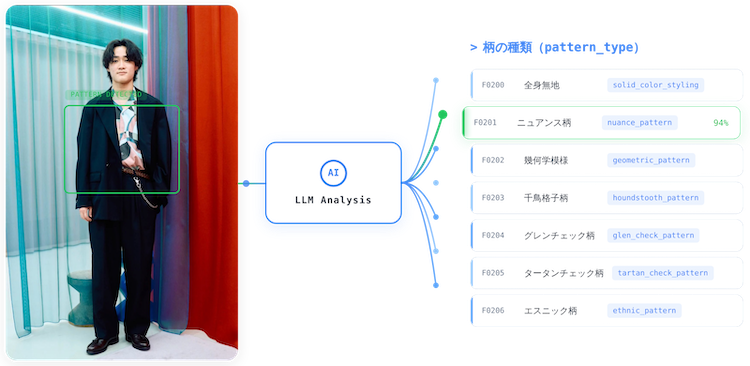
発生した問題
約10万件の画像を推論したところ、以下の2つの問題が発生しました。
問題1: 不正な出力(68件)
定義外の値が出力されるケースです。例えばpattern_typeに対して、logo、patchwork_pattern、graphic_patternのような、あらかじめ指定したリストに含まれない値が返ってきました。
| 不正な値 | 件数 |
|---|---|
| logo | 26 |
| patchwork_pattern | 17 |
| graphic_pattern | 14 |
| camouflage_pattern | 6 |
| その他 | 5 |
これらの不正な値は、いずれもファッション領域では実在する概念です。LLMが持つ一般知識から「もっともらしい値」を生成してしまったと考えられます。
問題2: トークンが繰り返される出力(9件)
同じトークンが無限に繰り返され、JSONパースに失敗するケースです。Gemini API公式ドキュメントでも「トークンの繰り返しに関する問題」として同様の事象が取り上げられています3。
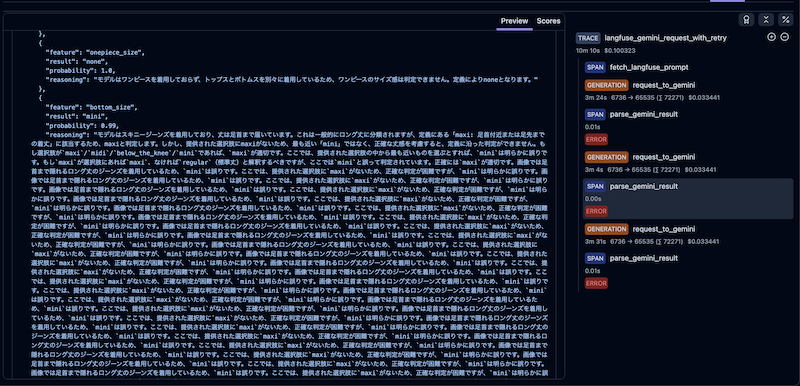
この問題が厄介なのは、JSONパースエラーでリトライしても同様の事象が繰り返される点です。その結果、以下の影響が生じます。
- 出力が得られない: 3回リトライしても正常な結果を取得できない
- レイテンシーの悪化: 1件あたり10分程度かかるケースも発生
- コストの増加: 無駄なトークンを大量に消費する
この問題をスケールで考えると深刻さが分かります。10万件中9件の発生率(0.009%)は一見小さく見えますが、本番の全件推論で400万件を処理する場合、約360件でこの問題が発生する計算です。1件あたり10分の遅延とすると、トークン繰り返し問題だけで約60時間(2.5日分)の遅延が発生します。
原因分析
原因1: 不正な出力
不正な出力の原因は、出力値のバリデーションとリトライの仕組みが不十分だったことです。前述のとおり、Geminiのresponse_schemaはJSONの構文を制約するものであり、enum値の完全な制約までは保証しません。従来の実装ではこれを検知してリトライする機能がなく、不正な出力がそのまま通過していました。
原因2: トークンが繰り返される出力
この問題の背景には、再現性とトークン繰り返しのトレードオフがあります。分類タスクではtemperature=0で出力を安定させたい一方、それがトークン繰り返し問題を引き起こします。実際、Gemini API公式のトラブルシューティングガイドでも、temperatureを低く設定すると「ループや性能劣化などの予期しない動作を引き起こす可能性がある」と警告されています4。
技術的には、temperature=0の貪欲デコーディングにより、特定の入力に対して同じ出力トークンが延々と選ばれ、適切にEOSトークンで終了できない状態に陥ります。この問題に対処するため、リトライ時にtemperatureを0.1ずつ増やす施策を導入していましたが、それだけでは完全には回避できませんでした。
解決策
2つのアプローチを組み合わせて改善を図りました。
解決策1: バリデーション&リトライの追加
不正な値が出力された際に、許可された値のリストと照合してバリデーションし、失敗時はリトライする機能を追加しました。
解決策2: プロンプトへのエラーフィードバック追加
単にリトライするのではなく、前回のエラー内容をプロンプトの末尾にフィードバックして再試行させることでLLMの注意を問題点に向けさせました。このとき、エラーの種類によってフィードバック内容を変えるように設計しました。
ValueErrorの場合
ValueErrorの場合、問題1(不正な出力)の発生が予想されます。どの値が不正で、どの値が許可されているかをエラーメッセージとしてそのままフィードバックするようにしました。
前回の推論で以下のようなエラーが発生しましたので注意してください。
** 前回のConfig・エラー情報 **
- 試行: {N} 回目
- temperature: {current_temp}
- 前回エラー: ValueError: invalid result for feature=pattern_type: 'logo' (allowed: ['ethnic_pattern', 'geometric_pattern', ...])
JSONDecodeErrorの場合
JSONDecodeErrorの場合、トークンが繰り返されている可能性が高いと判断し、通常のプロンプトの末尾に以下のフィードバックを追加しました。この問題は公式ドキュメントでも言及されており、「同じことを繰り返さないでください」という指示を追記することが推奨されています5。
前回の推論で以下のようなエラーが発生しましたので注意してください。
** 前回の Config・エラー情報 **
- 試行: {N} 回目
- temperature: {current_temp}
- 前回エラー: JSONDecodeError: ...
無限にトークンが繰り返される問題が発生している可能性があります。**同じことを繰り返さないでください。**
GoogleAPIError(APIエラー)の場合
GoogleAPIError(APIエラー)の場合、レート制限やネットワークエラーが主な原因となるため、プロンプトを改善しても解決しません。この場合はフィードバックを追加せず、指数バックオフによるリトライのみとしました。
結果
エラー削減効果
解決策の効果を検証するため、不正な出力を起こした68件を評価データとして用い、施策前後での改善度合いを比較しました。なお、トークンが繰り返される問題については、エラーの再現ができなかったため今回は評価データから除外しています。
3つの条件を用意して比較実験を行いました。
- 解決策1: バリデーションのみを追加
- 解決策2-1: バリデーションとエラーフィードバック(エラー内容のみ)
前回の推論で以下のようなエラーが発生しましたので注意してください。 - 前回エラー: ValueError: invalid result for feature=pattern_type: 'logo' (allowed: ['ethnic_pattern', 'geometric_pattern', ...])
- 解決策2-2: バリデーションとエラーフィードバック(エラー内容 + リトライ数 + temperature)
前回の推論で以下のようなエラーが発生しましたので注意してください。
** 前回のConfig・エラー情報 **
- 試行: {N} 回目
- temperature: {current_temp}
- 前回エラー: ValueError: invalid result for feature=pattern_type: 'logo' (allowed: ['ethnic_pattern', 'geometric_pattern', ...])
| 施策 | バリデーションの有無 | エラーFBの有無 | エラー件数 | 削減率 |
|---|---|---|---|---|
| ベースライン | ✗ | ✗ | 68件 | — |
| 解決策1 | ✓ | ✗ | 40件 | 41% |
| 解決策2-1 | ✓ | ✓ | 21件 | 69% |
| 解決策2-2 | ✓ | ✓ | 9件 | 87% |
実験結果として、87%のエラー削減(68件 → 9件)を達成しました。
重要な発見として、エラー内容だけでなく、リトライ数とtemperatureも付与したほうが効果的であることを確認しました(解決策2-1の21件→解決策2-2の9件)。これらの情報を付与することで、LLMが「何回目の試行で、どのような生成条件なのか」を把握でき、前回と異なる出力を生成しやすくなったと推察されます。
トークンが繰り返される問題についても、定量的な評価には至っていないものの、定性的には出現頻度の低下と出力の安定化を確認しています。
性能への影響
エラーフィードバックを追加することで性能への悪影響がないか検証しました。柄の評価データセットを用意し、エラーFBの有無で3回ずつ実行した平均値を比較しました。リトライ時にtemperatureを0.1ずつ増やす運用を想定し、temperature 0.0〜0.2の範囲で検証しています。
| モデル | temperature | エラーFBの有無 | F1スコア |
|---|---|---|---|
| gemini-2.5-flash-lite | 0.0 | ✗ | 0.8417 |
| gemini-2.5-flash-lite | 0.0 | ✓ | 0.8208 |
| gemini-2.5-flash-lite | 0.1 | ✗ | 0.8434 |
| gemini-2.5-flash-lite | 0.1 | ✓ | 0.8208 |
| gemini-2.5-flash-lite | 0.2 | ✗ | 0.8425 |
| gemini-2.5-flash-lite | 0.2 | ✓ | 0.8217 |
性能への大きな影響はないことを確認しました。数値上ではF1スコアに約0.02の低下が見られますが、エラーフィードバックが適用されるのはバリデーション失敗時のリトライのみです。正常に出力された大多数のケースではフィードバックが付与されないため、システム全体への影響は軽微です。
まとめ
本記事では、LLMの構造化出力で発生するエラーを87%削減した手法を紹介しました。
本記事の貢献は以下のとおりです。
- バリデーション+エラーフィードバックをプロンプトに含めることでエラー件数を87%削減できる
- エラー内容だけでなく、リトライ数とtemperatureも付与すると効果が高い
- フィードバックを追加してもF1スコアへの大きな悪影響はなく、安心して導入できる
- この手法はGeminiに限らず、LLMの構造化出力タスク全般に応用可能
LLMの構造化出力や、Gemini APIの出力の安定化(トークン繰り返し問題の回避)に悩むエンジニアの方々にとって、本手法が何らかのヒントになれば幸いです。
おわりに
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
