



はじめに
こんにちは、データ・AIシステム本部の冨田です。ファッションコーディネートアプリ「WEAR」において、ユーザーのコーディネート投稿データを分析し、「似合う」を届けるための機能開発を担当しています。
WEARには日々膨大な数のコーディネートが投稿されています。それらを活用して、経営戦略でもある「ワクワクできる『似合う』を届ける」ためには、画像やテキストからファッションに関する特徴を抽出する必要があります。本記事では、リサーチャーとの協業による評価サイクルを構築しながら、プロンプトエンジニアリングのみで特徴抽出の精度目標を達成した事例を紹介します。
背景・課題
独自定義「似合う4大要素」の抽出
現在私たちは、WEARのコーディネートデータから「似合う」を構成する4大要素を抽出するプロジェクトを進めています。本システムでは、まずLLMを用いてコーディネートの画像やテキストから言語化された特徴を抽出します。その後、説明可能なルールベースのロジックに入力して最終的な4大要素を判定するというハイブリッドな構成をとっています。この仕組みを正しく機能させるためには、まずは前段となるLLMが「オーバーサイズ」や「丈感」といったファッション特有の曖昧な特徴を正確に抽出する必要があります。

一般的なプロンプトの限界
ファッションの言語化は非常に曖昧です。例えば「オーバーサイズ」といっても、少しゆとりがある程度を指すのか、極端にシルエットが大きいものを指すのか、人によって解釈が異なります。単純に「この画像はオーバーサイズですか?」とLLMに尋ねるだけでは、サービスが求める基準(ZOZOとしての正解)とLLMの出力が乖離してしまい、実用レベルの精度が得られないという課題がありました。
アプローチ(技術選定)
手法の比較検討
LLMの回答精度を向上させる手法として、一般的に以下の3つが検討されます。私たちは開発コスト・運用コスト・データ準備の観点から比較しました。
| 手法 | 概要 | メリット | デメリット | 今回の判断 |
|---|---|---|---|---|
| プロンプトエンジニアリング | 指示文(Prompt)の工夫のみで精度を上げる | 開発・運用コストが最小。即時反映が可能。 | モデルの知識外のことは回答できない。 | 採用 |
| RAG | 外部知識を検索してプロンプトに含める | 最新情報や独自データに対応できる。 | 検索システムの構築・運用コストがかかる。 | 不採用 |
| ファインチューニング | 追加データでモデル自体を再学習させる | 特定のタスクや出力形式に特化できる。 | 高品質な大量の学習データと計算コストが必要。 | 不採用 |
選定理由
近年、LoRA(Low-Rank Adaptation)1などの効率的な手法の普及により、ファインチューニングのハードルは大きく下がりました。それでも、まずはプロンプトエンジニアリングで限界まで性能を引き出し、ベースラインを確立してから次の手法を検討する、というワークフローがベストプラクティスとなっています。
OpenAIの公式ドキュメント内のOptimizing LLM Accuracy2では、モデルの最適化を「Context(知識)」と「Behavior(振る舞い)」の2軸で定義しています。まずはプロンプトでベースラインを測定します。その上で、独自の知識が不足していればRAGを、特定の振る舞いや出力形式の徹底が必要であればファインチューニングを選択する、というアプローチです。また、多くの場合、プロンプトエンジニアリングだけで本番レベルの精度に到達できるという旨も記載されています。
今回のタスクにおいても、ファッションの一般的な知識自体はLLMが既に学習済みであり、最大の課題は「ZOZO独自の定義へのすり合わせ」にありました。そのため、いきなりコストや運用負荷のかかる手法に移行するのではなく、まずはプロンプトを徹底的に磨き込むことにしました。
プロンプト改善・評価サイクル
Google Cloudの「プロンプト設計の戦略」ドキュメント3より、プロンプト設計は反復的なプロセスであるとされており、継続的なテストと評価の重要性が説かれています。私たちはこれに則り、本格的なプロンプトチューニングへ着手する前に、以下のプロセスで評価サイクルを構築しました。
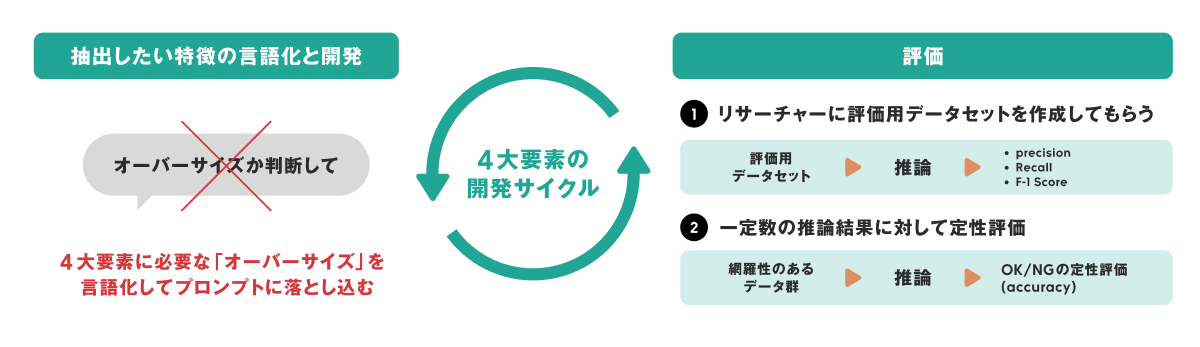
1. 開発用データセットの作成
エンジニアがプロンプト改善を試行錯誤するための正解データを用意します。社内のリサーチャー(ドメインエキスパート)に依頼し、WEARに投稿されたコーディネートの中から評価対象の特徴を持つ画像を探してラベルを作成してもらいました。
今回は100項目以上の特徴抽出が必要になるため、全件に対して十分なアノテーションを用意することは工数面で非現実的でした。そこで、本施策では各特徴量につき10件という最小限のデータで精度を検証するアプローチを採用しました。少数のデータでは特定のアイテムへの過学習(汎化できているか)が課題になります。これについては後述する定性評価にて、後段のルールベースを通した最終結果で担保する割り切ったアプローチをとりました。
2. プロンプト改善
開発用の評価データセットがあるおかげで、エンジニアは「なんとなく良さそう」といった感覚値ではなく、目標とした定量指標に向かってプロンプトを改善できるようになりました。今回は正解率70%を目標に設定しています。もちろん100%が理想ですが、開発リソースやリリースまでの期間には限りがあります。そこで、「抽出した特徴でコーディネート検索を行った際、結果として並んだ10枚のうち、何枚までならノイズが混ざっても体験を損なわないか」というシナリオをもとにプロジェクト内で議論しました。その結果、リリースに向けた開発コストとユーザー体験のバランスをとる現実的な落とし所として、この70%という目標値を決定しました。このように明確な基準と評価データが揃ったことで、エンジニアが手元で自律的かつ高速にチューニングを回すことができました。
3. ルールベースのロジックを通した最終出力による定性評価
開発用データセットに対する過学習を防ぎ、本番環境での網羅性を確認するために定性評価します。本来はLLMが抽出した特徴を直接評価したいところですが、無作為に収集した画像に対する抽出結果では出現頻度の低い特徴をうまく引き当てられません。また、評価する特徴が多過ぎるため、効率的な評価が困難です。そこで、後段のルールベースのロジックを通した結果のラベルを使って定性評価することにしました。開発段階でWEAR上の全データを推論すると時間とコストがかかり過ぎてしまうため、ファッションの季節性を網羅するように評価用データセットを作成しました。評価用データセットに特徴抽出とルールベースの判定をしてラベルを付与しました。最終的に付与されたラベルごとに300枚をサンプリングし、リサーチャーによる定性評価(こちらも目標正解率70%)をしました。
評価サイクルで得られた効果と結果
エラー分析による「曖昧さ」の解消
定量評価が可能になったことで、冒頭で触れた「ファッションの曖昧さ」に対して、「具体的に何ができていないのか」が可視化されるようになりました。例えば、評価結果のFalse Positive(誤検知)を分析した結果、以下のような原因が判明しました。
- 「厚底」の特徴:LLMの持つ一般的な厚底の基準と、ZOZOが求める基準にズレがある。
- 「柄や装飾」の特徴:服のシワや影を、柄として誤認識してしまっている。
原因が具体的に特定できたことで、リサーチャーと「どうすればLLMに伝わるか」を擦り合わせることが容易になりました。結果として、単純な2値(Yes/No)で判定させるのではなく、「度合いを複数のクラスに分類させてから判定する」といったプロンプトの改善に繋げられました。こうした改善の積み重ねにより、目標の正解率70%を達成しました。
適切なモデル選択
今回のプロジェクトでは非常に多くの特徴量を抽出するため、色や柄などのファッション特徴のカテゴリごとにプロンプトを分けています。
タスクの難易度に応じて、より上位のモデルを採用したものもあれば、逆に軽量なモデルへ落としても精度を維持できたものもありました。定量評価によって「どこまでモデルを落としても許容できるか」が数値化されたことで、システム全体での推論コストや処理時間の最適化を安全に進められました。
今回の手法の確からしさ
全ての特徴の開発とラベルの評価が完了したあとに、4か月分のデータセットに対してラベルの付与率などを分析しました。また、サービスリリース前にWEAR上のコーディネート画像全件に対しても同様に推論・分析し、付与率に大きな差がないことを確認しました。非常に少ないアノテーション画像からのスタートでしたが、特定の期間やアイテムに特化した調整(過学習)にはなっておらず、本番環境のデータに対しても適切に汎化できていることが確認できました。
課題と展望
今後の展望:LLM-as-a-judgeの導入
一方で、評価用データセットの作成にはリサーチャーの人手コストがかかるという課題も残りました。今後は、作成した正解データと評価基準を用いて別のLLMに評価担当を任せるLLM-as-a-judgeの導入を検討しています。LLMによる一次評価で大まかな傾向を掴み、判断が分かれる際どいケースのみリサーチャーが確認するフローにすることで、評価コストを下げつつ、より高速な改善サイクルを実現できます。
まとめ
本記事では、WEARの機能開発におけるLLM活用事例として、RAGやファインチューニングを使わずに高精度な特徴抽出を実現したプロセスをご紹介しました。
ZOZOでは、ファッションの曖昧な感性を技術で解き明かし、ユーザーに新しい体験を届けるエンジニアを募集しています。ご興味のある方は、ぜひ採用ページをご覧ください。
