みなさんEC2インスタンスを運用していて、うっかり停止するのを忘れてしまうことってありませんか?
- 一時的な検証のために必要になってしばらく起動させていたけど、検証期間が終わっても停止していなかった
- サービスでの利用開始はまだ先なので停止しておきたいけど、ちょくちょく起動して設定修正するので、停止し忘れていないか心配になる
- 必要になった時だけ起動してtoolを実行する運用が徹底されない
- 自動停止の設定をしてあるが、停止スケジュール後も利用したくて手動で起動してそのまま放置
EC2インスタンスの自動停止の仕組みを導入するほどではないけど、止め忘れてしまったことには気づきたい、しかもなるべく簡単に。
今回は、CloudWatch標準メトリクスを使って、長時間起動し続けているEC2インスタンスをお手軽に検知する方法を紹介します。
CloudWatchメトリクスのデータ不足を利用する
EC2の標準メトリクスには、インスタンスが何時間起動しているかを示す、Uptimeのようなメトリクスはありません。
実現方法を検索すると、CloudWatchエージェントをインストールしてカスタムメトリクスを作成したり、
LambdaやDynamoDBを駆使して、監視システムを構築する方法の紹介記事がヒットしました。
なるべく手間をかけず、一時的に監視しておきたいだけだったので、CloudWatch標準メトリクスだけで何とかならないか...
考えた結果、インスタンスが起動しているときだけCloudWatchメトリクスの値が記録される ことを利用することにしました。
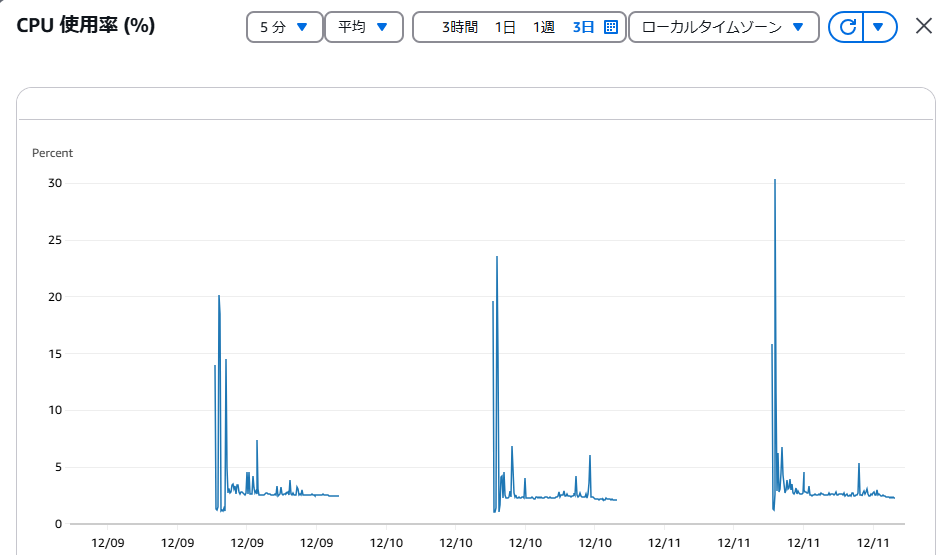
このとおり、インスタンスの起動中は、値が記録され、停止中は値がありません。
CloudWatchアラームではデータ不足となる期間です。
メトリクスの値が欠落なく連続して存在している期間を取得できれば、インスタンスの連続稼働時間として検知できそうです。
たとえば、インスタンスが24時間以上連続で稼働していることを検知するCloudWatchアラームは次のような設定となります。
- メトリクス名(Metric Name): 任意のEC2の標準メトリクス
- しきい値(Threshold):
0.0以上 - 期間(Period):
600 - 評価期間(Evaluation Periods):
144- 24h(86400s)を期間(600s)で割ると144回評価をおこなうことになります
- アラームを実行するデータポイント(Datapoints to Alarm):
144- 評価期間すべてのデータポイントでメトリクスの値がある場合
ALARMとなります
- 評価期間すべてのデータポイントでメトリクスの値がある場合
- 欠落データの処理(Missing data treatment):欠落データを適正として処理(
notBreaching)- データが存在しない期間は停止中なので正常とします
10分間隔でチェックをして、24h(144回)連続でメトリクスの値が存在した場合にアラート状態となります。
あとは、アラートアクションでSNSトピックスにメッセージ送信したり、EC2アクションで停止する設定を行ってください。
必要な設定は以上となります。
以降はアラームの使い勝手を改善したパターンを紹介します。
数式を使ったアラームで検知時間を短縮する
前述のような条件でCloudWatchアラームを作成した場合、状態がALARMからOKに戻るのに、期間(Period)以上の時間が必要になります。
これは、しばらく欠落データが続いた場合に、直近に存在しているデータポイントの値を使って評価し続けるためです。
検証を行ったときは、インスタンスを停止してから30分ほどたってから、ようやくアラームの状態が正常にもどるような状況でした。
インスタンスの停止をスムーズに通知するためには、データがあれば1、欠落データなら0というように、データ欠損がないグラフに変換します。
CloudWatchメトリクスで、対象インスタンスの任意のメトリクスをグラフ表示させたら、次のようなMetric Mathを使った数式を追加してください。
FILL(IF(m1 >= 0, 1, 0),0) ※m1は対象インスタンスの標準メトリクスを指定したグラフ
FILL関数で対象のメトリクスの値が欠損している場合0で埋めるIF関数で対象のメトリクスの値が0以上なら1、それ以外は0に変換する
この数式で作成されたグラフをCloudWatchアラームに設定すれば、インスタンスを停止した次の評価のタイミングでアラーム状態がOKに戻るようになります。
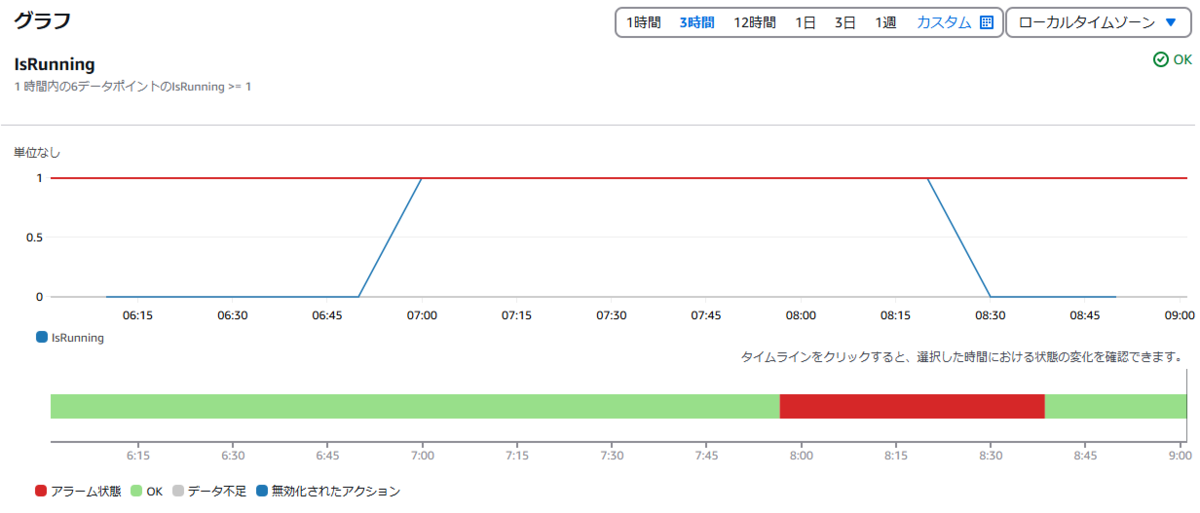
注意点は、数式を使ったメトリクスに基づいたCloudWatchアラームでは、EC2アクションを選択することができません。 このアラームを使ってインスタンスを自動停止したい場合は、EventBridgeルールでアラームのステータス変化を監視して、インスタンス停止アクションを実行してください。
Terraformモジュールで簡単に設定
毎回AWSマネジメントコンソールからアラーム設定するのは手間なので、Terraformのモジュールにして、簡単に登録できるようにしました。
modules/EC2-UptimeCheck ├── main.tf ├── output.tf └── variable.tf
パラメータ
| Name | Description | Type | Default | Required |
|---|---|---|---|---|
| instance_id | インスタンスID | string |
N/A | yes |
| instance_name | アラーム名につける文字列 省略した場合instance_idが使われます |
string |
"variable undefined" |
no |
| sns_topic_arn | アラーム・OKアクションに指定するSNSトピックス | string |
N/A | yes |
| uptime_threshold | 稼働時間のしきい値 | number |
86400 |
no |
| check_period | 監視間隔 | number |
600 |
no |
main.tf
locals { instance_name = var.instance_name == "variable undefined" ? var.instance_id : var.instance_name } resource "aws_cloudwatch_metric_alarm" "EC2Uptime_check" { alarm_name = "EC2UptimeCheck_${local.instance_name}" alarm_description = "Uptime_check" comparison_operator = "GreaterThanOrEqualToThreshold" evaluation_periods = "${var.uptime_threshold / var.check_period}" datapoints_to_alarm = "${var.uptime_threshold / var.check_period}" threshold = "1" treat_missing_data = "notBreaching" metric_query { id = "m1" metric { metric_name = "StatusCheckFailed" namespace = "AWS/EC2" dimensions = { InstanceId = var.instance_id } period = var.check_period stat = "Maximum" } } metric_query { id = "e1" expression = "FILL(IF(m1 >= 0, 1, 0),0)" label = "IsRunning" return_data = "true" } alarm_actions = [ var.sns_topic_arn ] ok_actions = [ var.sns_topic_arn ] }
variable.tf
variable "instance_id" { description = "インスタンスid" type = string } variable "instance_name" { description = "インスタンス名" type = string default = "variable undefined" } variable "sns_topic_arn" { description = "SNSトピックスARN" type = string } variable "uptime_threshold" { description = "稼働時間閾値(sec)" type = number default = 86400 # 1day } variable "check_period" { description = "検証間隔(sec)" type = number default = 600 }
output.tf
output "EC2UptimeCheck_alarm" { value = aws_cloudwatch_metric_alarm.EC2Uptime_check.id }
まとめ
EC2インスタンスの止め忘れをとにかく簡単に検知したい方は、今回紹介した方法をぜひお試しください。
検知するだけでなく、スケジュールで自動停止したい方は、本ブログでも方法を紹介していますので、そちらもチェックしてみてください。
