
こんにちは。CARTA ZERO の DSP チームで @marching_cube として活動しています。
私たちのチームは、オンライン広告向けの大規模なリアルタイムビッディング(RTB)システムを運用しています。膨大な数の入札リクエストに対して、高速な機械学習モデルを複数展開しています。
最近は、ML パイプライン改善に取り組んでおり、特に前処理を共通化した実装に注力してきました。この過程で得られた知見を今回のブログで共有をしたいと思います
この記事を読み終える頃には、生の文字列から最終的な予測結果まで、すべてを単一の ONNX アーティファクトにシリアライズすることで、学習時と推論時のズレ(training–inference drift)をどのように解消しているかが分かるはずです。
この記事で学べること
- 前処理は学習時だけのものではなく、本番コードの一部として扱う重要性
- 前処理と学習を 1 つの
sklearn.Pipelineにまとめることで、デプロイが大幅に簡単になり、学習と推論のズレを減らせること - カスタムエンコーダには慎重なテストと明示的な変換ロジックが必要なこと
- カスタム前処理や特徴量エンジニアリングを導入する際には、sklearn と onnxruntime を比較するテストが不可欠なこと
- 役割が明確な小さなエンコーダを再利用する方が、大きくて一体化した前処理パイプラインよりもスケールしやすいこと
- 複数のフレームワーク、モデル、デプロイ環境をサポートするうえで、早い段階から柔軟性に投資することは後々大きな効果をもたらすこと
用語集
- Real-time Bidding (RTB): 広告オークションに参加するシステムです。膨大な入札リクエストに対し、一つひとつ値段を決める仕組みです。
- sklearn: Pythonの人気の機械学習ライブラリです。
- ONNX: 機械学習モデルの保存フォーマットです。.onnxファイルは多数の環境で実行が可能です。
- onnxruntime: .onnxファイルを実行するライブラリです。Python、C、Javaなど多数の言語に対応しています。
- 学習(Training): データから賢いモデルを作るフェーズです。試行錯誤がしやすくライブラリが豊富な Python が主役です。
- 推論(Inference): 実際にユーザーに広告を出すフェーズです。DSPでは、0.1秒以内に計算を終える必要があります。
- Training-Inference Drift: データサイエンティストが準備したPythonの仕組みと、推論環境の実装が少しでも食い違うと発生する厄介な問題です。
- 前処理: 学習時も推論時も、生データをモデル入力に変換する仕組みです。
機械学習パイプライン全体のアーキテクチャ概要
私たちの MLOps パイプラインの目的は、開発者の手をあまり介さずに、機械学習モデルの学習とデプロイを繰り返し行えるようにすることです。 そのために、パイプラインのオーケストレーション、データ収集など、さまざまなコンポーネントが組み合わさって動いています。 全体のゴール自体はとてもシンプルです:
- 機械学習モデルを学習する
- ONNX 形式にパッケージする
- そのままの形で本番環境にデプロイする
これらを実現するため、次のような手順を採っています。
- 機械学習モデルは常に sklearn のパイプラインでラップする
- 1 つのパイプラインは、次の 3 つのパートで構成される
- 前処理(OneHotEncoding、SimpleImputer など)
- モデル学習(sklearn、PyTorch、LightGBM など)
- 後処理(キャリブレーション、CDF など)
- 学習を成立させるために、各 ML フレームワークを sklearn の classifier として扱うためのカスタムコードを用意する
- 学習済みパイプラインは、skl2onnx 変換ライブラリを使って ONNX にエクスポートする
- 多くの標準的な sklearn コンポーネントをサポートしている(例外もある)
- PyTorch モジュールなどをエクスポートするために、軽量なコールバックが必要になる
- さらに、前処理を扱うための多くのカスタムコードも必要になる
- カスタムコードが sklearn と ONNX の両方で同じ結果を出すことを保証するため、多数のユニットテストを書く
- 最後に、エンドツーエンドのテストを自動で実行し、本番コードでも同じ挙動になることを確認する
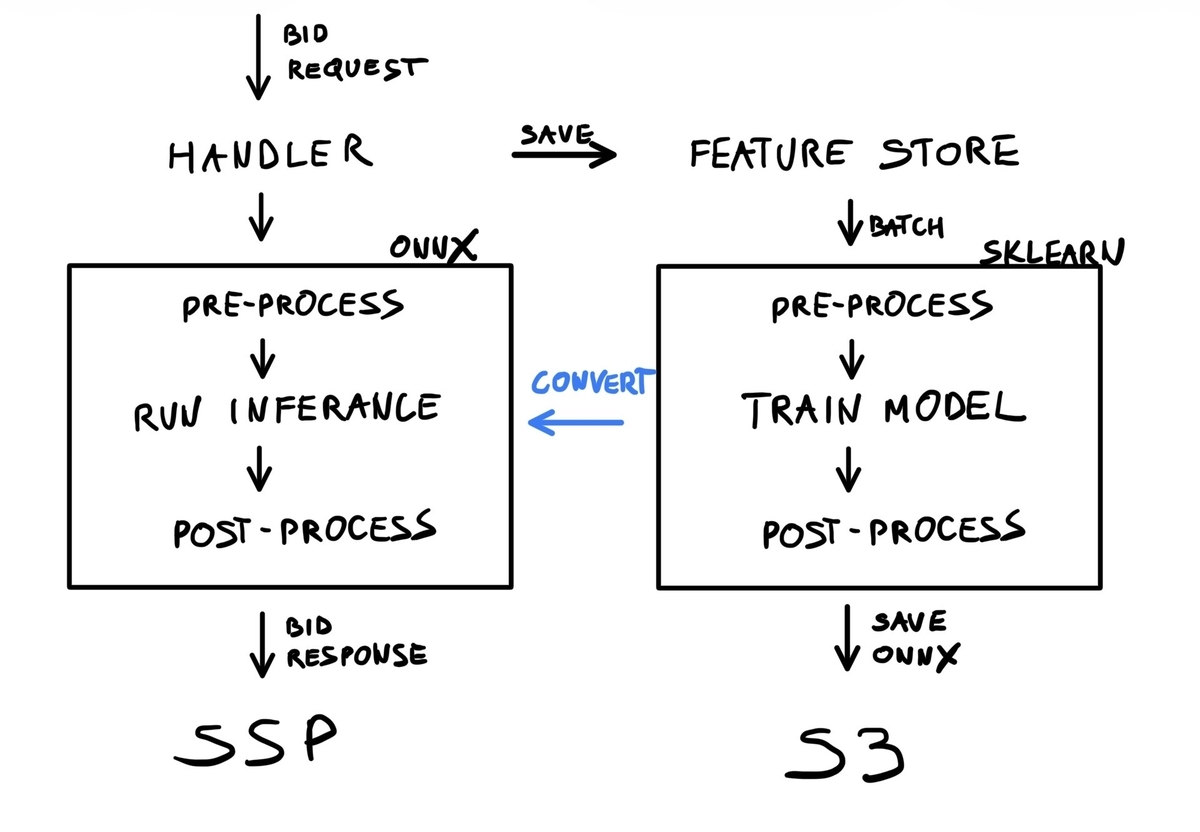
ONNX対応の機械学習パイプラインの設計について、詳しくは昨年の記事をご覧いただくことをおすすめします: techblog.cartaholdings.co.jp
前処理パイプラインとは何か、そしてなぜ重要なのか
前処理は、全体のパイプラインの一部であり、データストアから取得した生の特徴量を、機械学習モデルが直接扱えるテンソル入力へと変換する役割を担っています。多くの場合、こうした処理は単純な定型作業であり、小規模なプロジェクトではあまり意識されないこともあります。しかし、機械学習パイプラインの基盤として非常に重要な要素です。特に重要なのは、この変換が学習時(Python)と推論時(今回のケースでは Kotlin)で完全に同一の方法で実装されている点です。
前処理は、文脈や目的に応じて、次の 2 つの観点で考えることができます。
- エンコーディング:生データを、その意味を保ったまま数値に変換するもの
- 特徴量エンジニアリング:生データから特定の情報を抽出するもの
いくつか簡単な例を見てみましょう。
ad_campaign_idは名義尺度の整数値です。各値は異なるオブジェクトを表しており、大小比較や代数的な変換には意味がありません。このような ID は、そのまま使うか、ダミー変数(OneHotEncoding)に展開します。req_ssp_nameは、リクエストを送信してきた SSP を表す文字列です。文字列は、整数に変換する(OrdinalEncoder)か、ダミー変数に変換する必要があります。ad_creative_frequencyは、特定のクリエイティブに対する過去の表示回数です。通常は、欠損値を補完したり(SimpleImputer)、対数変換を行ったり、ビン分割されたカテゴリに変換したりします。imp_average_ctrは浮動小数点の値で、回帰モデルではそのまま使うこともできますし、カテゴリに分割して使うこともあります。- ほかにも多くの例があります。
Before: 特徴量を カテゴリ型・数値型・バイナリ型 に3分類
特徴量ごとに個別の前処理を設計することもできますが、特徴量の数が多くなると現実的ではありません。 そこで以前は、特徴量を カテゴリ型・数値型・バイナリ型 の 3 つに分類し、それぞれに固定の前処理パイプラインを割り当てていました。この方法は初期段階ではうまく機能していましたが、リリースを重ねるにつれて、モデルの複雑さや要求も次第に増していきました。
- 利用可能な特徴量が増え、新しい特徴量の中には、既存の固定セグメントにきれいに当てはまらないものが出てきた
- 複数の学習フレームワークやモデルアーキテクチャをサポートするようになり、特徴量のエンコーディングが利用箇所に依存するケースが増えた
- 基本となるデータ型が明示的に定義されておらず、3 つのセグメントへの暗黙的な変換が入り込んでいた
- データベースには存在せず、既存の特徴量から動的に計算される組み合わせ特徴量を多数導入した
- ビニング方法を変えるといった小さなカスタマイズでも、既存の設計が破綻し、見苦しい実装につながってしまう
After: カスタム変換ルールを追加できるよう
そこで現在は、より動的なパイプライン設計へと移行しています。
データ型、利用目的、適用可能な変換を考慮し、コールバックを通じてカスタム変換ルールを追加できるようにしました。前処理パイプラインは、現在のモデルの文脈に応じて動的に解決されます。
| Type | Usage | Features | default transformations |
|---|---|---|---|
| Integer | nominal | ad_campaign_id | OneHotEncoder/OrdinalEncoder |
| Integer | ordinal | frequency | SimpleImputer, FunctionTransfomer |
| Double | ordinal | average_ctr | SimpleImputer, StandardScaler |
| Double | nominal | average_ctr | KBinsDiscretizer |
| Boolean | nominal | ad_is_video | OneHotEncoder/OrdinalEncoder |
| String | nominal | req_ssp_name | OneHotEncoder/OrdinalEncoder |
sklearn が標準で提供しているエンコーダでも、かなり多くのユースケースをカバーできます。ただし、それに加えて、私たちはいくつかのカスタムエンコーダも実装しています。
CustomOneHotEncoder
出現頻度の低いカテゴリをより適切に扱うための One-Hot エンコーダCustomOrdinalEncoder
「欠損」カテゴリの扱いを改善し、埋め込み(embedding)参照での利用を簡単にするためのエンコーダFeatureCrossEncoder
sklearn のPolynomialEncoderに似ていますが、文字列特徴量にも対応していますEmbeddingEncoder
事前計算された埋め込みテーブルを使い、高速に実験できるようにするエンコーダUniformBinningEncoder
従来から使っているビニング手法で、将来的にはKBinsDiscretizerに置き換える予定ですCalendarEncoder
タイムスタンプから時間や曜日などの要素を抽出し、週末かどうかといったイベントフラグを追加します- …
これらを動かすためには、実際にはかなりのカスタム実装が必要になります。ただし、エンコーダ自体は完全に再利用可能で、ONNX グラフの一部としてそのまま本番環境にデプロイできます。
実装方針
典型的な実装は、sklearn の標準的なパターンに従っています。まず、用途に応じた sklearn.pipeline.Pipeline を構築し、それらを一つずつ組み合わせて、より複雑な学習パイプラインを作っていきます。
最初に行うのが前処理です。概念的には、次のような形になります。
pipeline1 = Pipeline(steps=[
SimpleImputer(strategy="mean"),
StandardScaler()
])
pipeline2 = ...
pipeline3 = ...
preprocessing = ColumnTransformer(transformers=[
("group1", pipeline1, features_in_group1),
("group2", pipeline2, features_in_group2),
("group3", pipeline3, features_in_group3),
])
これは、カテゴリ型・数値型・バイナリ型の 3 つの固定セグメントを使っていた初期の実装に対応しています。ただし、実際の割り当てロジックは、これよりもはるかに複雑になり得ます。そのため、カスタム実装では、上記のようなハードコードされた変換を置き換え、次のように動的に解決される形を目指しています。
preprocessing = Encoders(
supports_ordinal_cateogories=True,
supports_numerical_features=False
).build_pipeline()
柔軟な実装の鍵となるのは、前処理(上記)と学習の両方を、単一の sklearn.Pipeline にまとめることです。
個々のコンポーネントを別々に学習させるのではなく、すべてをまとめてフィットさせます。
pipeline = sklearn.pipeline.Pipeline(steps=[
('preprocessing', preprocessing),
('training', model),
]
pipeline.fit(X, y)
最後に、学習済みのパイプラインを、skl2onnx ライブラリを使って直接 ONNX 表現に変換します。
proto = skl2onnx.convert_sklearn(pipeline)
artifact_registry.save(proto, "amazing-new-model")
エコシステムの拡張:CalendarEncoder の例
低レベルなカスタマイズの例として、最小限の CalendarEncoder を実装してみます。これは特徴量エンジニアリング用のエンコーダで、「リクエスト時刻」(必ずしも現在時刻ではありません)を入力として受け取り、時間帯や曜日、各種イベントフラグといった有用な変数に変換します。ここで重要なのは、タイムスタンプを整数として表現することです。そうすることで、特徴量の抽出を、基本的な算術演算と sin や cos といった一般的な関数だけで行えるようになります。
パート 1:学習時のサポート
まずは、カスタム sklearn エンコーダのシンプルな実装例を見てみましょう。
import pandas as pd from sklearn.base import BaseEstimator, TransformerMixin class CalendarEncoder(BaseEstimator, TransformerMixin): def fit(self, df: pd.DataFrame, y: pd.Series | None = None) -> "CalendarEncoder": return self def transform(self, df: pd.DataFrame) -> pd.DataFrame: name = df.columns[0] return pd.DataFrame({ f"{name}_hour": ((df[name].astype(int) + 9 * 3600) // 3600) % 24, f"{name}_dow": (df[name].astype(int) + 9 * 3600 + 4 * 24 * 3600) // (24 * 3600) % 7, f"{name}_sin": np.sin((df[name].astype(int) + 9 * 3600) % (24 * 3600)), f"{name}_cos": np.cos((df[name].astype(int) + 9 * 3600) % (24 * 3600)), })
いくつか補足します。
- init メソッドは省略していますが、本来はここで適用する変換内容を設定するのが理想です。
- 上の例のように、
fitでは特に何もしないケースもよくあります。 - 一方で、実際に重要な処理は
transformに実装されます。 - このエンコーダには、祝日やキャンペーン日を示すフラグなど、さらに多くの有用な変換を追加できます。
- JST に合わせる処理(
9 * 3600の係数)は、必須というわけではありません。 - ここでは入力として
pd.DataFrameのみを扱っていますが、一般なnp.ndarrayを入力・出力に使うこともできます。 - ユニットテストと簡単なドキュメントは必須です。
パート 2:推論時のサポート
これで CalendarEncoder は、学習済みモデルと一緒にフィットできるようになります。ただし、このままでは ONNX には変換できません。追加のカスタマイズが必要です。
skl2onnx ライブラリは、多くの sklearn.Pipeline コンポーネントをそのまま扱えますが、カスタムコードを自動で変換することはできません。たとえば、次のようなケースがあります。
- PyTorch の学習コードはデフォルトでは扱われませんが、
torch.exportを使えば比較的簡単に統合できます。 FunctionTransformerは sklearn の標準コンポーネントですが、任意の引数を取れるため、skl2onnxでの変換には向いていません。CalendarEncoderのようなカスタムエンコーダは、当然ながらサポートされていません。- ほかにもいくつかあります。
幸いなことに、変換用のコールバックは自分たちで簡単に用意できます。ただし、細かい部分はやや面倒です。
最低限、次の 2 つ(通常は 3 つ)のコールバックを定義する必要があります。
- 出力の構造(個数や名前)を定義する(任意の)パーサ
- 出力の型と形状を定義するシェイプ計算
- sklearn の
transform関数を ONNX 表現に変換するコンバータコード
flowchart LR
parser["Parser<BR>(Inputs/Outputs)"]
shapes["Shape Calculator<BR>(Types)"]
converter["Converter<BR>(Math Logic)"]
parser ---> shapes
shapes ---> converter
parserの実装はとてもシンプルです。入力と出力を列挙するだけで十分です。この例では、入力は 1 つで、名前付きの出力が 4 つあります。
from skl2onnx import get_model_alias from skl2onnx.common._topology import Operator, Scope def _onnx_parser(scope: Scope, model: Any, inputs: list, custom_parsers: Any = None) -> list: onnx_name, onnx_type = inputs[0].onnx_name, inputs[0].type.__class__ operator = scope.declare_local_operator(get_model_alias(type(model)), model) operator.inputs.extend(inputs) operator.outputs.extend([ scope.declare_local_variable(f"{onnx_name}_hour", onnx_type()), scope.declare_local_variable(f"{onnx_name}_dow", onnx_type()), scope.declare_local_variable(f"{onnx_name}_sin", onnx_type()), scope.declare_local_variable(f"{onnx_name}_cos", onnx_type()), ]) return operator.outputs
shape_calculator では、出力がどの型になるかを明示的に定義します。
この少し作為的な例では、出力の半分が整数型、残りの半分が浮動小数点型になっています。
from skl2onnx.common._topology import Operator, Scope from skl2onnx.common.data_types import Int64TensorType, FloatTensorType from skl2onnx.common.utils import check_input_and_output_numbers def _onnx_shape_calculator(operator: Operator) -> None: check_input_and_output_numbers(operator, input_count_range=1, output_count_range=4) operator.outputs[0].type = operator.outputs[1].type = Int64TensorType([None, 1]) operator.outputs[2].type = operator.outputs[3].type = FloatTensorType([None, 1])
最後に、converter では ONNX のプリミティブを使って、実際の変換ロジックを実装します。
skl2onnx.algebra.onnx_ops を使うことで、より低レベルなフレームワークを使う場合と比べて、コードをかなり書きやすくなります。
from skl2onnx.algebra.onnx_ops import OnnxAdd, OnnxDiv, OnnxMod, OnnxSin, OnnxCos, OnnxCast from skl2onnx.common._container import ModelComponentContainer from skl2onnx.common._topology import Operator, Scope from skl2onnx.proto import onnx_proto def _onnx_converter(scope: Scope, operator: Operator, container: ModelComponentContainer) -> None: opv = container.target_opset # ここでJST変換をしています jst = OnnxAdd(operator.inputs[0], np.array([9 * 3600]), op_version=opv) # 時間 = (jst // 3600) % 24 z = OnnxDiv(jst, np.array([3600]), op_version=opv) z = OnnxMod(z, np.array([24]), op_version=opv, output_names=operator.outputs[0]) z.add_to(scope, container) # 曜日 = ((jst + 4 * 24 * 3600) // (24*3600)) % 7 z = OnnxAdd(jst, np.array([4 * 24 * 3600]), op_version=opv) z = OnnxDiv(z, np.array([24 * 3600]), op_version=opv) z = OnnxMod(z, np.array([7]), op_version=opv, output_names=operator.outputs[1]) z.add_to(scope, container) # sin = math.sin(jst % (24 * 3600)) z = OnnxMod(jst, np.array([24 * 3600]), op_version=opv) z = OnnxCast(z, to=onnx_proto.TensorProto.FLOAT, op_version=opv) z = OnnxSin(z, op_version=opv, output_names=operator.outputs[2]) z.add_to(scope, container) # cos = math.cos(jst % (24 * 3600)) z = OnnxMod(jst, np.array([24 * 3600]), op_version=opv) z = OnnxCast(z, to=onnx_proto.TensorProto.FLOAT, op_version=opv) z = OnnxCos(z, op_version=opv, output_names=operator.outputs[3]) z.add_to(scope, container)
最後に、どの処理をいつ使うかを skl2onnx に登録します。
from skl2onnx import update_registered_converter update_registered_converter( CalendarEncoder, "CalendarEncoder", _onnx_shape_calculator, _onnx_converter, parser=_onnx_parser, )
ここまででかなりの分量になりましたが、これで ONNX を完全にサポートするには十分です。
skl2onnx.convert_sklearn は、必要に応じて私たちのカスタムコールバックに処理を委譲し、生の特徴量を入力として最終的な予測を返す、単一の ONNX グラフにすべてのノードをまとめてくれます。
最後に、いくつか注意点を挙げておきます。
- 上記の例はやや作為的で、実際の利用に応じて、本番コードではもっと整理された設計になるはずです。
- ユニットテストも重要ですが、sklearn と onnxruntime の結果を比較するテストは必須です。
- パーサとシェイプ計算のコードは、再利用可能なライブラリとして切り出したほうがよいでしょう。
- 定数をハードコードしている点については、ご容赦ください。
まとめ
これまでに説明してきた設計に近い仕組みは、すでに本番サーバーにデプロイされています。
各モデルは、カスタムエンコーディングや特徴量エンジニアリングを含めて、1 つの独立した ONNX ファイルとして表現されています。アーキテクチャはいつでも差し替え可能で、配信コードを頻繁に更新したり、学習時と推論時の実装差分を心配したりする必要はありません。主な狙いは、何をデプロイできるかという柔軟性を確保することです。
付録:sklearn.preprocessing.FunctionTransformer
多くの場合、カスタムエンコーダを書く代わりに、sklearn 標準の FunctionTransformer をそのまま使っています。型変換や単純な算術演算といった軽量な変換であれば、次のように追加するだけで済みます。
pipeline = Pipeline(steps=[
SimpleImputer(strategy="mean"),
FunctionTransformer(func=np.log1p)
])
残念ながら、skl2onnx は任意の関数引数をそのまま扱うことはできません。ただし、変換用のコールバックを追加する手間はそれほど大きくありません。
上の例に対する最小限の実装は、次のようになります。
def _shape_calculator(operator: Operator) -> None: check_input_and_output_numbers(operator, input_count_range=1, output_count_range=1) operator.outputs[0].type = operator.inputs[0].type def _converter(scope: Scope, operator: Operator, container: ModelComponentContainer) -> None: opv = container.target_opset z = OnnxAdd(operator.inputs[0], np.array([1]), op_version=opv) z = OnnxLog(z, op_version=opv, output_names=operator.outputs[0]) z.add_to(scope, container) update_registered_converter(FunctionTransformer, "FunctionTransformer", _shape_calculator, _converter)
実際には、1 つの変換だけで足りることはほとんどありません。そのため、最終的には、利用可能な基本的な関数をすべて網羅する、長い switch 文になるのが一般的です。
