こんにちは!プロダクトエンジニアのkazzhiraです。
私たちのチームでは、2025年の夏ごろから「AI活用による開発生産性の向上」に取り組んできました。しかし、当初の取り組みは抽象的なガードレールの提示や個々人の実践にとどまり、チームとして大きな成果には結びつきませんでした。
その後、SDD(仕様駆動開発)というアプローチに出会い、オープンソースの cc-sdd フレームワークをベースに試行錯誤を重ねてきました。
本記事では、AI開発標準の策定に失敗した経験から何を学び、どのように仕様駆動開発に辿り着いたのか、そして、実践を通じて得た成果と学びをご紹介します。
チームのAI導入でうまくいかなかった話
AI活用の個人最適化
当初、チームでは Cursor、Claude Code、Devin、GitHub Copilot、Gemini などの AI ツールを個々人の判断で利用できる状態でした。 しかし、AI活用の状況は個々人に閉じており、チームとしてのナレッジ共有や標準化は進んでいませんでした。
AI開発標準策定の失敗
そこで「AI開発標準」の策定を試みました。情報を収集したうえで、Planモードで実装計画を立て、途中でレビューを挟む開発スタイルを言語化しました。しかし、結果的にこの取り組みは失敗に終わりました。
- 資料の説明が抽象的で、チームが具体的に動きようがなかった
- 開発手法の共通項を抜き出しただけのガードレールに過ぎなかった
- 実際の開発プロセスに落とし込めず、絵に描いた餅になった
なぜSDDをやろうと思ったのか
理想の開発体験の議論
チームで理想の開発体験・開発生産性の課題を話し合った結果、以下の課題が明確になりました。
- リファインメント(仕様を決める会議)で議論が発散して収束に時間がかかる
- AIは顧客課題、ユーザーストーリーを知らず、要件の精度が高くない
- AIの出力が微妙で、整理されたコンテキストが足りない
SDDとの出会い
これらの課題を解決する方法として、SDD(仕様駆動開発)に辿り着きました。
SDDの本質は、仕様書を「単なるドキュメント」ではなく、AI と人間の両方が参照する SSoT(Single Source of Truth)として機能させることです。
- 定性面
- AIがユーザーストーリー、背景、受け入れ条件から精度の良い仕様書を生成する
- →「AIは顧客課題、ユーザーストーリーを知らず、要件の精度が高くない」の解決
- 構造化された要件定義書・設計書・開発ルールで一貫したコンテキストを提供する
- →「AIの出力が微妙で、整理されたコンテキストが足りない」の解決
- AIがユーザーストーリー、背景、受け入れ条件から精度の良い仕様書を生成する
- 定量面
- 価値提供速度の向上
これらの効果を期待し、投機的に取り組んでみることを決めました。
ちなみに、「リファインメントで議論が発散して収束に時間がかかる」は当時Notion AIでの解決も試しました。しかし本題から外れるため、本記事では割愛します。
SDDの実践と工夫
cc-sddフレームワークの採用
SDD を実践するにあたり、私たちはオープンソースの cc-sdd(Spec-Driven Development フレームワーク)を採用しました。 深い理由はなく、筆者が各所で目にして実験的に入れていた背景があります。
チーム固有の課題
cc-sdd の基本的なアプローチを導入した上で、私たちのチームは以下の課題に直面しました。
- 複数のリポジトリを AI が横断的に操作できない
- チーム固有のタスク分割・実行ルールがなく、AI の出力がチームの開発フローに合わない
- Rails 固有の設計パターンが AI に伝わらない
- プロダクトのドメイン知識が AI に渡っていない
私たち独自のソリューション
これらの課題に対し、私たちは以下の解決策を構築しました。
1. マルチリポジトリ横断ワークスペース
Cursorによる開発を前提に、code-workspaceを生成して複数リポジトリを統合的に扱う仕組みを実装しました。
【my-team.code-workspace】
{ "folders": [ { "name": "my-team", "path": "." }, { "name": "backend", "path": "~/workspace/backend-repository" }, { "name": "frontend", "path": "~/workspace/frontend-repository" }, ... ] }
これにより以下のメリットが得られました。
- AI エージェント(Cursor / Claude Code 等)がリポジトリを横断して操作可能
- 仕様書リポジトリ(my-team)とコードベースを統合管理
私たちの最初の実装では、my-team・backend・frontendをセットで管理しました。 今はもう少し増えています。
2. タスク生成・実行ルールの整備
チーム固有のタスク生成・実行ルールを定義しました。
| ルール種別 | 内容 |
|---|---|
| タスク分割ポリシー | "デプロイ可能な最小粒度" にタスク分割 |
| Commit・Push・PRのルール | 例示することで、意図した生成に誘導する。例えば "commitには変更理由とリファレンスを必ず含める"、"PRテンプレートに従う" など。 |
| タスク実行順序の定義 | Swaggerを定義してからfrontendとbackendの作業に移行する。 |
3. カスタムステアリングドキュメント
Rails 固有の設計パターンやプロダクトのドメイン知識をステアリングドキュメントとして整備しました。
- Controller Patterns(
before_actionの濫用禁止、個別でエラーハンドリング不要など) - プロダクト固有の名称、用語、ユースケース
- リポジトリ構造のサマリ
- 採用している技術の詳細
例として「プロダクト固有の名称、用語、ユースケース」を定義した例を示します。
# Product Overview タイミーアプリのAPIサーバー、クライアント向けWebアプリケーションのAPIサーバー、 ワーカー向けモバイルアプリケーション、社内管理ツールを提供するプラットフォーム。 ## Core Capabilities 1. **ワーカー・クライアント管理**: ワーカーとクライアント企業のアカウント管理、認証、プロフィール管理 2. **求人・マッチング**: 求人作成、公開、ワーカーとのマッチング機能 3. **勤怠・給与管理**: 出勤管理、給与計算、支払い処理 4. **コミュニケーション**: チャット機能、レビュー・フィードバック機能 5. **管理機能**: 社内管理ツール、各種レポート・分析機能 ## Target Use Cases - **クライアント企業**: 求人作成・管理、ワーカー管理、勤怠確認、給与支払い - **ワーカー**: 求人検索・応募、勤怠管理、給与確認 - **社内管理者**: システム管理、データ分析、各種レポート生成 ## Value Proposition - ワーカーとクライアント企業を効率的にマッチングするプラットフォーム - 勤怠管理から給与計算まで一貫した業務フローを提供
4. カスタムコマンド
cc-sddのコマンド体系以外で、チームで必要な成果物を保管するためのコマンドを用意しました。内容は長いため省略します。
- QAチェックリストの自動生成「spec-qa-checklist」
- Playwright MCPによるQA自動実行「playwright-mcp-qa」
最終的なファイルツリーを示します。
my-team/
├── my-team.code-workspace # マルチリポジトリ統合ワークスペース定義(独自作成)
├── repos.yml # 対象リポジトリ一覧(独自作成)
├── repos.template.yml # ↑のテンプレート(独自作成)
├── docs/ # プロジェクト横断ドキュメント
│
├── scripts/
│ ├── setup.sh # 初期セットアップ(独自作成)
│ ├── setup-workspace.sh # ワークスペース構成生成(独自作成)
│ └── sync-*.sh # リポジトリ・設定の同期(独自作成)
│
├── .cursor/
│ └── commands/ # カスタムコマンド(独自作成)
│ ├── spec-qa-checklist.md # QAチェックリスト生成
│ └── kiro/ # Kiro Spec-Driven コマンド群
│
└── .kiro/
├── steering/ # アーキテクチャ制約
│ ├── product.md # プロダクト原則
│ ├── tech.md # 技術標準
│ └── structure.md # コード構造パターン
├── settings/
│ ├── rules/ # 設計・実行ルール(独自)
│ │ ├── tasks-generation.md # タスク生成(プレフィクス規約・分割順序)(独自作成)
│ │ └── task-execution-policy.md # 実行ポリシー(環境・Git・コミット規約)(独自作成)
│ └── templates/
│ ├── specs/ # 仕様テンプレート
│ └── steering/ # ステアリングテンプレート
└── specs/{feature}/ # 機能単位で生成
├── requirements.md # 要件
├── design.md # 設計
├── tasks.md # タスク
└── e2e-qa-checklist.md # QA(独自作成)
評価
ポジティブな評価
cc-sddの短期間の導入で最も価値を感じたのは、実装速度の向上ではなく、開発プロセスの質の向上でした。
- 暗黙知の形式知化 — これまで個人の頭の中にあった仕様判断が、requirements / design / task の3つの成果物を通して言語化・共有された
- 手戻りの減少 — 仕様書によってコンテキストが整理されたことで、AIの出力品質が安定し、実装後の手戻りが体感として減った
- 合意形成の質の向上 — 仕様を厳格に言語化するプロセスが、チーム内の認識齟齬を早期に解消した
- モブワークとの親和性 — 構造化された仕様書が共通言語として機能し、スプリント初期の設計作業を効率的に進めることができた
ネガティブな評価
一方で、チームで改善すべき課題も挙がっています。
- モノにもよるが、仕様書を作る工程で同期的に1日〜1.5日の時間を使う
- 仕様書を精査する工程の疲労感
- 実装スピードとデプロイ頻度は、以前と同等か、微増している感覚
- シンプルに練度不足
- リファインメントが引き続きボトルネック。実装が効率化しても、要求の供給が追いつかなければ全体のスループットは上がらない
- 中間生成物のレビューがリファインメントに次ぐボトルネック。AIが高速に生成するアウトプットに対し、人間のレビューが追いつかない
- etc.
データで見る事実:cc-sdd導入でデプロイ頻度は向上しなかった
前提として、開発者が3名のスクラムチームです。
【デプロイ頻度の移動平均推移】
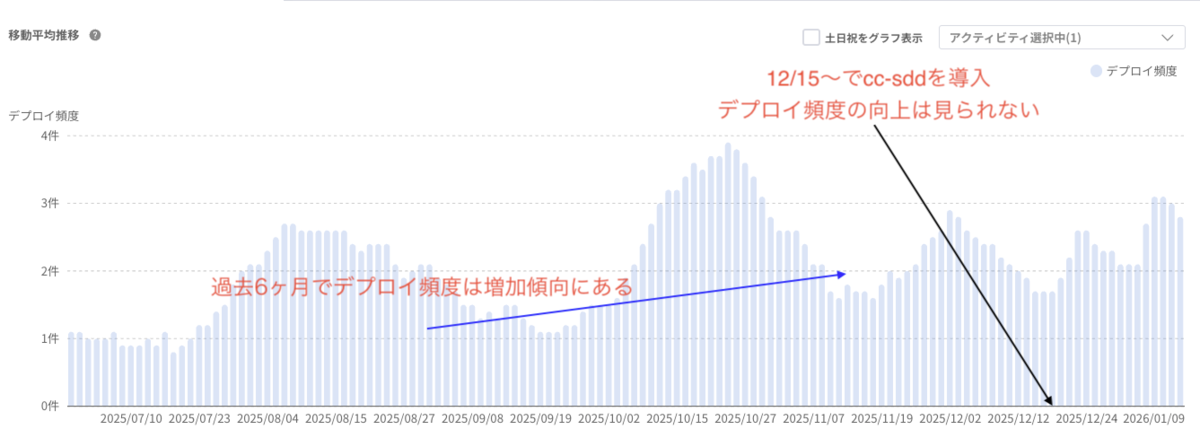
開発生産性を測るFour Keysの1つの指標であるデプロイ頻度に着目しました。
- cc-sdd導入前後でデプロイ頻度が向上していないことを観測
- AIを本格導入してきた過去6ヶ月で見るとデプロイ頻度は増加傾向
先ほどのネガティブな評価の「実装スピードとデプロイ頻度は、以前と同等か、微増している感覚」とも一致しています。
ここで、他の視点も入れてみます。
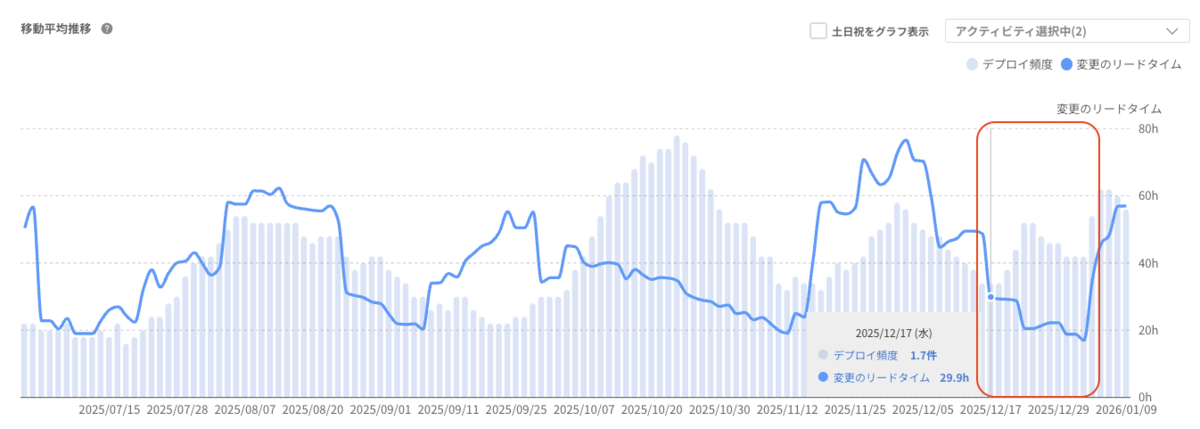
【デプロイ頻度と変更リードタイムの移動平均推移】
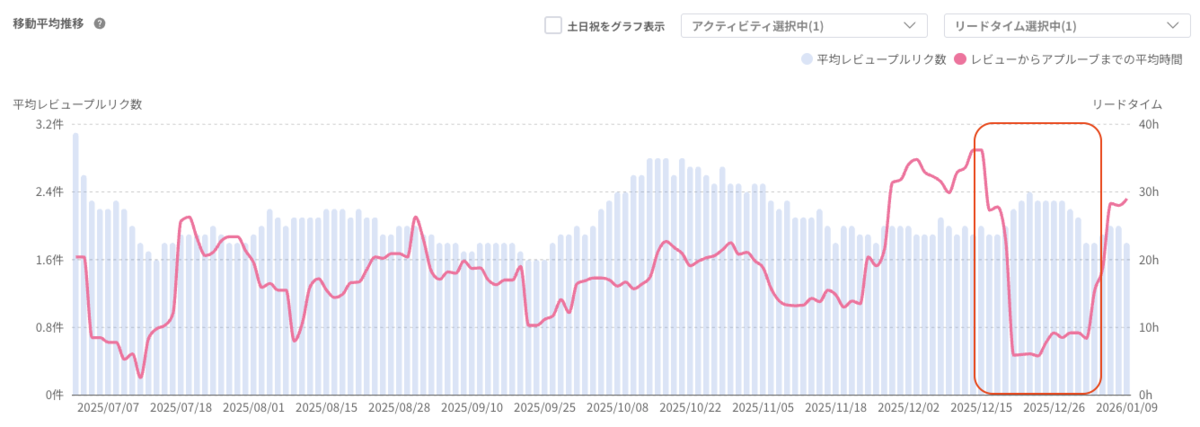
【平均レビュープルリク数とレビューからアプルーブまでの平均時間の移動平均推移】
【マージ済みプルリク数のアクティビティの推移】
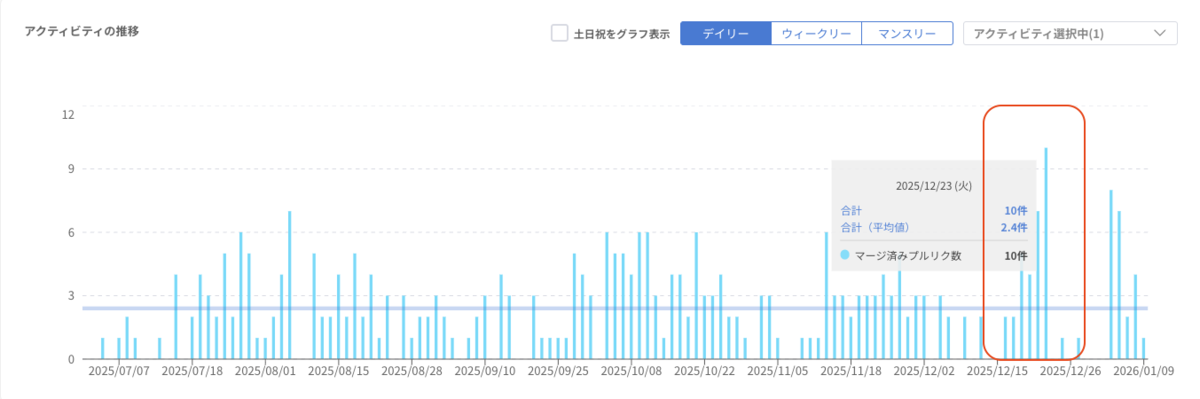
これらの結果から、cc-sddによる開発について3つの事実が分かりました。
- 変更リードタイムは以前の開発繁忙期の時と同程度の推移
- ※sddに関連するドキュメント更新のアクティビティは計測対象外です
- レビュー時間は以前よりも下がっている
- 瞬間風速的にはPR作成数が過去半年で最多を記録した
cc-sddによって、設計からレビューの効率化には成功しているが、デプロイまでの流れを阻害しているボトルネックが別に存在すると読み取れます。 これまでの経緯を含めて考察すると、それはリファインメントによる要件の供給速度だということがわかります。
今後の取り組み
ここまでの取り組みでは事実としてデプロイ頻度が上がりませんでした。 ネガティブな評価であがった課題を “のびしろ” と捉え、インパクトの大きい課題をコツコツ解消していく予定です。
直近では、AI-DLCのアプローチとスクラム開発と組み合わせ、リファインメントを改善する方針で以下の取り組みを進めています。
- AIを要求・デザインフェーズにも適用し、仕様策定のボトルネックを解消する
- 仮説の壁打ち
- プロトタイプ作成を回す
- AIがアクセス可能なSSoTの範囲拡充(ビジネスコンテキスト、ユーザーリサーチ等)
- 価値提供のフィードバックループを短縮し、次の要求定義に繋げる
まとめ
cc-sddの導入で仕様の認識齟齬が早期に解消され、意図した仕様どおりの実装に到達しやすくなりました。 しかし世間で語られるようなAIによる劇的な生産性向上には至っていません。 仕様策定フェーズのボトルネックやレビュー負荷など、AIを適用できる余地は多く残されています。 私たちのチームでは、思考をAI Drivenに変化させ、要求定義から価値提供までの全体フローを、改めてAI前提で組み直す必要があることが見えてきました。
この記事を書いている時点でも新たな取り組みで急速に進化していることを実感しています。 私自身も置いていかれないように、チームに貢献できるように成果を出し続けようと思います。 引き続きこの領域に挑戦していきます。
タイミーには、こうした挑戦と学び、そして発信を歓迎する文化があります。 ともに挑戦し成長していきたい方、興味があればぜひ1度お話ししましょう!
