※この記事は、2025 Speee Advent Calendar 12日目の記事です。 昨日の記事はこちら
こんにちは、Speee リフォームDX事業本部 プロダクトマネージャーの嶋です。
以前書いた記事、組織全体の開発スループットを劇的に向上させた「AIプランナー」とは? でも触れたように、私たちは現在、AIを前提にバリューチェーンを再創造する「AX(AI Transformation)」に取り組んでいます。
その最終的な到達点の一つとして掲げているのが「接客の完全AI化」です。
今回はその第一歩として、外壁塗装の会社探しサイト「ヌリカエ」における 「電話営業データの、リアルタイムかつ完全自動での構造化」に挑んだ話をします。
目指す水準:「人間による修正が不要」となる完全自動化
現在、私たちのカスタマーサクセス(CS)は、通話を行いながら専用ツールで議事録を作成し、施工業者への送客データを作成しています。
今回、私たちが目指したのは、単なる「入力支援」や「下書き作成」ではありません。
「通話が終わった瞬間に議事録が完成しており、人間が一切修正することなく、そのまま施工業者に送信できる水準」
これが、私たちの定義する「自動化」です。
この水準に達しなければ、結局CSが内容を目視確認・修正する工数が残り、本質的な生産性向上(=接客への集中)は実現できないからです。
「ヌリカエ」における議事録作成の特性
- 明確なインプット・アウトプット: 通話音声 → 構造化された議事録
- 人間の作業負荷が高い: CS担当者が通話しながら手動でメモを取る必要がある
- 後続プロセスへの影響が大きい: 施工業者が見積もりを作る上で不可欠な情報
この業務をAI化できれば、CSチームの負担軽減と業者への情報伝達精度の向上が同時に実現できると考えました。
なぜ難しいのか? 立ちはだかる「暗黙知」の壁
一見すると「通話音声を文字起こしして、要約すればいい」と思われがちですが、この「完全自動化」には「暗黙知」という高い壁が存在します。
「ヌリカエ」のCS担当者は、ユーザーの言葉をそのまま記録しているわけではありません。
これまでの経験や専門知識をベースに、発話の裏にある意図を「解釈」し、施工業者が知りたいデータ形式(築年数、劣化状況、緊急度など)に「構造化」して翻訳しています。
- 会話:「今の家はもう20年くらい住んでて、屋根の色がちょっと変わってきてるんだよね〜」
- CS担当者の脳内変換(暗黙知):
- 築年数確定:20年
- 劣化状況判定:色褪せ(チョーキング現象の可能性あり)
- 工事種別判定:屋根塗装(張り替えではなく塗装で対応可能と判断)
- 構造化データ:
article_age: 20deterioration_roof: "fading"construction_type: "roof_painting"
この「発話 → 解釈(暗黙知) → 構造化」というプロセスを、人間と同等、あるいはそれ以上の精度で再現できなければ、「修正なし」の自動化は不可能です。この暗黙知の塊を、いかにしてAIに移植するか。これが本プロジェクトの核心でした。
挑戦:CS担当者の「脳内」をプロンプトに実装する
私たちは検証環境としてDifyとGoogleスプレッドシートを連携させた基盤を構築し、実際の通話データを用いた精度の検証を開始しました。
初期のAIは「解釈」ができず、表面的な言葉を拾うことしかできませんでした。そこから、CSの暗黙知を言語化し、プロンプトに落とし込む取り組みを行いました。
1. 現場の暗黙知を言語化する — CS担当者とのフィードバックループ
AIとの対話だけでは、どうしても埋まらないギャップがありました。AIが理解できない「文脈」や「行間」の正体を知っているのは、やはり現場の人間です。
そこで私たちは、実際のCS担当者を巻き込んだフィードバックループを構築しました。
- プロの視点でデータをレビュー: LLMが出力したデータを見てもらい、「なぜこの数値が間違っているのか?」「人間ならどう解釈してこの数字を導き出すのか?」という思考プロセスをヒアリング。AIにはないドメイン知識や判断基準を教えてもらいました。
- 対象者を絞ったスモールスタート: 完成度がある程度高まった段階で、一部のメンバーに対象を絞って実際にAI議事録作成ツールを使用してもらいました。現場からの「ここが使いにくい」「この表現だと業者に伝わらない」といった生の声が、ラストワンマイルの精度向上に不可欠でした。
2. 「推測」を許さない — null出力の厳格化
施工業者が見積もりを作る上で、誤った情報は致命的です。
しかし、LLMは文脈からそれらしい値を「推測」して埋めてしまう特性があります。「わからない」ことを「わからない(null)」と定義することは、実は正解を出すことよりも難しいのです。
【実際に起きた問題】
エージェント:「築年数は何年くらいですか?」 ユーザー:「ちょっとわからないですね...」 AIの出力:
article_age: 15(一般的な相場から勝手に推測)
これでは「修正なし」で送ることはできません。
私たちは「情報がない = null」とする条件を、ヒアリングした判断基準に基づいて徹底的に言語化しました。
【暗黙知の言語化例:築年数】
- ユーザーが「わからない」と回答した場合は絶対null
- エージェントが相場説明のために出した数値(例:「15年くらいで塗装が必要です」)は抽出しない
- 「だいたい○○くらい」という推測発言は採用する
このように「人間ならどう判断するか」を一つずつ条件分岐としてプロンプトに記述していきました。
3. AIは「延べ床面積」を理解できない — Chain of Thoughtの実装
特に難易度が高かったのが「延べ床面積」の抽出です。
- 会話の中には「建坪」と「延べ床」が混在し、単位も「㎡」と「坪」が入り乱れる。
- そもそも会話に出てきた数字が、面積の話なのか、金額の話なのか、文脈の判断が難しい。
初期のプロンプトでは、文脈を無視して適当な数値を拾ってきたり、あろうことか「プロンプト内の例示に使った数値」をそのまま出力するハルシネーション(幻覚)まで発生しました。
そこで、AIにいきなり答えを出させるのではなく、思考プロセスを強制する Chain of Thought(思考の連鎖) と、具体的なOK/NGパターンを学習させる Few-shotプロンプティング を実装しました。
# 延べ床面積抽出プロンプト(抜粋) ## 抽出の絶対条件 1. 「坪」「平米」などの単位が会話に存在する 2. 顧客が「自分の物件の面積」として述べている 3. CS担当者が確認し、同意が取れている ## Few-shot(抽出してはいけないケースの教育) ❌ CS担当者が相場説明で使った数値 例: 「15坪から30坪のお値段になってまして」 → これは相場の説明であり、顧客の物件の面積ではない → null ❌ 金額を誤認 例: 「50万」「120万円」 → 金額であり面積ではない → null ❌ 顧客が「わからない」と言っている 例: 「何坪何平米行かないかちょっと分からない」 → 面積不明 → null ## Chain of Thought(判定フローの強制) Step 1: 会話に「坪」「平米」「m²」という単語があるか? ↓ なし → null Step 2: 顧客が自分の物件の面積として数値を述べているか? ↓ いいえ(相場説明のみ) → null Step 3: 顧客が「わからない」と言っているか? ↓ はい → null Step 4: CS担当者の確認に顧客が同意しているか? ↓ はい → 数値を抽出 ↓ いいえ → null
このように、「いきなり抽出するな、まず手順を踏め」と指示し、さらに「これはダメな例だ」と具体的に教え込むことで、ようやくAIは「延べ床面積」と「それ以外の数字」を正しく区別できるようになりました。
4. 「リアルタイム」への挑戦 — 差分更新アーキテクチャ
「通話終了と同時に完成」を実現するには、通話終了後にバッチ処理をするのではなく、通話中にリアルタイムでデータを生成し続ける必要があります。 そこで、音声データを1分ごとのチャンク(塊)に分割し、順次処理する方式を採用しました。しかし、ここで「情報の分断」という新たな問題が発生しました。
【問題】
- 1分目:ユーザー「築14年です」→ AI「了解(
age:14)」 - 2分目:CS担当者「20年くらいで…」(塗料の耐久年数20年の話)→ AI「築年数の話かな?(
age:20で上書き)」
分割して処理することで文脈が切れ、過去の確定情報が、新しい(無関係な)数値で上書きされてしまうのです。
【解決策:差分要約アプローチ】
これを解決するために、「前回の状態(State)」を保持し、新しい会話はその差分として処理するアーキテクチャを導入しました。
さらに、前回のデータで最後に会話されていた内容の文脈予測と回答ステータスを出力することで、次のデータの冒頭で「20年」という発話があった際に、何が20年なのか判別できるようにしています。
- Input: 「前回の議事録JSON」 + 「今回の会話テキスト」
- Process: 今回の会話で新しく言及された項目だけを更新する
- Output: 「最新の議事録JSON」+「前回の最後の会話の文脈予測」+「回答ステータス」
このようにして、AIはあたかも人間がメモ帳に追記していくように、一貫性を保ちながらリアルタイムにデータを構造化できるようになりました。
5. AIによる品質担保の自動化
「修正なし」を目指す以上、人間の目視チェックに頼るPDCAでは限界があります。
そこで、「AIの出力を、別のAIが評価する」仕組みを導入しました。評価用プロンプトにはベテランCSのレビュー観点を注入し、「なぜこの数値になったのか?」「文脈を読み違えていないか?」をAI同士で議論させ、プロンプトを磨き上げました。
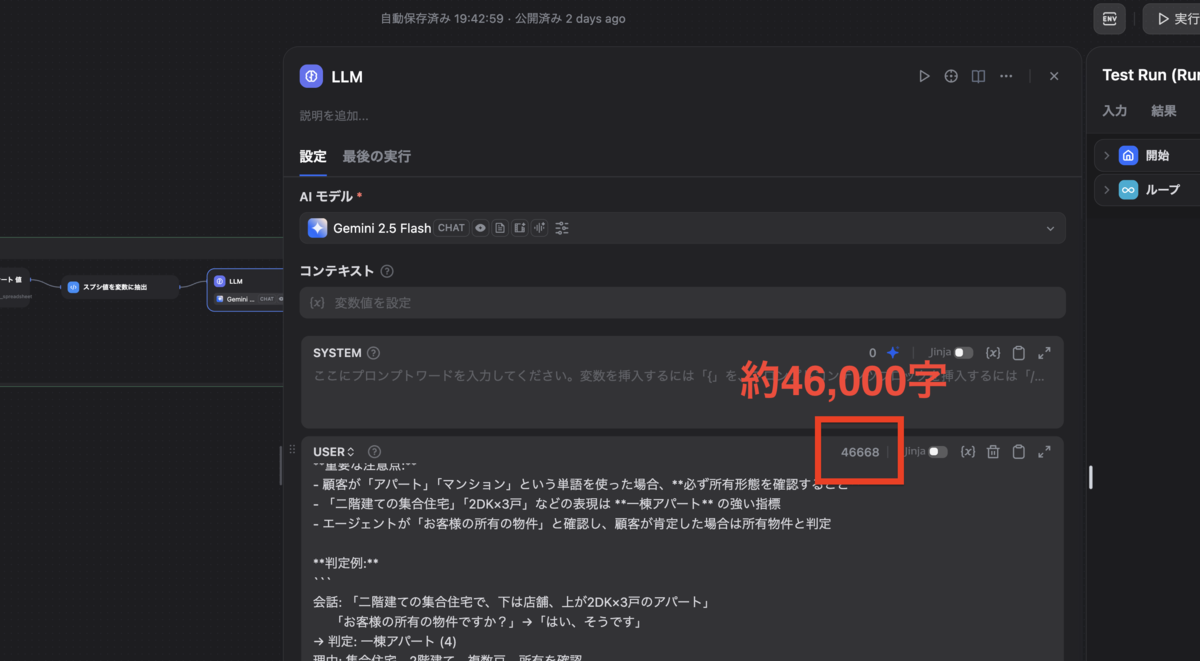
結果:45,000文字のプロンプトが示す「解像度」
上にあげた例以外にも、工事種別の判定・電話可能な時間帯・屋根の材質や劣化状況など、議事録作成に必要な項目はまだまだあります。
それらを一つ一つプロンプトに落とし込んでいくために、CS業務の暗黙知を言語化し、例外処理を網羅し、リアルタイム処理の整合性を担保し続けた結果、最終的なプロンプトは45,000文字(バージョン42)に達しました。
一見すると冗長な文字数はプロンプトチューニングのアンチパターンに陥っているように見えます。しかし、これは単なる命令文の羅列ではなく、「ヌリカエ」というサービスの接客品質そのものを記述したプロンプトです。
こうしたチューニングの結果、私たちはついに「人間が修正することなく、そのまま施工業者へ送信できる水準」のデータ構造化を実現できました。
まとめ
42回の検証と45,000文字のプロンプトを経て、ようやく狙った精度・レスポンスで得たい結果が得られるようになり、この取り組みは一区切りとすることにしました。
今回は議事録作成という局所的な業務でしたので、Difyのシンプルなワークフローと1つの巨大なプロンプトを軸に突破しましたが、この後のプロジェクトではより複雑な判断や業務フローを進める必要があるため、複数のLLMを連携させたエージェント設計が必要になると考えています。
「データがリアルタイムかつ高精度に構造化される」ということは、AIが「今、顧客が何を求めているか」を瞬時に理解できるということです。 次はこの構造化されたデータを元に、AI自身が最適な提案を行い、意思決定をサポートする——そんな「接客の完全AI化」の実現に向けて、私たちはさらに開発を加速させていきます。
おまけ
プロンプトの一部とDifyの画面

Speeeでは、こうした高い目標に向かって、泥臭く、しかし本質的な挑戦を楽しめる仲間を募集しています!
私ならもっと上手くやれるよ!という方、まずは話を聞いてみたいという方も大歓迎です🙏
新卒の方はこちらより本選考に申し込みが可能です。 キャリア採用の方はこちらのFormよりカジュアル面談も気軽にお申し込みいただけます。
Speeeでは様々なポジションで募集中なので「どんなポジションがあるの?」と気になってくれた方は、こちらチェックしてみてください。
