こんにちは、SmartHR プロダクトエンジニアのB6です。
「基本機能」と呼ばれるSmartHR最大のRailsアプリケーションでは、アプリケーションサーバにPumaを使用しています。
RailsでPumaデフォルトスレッド数が変更されたのをきっかけに、私たちもスレッド数の設定を見直してみたいと思うようになりました。
本記事では、調整の際に行ったこととその結果について共有いたします。
背景
2024年、RailsでPumaのデフォルトスレッド数を減らすための議論が展開されました(Issue #50450)。議論の結果、I/O比率を25~50%とする一般的なRailsアプリケーションでは、スレッド数3が適切ではないかという結論に至りました。
要点をざっくりまとめると以下のようになります。
- CRubyでは、GVLが存在するため、同時に1つのスレッドしかRubyコードを実行できない
- Pumaのスレッド数を増やしすぎると、Rubyコード実行のためにスレッド間でGVLを取り合う
- 一方で、I/O操作中はGVLが解放されるため、複数のスレッドが並列実行できる
- I/O比率が高いアプリケーションほど、スレッド数を増やす効果が大きい
- そのため、最適なスレッド数はアプリケーションのI/O比率に基づいて決めることができる
そこで、私たちもアプリケーションのI/O比率を計測し、それに基づいてスレッド数を調整することにしました。
変更前の状況
基本機能のRailsアプリケーションは、もともと12スレッドで運用していました。
そして数年前、メモリ使用量の削減のため、6スレッドに変更されました。
ただ、Railsでの議論のようにI/O比率やGVL競合の観点でスレッド数が検討されたことは一度もありませんでした。
I/O比率の計測
I/O比率の計測には、gvl_metrics_middlewareというGemを使用しました。Ruby 3.2で追加されたGVL instrumentation APIを活用して、以下を計測できます。
- running:GVLを獲得してCPU処理を行っている時間
- io_wait:I/O処理に費やした時間
- gvl_wait:GVLが獲得できず待機している時間
ここから、I/O比率をio_wait / (running + io_wait + gvl_wait) で計算することができます。
GVLの計測を行う場合、アプリケーションのレイテンシにオーバーヘッドが加わるため注意が必要です。実際に検証環境で試したところ、1~2%のオーバーヘッドが見られました。 そこで、本番環境での計測時は全体の1%のトラフィックでのみ計測を有効にするようにして、影響を最小限にしました。
I/O比率の計測結果
計測を行った結果、以下が得られました。
| パーセンタイル | I/O比率 |
|---|---|
| P50 | 52% |
| P90 | 66% |
| P99 | 79% |
P50で見ると、リクエスト処理時間の約半分をI/O処理に費やしていることがわかりました。
パーセンタイルによってI/O比率に大きな差がありましたが、スレッド数の決定にはP50の値を用いることにしました。
ただし、この判断にはトレードオフもあります。高I/O比率のリクエストが集中した場合、より多くのスレッドを用意すればスループットを向上できる余地があります。この課題については、後ほど検討します。
スレッド数の算出
I/O比率がわかったので、次は最適なスレッド数を決める必要があります。 スレッド数ごとの理論的な性能向上を計算するため、まずはアムダールの法則を用います。 I/O処理を行っている時間を並列化可能な部分とすることで、スレッド数を追加することでどれだけ性能が向上するかを計算できます。
結果は以下のようになります。
| スレッド数 | 1スレッドからの向上率 | 追加スレッドあたりの効果 |
|---|---|---|
| 1 | 1.00x | - |
| 2 | 1.35x | +35% |
| 3 | 1.53x | +13% |
| 4 | 1.64x | +7% |
| 5 | 1.71x | +4.5% |
| 6 | 1.76x | +3.1% |
スレッド数を増やすほどスループットは向上しますが、追加効果は逓減していきます。スレッド数4では1.64倍のスループットが得られますが、5に増やしても追加効果は5%を下回ります。
一方、スレッド数を増やすとGVL競合によりテールレイテンシが悪化するリスクも高まります。このことを実際に確認しましょう。
以下のグラフは、計測したI/O比率を用いて負荷量を変えながらレイテンシを計測した結果です。グラフのX軸は1秒あたりのリクエスト数(req/s)、Y軸はレイテンシ(ms)を表しています。
計測にはthreadbenchを用いました。スレッド数やI/O比率などを変えて擬似的なアプリにリクエストを送り、ベンチマークを取ることができます。
今回はI/O比率を52%(P50相当)と66%(P90相当で、ほぼ2/3の時間をI/Oに費やしている)の2パターンに設定し、スレッド数3, 4, 5のそれぞれについて計測を行いました。



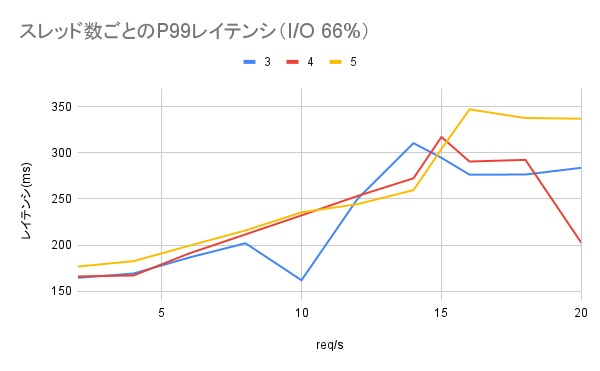
グラフから、以下のようなことがわかりました。
- 低負荷時では、スレッド数によるレイテンシの差はほとんど見られない
- 中負荷時(10 req/s~)から、スレッド数を増やすほどレイテンシが劣化し始める
- 高負荷時では、スレッド数が多いほどレイテンシの劣化が顕著になる
- I/O比率が高くなると、高負荷でもスレッドを増やしたときのレイテンシ劣化が目立たなくなる
このベンチマーク結果と実際に計測したI/O比率を組み合わせることで、スループットと高負荷時のレイテンシ劣化のバランスを考慮して最適なスレッド数を割り出すことができそうです。
5スレッドではスループットの追加効果が5%を下回ること、そして高負荷時のレイテンシが顕著に悪化することから、まずはスレッド数を4に変更する決定をしました。
Railsのデフォルトである3も検討しましたが、影響範囲を小さく保ちながら段階的に効果を確認したいと考え、まずは6から4への変更で様子を見ることにしました。
本番環境での段階的適用
では、実際にアプリケーションのスレッド数を変更してみます。
影響を最小限にするため、当初は検証環境でのスレッド数変更を検討しました。しかし、以下の理由から本番環境で検証する方針に変更しました。
- データ量が本番と大きく異なり、I/O比率が正確に再現できない
- トラフィックパターンが再現できない
- どのエンドポイントでシナリオを組むかによって結果が大きく変わる
とはいえいきなり全トラフィックを4スレッドに切り替えるのはリスクが高いため、トラフィックを以下のように段階的に適用していきました。
- 1回目:4スレッド 30% : 6スレッド 70%
- 2回目:4スレッド 70% : 6スレッド 30%
- 3回目:4スレッド 100%
Cloud Runでは複数のリビジョン間でのトラフィックの分割が簡単に行えます。
トラフィックを割り振りながら、各段階で主要メトリクスを監視しつつ、問題が発生したらすぐにロールバックできる体制を整えました。
下記は当時のリビジョンごとのリクエスト数の様子です。緑色の線が6スレッドで動いている変更前のリビジョンで、青色の線が4スレッドで動かしているリビジョンです。段階的に4スレッドのリビジョンへ移行しているのがわかります。

結果と考察
以上のプロセスを経て、Pumaのスレッド数を6から4に変更しました。ここからは、変更後の結果を見ていきます。
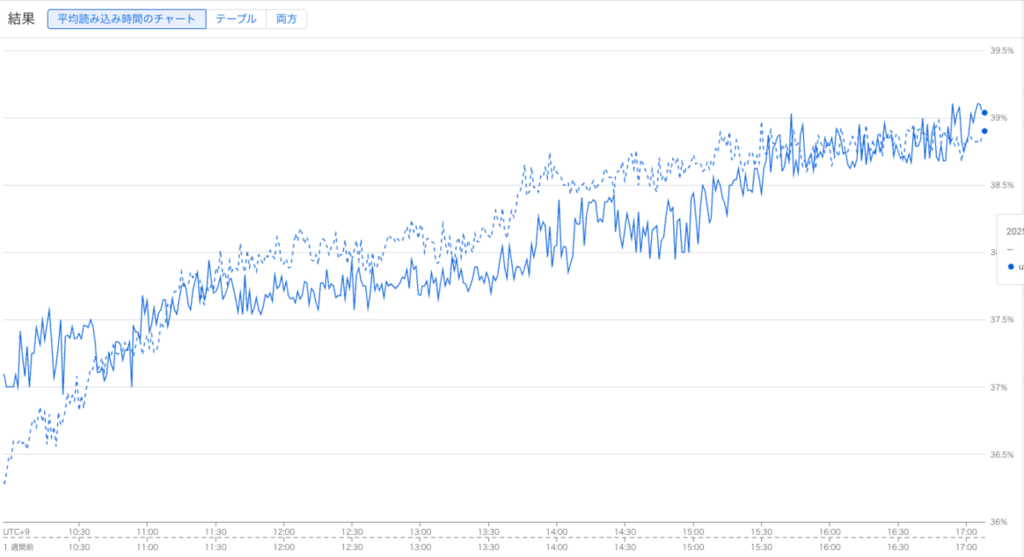
メモリ使用量の削減
スレッド数の削減により、メモリ使用量が減少しました。 以下は、スレッド数変更前/変更後でメモリ使用量を比較したグラフです。実線がスレッド数変更後のデータ、点線がその1週間前のデータを表しています。
GVL待機時間のわずかな減少
スレッド数変更後、再びgvl_metrics_middlewareを入れてGVLに関する時間を計測しました。
以下がGVL獲得のため待機している時間(gvl_wait)を計測したグラフです。実線がスレッド数変更後のデータ、点線がその1週間前のデータを表しています。
P50などではほとんど変化が見られませんでしたが、P90/P99でGVL待ち時間がわずかに減少しているように見えます。

目に見えるレイテンシ改善はなかった
レイテンシに関しては、スレッド数変更後も目立った変化は見られませんでした。
threadbenchでのベンチマークからも示されたように、低負荷時では、スレッド数によるレイテンシの差はほとんど見られません。
効果検証中、アプリケーションのサーバーの利用率(稼働率)は50~60%ほどを推移していました。この低負荷環境では、スレッド数の違いが顕在化しにくかったと考えられます。
RailsのIssueでも、同様の見解が示されています。
P50基準の課題と今後の展望
前述の通り、P50基準でスレッド数を決定する判断にはスループットとのトレードオフがあります。 SmartHRのアプリケーションには、高I/O比率になりやすい要因がいくつかあります。例えば、
- DBクエリなど、最適化の余地が残っている部分が多く存在する
- 外部サーバーにアクセスして結果をそのまま返すだけのエンドポイントが存在する
などです。
こうした高I/O比率のリクエストが集中した場合、スレッド数を4以上にすればより高いスループットを出せる可能性があります。 このトレードオフの中で、今回我々はレイテンシの最小化を優先しました。
スループットはPumaのプロセス数やサーバのインスタンス数を増やすことで、比較的容易に対応できます。対してレイテンシは、個々のリクエストの応答速度であり、スケールアウトを行っても必ずしも改善されません。 そのため、スレッド数決定という文脈ではまずユーザー体験に直結するレイテンシを優先し、スループット不足にはスケールアウトで対応する方針としました。
余談ですが、この課題に対しては、より高度な最適化も検討の余地があるかもしれません。 例えば、極端にI/O比率が高いエンドポイントが特定できているのであれば、エンドポイントによって異なるスレッド数の専用インスタンスを用意することも考えられます。
また、Pumaで現在議論されているpuma.mark_as_io_boundという機能にも着目をしています(PR #3816)。
I/O比率が高いリクエストをマークすることで、そのリクエストを処理するスレッドは「I/Oバウンドを処理しているスレッド」として扱われ、スレッドプール内のスレッド数上限とは別に扱えるようになります。
これにより、I/O比率の異なるエンドポイントが混在する環境で、用途に応じて柔軟にスレッド数を用意することができる可能性があります(※2026/02/02現在、本機能はまだマージされていません)。
おわりに
今回、I/O比率を計測し、その結果に基づいてPumaのスレッド数を6から4に変更しました。
結果として、メモリ使用量の減少とGVL競合の緩和を確認できました。
またレイテンシの目立った変化は見られませんでしたが、ベンチマークで示したように、スレッド数によるレイテンシへの影響はサーバー利用率が高い時に顕著になります。現在は低負荷環境のため差が出にくいものの、今回の変更により将来的な高負荷時のテールレイテンシ悪化リスクを軽減できたと考えています。
この取り組みは、RailsのIssueでの長い議論やThe Mythical IO-Bound Rails Appの記事をきっかけに始めました。
記事では、YJITの性能向上を例に、「もしRailsアプリケーションが本当にI/Oバウンドであれば、CPU処理を最適化するYJITがここまで効果を発揮するはずがない」という指摘がなされています。
SmartHRでも、YJITを有効化したことでレイテンシが大きく改善した経験があり、この指摘は実体験とも重なります。
こうした異なる事象を結びつけながら仮説を立て、実測とデータに基づいて判断していくという視点は、今後の改善を考える上でも重要な示唆を与えるものだと感じました。
なお、本取り組みを進めるにあたり、技術顧問であるwillnetさんから多くのアドバイスをいただきました。この場を借りて感謝申し上げます。
We Are Hiring!
SmartHRでは、一緒にSmartHRを作りあげていく仲間を募集中です! 少しでも興味を持っていただけたら、カジュアル面談でざっくばらんにお話ししましょう!
