1. はじめに
newmoではメインのデータベースとしてGoogle CloudのAlloyDBを利用しています。サービスの成長に伴い、GraphQLやgRPCを通じたリクエストが増加し、最近、本番環境のデプロイ時にCPU負荷が90%を超えるという問題に直面しました。

この記事では、AlloyDBのパフォーマンス最適化に取り組んだ記録をまとめています。「発見 → 改善 → 計測」のサイクルを繰り返しながら、Slow Queryの改善、N+1問題の解消、そしてRead Pool Instanceの導入まで、段階的に行った改善とその効果について詳しく解説します。
かなり詳細な内容になっていますが、同様の問題に悩んでいる方の参考になれば幸いです。
2. システム構成と発生した問題
システム構成
newmoのバックエンドは、Goで実装されたModular Monolithアーキテクチャを採用しています。1つのプロセスとして動作しますが、内部的にはモジュールごとに分割されており、それぞれのモジュールが独立したデータベースを持っています。例えば、paymentモジュールはpaymentデータベース、rideモジュールはrideデータベースといった具合です。
クライアント向けにはGraphQL APIを提供しており、モジュール間の通信にはgRPCを使用しています。データベースにはGoogle Cloud の AlloyDB for PostgreSQLを採用しており、当初はPrimary Instanceのみで運用し、Read Pool Instanceは使用していませんでした。
アーキテクチャの詳細については、以下の記事で詳しく解説していますので、そちらをご参照ください。
発生した問題
サービスの成長に伴い、以下の問題が顕在化してきました。
GraphQL N+1問題の増加
サービス開始当初は、GraphQLの型同士の参照関係は少なく、1つのクエリが1つのresolverで完結するシンプルな構成でした。しかし機能追加に伴い、ある型から別の型を参照するフィールドが増加し、resolverによるN+1問題が徐々に蓄積されていきました。
gRPC N+1問題の発生
さらに、データの取得先として別モジュールからデータを取得するケースも増えてきました。これにより、モジュール間のgRPC通信でもN+1問題が発生するようになりました。
デプロイ時のCPU負荷急上昇
これらの問題が積み重なった結果、あるタイミングで本番サーバーのデプロイ時にCPU負荷が90%を超える事態が発生しました。これをきっかけに、本格的なパフォーマンス最適化に取り組むことになりました。
3. Slow Query の改善
最初にデータベースのSlow Queryの改善から取り組みました。N+1問題の解消も重要ですが、DBの負荷上昇が差し迫った課題だったため、まずは速やかにCPU使用率を下げられる方法としてSlow Queryの改善を選択しました。
「発見 → 改善 → 計測」のサイクルを回すにあたり、最初のステップである問題の発見方法について説明します。
問題の発見方法
Slow Queryの発見には、AlloyDBが提供するQuery Insightsを活用しました。Query Insightsでは、実行時間が長いクエリを一覧で確認でき、さらに各クエリの実行計画も確認できます。


Query Insightsの良い点は、指定した時間内でトータル実行時間が長いクエリ順にソートして確認できることです。つまり、CPU使用率の改善には、ソートされた上位から順番に解決していくのが最も効率的です。
各クエリの実行計画を確認し、「Highest latency」や「Highest cost」となっている箇所を分析していきます。その中でも特にわかりやすいのがSeq Scan(シーケンシャルスキャン)です。Seq Scanはテーブル全体を走査するため、レコード数が増えるほど実行コストが高くなり、インデックスの追加で改善できることが多いです。
クエリパターンの最適化
複数のキーを指定してレコードを取得する場合、当初は以下のようなクエリを使用していました。
SELECT * FROM table WHERE key = ANY($1)
しかし、レコード数が多い場合にこのパターンが遅くなることがわかり、パフォーマンスが良いとされるUNNEST JOINパターンに変更しました。
SELECT x.* FROM table x JOIN UNNEST($1) AS u(key) ON x.key = u.key
さらに調査を進めたところ、CTE + ANYパターンが最速という結果になりました。
WITH keys AS (SELECT UNNEST($1::uuid[]) AS key) SELECT * FROM table WHERE key = ANY(SELECT key FROM keys)
以下では、3つのパターンについて実際に実行計画を取得し、テーブルのレコード数による違いを比較した結果を紹介します。
検証環境
- AlloyDB (PostgreSQL 16互換)
- テーブルのレコード数: 3万件 / 100万件
- 取得件数: 1,000件(固定)
パターン1: ANY
SELECT * FROM table WHERE key = ANY($1);
テーブル3万件の場合:
Seq Scan on table (cost=2.50..1169.00 rows=1000 width=99) (actual time=0.064..2.931 rows=1000 loops=1) Filter: (key = ANY (...)) Rows Removed by Filter: 26518 Planning Time: 1.855 ms Execution Time: 3.000 ms
Seq Scan(シーケンシャルスキャン)が選択されています。テーブル全体を走査し、26,518件をフィルタで除外して1,000件を取得しています。テーブルサイズが小さいため、プランナーはインデックスを使うよりもSeq Scanの方が効率的と判断しています。
テーブル100万件の場合:
Bitmap Heap Scan on table (cost=4063.25..7167.83 rows=1000 width=97) (actual time=19.384..19.475 rows=1000 loops=1) Recheck Cond: (key = ANY (...)) Heap Blocks: exact=15 -> Bitmap Index Scan on table_pkey (cost=0.00..4060.50 rows=1000 width=0) (actual time=19.360..19.361 rows=1000 loops=1) Planning Time: 2.022 ms Execution Time: 19.694 ms
テーブルサイズが大きくなったため、Bitmap Index Scanに切り替わっています。しかし、ANYに渡された配列の要素数が多い場合、Bitmap Index Scanのコストが高くなり、実行時間が19msと大幅に増加しています。
パターン2: UNNEST JOIN
SELECT x.* FROM table x JOIN UNNEST($1) AS u(key) ON x.key = u.key;
テーブル3万件の場合:
Hash Join (cost=1372.75..1385.38 rows=1000 width=99) (actual time=5.901..6.210 rows=1000 loops=1)
Hash Cond: (u.key = x.key)
-> Function Scan on unnest u (cost=0.00..10.00 rows=1000 width=16) (actual time=0.063..0.093 rows=1000 loops=1)
-> Hash (cost=1029.00..1029.00 rows=27500 width=99) (actual time=5.714..5.715 rows=27518 loops=1)
Buckets: 32768 Batches: 1 Memory Usage: 3431kB
-> Seq Scan on table x (cost=0.00..1029.00 rows=27500 width=99) (actual time=0.011..2.038 rows=27518 loops=1)
Planning Time: 1.595 ms
Execution Time: 6.348 ms
Hash Joinが選択されています。UNNESTで展開した1,000件とテーブル全体をハッシュ結合しています。テーブル全体をSeq Scanしてハッシュテーブルを構築するため、3万件でも6msかかっています。
テーブル100万件の場合:
Nested Loop (cost=0.43..7940.50 rows=1000 width=97) (actual time=0.143..5.121 rows=1000 loops=1)
-> Function Scan on unnest u (cost=0.00..10.00 rows=1000 width=16) (actual time=0.108..0.164 rows=1000 loops=1)
-> Index Scan using table_pkey on table x (cost=0.42..7.93 rows=1 width=97) (actual time=0.005..0.005 rows=1 loops=1000)
Index Cond: (key = u.key)
Planning Time: 2.173 ms
Execution Time: 5.276 ms
テーブルサイズが大きくなると、Nested Loop + Index Scanに切り替わります。UNNESTで展開した各行に対してIndex Scanを行うため、効率的に処理されています。
パターン3: CTE + ANY
WITH keys AS (SELECT UNNEST($1::uuid[]) AS key) SELECT * FROM table WHERE key = ANY(SELECT key FROM keys);
テーブル3万件の場合:
Bitmap Heap Scan on table (cost=42.96..79.73 rows=10 width=99) (actual time=2.157..2.317 rows=1000 loops=1)
Recheck Cond: (key = ANY ($0))
Heap Blocks: exact=15
InitPlan 1 (returns $0)
-> Result (cost=0.00..0.01 rows=1 width=32) (actual time=0.004..0.004 rows=1 loops=1)
-> Bitmap Index Scan on table_pkey (cost=0.00..42.95 rows=10 width=0) (actual time=2.131..2.131 rows=1000 loops=1)
Index Cond: (key = ANY ($0))
Planning Time: 1.629 ms
Execution Time: 2.449 ms
CTEによって配列がInitPlanで事前に評価され、その結果を使ってBitmap Index Scanが実行されています。プランナーがインデックスを効率的に使用できるようになっています。
テーブル100万件の場合:
Index Scan using table_pkey on table (cost=0.43..84.43 rows=10 width=97) (actual time=0.194..3.413 rows=1000 loops=1)
Index Cond: (key = ANY ($0))
InitPlan 1 (returns $0)
-> Result (cost=0.00..0.01 rows=1 width=32) (actual time=0.005..0.005 rows=1 loops=1)
Planning Time: 1.172 ms
Execution Time: 3.514 ms
100万件でもIndex Scanが選択されており、3.5msと高速に処理されています。CTEによって配列が一時的な結果セットとして扱われることで、プランナーが最適な実行計画を選択できています。
比較結果
| パターン | 3万件 | 100万件 |
|---|---|---|
| ANY | 3.0 ms | 19.7 ms |
| UNNEST JOIN | 6.3 ms | 5.3 ms |
| CTE + ANY | 2.4 ms | 3.5 ms |
この結果から、CTE + ANYパターンが最も高速であることがわかりました。特にテーブルのレコード数が多い場合に差が顕著です。
ANYパターンはテーブルサイズが小さいときはSeq Scanでも問題ありませんが、100万件規模になるとBitmap Index Scanに切り替わっても19msと遅くなります。UNNEST JOINは100万件で高速ですが、3万件ではHash Joinが選択されSeq Scanが発生するため遅くなっています。
一方、CTE + ANYパターンはCTEによって配列が事前に評価されることで、プランナーがテーブルサイズに関係なく効率的なIndex Scanを選択できるようになります。この結果を踏まえ、該当するクエリをCTE + ANYパターンに書き換えました。
Covering Index の適用
クエリパターンの最適化に続いて、Query Insightsで上位のクエリを確認していくと、すでにインデックスが適用済みの単純なクエリが依然として上位に残っていることがわかりました。
SELECT x, y, z FROM table WHERE key = $1
このようなシンプルなクエリでも、取得するカラムがインデックスに含まれていない場合、インデックスで行を特定した後にテーブル(ヒープ)へアクセスする必要があります。この追加のI/Oを削減するため、Covering Index(カバリングインデックス)を適用しました。
Covering Indexとは、クエリで必要なカラムがすべてインデックスに含まれている状態のことです。Covering Indexが適用されると、インデックスだけでクエリを完結できるため、テーブルへのアクセスが不要になります。
実行計画では、通常のインデックス利用が「Index Scan」と表示されるのに対し、Covering Indexが適用されると「Index Only Scan」と表示されます。
適用例
例えば、以下のようなクエリがあったとします。
SELECT id, status FROM orders WHERE user_id = $1;
user_id にインデックスがある場合、Index Scanでuser_idの条件に合う行を特定し、その後テーブルから id と status を取得します。
CREATE INDEX ON orders(user_id);
Index Scan using orders_user_id_idx on orders Index Cond: (user_id = $1)
ここで、インデックスに id と status を含めることで、テーブルへのアクセスを省略できます。
CREATE INDEX ON orders(user_id) INCLUDE (id, status);
Index Only Scan using orders_user_id_idx on orders Index Cond: (user_id = $1)
Index Only Scanになることで、ディスクI/Oが削減され、クエリのレイテンシが改善されます。
今回の適用方針
実際にCovering Indexを適用する際には、単純化のためINCLUDEに全カラムを追加しました。
CREATE INDEX ON table(key) INCLUDE (col1, col2, col3, ...);
通常、全カラムを含めるとインデックスサイズが大きくなり更新コストも増加しますが、今回の対象テーブルは以下の条件を満たしていたため、この方針を採用しました。
- 一度作成されたらほとんど更新されない
- 各カラムのデータサイズが小さい
これにより、SELECTで取得するカラムを気にせず、すべてのクエリでIndex Only Scanの恩恵を受けられるようになりました。
4. N+1 問題の改善
Slow Queryの改善によってCPU使用率は下がりましたが、根本的な問題であるN+1問題の解消にも取り組みました。
問題の発見方法
Modular Monolithアーキテクチャでは、GraphQLのresolverやモジュール間のgRPC通信が複数のサービスに分散するため、N+1問題の発見が難しくなります。単一のデータベースクエリを見ているだけでは、全体としてN+1が発生しているかどうかがわかりません。
この問題の発見には、Datadog Trace Queriesを活用しました。Trace Queriesを使うと、分散トレースに対してクエリを実行し、特定のパターンに一致するトレースを検索できます。

今回は特に、トランザクションの作成回数に着目して問題を発見しました。pgxpoolライブラリを使用しており、トランザクション利用時には自動的にspanが作成されます。そのため、1回のリクエスト内でトランザクションが大量に発生している場合は、N+1が発生していると判断できます。
例えば、同一トレース内で同じトランザクションspanが10回以上出現しているケースを検索することで、N+1が発生している箇所を特定できます。トレースの詳細を見ると、どのresolverから呼び出されているか、どのようなパターンで繰り返し呼び出されているかが可視化されます。

DataLoader の導入
N+1問題の解消には、DataLoaderパターンを導入しました。DataLoaderは、同一リクエスト内で発生する複数の個別取得を集約し、一括取得に変換する仕組みです。
実装にはgraph-gophers/dataloaderをベースとして使用し、内部で使いやすくするためにラップして提供しています。
導入前
Request
└── Resolver A
├── Get(id=1) → DB Query
├── Get(id=2) → DB Query
├── Get(id=3) → DB Query
└── Get(id=4) → DB Query
導入後
Request
└── Resolver A
├── Load(id=1) ─┐
├── Load(id=2) │
├── Load(id=3) ├─→ BatchGet([1,2,3,4]) → DB Query (1回)
└── Load(id=4) ─┘
DataLoaderは、ユニークキーやプライマリキーでのアクセスを配列で一括取得するように変換します。これにより、N回のクエリが1回のクエリに集約されます。
gRPC の BatchGet 化
GraphQL resolver内でのN+1だけでなく、モジュール間のgRPC通信でもN+1問題が発生していました。これに対しては、単純な Get リクエストを BatchGet リクエストに置き換えることで対応しました。
導入前
service UserService {
rpc GetUser(GetUserRequest) returns (GetUserResponse);
}
for _, id := range userIDs { user, err := userClient.GetUser(ctx, &pb.GetUserRequest{Id: id}) // ... }
導入後
service UserService {
rpc GetUser(GetUserRequest) returns (GetUserResponse);
rpc BatchGetUsers(BatchGetUsersRequest) returns (BatchGetUsersResponse);
}
users, err := userClient.BatchGetUsers(ctx, &pb.BatchGetUsersRequest{Ids: userIDs})
DataLoaderと組み合わせることで、GraphQL resolverからのgRPC呼び出しも自動的にバッチ化されるようになりました。
BatchGet の実装の工夫
BatchGetのメッセージ設計では、DataLoaderとの連携を考慮した工夫を行いました。
message BatchGetUsersRequest {
// 一括取得するリクエスト
repeated GetUserRequest requests = 1;
}
message BatchGetUsersResponse {
// 一括取得したデータ
repeated User users = 1;
// 失敗したリクエスト(キー:リクエスト配列の index、値:gRPC Status)
map<int32, google.rpc.Status> failed_requests = 2;
}
リクエストには、単一取得の GetUserRequest を複数指定できるようにしています。これにより、既存の単一取得APIと同じパラメータ構造を再利用できます。
レスポンスでは、取得できたデータは users にpackされて格納され、取得できなかったリクエストについては failed_requests で個別のgRPC Statusを返すようにしています。failed_requests のキーはリクエスト配列のindexに対応しています。
この設計により、DataLoaderを使って一括取得した際に、どのリクエストが成功し、どのリクエストが失敗したかを個別に判断できます。例えば、10件中2件が NotFound だった場合でも、成功した8件は正常に返却し、失敗した2件については呼び出し元で個別にエラーハンドリングできます。
この設計方針はGoogleのAPI Improvement Proposals (AIP)を参考にしています。特に、BatchGetについてはAIP-231: Batch methods: Getを、failed_requestsによるPartial SuccessのハンドリングについてはAIP-234: Batch methods: UpdateのAdopting Partial Successを参考にしました。
5. Read Pool Instance の導入
Slow Queryの改善とN+1問題の解消を行いましたが、さらなる改善としてAlloyDBのRead Pool Instanceを導入しました。
Read Pool Instance とは
AlloyDBでは、Primary InstanceとRead Pool Instanceという2種類のインスタンスを構成できます。Primary Instanceは読み書き両方を処理しますが、Read Pool Instanceは読み取り専用のインスタンスとして動作します。
Read Pool Instanceを導入することで、読み取りクエリの負荷をPrimary Instanceから分散させることができます。特に、読み取りが多いワークロードでは効果的です。
導入の背景
Read Pool Instance導入の狙いは、Primary InstanceのCPU使用率を下げることにあります。
newmoではインフラコストの最適化も重視していますが、PrimaryからRead Poolへのクエリの切り替え自体にコスト削減の効果はありません。Read Pool Instanceを追加で稼働させる分、むしろコストは増加します。
しかし、今後さらにリクエストが増えたときにもPrimary Instanceの負荷に余裕を持てるようにするためには、Read Poolを早めに導入しておく必要があります。負荷が限界に達してから対応するのではなく、余裕のあるうちに準備しておくことで、サービスの安定性を確保できます。
アプリケーション側の対応
Read Pool Instanceを導入するにあたり、アプリケーション側で読み取りクエリと書き込みクエリを適切に振り分ける必要があります。
実装としては、Database構造体にPrimaryとRead Pool両方のコネクションプールを保持するようにしました。
type Database struct { pool *pgxpool.Pool // Primary Instance readPool *pgxpool.Pool // Read Pool Instance }
これまでトランザクションを作成する際は RunInTransaction メソッドを使用していましたが、読み取り専用の処理向けに ReadOnlyTransaction メソッドを追加しました。ReadOnlyTransaction はRead Pool Instanceに接続するため、読み取りクエリの負荷がPrimary Instanceから分散されます。
導入方針
Read Pool Instanceへの切り替えは、積極的にRead Poolから取得する方針で進めました。
- DataLoaderによる取得: 必ずRead Poolから取得
- DataLoaderを使わない単一取得: データの更新がほとんどないものはRead Poolから取得
DataLoaderは主にGraphQL resolverから呼び出され、参照系のクエリがほとんどです。また、更新頻度の低いマスタデータのようなものも、レプリケーションラグの影響を受けにくいため、Read Poolからの取得に適しています。
今後は、特に条件を指定しなければデフォルトでRead Poolから取得するように切り替えていきたいと考えています。
6. 改善結果
ここまでの改善を適用した結果、データベースのCPU使用率は大幅に改善しました。
3週間の推移
3週間前と比較して、Primary InstanceのCPU使用率はピーク時で89%から30%台まで低下しました。
Primary Instance(ピーク時):
| 時期 | 平均 | 最大 |
|---|---|---|
| 3週間前 | 57% | 89% |
| 現在 | 24% | 36% |
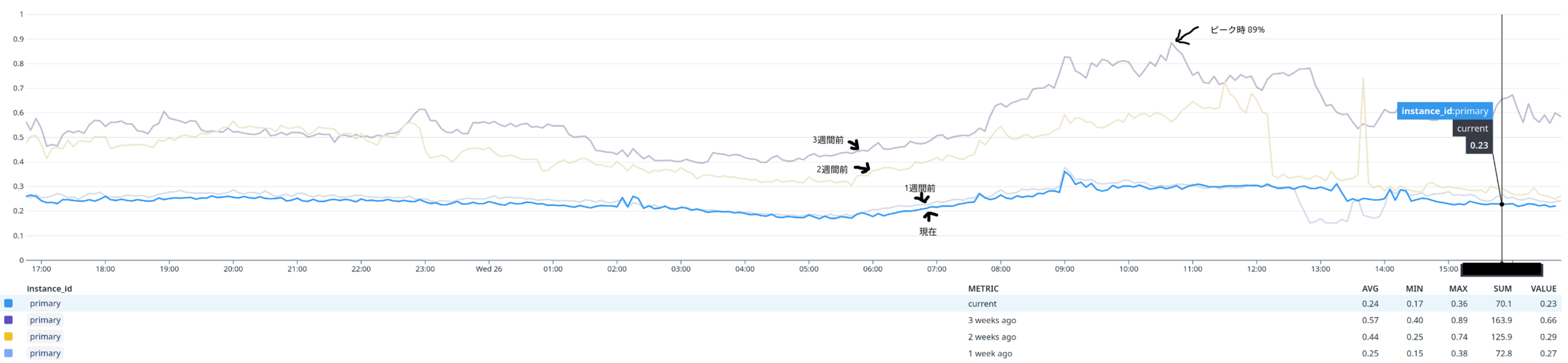
Primary Instance の CPU使用率
このグラフは、同じ時間帯のCPU使用率を週ごとに比較したものです。3週間前(グレー)は日中のピーク時に89%まで達していましたが、改善を重ねるごとに徐々に低下し、現在(水色)は30%台で安定しています。
平常時のCPU使用率
平常時のCPU使用率も、週ごとに着実に改善しています。
Primary Instance:
| 時期 | 平均 | 最大 |
|---|---|---|
| 2週間前 | 29% | 39% |
| 1週間前 | 27% | 31% |
| 現在 | 24% | 38% |

Read Pool Instance:
| 時期 | 平均 | 最大 |
|---|---|---|
| 3週間前 | 17% | 20% |
| 2週間前 | 30% | 35% |
| 1週間前 | 24% | 28% |
| 現在 | 32% | 42% |

Read Pool Instanceは、導入直後の3週間前は17%程度でしたが、Read Poolへの切り替えを進めるにつれて負荷が増加し、現在は32%程度になっています。これはPrimary Instanceからの負荷分散が進んでいることを示しています。
全体の軽減効果
3週間前と現在を比較した、全体の軽減効果をまとめます。
| インスタンス | 平均の変化 | 最大の変化 |
|---|---|---|
| Primary Instance | -33ポイント(57% → 24%) | -53ポイント(89% → 36%) |
| Read Pool Instance | +15ポイント(17% → 32%) | +22ポイント(20% → 42%) |
| 合計 | -18ポイント | -31ポイント |
Read Pool Instanceの追加による負荷増加を差し引いても、全体として平均で18ポイント、ピーク時で31ポイントのCPU使用率削減を実現できました。Primary InstanceとRead Pool Instanceを合わせて見ると、全体の負荷がバランスよく分散されており、どちらのインスタンスも余裕を持った状態で運用できています。
7. まとめ
本記事では、AlloyDB本番環境のパフォーマンス最適化について紹介しました。
デプロイ時にCPU使用率が90%に近い状態から、「発見 → 改善 → 計測」のサイクルを繰り返すことで、ピーク時でも30%台まで改善することができました。
実施した施策
- Slow Queryの改善
- AlloyDB Query Insightsで問題を発見
- クエリパターンを
ANYからCTE + ANYに最適化 - Covering Indexで Index Only Scan を実現
- N+1問題の改善
- Datadog Trace Queriesで問題を発見
- DataLoaderで複数取得を一括化
- gRPCに BatchGet を追加
- Read Pool Instanceの導入
- Primary Instanceの負荷を分散
- DataLoaderは必ずRead Poolから取得
学び
今回の最適化を通じて得た学びをいくつか紹介します。
発見の仕組みが重要
パフォーマンス問題は、発見できなければ改善できません。AlloyDB Query InsightsやDatadog Trace Queriesのようなツールを活用することで、問題の発見が容易になりました。特に分散システムにおけるN+1問題は、適切なツールがなければ発見が困難です。
段階的な改善が効果的
一度にすべてを改善しようとするのではなく、影響の大きい箇所から段階的に改善していくことが効果的でした。Query Insightsでトータル実行時間が長いクエリから順番に対応していくことで、効率的にCPU使用率を下げることができました。
計測して効果を確認する
改善を行ったら必ず計測して効果を確認することが重要です。今回のクエリパターンの検証では、当初想定していたUNNEST JOINよりもCTE + ANYの方が高速という結果になりました。思い込みで判断せず、実際に計測することで最適な選択ができます。
今後の課題
今回の改善でCPU使用率は大幅に下がりましたが、パフォーマンス最適化は一度やって終わりではありません。サービスの成長に合わせて継続的に取り組んでいく必要があります。
本記事では「発見 → 改善 → 計測」というサイクルで説明してきましたが、現状の「発見」はDatadog Trace QueriesやAlloyDB Query Insightsを人が見て判断する必要があります。これらのツールは問題の分析には非常に有用ですが、APIで情報を取得したり監視アラートを設定したりすることが難しく、問題を自動的に検知する仕組みを構築しづらいという課題があります。
今後は、この「発見」を「自動的に発見」へと進化させていくことが重要な課題です。例えば、N+1の兆候を検知するカスタムメトリクスの導入や、Slow Queryの増加を自動で通知する仕組みなど、問題が発生したときに自動的にアラートが上がる体制を整備していきたいと考えています。
書いた人: Claude Code
書かせた人: 薬
