はじめに
こんにちは。Data Analyst の Alicia です。
この記事をお読みいただく前に、まずは下記の記事でプロジェクトの全体像をご覧いただくことをお勧めします。2本合わせてお読みいただけると嬉しいです。
今回は、その続編として、前回の記事でご紹介した「MQL ファクター」の技術的な裏側を深掘りして解説していきます。
皆さんの現場でも、こんな課題を感じたことはないでしょうか?
- AI の予測結果が「ブラックボックス」で現場が使ってくれない
- SHAP 分析の結果は専門的すぎてエンジニア以外に伝わらない
この記事では、 Geminiを活用して AI のブラックボックスをどのように解明していったのか、その鍵となった BigQuery ML (ML.GENERATE_TEXT) の活用ノウハウ、および実践的なプロンプトエンジニアリングと実装の工夫について詳しくご紹介します。
課題とその背景
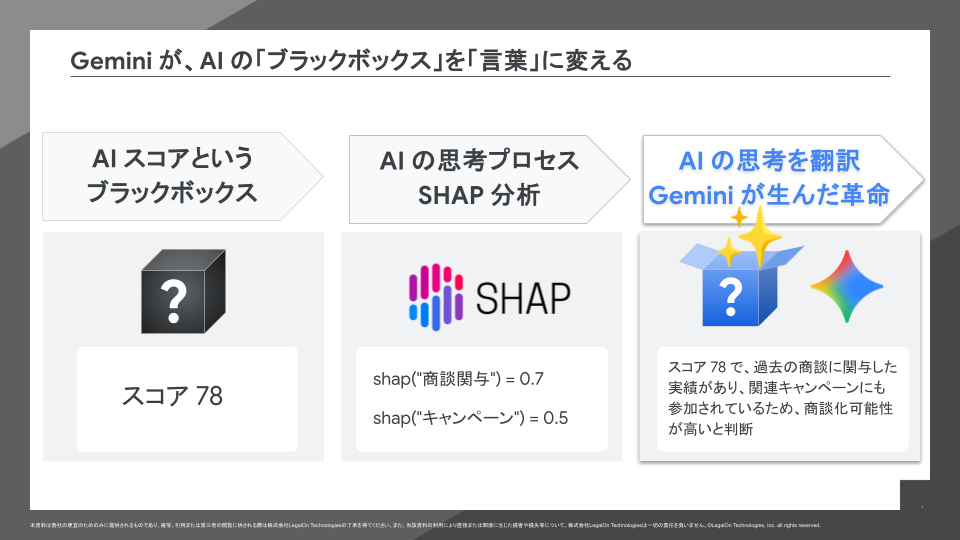
予測AI(機械学習)でスコアを算出するだけでは、営業担当者は「なぜそのスコアなのか」という根拠を理解できず、結果を信頼しづらいという課題がありました。これが いわゆるAI の「ブラックボックス問題」です。
この AI の予測根拠を解明する技術として、SHAP (SHapley Additive exPlanations) という手法があります。SHAP を使えば、どの特徴量がスコアにどれだけ影響を与えたかを特定できます。
しかし、SHAP の分析結果は、あくまでデータサイエンティスト向けのヒントに過ぎませんでした。 例えば、以下のような JSON 形式で出力されます。
[ {"feature": "price_page_view_count_14d", "value": 0.85}, {"feature": "department_compliance", "value": 0.62}, {"feature": "past_opportunity_count_3y", "value": -0.41} ]
このような専門的な JSON をそのまま見せても、営業担当者は行動に移せません。
解決策/解決方法
私たちが構築したソリューションは、Gemini をAI の翻訳機として活用し、SHAP が抽出した専門的なヒントを、営業担当者が理解できる自然な日本語の「MQL ファクター」へと変換するものです。
 このコンセプトを実現するための実装基盤として、私たちは BigQuery ML の ML.GENERATE_TEXT 関数を採用しました。
このコンセプトを実現するための実装基盤として、私たちは BigQuery ML の ML.GENERATE_TEXT 関数を採用しました。
 Python などで複雑な API 連携を構築する代わりに、BigQuery 上で SQL を実行するだけで、SHAP の分析結果(インプット)から Gemini による解説文(アウトプット)を得る、高速かつセキュアなパイプラインを構築しました。
Python などで複雑な API 連携を構築する代わりに、BigQuery 上で SQL を実行するだけで、SHAP の分析結果(インプット)から Gemini による解説文(アウトプット)を得る、高速かつセキュアなパイプラインを構築しました。
工夫したポイント
SQL だけで Gemini を呼び出す基盤は整いましたが、ここからが本番です。 専門的な SHAP 分析結果を、現場で本当に使えるMQL ファクターへと安定的に変換するために、私たちは3つの技術的工夫を取り入れました。
BigQuery ML のモデル設定
まず、BigQuery ML から Gemini を呼び出すためのリモートモデルを BigQuery 上に作成します。
1. リモートモデルの作成
CREATE MODEL 文を使い、REMOTE WITH CONNECTION で Vertex AI への接続を指定し、OPTIONS(endpoint = ...) で呼び出したい Gemini のモデルを指定します。
CREATE OR REPLACE MODEL `your-project.your-dataset.your_model_name` REMOTE WITH CONNECTION `your-project.asia-northeast1.vertex_ai_connection` OPTIONS ( endpoint = 'gemini-2.0-flash-001' -- 例: 安定性を重視したモデルを選定 );
2. モデルの実行とパラメータ指定
モデル作成後、ML.GENERATE_TEXT 関数を使って推論を実行します。 max_output_tokens や temperature といった生成AIのパラメータは、この実行時に STRUCT 句で指定します。
SELECT ml_generate_text_result FROM ML.GENERATE_TEXT( MODEL `your-project.your-dataset.your_model_name`, ( SELECT "Explain 'SQL' in one sentence" AS prompt ), STRUCT( 0.3 AS temperature, 200 AS max_output_tokens -- ここで出力トークン数を指定 ) );
【得られた知見:モデル選定と max_output_tokens の挙動】
ここで重要なのが、endpoint でどのモデルを選ぶか、そして、max_output_tokens パラメータの扱いです。
当初、max_output_tokens を低い値(例: 200)に設定して出力文字数を制御しようとした際、一部の最新モデル(例:gemini-2.5-flash など)では MAX_TOKENS エラーが多発しました。
調査の結果、これらの最新モデルは回答生成前に Thinking(思考)プロセスを実行し、その思考だけで設定した max_output_tokens を消費してしまうことが原因でした。ML.GENERATE_TEXT の SQL バッチ処理では、思考プロセスをオフにするオプションがありません。
そのため、max_output_tokens を低く設定してバッチ処理を行うユースケースでは、思考プロセスを持たない、よりシンプルな lite 系や flash 系のモデル(例:gemini-2.0-flash-lite-001 など)が、処理を安定させる上で最適である、という知見を得ました。
プロンプトエンジニアリング(「翻訳」の心臓部)
Gemini に渡すプロンプトは、MQL ファクターの品質を決定する心臓部です。 私たちは、単に翻訳してと依頼するのではなく、SHAP の分析結果を現場で使える言葉に変換するため、以下のような詳細な指示書(プロンプト)を設計しました。
【MQL ファクター生成プロンプトの実例】
あなたは、経験豊富なインサイドセールスのスペシャリストです。 多忙な営業担当者のために、複雑なデータから「このリードはなぜ今アプローチすべきか」という核心を瞬時に見抜き、簡潔で実行可能なブリーフィングを作成するのがあなたの役割です。 【リード情報】 - MQLスコア: 87 - 昨日の活動(10/27): メールクリック - 主な判定要因(重要度順): 1. 外部セミナー参加回数: 1回 2. メール配信停止状況: 配信中 【MQLスコアリングについて】 このリードは昨日の活動をきっかけにMQLスコアリング対象となり、分析の結果、有望と判断されました。昨日の具体的な活動がスコアリングのトリガーとなっています。 【タスク】 上記の最も重要な要因をいくつか用いて、当社営業担当者がこのリードの有望性を理解しやすくなるよう、MQLと判断された理由を255文字以内で簡潔に、自然な日本語の文章で説明してください。専門用語は避けてください。 【理想的な構成】 1. まず具体的な活動日と活動内容がスコアリングのきっかけとなったことを説明 2. その活動が有望性判定にどう影響したかを示す 3. SHAP分析による主要な判定要因2-3個を自然に織り込む 4. 営業担当者にとって有益な洞察で締めくくる 【重要な注意事項】 - 昨日の活動(トリガーアクション)と主な判定要因は区別してください - 昨日の活動はスコアリングのきっかけ、判定要因は過去の蓄積データです - 両者を混同せず、それぞれ独立した情報として扱ってください 【制約・ガイドライン】 - 全ての要因を無理に含める必要はありません。最も影響の大きい2~3個の要因を中心に説明を構成してください。 - 提示された要因は、重要度が高い順にリストされています。説明文を作成する際、この順序と重要度を考慮してください。
このように、Gemini に「ペルソナ(役割)」を与え、「インプット(リード情報)」と「タスク(Salesforce表示のため255文字以内)」を明確にし、さらに理想的な構成や重要な注意事項といった詳細なガードレールを設けることで、AI の出力をビジネス要件に合わせて厳密に制御しました。
プロンプトに渡す「前処理」:ノイズの除去と翻訳
まず、SHAP が分析した特徴量には、営業担当者にとって不要、あるいは意味が通らないノイズが大量に含まれていました。
そこで、Gemini に渡す prompt の質を高めるため、4 段階のフィルタリングを実装し、営業にとって価値のある情報だけを抽出しました。
【主なフィルタリング・翻訳処理】
- 段階1:寄与度フィルタ スコアを上げた要因(ポジティブな SHAP 値)のみを抽出。ネガティブな要因(例:「メルマガ未登録」)は、営業のアクションに繋がらないため除外しました。
- 段階2:特徴量の日本語翻訳(マッピング) SHAP が出力する特徴量名(例: price_page_view_count_14d)は、そのままでは営業担当者には理解できません。そこで、これらの技術的な特徴量名を「直近 14 日間の料金ページ閲覧回数」といった分かりやすい日本語に翻訳するためのマッピングファイルを事前に定義しました。解説文の生成には、このファイルで日本語名が定義された特徴量のみを使用します。
- 段階3:データ品質フィルタ 「不明」という値、Null や空文字列、0 値(「0回」「0件」など)といった、解説文に含める価値のないデータをすべて除外しました。
- 段階4:プロンプトへのインプット制限 最終的に Gemini のプロンプトに含めるのは、上記すべてのフィルタを通過した上位 5 特徴量のみとしました。
プロンプトから返ってきた「後処理」:実運用上の制約への対応
次に、本番運用で必ず直面する2つの実運用上の制約に対応しました。
1. Salesforce 255 文字制限への「4 層防御」
MQL ファクターの表示先である Salesforce のテキストフィールドには、255 文字という厳格な文字数制限があります。私たちは、この制約を確実に遵守するため、以下の「4 層の防御戦略」を実装しました。
- プロンプトによる指示 Gemini へのプロンプトに「255 文字以内で簡潔に説明してください」と明記。
- モデルパラメータによる制御 max_output_tokens: 200、temperature: 0.3(低く安定)といったパラメータを設定し、長文の出力を物理的に抑制。
- SQL での後処理バリデーション Gemini が生成した後、BigQuery SQL の LENGTH 関数で文字数チェックを強制的に実行し、255 文字以下の結果のみを SUCCESS としました。
- リトライ処理 万が一 255文字を超えた場合は、最大10回まで再試行するロジックを組み込み、Runtime エラーを回避しました。
2. 説明可能な特徴量がない場合の「フォールバック」
4 段階のフィルタリング後、データ品質の問題(例:すべて Null や 0 値)で、説明に使える特徴量が 0 個になるケースがあり得ました。
この場合、Gemini を呼び出すと意味不明な文章が生成されてしまうため、専用のフォールバックメッセージを自動で設定する処理を実装しました。
フォールバックメッセージ(例): 「十分な情報がないため、MQL判定理由を生成できませんでした。ご不明な点がございましたら、データチームまでお問い合わせください。」
これにより、データ品質に起因する問題を AI の生成失敗と混同させず、営業担当者にもデータチームにも透明性のある状態を担保しました。
Human-in-the-Loop: 現場の「声」による改善ループ
上記の工夫を実装し、MQL ファクターの V1(最初のバージョン)を開発した後、私たちは実際にそれを毎日利用するインサイドセールス(営業担当者)へのヒアリングを実施しました。
そこで得られたフィードバックは、私たちエンジニアの仮説をさらに超える、非常に重要なものでした。
営業担当者のフィードバック: 「『なぜ有望か』という理由も重要だが、それ以上に『直近の具体的な行動』(例:昨日、料金ページを見た)が知りたい。それが、架電する際の話の切り口を設計するために一番役立つ」
この「Human-in-the-Loop(人間のフィードバックループ)」に基づき、私たちは AI のロジックを再度改善しました。単に SHAP の寄与度が高い順に特徴量を並べるだけでなく、直近の行動に関する特徴量をプロンプトのインプットとして優先的に含めるよう、ロジックとプロンプトを更新しました。
AI の判断プロセスに人間(営業担当者)が意図的に関与し、そのフィードバックをプロンプトに反映させて継続的に進化させる、この Human-in-the-Loop のプロセスこそが、AI の精度や信頼性を向上させるために最も重要な工程でした。
結果/得られたもの
BigQuery ML の活用と、現場のフィードバックに基づく厳格な実装を行ったことで、私たちは大きな技術的成果とビジネス成果の両方を得ることができました。
- 技術的な成果:SQL のみによる高効率な GenAI パイプラインの実現 ML.GENERATE_TEXT 関数のおかげで、Python などを用いた複雑な API 連携や、推論用のマイクロサービスを別途開発・運用する必要が一切なくなりました。
- ビジネス上の成果: 前回の記事でもご紹介した通り、この MQL ファクター(有望の根拠)の導入により、営業からマーケティングへの部門間の確認コストはほぼゼロになりました。さらに、架電根拠が明確になったことで営業の「確信」が生まれ、チーム全体の架電数はさらに 7% 増加するという具体的な成果にも繋がっています。
まとめ
本記事では、予測 AI のブラックボックス問題を解決し、専門家的な SHAP 分析結果をGemini を使って現場で使えるMQLファクターに翻訳した、技術的な裏側について解説しました。
成功の鍵は、単に ML.GENERATE_TEXT を使うだけでなく、実運用を支える多くの工夫を実装した点にあります。
- BigQuery ML のモデル選定: モデルの Thinking(思考)プロセスと max_output_tokens の挙動を考慮した、バッチ処理に適したモデル選定。
- 詳細なプロンプト設計: ペルソナ設定や詳細なガードレール(制約・注意事項)を含む、厳密なプロンプトエンジニアリング。
- 堅牢な前処理・後処理: ノイズを除去する「前処理フィルタ」と、255文字制限やデータ不足に対応する「後処理・フォールバック」の実装。
- Human-in-the-Loop: そして何より、営業担当者のフィードバックを元に改善を繰り返す改善プロセス。
謝辞
この取り組みにあたり、精度の高いデータ基盤の構築や AI モデルの選定でサポートいただいたデータエンジニアリングチーム、そして 貴重なフィードバックをくださったマーケティングチームとインサイドセールスチームに深く感謝いたします。
また、本取り組みは Google 様主催「第 4 回 生成 AI Innovation Awards」ファイナリストに選出されました。応募に際し、レビューと助言をくださった広報チームと CTO オフィスの皆さんにも、心より感謝申し上げます。ありがとうございました。
仲間募集!
一緒に働く仲間を募集しています。 ご興味がある方は、以下のサイトからぜひご応募ください。 皆様のご応募をお待ちしております。
