
こちらはLayerX AI Agentブログリレー1日目の記事です。
こんにちは、Hiromu Nakamura (pon) です。 LayerXでAI/MLOpsをやってます!
最近はAI Agentの開発の中で、個人的にTemporal Knowledge Graphに注目しています。今回は関連論文や技術を紹介しつつ、私が作成したPoCや実装のポイント、課題についてお話しします。
目次
- 目次
- AI Agent用のメモリ/ナレッジを持つ必要性
- Knowledge Graphの世界
- Temporal Knowledge Graphの世界
- 申請レビューAI AgentのPoCから学ぶ Temporal Knowledge Graphで出来ること
- Temporal Knowledge Graph周りのプラクティス
- AI Agent × Temporal Knowledge Graphの評価
- まとめ
AI Agent用のメモリ/ナレッジを持つ必要性
まずは、そもそもなぜメモリ/ナレッジ基盤が必要なのでしょうか?AI Agentのコンテキストエンジニアリングのためというのが一つの理由ですが、もっと大きな理由があります。次は# The State of AI 2025の「Dark matter: Memory, context and beyond」の章からの引用です。
メモリをバックエンドの配管ではなく、製品として扱うべきです。今日、メモリ認識を基盤に構築するスタートアップこそが、未来の最もインテリジェントでパーソナライズされ、かつ強力なAIシステムを構築するでしょう。
自社製品がナレッジとしてユーザーの世界を深く学べれば、大きな資産となり、競合へのリプレイスを防ぐ強固な壁になります。これは、近い領域のプロダクトが今後も増えていくであろうことを考えると、私たちLayerXにとっても重要な観点であると考えています。
LayerXでもナレッジは非常に重要な基盤として扱っており、先日公開されたLayerXのAi Workforceでもナレッジは重要なコンポーネントとして位置づいています。
また、バクラクでもテナントごとの社内規定や、ユーザーの過去の申請などをナレッジとして蓄積する開発が絶賛進んでいます。ナレッジはAI Agent開発にとって非常に重要です。
次からは、AI Agentがメモリ/ナレッジを扱う基盤として注目を浴びているKnowledge Graph & Temporal Knowledge Graphの世界を覗いていきます!
Knowledge Graphの世界
そもそもKnowledge Graphとは
Knowledge Graphは、文脈に沿って情報を整理し、洞察を得やすいようにデータをグラフで表現したものです。これにより、非常に直感的な方法で有用なナレッジを汎用的に表現できます。
Knowledge Graphに関する日本語の文献としては書籍「はじめての知識グラフ構築ガイド」がお勧めです。この本ではKnowledge Graphとは何か、実際にNeo4jでグラフを触るハンズオンから、グラフを使ったデータサイエンス、機械学習まで踏み込んでいます。AI Agentに組み込むなどの応用的なトピックはありませんが、Knowledge Graphに関する知識を包括的に解説しています。
AI Agent開発においては、コンテキストエンジニアリングの方法としてKnowledge Graphを利用するケースが増えてきました。特にGraphRAGはKnowledge Graphを使ったRAGとして注目されています。
LLMの登場でKnowledge Graphが構築しやすくなった!!
Knowledge Graphが盛り上がっている背景として、AI Agentのコンテキストとして利用するユースケースが増えたということもありますが、LLMでKnowledge Graphが構築しやすくなったという点も見逃せません。今まではドメインのユースケースに沿ったエンティティやリレーションの抽出を自然言語処理や機械学習モデルで行う必要があり、非常にハードルが高いものでした。しかしLLMを使えば、プロンプトでエンティティやリレーションの抽出が容易になりました。
例えば、GraphRAGの論文では、LLMベースのエンティティ、リレーションの抽出を行っています。そして、Leidenアルゴリズムでグラフのコミュニティ抽出をしたのちにコミュニティ要約もLLMで生成しています。

今まで難しかったKnowledge Graph構築の大部分をLLMで行うことができます。そのため、AI AgentのコンテキストとしてKnowledge Graphを利用するユースケースも増えています。
Knowledge Graphの使い所
全てのAI AgentでKnowledge Graphを使うのは冗長になる可能性もあります。GraphRAGは多くのタスクにおいて、vanilla RAG(通常のRAG)よりも性能が低いことが報告されることもあります。どういった時にKnowledge Graphを導入するのが良いでしょうか。
Zhishang Xiangらの研究では階層的な知識検索と深い文脈的推論の両方でGraphRAGモデルを評価するために設計された包括的なベンチマークであるGraphRAG-Benchを提案し、GraphRAGが従来のRAGを上回る条件と、その成功の根本的な理由を体系的に調査し、その実用的な応用に関するガイドラインを提供します。
4つの検索レベルを定義し、4つの評価指標で包括的にGraphRAGについて調べた研究で学びになるので、Knowledge Graph系列でRAGを使うことを考える場合は一読をお勧めします。
超ざっくりまとめると、GraphRAGは単純な事実検索、WideSearchのような網羅性が重要なタスクには弱いです。逆に、複数の概念間の複雑な関係性や深い文脈理解を必要とするタスクではGraphRAGに軍配があがります。GraphRAGはタスクの複雑性が増すにつれて検索の網羅性と組織化を向上させますが、プロンプトの膨張によるトークンオーバーヘッドという非効率性を伴うので、ここはトレードオフで考える必要があります。
詳しくは論文をご覧ください。
Temporal Knowledge Graphの世界
そんなGraphRAGにも課題があります。GraphRAGは事実が時間とともに変化しない静的なKnowledge Graphに焦点を当てており、時間変化に伴う動的な進化を無視しています。一方で、Temporal Knowledge Graphは時間認識型で動的な変更に強いKnowledge Graphです。会話データの中で出現するユーザーの新しい嗜好はもちろん、時間経過で追加される年次決算書や社内ルールなど、時間経過で変化するナレッジを扱うことができます。これにより、ユーザーとのやり取りでAI Agentの行動が逐次的に改善されていくサイクルを回すことができます。
それではTemporal Knowledge Graphにはどのような種類があるのでしょうか?今回はTechnology Radar Vol 32で推奨度レベルAccessとして取り上げられ、先日話題になった# The State of AI 2025でも言及されたGraphiti(Zep)を中心に紹介していきます。後述するPoCのデモでもこのGraphitiを使っています。
Graphiti
GraphitiはTemporal Knowledge Graphの一種であり、それを扱うフレームワークとしてZepというOSSがあります(Zep Cloudとして有償利用か可能)。Zep(Graphiti)はPreston Rasmussenらの論文で紹介されています。
Graphitiは3段層のサブグラフで構成されます。
- エピソードサブグラフ(Ge)
- 生の入力データ(メッセージ、テキスト、JSONなど)を損失なしで保存し、時間的な順序を維持する。セマンティックエンティティや関係性を抽出する際の基盤となる。
- セマンティックエンティティサブグラフ(Gs)
- エピソードサブグラフから抽出されたエンティティ(人、物、場所、概念など)と、それらの間の関係性(ファクト)を構造化された形で表現する。
- コミュニティサブグラフ(Gc)
- セマンティックエンティティのクラスター(コミュニティ)を形成し、これらのクラスターの高レベルな要約を提供する。Knowlegdge全体の広範な、相互接続された視点を提供する。
- コミュニティサブグラフのアイデアはGraphRAGでも使用されています。
面白いのはエピソードサブグラフで、文章の損失なしでそのまま保存している点です。ベクトル化やサマライズで抜け落ちる情報の欠損を回避しています。この3段層により、生データから詳細な関係性、そして高レベルな概念までを、時間的文脈を維持しながら動的に表現し、エージェントが複雑な情報を効率的に検索・利用できるようなメモリを構築できるようになります。このように多階層のインデックスやグラフを作成手法は近年の研究ではよく見るするアプローチです。
3段層の繋がりを図にするとこうなります。
コミュニティサブグラフ (Gc)
▲
│ (Community edges: コミュニティとエンティティの接続)
▼
セマンティックエンティティサブグラフ (Gs)
▲
│ (Episodic edges: エピソードからエンティティへの参照)
▼
エピソードサブグラフ (Ge)
例として「国内出張は上長、海外出張は部門長の承認を得てください。」というエピソードを追加するとこのようになります(次の図は論文ではなく私が作成したものです)。
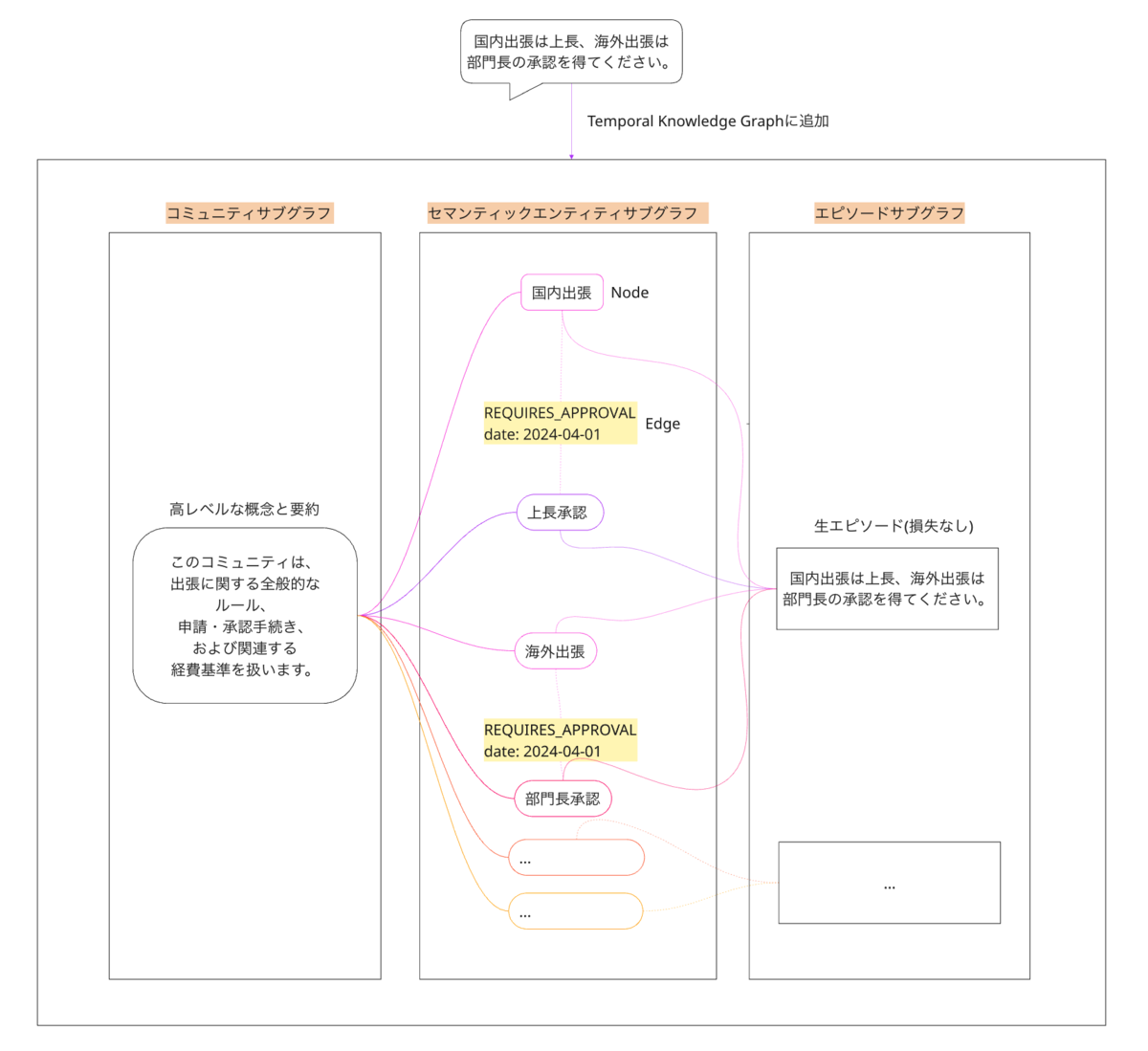
エピソードグラフには損失なしのそのままのエピソードを格納し、セマンティックエンティティサブグラフには各ノードとエッジ、エピソードサブグラフには概念と要約が格納されます。
各階層に対して、コサイン類似度検索、Okapi BM25全文検索、および幅優先探索を駆使して検索を行います。検索結果に対してZepはReciprocal Rank Fusion (RRF) や Maximal Marginal Relevance (MMR) などの既存のリランキングアプローチをサポートしています。
さらに、Zepは、会話内でのエンティティまたは事実の言及頻度に基づいて結果を優先するグラフベースのエピソード言及リランカーを実装しており、頻繁に参照される情報にアクセスしやすくなるシステムを実現しているそうです。ここに関しては解説が論文にありませんでしたが、気になりますね。
このTemporal Knowledge Graphがすこいのは、ナレッジをアップデートする際に、削除、アップデートするべき情報を見つけるための検索をしなくても良いということです。時間を付与したノード/エッジを追加するだけで、最新の情報だけを検索、3日前の情報を検索ができることです。そのため、動的なナレッジ統合が達成できます。
データセットは「LongMemEval」(平均約115,000トークンという長い会話コンテキストを提供し、より複雑な時系列推論タスクを含む)を利用しています。LLMにフルコンテキストを与える手法をベースラインに、質問タイプ別、モデルタイプ別で比較した結果がこちらです。
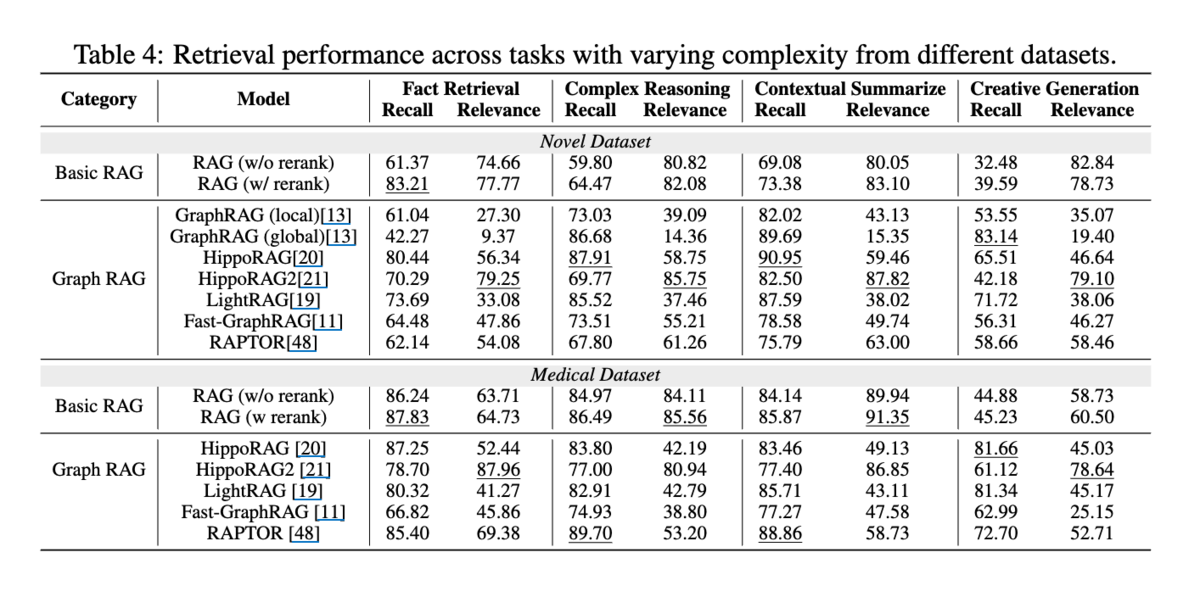
ここで各Question Typeの定義は割愛しますが、複雑なタスクにおいてはZepが従来のRAGアプローチでは扱いきれなかった動的なナレッジ統合と長期記憶において、既存のシステムを上回る性能を持つことを示しました。
T-GRAG
Temporal Knowledge Graphには他にも亜種があり、例えばT-GRAGは検索フェーズが3stageになっています。指定時間だけのサブグラフ取り出し、不要なコンテキストをベクトルの類似度で削るなどをしており、非常に面白いです。こちらの論文でもプロンプトを含めたKnowledge Graph構築方法も詳しく書かれているので、実装時の参考にもなります。詳しく解説はしないので、もし興味のある方は論文を参照ください。
ちなみにこちらは週一回LayerXでやっている機械学習勉強会でもメイントピックとして取り上げました。こちらもぜひ参照ください。
申請レビューAI AgentのPoCから学ぶ Temporal Knowledge Graphで出来ること
Temporal Knowledge Graphを利用したAI Agent機能を紹介するに当たって、バクラクの提供するAIエージェントサービスのひとつ「AI申請レビュー」の今後の拡張を見据えたPoCを行いました。PoC用のデモアプリケーションをお見せしつつ、実装のポイントをかいつまんで紹介します。
※これらはPoC段階の実験的な取り組みであり、AI申請レビューにおける開発・提供が決まっているわけではありません。
申請レビュー機能実装の難しさ
申請ルールは会社によって全く違うものであり、尚且つそのルールは不変ではありません。ルールをナレッジとして表現するためには時間経過による更新を表現できなくてはいけません。また、文章化されていないルールの場合、暗黙的に運用されているルールをナレッジとして動的に組み込んでいく必要があります。
これらの課題をTemporal Knowledge Graphで突破します。
ルール変更を自然言語で取り込むAI Agent機能
ユーザーから自然言語で申請ルールの変更を受け取り、リアルタイムにナレッジを更新することで、次の申請から即座に適用できます。
Temporal Knowledge Graphがすごいのは自然言語でナレッジの変更を動的に取り込めることです。LLMによるエンティティ/リレーション抽出パイプラインにより、ルール変更時に、現在時間をノードやリレーションに加えることで最新のルールをAI Agentが参照できるようになります。
人間による差し戻しコメントから学習し申請をレビューするAI Agent機能
もちろんルール変更を人が管理するのは手間です。そこで、差し戻しコメントから自動でAI AgentがコンテキストとしてTemporal Knowledge Graphに取り込みます。これで差し戻し発生時に自然とルールを拡張できます。差し戻しコメントにより、同じ差し戻し申請を手前でレビューできるようになるため、この機能を使えば使うほど、ユーザーの手間を減らすことができます。
社内ルールで曖昧なところを発見して補完してくれるAI Agent機能
更にAI Agentであればアップロードされた社内規定文書に対して曖昧な部分を自律的に発見し、報告してくれます。ユーザーはこの報告に対して、このパターンは承認、差し戻しという回答をすることで、社内ルールを拡張することができます。これは特に社内規定文書がまだ充実していないテナントにとって有用です。
このようにTemporal Knowledge Graphを採用した世界では動的なナレッジの変化をAI Agentが扱えるようになり、コンテキストエンジニアリングの基盤となります。そして、最初に紹介したようにナレッジとして、ユーザーの世界を深く学ぶことが、サービスにとって最も強力な資産となり、競合へのリプレイスに対する強い防壁となります。
実装方法
全てのデモはLangGraph + Azure OpenAI + Graphitiを利用して作成しています。GraphitiはDockerでローカルでたてています。もっとサクッと試したい場合はZep Cloudの無料枠で試すのもありかもしれません。Graphitiは内部でグラフDBを必要とします。現在はNeo4jやFalkorDB、AWS Nepture、Kuzu DBが使えます。今回のPoCではFalkorDBを利用しました。実験管理にはLangfuseを利用しています。
全体的なアーキテクチャはこうなります。

具体的なGraphiti利用方法はドキュメントに書いてあるのでそちらを参照してください。次からはその中でも実装のポイントについて解説します。
Temporal Knowledge Graph周りのプラクティス
ここからは私Temporal Knowledge Graphを使ったAI AgentをPoCした中で得たノウハウを紹介します。
日本語文書からTemporal Knowledge Graphを構築する
エンティティ/リレーション抽出パイプラインの構築は良いTemporal Knowledge Graphを構築するために最も重要なコンポーネントです。ここを実装する知見を共有します。
まずは、チャンク化です。あまりに長い文章をLLMに与えると抽出がうまくいきません。そこで文書を一行単位のエピソード形式に変換します。私のLLMプロンプトの例がこちらです。
ルールテキストをGraphitiナレッジグラフに適したエピソード形式に変換してください。
## 変換ルール:
1. 各ルールを個別のエピソードとして変換
2. 「何をする時のルールか」の文を各ルールで補完する
3. 1つのエピソードは1つの明確な事実または関係性に集中
4. 各エピソードは具体的で明確な記述にする
5. 階層がある場合は、上の階層との説明とマージする。
6. エンティティ(人、物、概念、目的、行動、状態)と関係性が明確になるよう記述
7. 「〜の場合、〜である」形式のルールを自然な文章に変換
8. 【重要】主語を必ず明確にし、「何が」「誰が」を省略しない
## 注意点:
- 各エピソードは1つの明確な事実または関係性に集中
- エンティティ間の関係が明確になるよう記述
- 抽象的な表現ではなく具体的な記述を心がける
- 階層がある場合は、上の階層との説明とマージする。
- 主語が不明確な場合は、文脈から適切な主語を補完する
- 出力結果には空行、リストの数字は不要です。
## 変換例:
入力ルール: ・交通費は月額5万円までが上限である。この制限は経費精算規程により定められている。
出力エピソード: 交通費の精算には月額5万円の上限が設定されている。交通費の精算に関する制限は経費精算規程により定められている。
入力ルール: ・1000円以上を申請する場合、領収書の添付が必要である
出力エピソード: 1000円以上の支出を申請する際は、必ず領収書の添付が義務付けられている。
入力ルール: 同行者分もまとめて申請が可能だが、同行者の氏名はフルネームで記載しなければならない。
出力エピソード: 出張を申請する際の代表者は、同行者分もまとめて申請が可能だが、同行者の氏名はフルネームで記載しなければならない。
入力ルール: 18,000円を超過する場合は、上長へ相談し会社の承認を得る必要がある。
✗ 悪い出力: 18,000円を超過する場合は、上長へ相談し会社の承認を得る必要がある。(何が超過か不明)
✓ 良い出力: 出張の際に宿泊費が1日あたり18,000円を超過する場合は、上長へ相談し会社の承認を得る必要がある。
ルールテキスト:
{rules_text}
各エピソードをエンティティ/リレーション抽出できるような変換ルールや注意事項を記載しています。。特に日本語で課題となるのは「主語の省略」です。ここはプロンプトで明確に対応する必要があります。このような注意ポイントはT-GRAG論文の「C Prompts for Building Dataset」のプロンプトを見ると勉強になります。この論文でも次のような注意ポイントをプロンプトに渡しています。
- キーポイントが互いに独立しており、内容が重複しないようにすること。 - 数字、名前、日付などを含む、簡潔で正確かつ完全なキーポイントであること。 - 複雑な書式や改行を避け、1〜2文で記述すること。 - 特定の年に発生したイベントに関わるキーポイントのみを抽出し、それ以外のものは無視すること(非常に重要)。 - 代名詞を避け、参照するエンティティを明確にすること。 - 特定の導入フレーズ(例:「記事では議論されている」)を使用しないこと。
また、Temporal Knowledge Graphでは時間を付与した上で適切にナレッジを上書きしたいため、同じエンティティを別のエンティティとして扱ってしまうのは致命的です。申請レビューAgentのように、どんなルール更新が投げられるかわからない場合はより問題です。この問題がより顕著で、後続のLLMによるエンティティ解決が揺れる場合、ノード重複排除、エッジ重複排除ロジックを別で考える必要があります。この課題の対処は現在探求中です。
データセットとして加工した後続はGraphitiのKnowledge Graph変換処理に投げることになるので、ここが重要なステップとなります。もちろんGraphitiでのエンティティ抽出はカスタマイズ可能なのですが、Knowledge Graph検索の精度を上げるためにも、ここは手が抜けません。
効率的なKnowledge Graph構築
整形済みデータが用意できたら、Graphitiの内部処理に渡してグラフを構築します。
product_data = [
...
]
bulk_episodes = [
RawEpisode(
name=f"Product Update - {product['id']}",
content=json.dumps(product),
source=EpisodeType.json,
source_description="Allbirds product catalog update",
reference_time=datetime.now()
group_id= {product['tenant_id']}
)
for product in product_data
]
await graphiti.add_episode_bulk(bulk_episodes)
内部ではLLMで次のことが行われます。
- 前処理: テキストをクリーンアップして正規化する
- エンティティ抽出: NERとLLM分析を使用して言及されたエンティティを識別する
- 関係抽出: エンティティ間の接続を決定する
- 時間分析:時間マーカーとコンテキストの抽出
- グラフ統合: 新しい情報でナレッジグラフを更新する
- 一貫性チェック:既存の知識と照らし合わせて検証する
ローカルでの実験環境構築などでは大規模なデータセットから一気にKnowledge Graphを構築する必要があります。そこでadd_episode_bulkを使っています。これにより大幅なパフォーマンス向上を実現できます。
bulk insertの効率性は主に以下の要因になります。
- DBレベルでのバッチ処理(UNWIND文の使用)
- メモリ内でエピソード間での重複ノードの事前排除することにより無駄な処理の削減
- 並列処理による処理時間の短縮
- 単一トランザクションによるオーバーヘッドの削減
さらにGraphitiではgroup_idでユーザーやテナント固有の情報として格納できます。
await graphiti.add_episode( name="customer_interaction", episode_body="Customer Jane mentioned she loves our new SuperLight Wool Runners in Dark Grey.", source=EpisodeType.text, source_description="Customer feedback", reference_time=datetime.now(), group_id="customer_team" # This namespaces the episode and its entities )
group_idにより、以下のクエリ最適化が実現されます:
- 範囲限定検索: 特定のグループ内のみでの検索が可能
- インデックス効率: グループ固有のインデックスにより高速アクセス
- 並列処理: グループ単位での独立した処理が可能
- マイグレーション処理での効率化
申請レビューAI Agentの場合はテナントごとにgroup_idをつけることにより、名前空間を分離しています。名前空間がつけれるようなサービスの場合はgroup_idの運用を検討しましょう。
Knowledge Graph Qualityの評価
Knowledge Graphが上手く構築できたかどうかはAI Agentが正しく動作するかを支える大事なポイントであるとお伝えしました。Knowledge Graphがうまく構築できたかをどうやって評価すれば良いでしょうか?
Zhishang Xiangらの研究では構築したRAGのためのKnowledge Graph Qualityの評価指標を紹介しています。ノード数エッジ数、平均エッジ数を見るのはもちろんですが、平均クラスタリング係数などの指標も有効です。私の今回のPoCではこれらの指標で簡単にTemporal Knowledge Graphを確認しました。
検索クエリ生成
受けた申請から、検索クエリを文章として生成します。申請は構造化されたデータで飛んでくるので、受けた申請のレビューに必要な文書を問い合わせる質問をLLMに生成させます。
出張申請の内容を分析して、この申請を差し戻すかどうかを決定するための文章を検索するクエリを生成してください。
【申請内容】
申請者: {application.applicant}
目的: {application.purpose}
行き先: {application.destination}
出発日: {application.departure_date}
帰着日: {application.return_date}
概算費用: {application.estimated_cost:,}円
詳細: {application.details}
【検索クエリ生成指示】
以下の観点から最大8個の検索クエリを生成してください:
1. 行き先に関する規定(地域別制限、承認条件等)
2. 費用に関する規定(上限額、費目別制限等)
3. 目的に関する規定(業務内容による制限等)
4. 期間・日程に関する規定
5. 申請・承認プロセスに関する規定
6. その他関連する規定
【出力形式】
各クエリは1行ずつの質問文で出力してください。
例:
東京出張のルールはありますか?
宿泊費の上限に関するルールは?
このクエリ生成も実は難しく、LLMはKnowledge Graphにどのようなエンティティが入っているか知らないため、こちらからある程度、質問を考える範囲をプロンプトで調整する必要があります。複数のクエリを生成し、並列に検索することでコンテキストの見逃しを防ぐ、つまりコンテキスト再現率(Context Recall)を重視しています。 この方法は必要なContextを逃さない代わりに、コンテキストが大きくなりLLMの精度低下をもたらします。
ここは私もまだ調整しきれてない部分なので、今後も追求していきます。クエリ生成のプロンプトはテナントごとに変わるはずなので、プロンプト自動修復などの研究は追っていきたいです。
検索で使える手法に関してはこちらをご覧ください。
定性的にサクッと評価する
まずは数十個のサンプルスイートを手で作ってテストしましょう。AI Agentの一挙手一投足を追うことで、プロンプト改善の方向性、クエリ生成の方法などが見えてきます。これは「現場で活用するためのAIエージェント実践入門」でも紹介されているプラクティスです。
今回のPoCでは10件のデータ+ルール変更10件で、正しく差し戻しが動作できることをテストしました。実験ではLangfuseを利用しました。LangfuseはLLMOpsプラットフォームであり、プロンプトの管理から、データセット管理、実験までを扱えます。
AI Agent × Temporal Knowledge Graphの評価
私のPoCではここまで踏み込めてないのですが、Temporal Knowledge GraphでAI Agentを構築する際に非常に重要になるので紹介します。
Knowledge Graphが上手く構築できたかどうかはAI Agentが正しく動作するかを支える大事なポイントであるとお伝えしましたが、Knowledge Graph Qualityメトリクスだけでなく、AI Agent × Temporal Knowledge Graphを包括的に評価したい場合どうすれば良いでしょうか?
このトピックに関してはRAGの評価メトリクスを提供するRagasが非常に参考になります。検索モジュール単体の評価、LLM+コンテキスト単体の評価、一連のパイプラインを統合した評価など、包括的なメトリクスを提供してくれます。検索好きとしては眺めるだけで酒が進みます。詳しくは解説しないので、興味のある方は是非見てみてください。
https://docs.ragas.io/en/latest/
そして、問題となるのが評価データセット問題です。実はRagasはLLMを使ったデータセット構築もサポートしており、なんとその中でKnowledge Graphを使っています。(これを読んだ時私は最高に興奮しました)

ドキュメント群を一度ナレッジグラフに変換してそこからクエリ生成を行います。データセットの質がナレッジグラフ構築力に依存してしまいますが、試してみる価値はありそうです。これを実際に日本語で実践した話は別の記事で書く予定です。
しかし、これだけだと時間経過を扱うデータセットがありません。時間経過するデータセットを作るヒントはT-GRAG論文で議論されています。ここでは企業の報告書からLLMで時間を含むデータセットを作る方法が言及されており参考になります。ここはドメイン固有のデータセットが必要になるため、腕力が問われます。
私もまだ「これが正解!」というものを見つけれてませんので、ここは随時追っていきます。
まとめ
今回はTemporal Knowledge Graphの世界をご紹介しました。この記事をきっかけにTemporal Knowledge Graphの面白さを知っていただき、日々のサービス開発のお役に立てると幸いです。
また、この記事はLayerX AI Agentブログリレーの1日目の記事です。毎日AI Agentに関する知見をお届けします!!LayerXテック公式Xか僕のX(@po3rin)を是非フォローして見逃さないようにお願いします!
LayerXではAIで全ての経済活動をデジタル化する仲間を募集しています。LLMを使って終わりではない難しいチャレンジが溢れています。もし今回の内容に興味を持っていただけたら、ぜひ一度お話しましょう。LayerXでは技術検証を積極的に行っており、非常に刺激的な環境です。是非カジュアルにお話ししましょう。
ここから僕につながります! jobs.layerx.co.jp
