こんにちは!Ai Workforce事業部FDEの恩田(さいぺ)です。
AIエージェントの進化も凄まじく、どんどん長時間のタスクをこなせるようになっています。この分野のベンチマークの第一人者であるMETRでも、最新のClaude Opus 4.6で10時間のタスクが50%の確率で完了できることが示されています(80%だと1時間)。
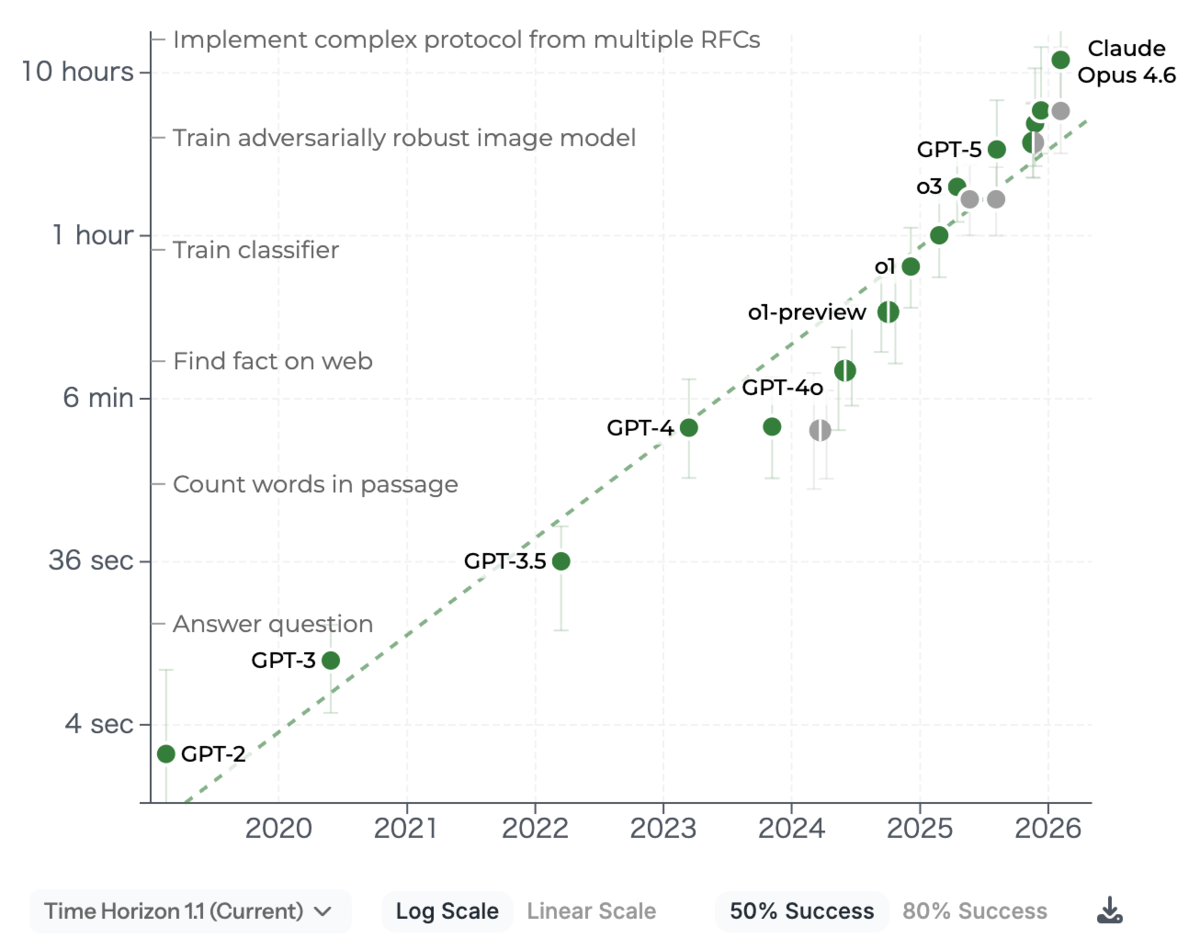 (出典: https://metr.org/ , 2026/4/7アクセス)
(出典: https://metr.org/ , 2026/4/7アクセス)
とはいえ、長時間に渡るタスクは、ステップ数も膨大です。各ステップの成功確率を上げたり、リトライや失敗の原因を考え、失敗しても復帰できるような仕組みが必要になりそうです。この分野をいくつか読んだので、その中でもおもしろかった論文をピックアップし、紹介します。
100万ステップのタスクをノーミスで解く
最初に紹介するのは2025年11月に公開された Solving a Million-Step LLM Task with Zero Errors (Elliot Meyerson et al.) です。論文のタイトルにもあるように100万ステップもの長さのタスクをLLMで解こうという論文です。これほどステップ数が膨大になると、各ステップの成功確率がほぼ100%でないと、最後まで成功し切ることができません。
そこで、本論文は以下のようなプロセスを考え、スケーリング則を示しています。
(1)最小限にサブタスクへの分解。ただし、適切なサブタスクへの分解は本論文のスコープ外で、個に分解できたタスク列を所与のものとしている
(2)サブタスクレベルの投票に基づくエラー訂正
(3)相関エラーを減らすためのレッドフラッグ
特におもしろいのが、セクション3.2「First-to-ahead-by-k Voting and Scaling Laws」です。First-to-ahead-by-k Votingは、1つのステップを複数回実行し、他のどの候補よりも回多くサンプリングされたものを回答とする手法です。
この手法では、各ステップの成功確率
について、
の場合、このプロセスを通じて正しい候補が選択される確率が計算できます。さらに任意のエラー率
に対して、この投票プロセスが確率
で正しい回答をもたらすようなある
が存在することが示せます(つまり
を十分小さく取れば、各ステップがほとんど100%と成功するような
が存在する)。
さらに、
個のタスクすべてを成功させるために必要な
が
でスケールするというのがこの論文の一番の見どころです。
導出を簡単に紹介します。まず、以下の定式化、仮定を置きます。
- すべてのタスクを完了するために合計
ステップが必要
- 固有のステップあたりの成功率を
とする
- 解析は最悪のケース(確率
の単一の代替案と競合する)を仮定
- 解析は最悪のケース(確率
- サブタスクを
ステップに分解可能とする
- 各サブタスクのアクションを決定するために
票の差が必要
このとき、すべてのタスクが成功する確率が計算できます。
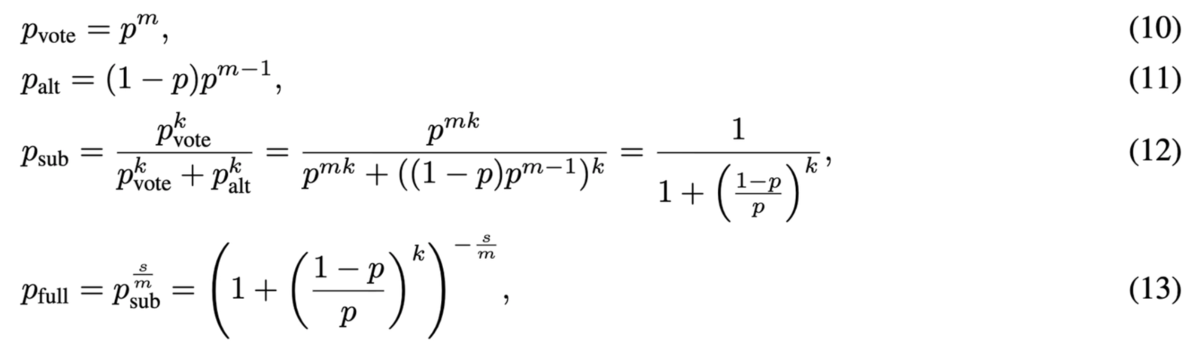 (論文より引用)
(論文より引用)
ここで式(10)は、あるサブタスクは個のステップに分解でき、各ステップの成功確率が
であることから、全てのステップが成功する確率です。これを図示したのが以下のFigure 3です。100万ステップを高い確率で成功するために、
がそこまで大きくならないのは嬉しいですね。
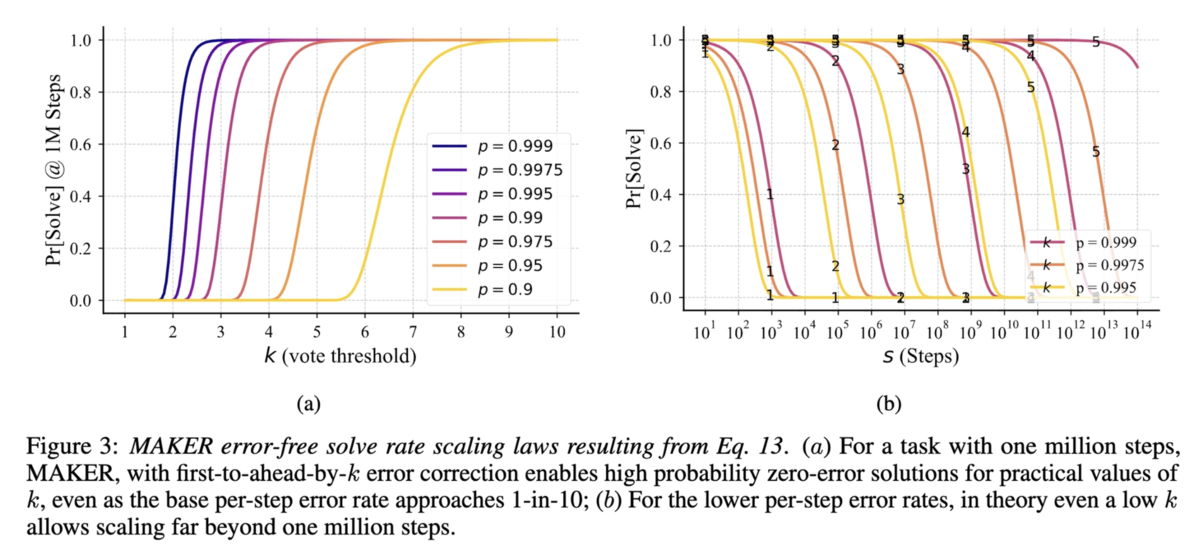 (論文より引用)
(論文より引用)
また、に対するスケーリング則だけでなく、LLMの実行コストも計算できます。
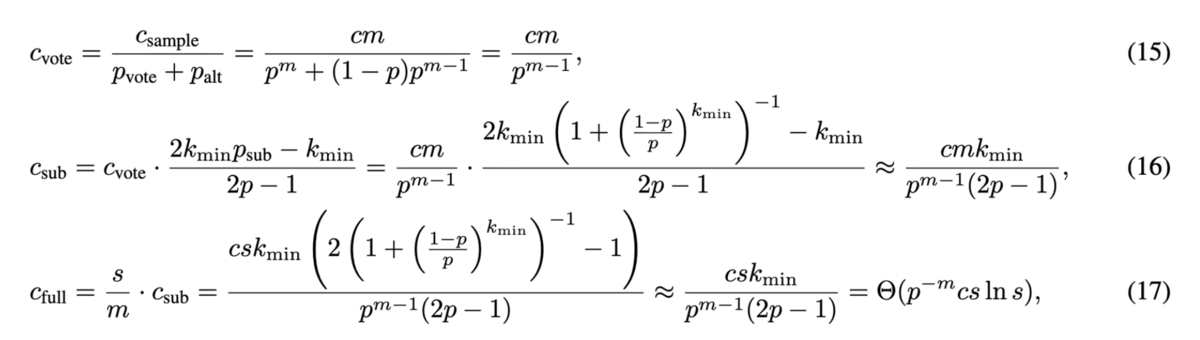 (論文より引用)
(論文より引用)
特に(サブタスクが
個に分解されるので、全
個のステップに分解されるワーストケース)でも、以下のように
でスケールします。
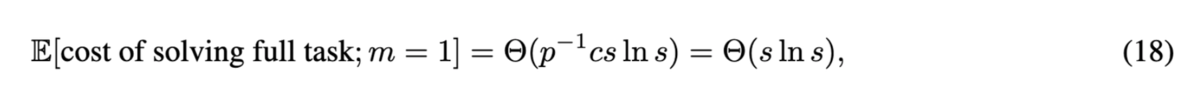 (論文より引用)
(論文より引用)
別の観点として、式(17)は(
は単一ステップあたりのLLMのコストなので、
は成功するために必要なコストの期待値と見なせる)に対しても線形のオーダーとなっていることもわかります。
が最小化されるようなLLMを選択するというのも一つポイントです。
また、を小さくできる点と、コストも
で減衰できる点で、単位ステップの成功確率
を上げる施策も重要です。この論文では信頼性の低い以下2つの兆候をレッドフラグとして利用することにも言及しています。
(1)過度に長い応答
(2)誤ってフォーマットされた応答
こういった「誤りである確率が著しく高い兆候」を見つけたらリトライしてしまうのもLong-running taskの実装では重要なヒューリスティックになる可能性があります。
検証器に求められる「正誤判定」の質
次に紹介するのは、On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks (Kaya Stechly et al.)です。2024年2月の論文で、検証しているモデルもGPT-4と、現在の最新モデルと性能に大きな差があるので、少し割り引いて結果を解釈する必要があるのですが、内容はとても興味深いです。
先ほどの論文では、各ステップの成功確率を上げるためにFirst-to-ahead-by-k Votingやヒューリスティックな誤り検知を採用していましたが、こちらの論文では、LLMによる自己批判と、信頼できる検証器によるフィードバックでLLMが再考することの効果を検証しています。特に信頼できる検証器とは何なのか、具体例があったほうがわかりやすいので本論文で扱っている3つの題材「Game of 24」、「グラフ彩色」、「STRIPSプランニング」で紹介します。
Game of 24は、4つの数字を括弧と基本的な算術演算(加算、乗算、減算、除算)で組み合わせ、計算結果が24になる式を作る数学パズルです(個人的には車のナンバーを四則演算で10にする問題を暇つぶしでやったりします)。LLMによる自己批判は、提示された式が正しいかをLLMに判断させます。信頼できる検証器は、Pythonで24に等しいかどうかを検証させます。プログラムで計算するだけなので、24に等しいかどうかをbooleanで確実に判定できます。
グラフ彩色問題は、エッジで結ばれた隣接するどの2つの頂点も同じ色にならないように、各頂点にn色のうちの1色を割り当てる問題です。こちらもLLMには同じ色になっていないかを判定させます。信頼できる検証器は、すべてのエッジの色を確認するだけで、Game of 24と同じく機械的な正誤判定が可能です。もし、結ばれている2つの頂点が同じ色であるエッジが一つでも存在すれば不正解と判断できます。
STRIPSプランニング(Blocksworld, Mystery Blocksworld)は、離散的で決定論的な空間で実行できる計画を自動立案するものです。こちらはPDDLという計画立案用の言語を用いて、前提条件に違反することなく初期状態から実行でき、最終的にゴールに到達できる一連のアクションとして記述されます。こちらはアクションを順番に実行し、ゴールに到達できるかを検証しています。
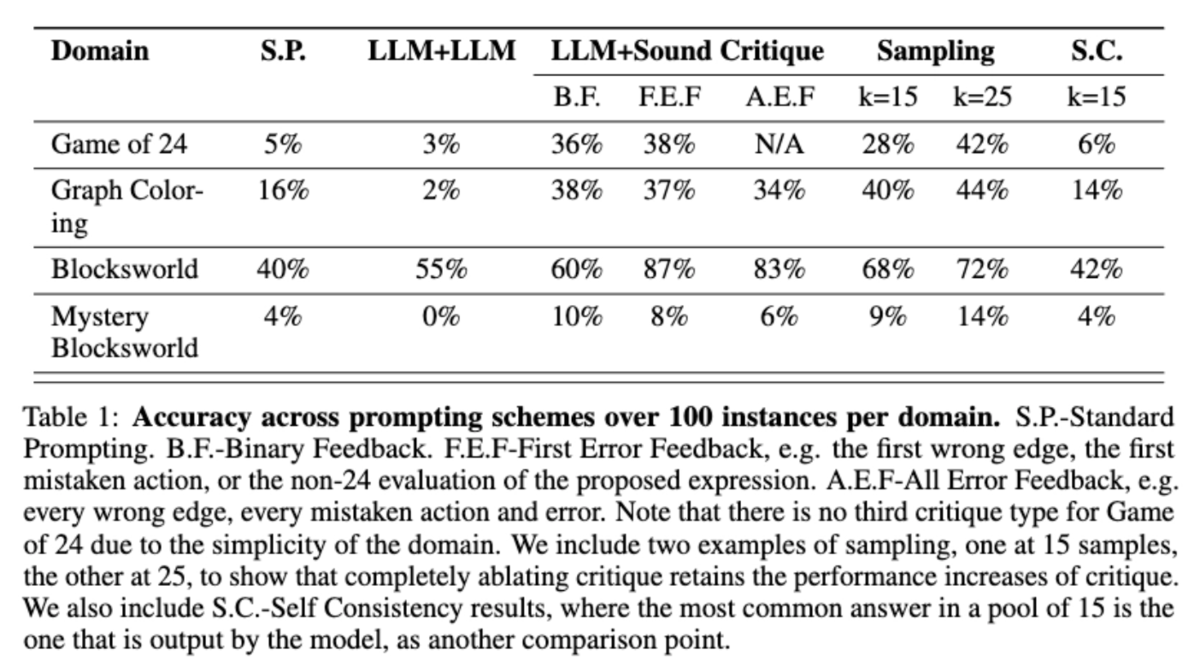
本論文では、これら3つの題材について、n=100で検証を実施しており、結果は以下です。S.P. (Standard Prompting) が標準的なプロンプトで自己批判なしに実行された結果で、ベースラインになるものです。LLM+LLMがLLMによる自己批評です。LLM+Sound Critiqueが上記の「信頼できる検証器」によるもので、B.F. (Binary Feedback)が正解・不正解のフィードバック、F.E.F. (First Error Feedback) が最初にエラーが発生したもののみをフィードバック、A.E.F. (All Error Feedback) が誤りがあったすべてをフィードバックするものです。
 (論文より引用)
(論文より引用)
S.P.とLLM+LLMを見比べると、むしろLLMによる自己批判は悪影響となっていることがわかります。GPT-4でモデル自体の性能が低いことも多分に影響していると思われますが、自己批判そのものが正しくない場合、せっかく正しい回答が出力されていたのに批判することでかえって誤りを導いてしまうようです。また、誤解を招くようなフィードバックを生成することもあり、結果的に再考で正解から遠ざかってしまうことがあるとのことでした。
また、B.F., F.E.F, A.E.F.を見ると、二値のみのフィードバックと内容を含めたフィードバックでは、Blocksworld以外ではさほど差はなく、フィードバックが最初のエラーのみと全てのエラーかでも、全てのエラーのほうがむしろ性能が低下していることがわかります。
注意点として、Game of 24とBlocksworldでは、検証器としてのLLMの精度はそれなりに高く、結果としてLLM+LLMの性能低下が低く抑えられたのではと考察されています。これらを踏まえると、LLMかどうかが課題というよりは、正しいか正しくないかを正確に判定できることが重要、かつ、その中身は問わない(具体的なフィードバックであることよりも誤っていることを正しく誤っているとフィードバックできることが重要)ということが言えそうです。
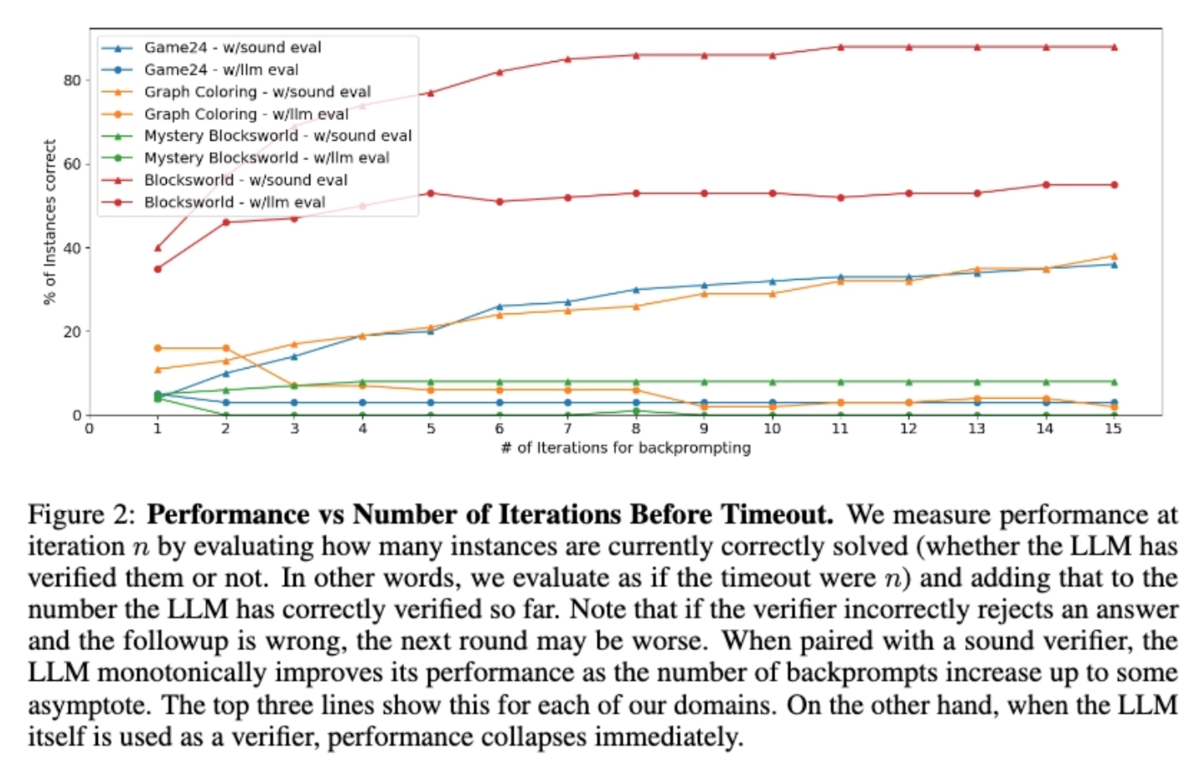
また、反復回数とパフォーマンスについての結果も述べられています。
 (論文より引用)
(論文より引用)
各色ごとに、信頼できる検証器が▲、LLMによる自己批判が●でプロットされていますが、▲が試行を繰り返すことで性能が上がっていくのに対し、●はむしろパフォーマンスが崩壊してしまっており、LLMによる自己批判がマイナスの結果となっています。
相互一致による正しい回答の判定
上記の論文で正しいか正しくないかを正確に判定できることが重要ということがわかりましたが、現実の問題は上記3つの題材のようにルールベースで正しいか判定できない問題もあります。そこで次に紹介したいのが、Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers (Zhenting Qi et al.)です。こちらも2024年8月の論文のため、少し古い点は留意が必要なのですが、アイデアがおもしろかったので紹介します。
こちら論文のモチベーションは、LLMというより、SLM(Small Language Model)を活用することにあります。ただ、SLMは多くの試行を繰り返しても、低品質な推論ステップを含む解空間に陥りがちで、どの最終回答が正しいかを判断することは難しいというissueが述べられています。1つ目に紹介した論文のFirst-to-ahead-by-k Votingもを前提としているので、SLMがこの前提を満たせないとなると、複数回実行しても各ステップが正しい回答にたどり着けなくなってしまいます。
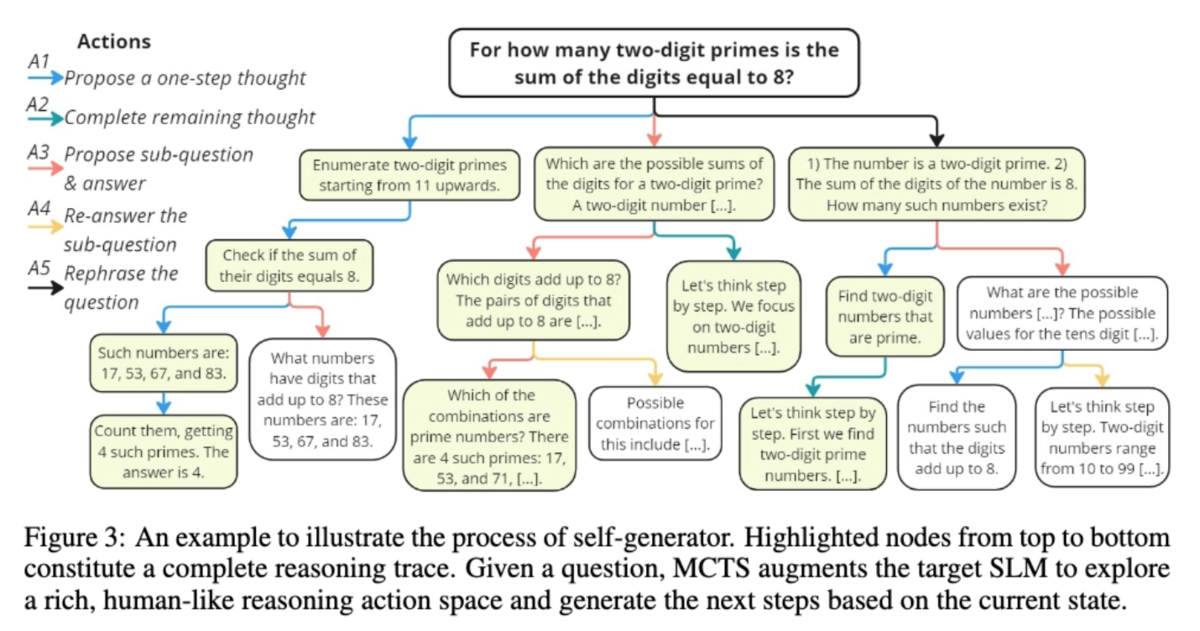
論文では、rStarという手法を提案しており、これは推論ステップをモンテカルロ木探索する手法をベースに相互一致プロセスで拡張しています。具体的には、サンプリングされた部分的な推論軌跡を2つ目のSLMに提示し、残りの推論ステップを完了させるよう促し、rStarは相互に一致した回答に導かれた推論軌跡を高品質であると判断するものです。また、推論ステップが取りうるアクション空間は以下5つとなっています。
- A1: 1ステップの思考を提案
- A2: 残りの思考ステップを提案
- A3: 次の部分問題とその回答を提案
- A4: 部分問題に再度回答
- A5: 問題/部分問題を言い換え
具体的なイメージとしては以下の例がわかりやすいです。
 (論文より引用)
(論文より引用)
この論文は実験結果というよりアイデアがおもしろいので実験結果は省略しますが、複数のSLMが別の軌跡で導いた回答が一致するのであれば、正解の可能性が高いという直感を反映した手法で、応用可能性を感じました。
最後に
ということで、Long-running taskのスケーリング則から、単一ステップの成功確率を上げるために信頼できる検証器や相互一致による判定に関する論文を紹介しました。LLM-as-a-Judgeやアンサンブルによる多数決といった手法はよく見かけますが、それ以外の手法も提案されており、とても興味深い分野です。実務にLLMを組み込もうと思うと、正解が定義できるユースケースほど、精度に苦しむシーンは多いので、今回紹介した内容が何かのお役に立てば嬉しいです。
また、LayerX Ai Workforce事業部では各方面のポジションで採用を行っております。ご興味がありましたら、ぜひお気軽にお声掛けください。
