こんにちは、Hiromu Nakamura (pon) です。 LayerXでMLOpsをやってます!! LayerXではLLMOpsにLangfuseを利用しています。最近、Trace書き込み失敗調査を行い、Langfuseの安定性を向上させました。その際に調べたLangfuseを支える裏側の技術について解説し、実際にどのような対策をしたのかお話しします。
LayerXでのLangfuseをどのように利用しているかについては、既にスライドになっているものがあるのでこちらをご覧ください。
目次
LayerXでのLLMOps
弊社ではAI Agentを使ったLLMOpsにLangfuseを利用しています。Langfuseではトレースの収集だけでなく、プロンプト管理、評価データ管理も行なっています。そのため、トレースからの評価データ生成をしています。また、将来的にトレースのデータをAIのコンテキストとして利用することも考えているため、トレースは非常に重要なデータとなります。
Langfuseのアーキテクチャ
LayerXではLangfuseをAWS Fargate で実現したクラスタ構成でセルフホスト運用しています。

Langfuse はオートスケールによる複数台構成、ClickHouse は2台、ClickHouse Keeper は3台で構築しています。
詳しくは次のブログをご覧ください
TraceがDropする問題
ある日から次のようなエラーが大量に出るようになりました。
Max attempts reached for * record. Dropping record.
先ほど、お話ししたように、Langfuseのトレースは、事業にとって重要であるため、トレースの書き込み失敗は許容できない問題です。
各種コンポーネントのリソースを見るとCPU、メモリも余裕です。次のグラフはClickHouseの実際のリソースです。


ネットワークのメトリクスも問題はなく、ただただ、書き込みに失敗します。 たかだか数百リクエストでも上記のエラーが発生しておりこれは非常に問題です。
当然、Langfuseのワーカーのリソースも余裕です。でもなぜかタイムアウト or 書き込み失敗によるdropが発生していました。
また次のようなエラーも出ていました。
ClickhouseWriter.writeToClickhouse Error: Timeout error.
auto DB::StorageReplicatedMergeTree::processQueueEntry(ReplicatedMergeTreeQueue::SelectedEntryPtr)::(anonymous class)::operator()(LogEntryPtr &) const: Poco::Exception. Code: 1000, e.code() = 0, Timeout
ClickHouseへの書き込み失敗と共に、MergeTreeなるタスクが失敗しています。このようにHTTPのTimeoutが大量に発生していました。Geminiなどに相談してもネットワークが不安定だからとしか返ってきません。しかし、Direct Connectを採用しており、そんなに不安定な通信になっているとは考えづらいです。
そこで残るはファイルシステムです。実際にEFSのメトリクスを見ると、面白いことが発見できます。

上図の緑がmetadataのオペレーションで、青がdata write、オレンジがdata readです。 スループットのほとんどを使い切っており、中でも、metadataのスループットが多いです。これにより、EFSのIOが詰まり、その間にHTTPタイムアウトが連発していました。
よってEFSの問題だとわかりました。LayerXではEFSのmodeはBursting Throughputを採用しており、容量に対してIOが多いため、今回の問題が発生していました。Bursting Throughputはファイルシステムのストレージ容量にスループットがスケールするため、今回のようにデータ量から想定されるIOよりも実際のIOが多い場合は問題になります。
Amazon EFS のパフォーマンス仕様についてはこちらをご覧ください。 docs.aws.amazon.com
Bursting Throughputでは、1 GiB あたり 50 KiBpsです。エラーが出ていたときはまだ数GiBだったので、スループットも数百KiBpsです。ClickHouseでは裏での定期処理が多く、metadata含むファイルシステムのオペレーションが定期的に発生します。そのため、大量のobservationを含んだ大きなトレースをwriteしようとするともう限界です。
よって、Elastic Throughputに変更することで、問題が解決しました。今まで、metadataのIOに支配されていたスループットが、modeを切り替えた時間を境にData Writeに使えるようになっているのを確認できます。これで正しくトレースがwriteできるようになりました。

これで対応は終わりですが、当初想定されていたmetadataのオペレーションよりも多いのが気になります。しかもこれは定常的に発生しています。内部でどのような処理が行われているのでしょうか。そこで、調査をここで終わることなく、裏側で何が起きているのかをDeep Diveしてみました。
Dive into ClickHouse
ClickHouseは列志向データベースであり、集計などオンライン分析処理(OLAP)に最適化されたDBです。
今回はレプリケーションやトレースの書き込みでエラーが発生していたため、その辺の挙動を調査しました。ClickHouseがどのようにデータを格納しているかについては次の記事が詳しいので、さらに深掘りたい人はこちらを参照してください。特に複合インデックスでパフォーマンスが落ちる話は必見。
ClickHouseではInsertを受けると、Partという単位でデータを格納します。一気にinsertするのではなく、一度Bufferに格納することで、前もってデータをソートして格納するなどの前処理ができるようになっています。

Partを作る際にはデータをソートし、カラムに分けてインデックス情報と共にPartとして保存します(下図)。これらは全てのちの分析時にパフォーマンスを担保するためです。特にソートすることにより、インデックス情報からどのファイルに必要なデータが格納されているかが計算しやすくなっています。
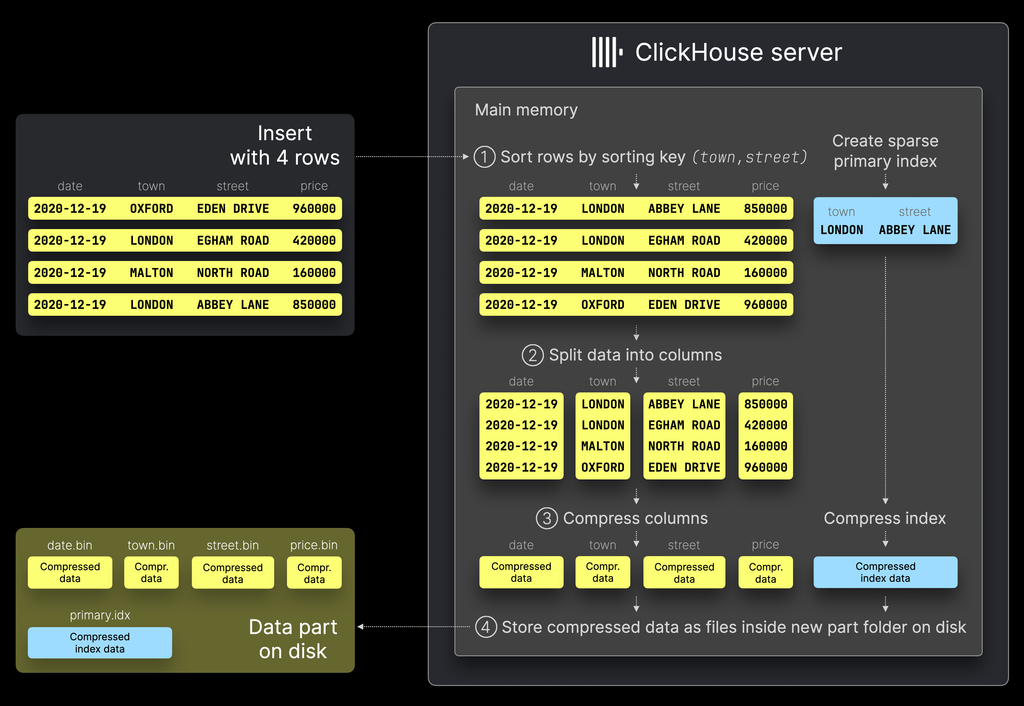
上の図の③Compress columnsのステップでは、granuleという単位にデータを分け(下図)、primary.idxというファイルにどの範囲のデータがあるかを保存しておくことで、高速なデータアクセスを実現しています。

実際にデータにアクセスするときにはmarkというデータを利用します。markはカラムごとに作られる、保存したgranuleの場所を辿りやすくするためのデータです。block_offsetがカラムデータファイルのブロック位置であり、そのブロックのどこにgranuleがあるかを指しているのがgranule_offsetです(下図)。

そのためレプリケーション時には次のデータを送信する必要があります。
- カラムデータファイル:
column_name.bin形式の圧縮されたデータ - インデックスファイル:
primary.idxなどのプライマリキーインデックス - マークファイル:
column_name.mrk2などの行位置マーカー - (メタデータファイル:
checksums.txt,columns.txtなどのパーツ記述情報)
また、partsのマージも定期的に発生します。ファイルシステムもこれを想定してスループットを確保する必要があります。

このようにClickHouseではレプリケーション、マージといった非同期処理が発生します。レプリケーション時には、このPartsをHTTP経由でレプリケーションするため、ネットワークスループットも気をつける必要があります。
今回の場合はネットワークのタイムアウトより、ファイルシステムのタイムアウトが長く設定されていたのが根本の問題に気づきにくい原因でした。
ECSのEFSマウントでデフォルト設定(timeo=600、retrans=2)の場合、以下のようにタイムアウトします:
0秒 : 初回リクエスト送信 6秒後 : 1回目タイムアウト → 1回目リトライ送信 18秒後 : 2回目タイムアウト → 2回目リトライ送信 42秒後 : 3回目タイムアウト → エラー返却
そのためHTTPタイムアウトに設定している30sより長いため、ファイルIOより先にタイムアウトしたため、レプリケーション時のParts受信側がタイムアウトで接続を切ったと考えることができます。そのため、多くのTimeoutエラーが出ていました。
EFSのメトリクスを見て、とりあえずスループットを上げる対応をするだけではなく、なぜClickHouseのメタデータ処理が多いのか、内部でどのような定期処理が行われているのかを知ることで、スループットを上げる必要があることに確信を持てました。
まとめ
Langfuseなどの裏側で動いている処理を具体的に知ることで、パフォーマンス改善、安定性を上げるときにどこに目をつければ良いかの調査が非常にしやすくなりました。ログやメトリクスだけを見て対応を想像するのではなく、実際に裏側を理解することで、確信を持った根本解決ができるようになります。
LayerXではAIで全ての経済活動をデジタル化する仲間を募集しています。LLMを使って終わりではない難しいチャレンジが溢れています。AI Agentの信頼性あるデプロイにはソフトウェアエンジニア力が必要です。是非カジュアルにお話ししましょう。
ここから僕につながります! jobs.layerx.co.jp
