0. はじめに
LayerX Ai Workforce事業部でR&Dチームマネージャーの澁井(しぶい)と申します。
実業務でLLMやAIエージェントを活用するときに頻繁に課題になることとして、作ったLLM/AIエージェントシステムを評価するデータが足りない、ということがあります。こうした課題に対処するため、LLMやAIエージェントを用いて合成データを作ることは一般的なプラクティスと言えます。しかし、必要な品質の合成データを大量かつ多様に作ることは相応に難しく、エンジニアリングが伴います。
本テックブログでは、合成データの作り方に関するTips集を紹介します。このTipsが読者の合成データ作成に貢献できると幸いです。
1. 合成データとは何か? AIエージェント時代に注目される理由
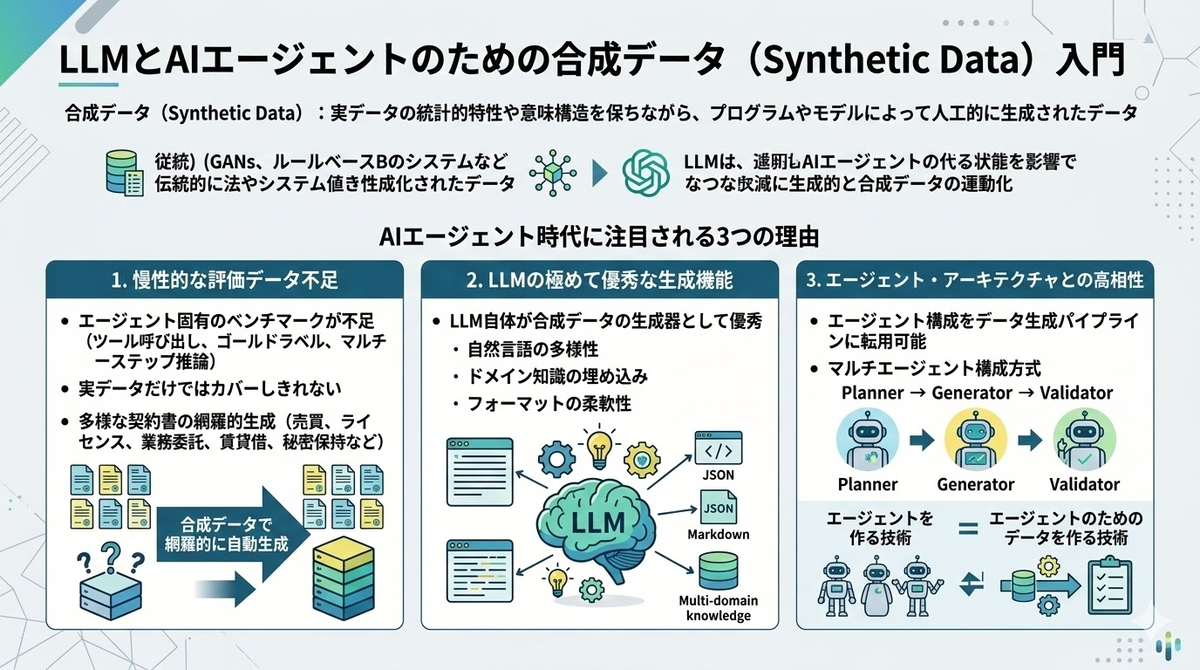
合成データ(Synthetic Data)とは、実データの統計的特性や意味構造を保ちながら、プログラムやモデルによって人工的に生成されたデータのことです。従来は GAN やルールベースの手法が主流でしたが、LLM の登場で状況が一変しました。
AIエージェント時代に注目される理由は3つあります。
第一に、エージェントの評価データが慢性的に不足している点です。ツール呼び出しの成否判定、マルチステップ推論のゴールドラベルなど、エージェント固有のベンチマークは実データだけではカバーしきれないことが多いでしょう。たとえば「契約書の条項抽出」タスクでも、世の中には多様な種別の契約書(売買契約書、ライセンス契約書、業務委託契約書、賃貸借契約書、秘密保持契約書、等々)が多様なフォーマットで存在し、網羅的なパターンの実データを用意することは工数がかかります。合成データであれば網羅的に自動生成できます。
第二に、LLM 自体が合成データの生成器として極めて優秀であるという点です。自然言語の多様性、ドメイン知識の埋め込み、フォーマットの柔軟性――これらを一つのモデルで同時に扱える生成器は LLM 以前には存在しませんでした。
第三に、AIエージェントのアーキテクチャそのものが合成データパイプラインと相性が良い点です。Planner → Generator → Validator のようなマルチエージェント構成は、そのままデータ生成ワークフローに転用できます。つまり「エージェントを作る技術」と「エージェントのためのデータを作る技術」が同一のスキルセットで完結します。
2. Pydantic × LLM で型安全な合成データを生成
合成データの品質を安定させるうえで最も効果的なのが、出力スキーマを Pydantic モデルで厳密に定義し、LLM の出力をバリデーションにかけるパターンです。
2.1 基本構成
from pydantic import BaseModel, Field, field_validator from openai import OpenAI import json class SyntheticTicket(BaseModel): """カスタマーサポートチケットの合成データスキーマ""" ticket_id: str = Field(pattern=r"^TKT-\d{6}$") category: str = Field(description="問い合わせカテゴリ") severity: int = Field(ge=1, le=5) customer_message: str = Field(min_length=20, max_length=500) expected_action: str = Field(description="エージェントが取るべきアクション") requires_escalation: bool
2.2 Responses API の Structured Outputs で型安全を API レベルで保証する
従来は LLM の出力を自前でパースし、バリデーションエラー時にリトライするループを書く必要がありました。しかし OpenAI の Responses API が提供する Structured Outputs 機能を使えば、API 側がスキーマ準拠を保証してくれます。
Pydantic の BaseModel をそのまま text_format パラメータに渡すだけで、レスポンスがパース済みのオブジェクトとして返ってきます。
from pydantic import BaseModel, Field, field_validator from openai import OpenAI client = OpenAI() def generate_ticket(prompt: str) -> SyntheticTicket | None: """Responses API + Structured Outputs による型安全な生成""" response = client.responses.parse( model="gpt-5.2", input=[ { "role": "system", "content": ( "あなたは合成データジェネレータです。" "指示に従い、リアルなカスタマーサポートチケットを生成してください。" ), }, {"role": "user", "content": prompt}, ], text_format=SyntheticTicket, ) # モデルが安全性の理由で拒否した場合のハンドリング if response.output_parsed is None: # refusal が返された場合 for item in response.output: if hasattr(item, "refusal") and item.refusal: print(f"モデルが生成を拒否しました: {item.refusal}") return None return response.output_parsed # 使用例 ticket = generate_ticket( "日本語で、配送遅延に怒っている顧客のチケットを生成してください。" "severity は 4 以上にしてください。" ) if ticket: print(ticket.model_dump_json(indent=2))
2.3 Tips: スキーマ設計のコツ
Field(description=...)を必ず書く: LLM はスキーマのdescriptionフィールドを手がかりに出力を生成します。説明が丁寧なほど出力品質が上がります。Literal型で選択肢を制限する:category: Literal["billing", "shipping"]のように書くと、JSON Schema 上でenumとして表現されるため LLM が逸脱しにくくなります。- ネストモデルを活用する: 複雑なデータは
BaseModelをネストして構造化しましょう。フラットな JSON よりも LLM が構造を理解しやすくなります。 model_json_schema()の出力をそのまま渡す: 手書きでスキーマを説明するよりも、Pydantic が生成した JSON Schema を直接プロンプトに含めるほうが正確です。
3. 答えから合成データを作る ― 逆方向生成
合成データ生成でもっとも見落とされがちで、かつ強力なテクニックが逆方向生成です。
3.1 なぜ「答え」を先に作るのか
通常の発想では「ドキュメントを作り、それに対する正解を作る」と考えます。しかし、LLM がドキュメントを生成した後に正解ラベルを抽出しようとすると、ドキュメントの曖昧性によって正解が一意に定まらないケースがあります。
逆方向生成では、先に「処理結果(正解)」を確定させ、その正解が自然に導出されるようなドキュメントを後から合成します。
3.2 具体例: 請求書データの抽出タスク
【Step 1: 正解の定義】
{
"vendor_name": "AAAAAAA",
"invoice_number": "INV-2025-003847",
"total_amount": 1254000,
"tax_amount": 114000,
"line_items": [
{"description": "クラウド基盤構築費", "quantity": 1, "unit_price": 800000},
{"description": "運用保守(月額)", "quantity": 3, "unit_price": 120000},
{"description": "セキュリティ監査", "quantity": 1, "unit_price": 94000}
]
}
【Step 2: 正解に整合するドキュメントの合成】
→ LLM に「上記の構造化データが抽出結果として正しくなるような
請求書のテキスト(レイアウト崩れ・表記ゆれを含む)を生成せよ」と指示。
3.3 プロンプト設計のポイント
逆方向生成プロンプトでは、ドキュメントに意図的なノイズを注入する指示が鍵になります。
以下の構造化データから、現実の請求書テキストを生成してください。 制約: - 金額表記は「¥1,254,000」「1,254,000円」「¥1254000」のいずれかをランダムに使用 - 品目名は微妙に異なる表現(例:「クラウド基盤構築」→「クラウドインフラ構築作業」)を含めてよい - 会社名にはふりがなや英語表記を併記するケースを20%の確率で含める - フッターに無関係な定型文(振込先情報、免責事項など)を追加する - 行の順序は元データと異なってもよい
このアプローチの利点は「正解ラベルの正確性が保証された状態で、入力側の多様性だけを自由に拡張できる」ことにあります。
3.4 応用: 要約タスクへの適用
要約タスクでは「理想的な要約」を先に定義し、その要約が正当化される元文書を合成します。
Step 1: 要約 = "2025年Q1の売上は前年比12%増。主因はAPAC市場でのSaaS契約増加。"
Step 2: → 上記要約の根拠となるような四半期報告書のセクションを生成。
副次的な話題(人事異動、設備投資)も含めて情報量を膨らませる。
4. 異常検知モデル向けに「異常パターン」だけを狙って合成するエージェント設計
4.1 課題: 正常データは豊富だが異常データが極端に少ない
異常検知では、正常:異常 = 99:1 以下の極端な不均衡が一般的です。単純に「異常データを作って」と LLM に頼むと、パターンが単調になりがちでしょう。
4.2 分類体系ドリブンデータ合成
有効なのが、異常パターンの分類体系(Taxonomy)を先に設計し、それに基づいて生成を制御する方法です。そのために以下のように各フェーズでエージェントを用意します。
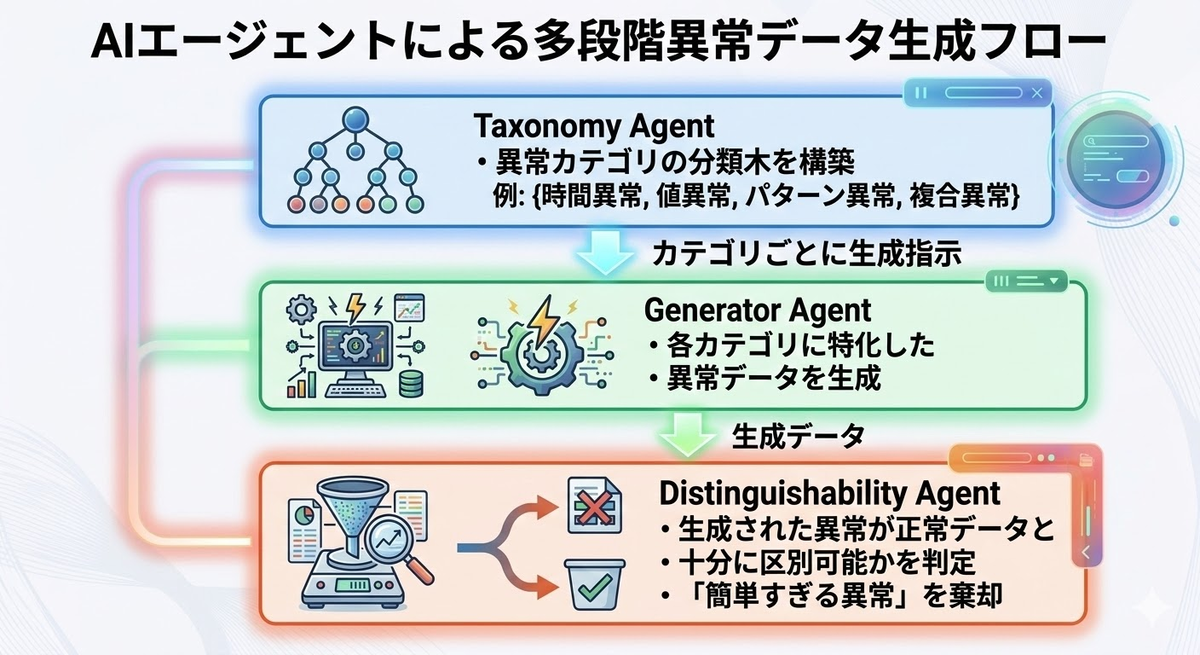
4.3 Taxonomy Agent による異常カテゴリの自動設計
Taxonomy Agent の役割は、ドメイン知識と正常データの特徴を入力として、「どんな種類の異常がありえるか」を体系的に洗い出すことです。人間が手動でカテゴリを設計するとどうしても既知の異常に偏るため、LLM のドメイン知識を活用して分類木を自動生成させます。もちろん、人間の既知の情報を補足として与えることで、より品質の高い分類木が作れるでしょう。
TAXONOMY_PROMPT = """
あなたは{domain}ドメインの異常検知の専門家です。
以下の正常データの特徴量サマリを分析し、
発生しうる異常パターンの分類木(Taxonomy)を設計してください。
正常データの特徴:
{normal_stats}
以下の軸で異常を分類してください:
1. 値の異常(範囲逸脱、統計的外れ値、物理的にありえない値)
2. 時間の異常(頻度変化、周期性の崩壊、時系列の逆転)
3. パターンの異常(通常と異なるシーケンス、欠損パターン)
4. 関係性の異常(フィールド間の相関崩壊、因果関係の逆転)
5. 複合異常(上記の組み合わせ)
各カテゴリについて以下を出力してください:
- category_name: カテゴリ名
- description: どのような異常か
- subtypes: 具体的なサブタイプ(最低3つ)
- generation_hint: この異常を生成する際の具体的な指示
- real_world_example: 現実世界でこの異常が発生するシナリオ
- estimated_difficulty: trivial / subtle / ambiguous(正常との区別しやすさ)
"""
たとえば製造業の品質検査データに対してこのプロンプトを実行すると、以下のような分類木が生成されるとします。
異常 Taxonomy(製造業・品質検査)
├── 値の異常
│ ├── 測定値の範囲逸脱(温度が設定上限+50℃)── trivial
│ ├── 微妙なドリフト(温度が1時間で0.5℃ずつ上昇)── subtle
│ └── センサー固着(同一値が100回連続)── subtle
├── 時間の異常
│ ├── 検査間隔の異常(通常5分間隔が30秒に)── trivial
│ ├── 夜間の異常活動(通常稼働しない時間帯のデータ)── subtle
│ └── タイムスタンプの逆転(前のレコードより過去の日時)── trivial
├── パターンの異常
│ ├── 工程順序の逸脱(工程Bの前に工程Cが記録)── subtle
│ ├── 通常セットで現れる測定値の一部欠損 ── subtle
│ └── 同一ロットでの品質値のばらつき急増 ── subtle
├── 関係性の異常
│ ├── 温度と圧力の相関崩壊(通常は正相関なのに無相関に)── subtle
│ └── 投入量と産出量の比率異常 ── subtle
└── 複合異常
├── 微妙なドリフト + 工程順序の逸脱 ── subtle
└── 夜間活動 + センサー固着 ── ambiguous
この分類木を得ることで、Generator Agent は「値の異常 > 微妙なドリフト」のように特定のサブタイプに焦点を当てた生成が可能になります。
4.4 Generator Agent のカテゴリ別生成戦略
Generator Agent は Taxonomy の各カテゴリに対して異なる生成戦略を取ります。
pythonCATEGORY_GENERATION_PROMPT = """
以下の正常データのサンプルを参考に、
指定された異常カテゴリに該当するデータを生成してください。
正常データサンプル(参考):
{normal_samples}
生成する異常カテゴリ:
- カテゴリ: {category_name}
- サブタイプ: {subtype}
- 説明: {description}
- 生成ヒント: {generation_hint}
制約:
- 正常データのスキーマ(フィールド名、型)は完全に維持すること
- 異常はこのカテゴリのサブタイプに限定し、他の異常を混入させないこと
- 異常の根拠となるフィールドを `anomaly_fields` として明示すること
- 現実に起こりうるシナリオとして自然であること
出力:
- data: 生成された異常データ(正常データと同じスキーマ)
- anomaly_fields: 異常が含まれるフィールド名のリスト
- anomaly_description: この異常が何を表しているかの説明
"""
ここで重要なのが、1回の生成で1カテゴリ・1サブタイプに限定するという制約です。複数の異常を同時に含めると、モデルの学習時にどの特徴が異常を示しているのか曖昧になります。複合異常は、単一異常のパターンを十分に生成した後に、意図的に組み合わせて作ります。
もう一つのポイントは anomaly_fields の明示です。これは逆方向生成と同じ考え方で、異常の正解ラベルを生成時点で確定させることで、後工程のアノテーションを不要にしています。
4.5 Distinguishability Agent で「ちょうど難しい」異常を選別する
異常検知モデルの学習には「境界付近の異常」が最も価値があります。Distinguishability Agent はこの難易度調整を担います。
pythonDISTINGUISHABILITY_PROMPT = """
以下の正常データの統計的特徴と、生成された異常データを比較してください。
正常データの特徴:
{normal_stats}
生成された異常データ:
{anomaly_sample}
以下の基準で判定してください:
1. trivial(正常と明らかに異なる → 学習価値が低い)
2. subtle(正常と紛らわしいが異常の根拠がある → 最も学習価値が高い)
3. ambiguous(正常と区別できない → 異常として不適切)
判定結果と根拠を出力してください。
"""
subtle と判定されたデータだけを採用することで、モデルの決定境界付近を効率的に学習させられます。 ただし、trivial なデータも完全に捨てるわけではありません。学習データセット全体の構成としては、subtle を中心としつつ trivial も一定割合(10-20%程度)混ぜるのが効果的です。trivial なデータはモデルの学習初期段階で「異常とは何か」の大まかな境界を学習するのに役立ちます。
5. 合成データの品質と多様性をどう測る? AIエージェントによる自動評価
5.1 品質の三軸
合成データの品質は以下の三つの軸で評価します。
忠実性(Fidelity): 個々のデータポイントが現実的かどうかです。たとえば「東京都の郵便番号が 100-0001 の範囲内か」「日本語として自然な文章か」などが該当します。
多様性(Diversity): データセット全体がどれだけ広い分布をカバーしているかです。同じパターンの繰り返しが多いとモデルが過学習します。
有用性(Utility): 生成したデータで学習したモデルが、実データのテストセットでどの程度のパフォーマンスを出すかです。最終的にはこれが唯一の正解指標になります。
5.2 LLM-as-a-Judge による忠実性評価
FIDELITY_JUDGE_PROMPT = """ あなたはデータ品質の審査員です。以下の合成データが現実のデータとして 自然かどうかを 1-5 のスケールで評価してください。 評価基準: - 5: 実データと区別がつかない - 4: 些細な不自然さがあるが実用上問題ない - 3: 不自然な点があるが修正可能 - 2: 明らかに不自然だが構造は正しい - 1: 非現実的でデータとして使用不可 合成データ: {synthetic_record} ドメイン知識(参考): {domain_context} score: <1-5の整数> reasoning: <判定根拠> fixable: <true/false> fix_suggestion: <修正案(fixable=trueの場合)> """
5.3 多様性の定量評価
LLM ベースの多様性評価で有効なのが、セマンティッククラスタリングと自己類似度スコアの組み合わせです。
from sentence_transformers import SentenceTransformer from sklearn.metrics.pairwise import cosine_similarity import numpy as np def diversity_score(texts: list[str]) -> dict: model = SentenceTransformer("all-MiniLM-L6-v2") embeddings = model.encode(texts) sim_matrix = cosine_similarity(embeddings) n = len(texts) mask = ~np.eye(n, dtype=bool) avg_similarity = sim_matrix[mask].mean() return { "avg_pairwise_similarity": float(avg_similarity), "diversity_index": float(1 - avg_similarity), # 高いほど多様 "num_samples": n, }
diversity_index がしきい値(例:0.3)を下回る場合、生成プロンプトの多様性が不足しているサインです。ペルソナの追加や条件分岐の導入を検討しましょう。
5.4 有用性(Utility)の評価 ― 合成データは本当に「使える」のか
忠実性と多様性が高くても、実タスクの性能向上に寄与しなければ意味がありません。有用性の評価には、コストと信頼性の異なる3つのアプローチがあります。
機械学習やAIの学習用途であれば、TSTR(Train-on-Synthetic, Test-on-Real) が重要です。合成データで学習したモデルを実データのテストセットで評価し、実データで学習した場合のスコア(TRTR)との比率を取ります。この比率が 0.9 を超えていれば、合成データは実用上十分な品質と言えます。ただし学習パイプラインを毎回回す必要があるため、マイルストーンごとの最終判定として使うのが現実的です。
LLM-as-a-Judge は日常的なスクリーニングに向いています。合成データが下流タスクに寄与しそうかを LLM に 1-5 スケールで判定させます。この際、「実データには存在するが合成データに欠けているパターン」と「悪影響を与えそうなパターン」の両面を出力させると、改善アクションに直結しやすくなります。
エージェント成功率による代理指標 はエージェント開発に特化したアプローチです。合成シナリオ上でエージェントを実行し、カテゴリ別の成功率を計測します。カテゴリ間の成功率のばらつきが大きい場合、低成功率カテゴリの合成データに質的な問題があるサインです。
有用性が低い場合は、忠実性スコア・多様性スコアとセットで見て原因を切り分けます。
6. 合成データのバイアス検出をエージェントに任せる方法
6.1 なぜ合成データにもバイアスが生じるのか
LLM は学習データの分布を反映するため、合成データにも系統的な偏りが混入します。典型的なバイアスは以下の通りです。
- 属性バイアス: 名前を生成すると特定の国や地域の名前に偏ります
- 言語バイアス: フォーマルな文体に偏り、口語やスラングが不足します
- シナリオバイアス: ポジティブな結末に偏り、失敗ケースが不足します
- 数値バイアス: 「丸い数字」(100, 500, 1000)に集中します
6.2 Bias Auditor Agent の設計
BIAS_AUDIT_PROMPT = """ あなたはデータバイアスの監査エージェントです。 以下の合成データセット({n}件)を分析し、系統的な偏りを検出してください。 検出すべきバイアスの種類: 1. 属性分布の偏り(性別、年齢、地域、名前の民族性など) 2. 数値分布の偏り(特定の値域への集中、丸い数字への偏向) 3. テキスト多様性の偏り(語彙の貧困、文体の均一性) 4. シナリオの偏り(成功/失敗比率、ポジティブ/ネガティブ比率) 5. 時間的偏り(特定の曜日・時間帯への集中) データセット: {dataset_sample} 出力フォーマット: - bias_type: 検出されたバイアスの種類 - severity: low / medium / high - evidence: 偏りの具体的な数値・例 - remediation: 修正方法の提案 """
6.3 バイアス修正の自動化
検出されたバイアスに対して、Generator Agent に修正指示を出すフィードバックループを構築します。
def debias_loop(dataset, max_iterations=3): for i in range(max_iterations): audit = bias_auditor.run(dataset) high_severity = [b for b in audit.biases if b.severity == "high"] if not high_severity: break for bias in high_severity: supplemental = generator.run( constraints=bias.remediation, count=len(dataset) // 10 ) dataset = dataset + supplemental return dataset
Tip: バイアス修正でデータを追加すると、別の軸でバイアスが生じる可能性があります。反復ごとに全軸を再監査するのがポイントです。
7. Planner / Generator / Validator の三層エージェント構成で合成データ品質を上げる
7.1 三層構成の全体像
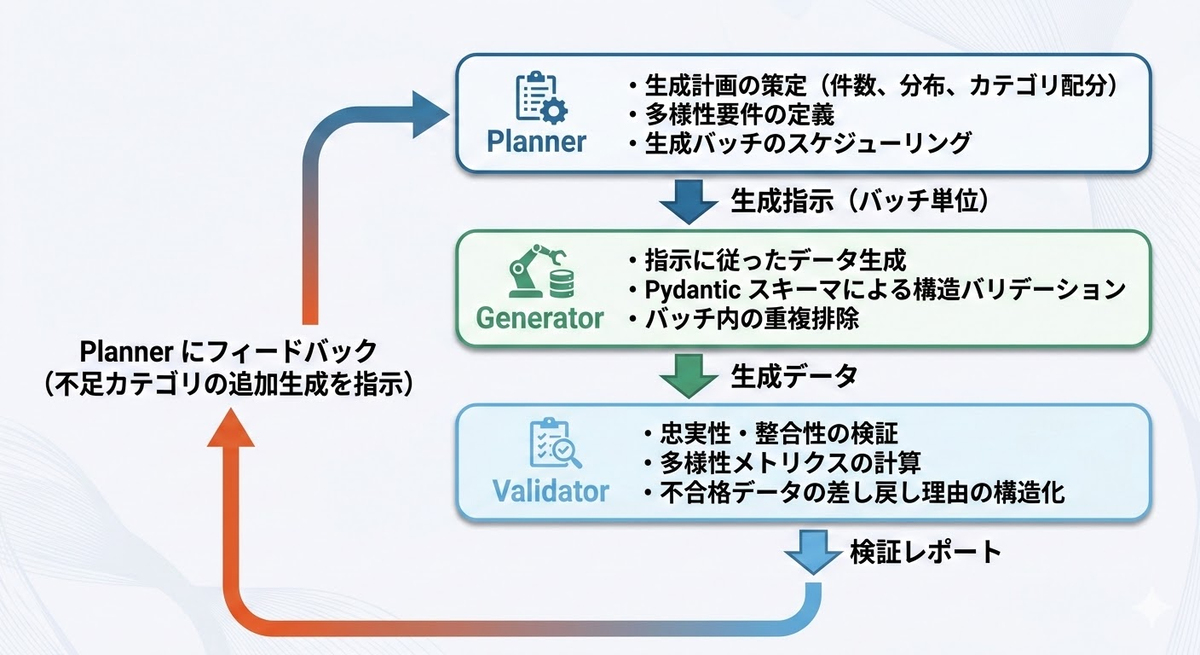
7.2 Planner の設計
Planner はデータセット全体の「設計図」を描きます。重要なのは、生成を一括で行うのではなく、バッチ分割して逐次的に多様性を確保する点です。
PLANNER_PROMPT = """ 以下の要件に基づき、合成データの生成計画を作成してください。 目標: カスタマーサポートチケット 1000件 カテゴリ分布: billing(30%), shipping(25%), product_defect(20%), account(15%), other(10%) 重症度分布: severity 1-5 が均等分布 言語: 日本語 80%, 英語 20% 計画はバッチ単位(各50件)で作成してください。 各バッチには以下を含めてください: - 対象カテゴリと件数 - 特に含めるべきエッジケース - 前バッチの Validator レポートを踏まえた修正指示 """
7.3 Validator の差し戻し判定
Validator は単に合格/不合格を出すだけでなく、不合格データの「修正コスト」を推定します。修正コストが高いデータは再生成、低いデータは LLM による自動修正に回します。
class ValidationResult(BaseModel): record_id: str is_valid: bool issues: list[str] fix_cost: Literal["low", "medium", "high"] # low: 自動修正可能, medium: 部分再生成, high: 全体再生成
7.4 Tips: 三層構成の運用ノウハウ
- Planner にデータセット全体の統計を見せる: バッチごとに現時点のデータセット統計を渡すことで、不足領域を自動的に補填できます。
- Generator のモデルと Validator のモデルを変える: Generator に Haiku、Validator に Sonnet を使うといったコスト最適化が可能です。
- Validator の合格率をモニタリングする: 合格率が 70% を下回ったらプロンプトに問題があります。90% 以上なら Validator の基準が緩すぎる可能性を疑いましょう。
8. エージェントに「ペルソナ」を与えてリアルな利用者や業界のデータを合成する
8.1 ペルソナ注入の効果
LLM に「あなたは30代の営業マネージャーです」と役割を指示するだけで、語彙選択、関心事、行動パターンがそのペルソナに沿ったものに変化します。これを合成データ生成に応用すると、ユーザーセグメントごとにリアルなデータを生成する手助けとなります。
8.2 ペルソナ定義のテンプレート
ペルソナは曖昧な人物像ではなく、データ生成に直結する属性を明示的に定義します。
class Persona(BaseModel): """合成データ生成用ペルソナ""" role: str # "製造業の品質管理エンジニア" experience_years: int tech_literacy: Literal["low", "medium", "high"] communication_style: str # "簡潔で技術用語を多用" typical_goals: list[str] # ["不良率の低減", "検査工程の自動化"] common_frustrations: list[str] # ["レガシーシステムとの連携"] vocabulary_hints: list[str] # ["SPC", "Cp値", "工程能力指数"] error_patterns: list[str] # ["専門略語の過多", "前提知識の省略"]
8.3 ペルソナ × シナリオのマトリクス生成
ペルソナ単体よりも、ペルソナとシナリオを掛け合わせたマトリクスが強力です。
personas = [
Persona(role="新卒エンジニア", tech_literacy="medium", ...),
Persona(role="CTO", tech_literacy="high", ...),
Persona(role="非技術職の営業", tech_literacy="low", ...),
]
scenarios = [
"本番環境でエラーが発生した",
"新機能の要件を整理したい",
"パフォーマンスの劣化を調査したい",
]
for persona in personas:
for scenario in scenarios:
prompt = f"""
あなたは「{persona.role}」です。
技術リテラシー: {persona.tech_literacy}
コミュニケーションスタイル: {persona.communication_style}
よく使う用語: {', '.join(persona.vocabulary_hints)}
以下の状況で、社内チャットツールに投稿するメッセージを生成してください:
状況: {scenario}
このペルソナらしい語彙・文体・情報の粒度で書いてください。
"""
8.4 業界特化ペルソナの自動生成
ペルソナ自体を LLM に生成させることで、自分のドメイン知識の限界を超えたペルソナを獲得できます。
PERSONA_GENERATOR_PROMPT = """ {industry}業界において、以下の条件でペルソナを5つ生成してください。 条件: - 職種・役職は重複させない - 技術リテラシーのレベルをばらけさせる - 各ペルソナは最低3つの「ありがちな困りごと」を持つ - その業界特有の専門用語をvocabulary_hintsに含める 出力は以下の形式に従ってください: {schema} """
8.5 Tips: ペルソナベース生成の落とし穴
- ステレオタイプの増幅: 「新卒 → 技術力が低い」のような紋切り型になりがちです。意図的に反ステレオタイプのペルソナを混ぜましょう。
- ペルソナ間の一貫性: 同一ペルソナから生成したデータ群の中で文体や語彙が一貫しているかを Critic Agent でチェックします。
- ペルソナ数の目安: データセットサイズの 5-10% 程度のユニークペルソナがあると多様性と一貫性のバランスが取れます。
9. 合成データを作る Agent Skill を Agent Skill で作る ― メタ Agent Skill による統一制御
ここまでのセクションでは「1件のデータをいかに高品質に作るか」に焦点を当ててきました。しかし現実のプロジェクトでは、互いに関連する複数のドキュメントを、共通のテーマ・フォーマット・世界観のもとで一括合成する必要があります。たとえば以下のようなケースです。
- ある架空企業の「就業規則」「出張旅費規程」「情報セキュリティポリシー」を整合性を保って同時に生成したい
- 患者 100 名分の「診療録」「検査結果」「処方箋」を、同一の医療機関フォーマットで統一して合成したい
- SaaS プロダクトの「API リファレンス」「チュートリアル」「FAQ」を同一プロダクトの用語体系で揃えたい
これらを個別の Agent Skill(=単一ドキュメント種別に特化した生成用Agent Skill)で個々に作ると、ドキュメント間でフォーマットが揃わない、用語が不統一、相互参照が破綻する、といった問題が起きます。ここで登場するのがメタ Agent Skillです。
9.1 全体像
本セクションでは Anthropic の Agent Skills を活用します。Agent Skills は SKILL.md(YAML フロントマター + Markdown 指示)を核とし、スクリプトやリソースをバンドルしたディレクトリ構成のモジュールです。Claude Codeは起動時にメタデータだけを読み込み、タスクに関連する Skill がトリガーされた時点で初めて指示本文を読み込む段階的開示の仕組みを備えています。
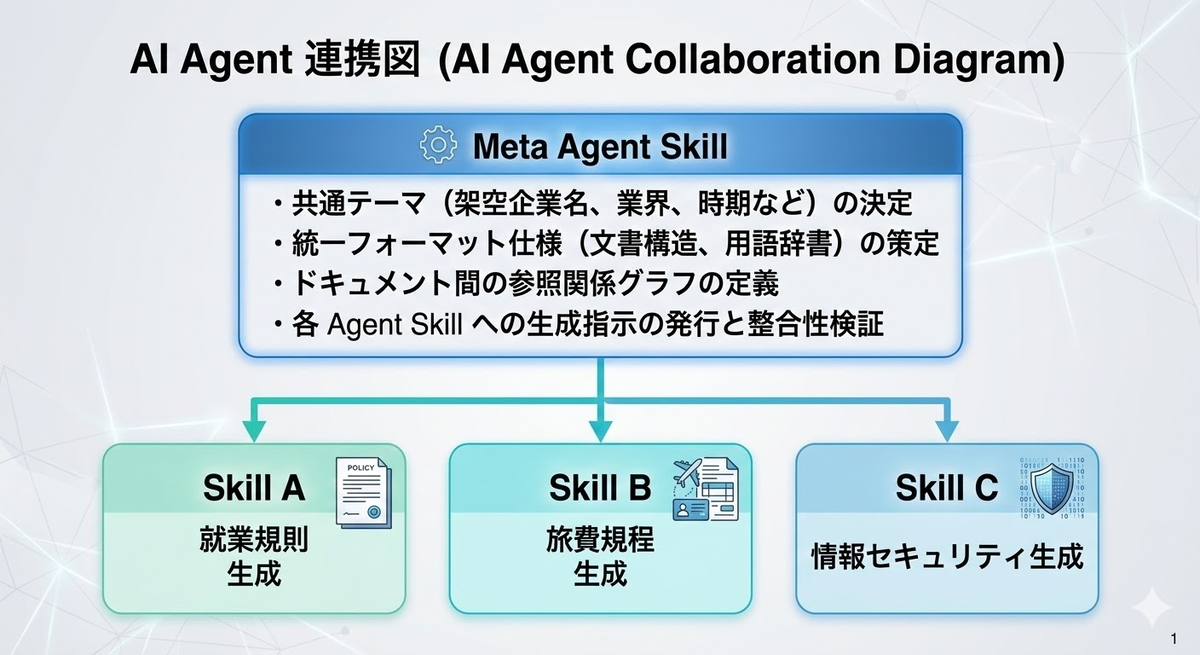
メタ Skill が「何を統一するか」の横断ルールを references/ に持ち、個別 Skill は「どう作るか」のドメイン固有ロジックを持つという関心の分離がポイントです。
9.2 メタ Agent Skill の SKILL.md
以下はメタAgent Skillの例です。重要なのは、Phase 1で統一コンテキストを策定し、保存して後続の処理で活用することです。ここでドキュメント全体のフォーマットやデザイン、用語等を整理することで、共通性をもたせた複数ドキュメントを生成可能にします。
--- name: synthetic-data-orchestrator description: > 複数の関連ドキュメントを共通のテーマ・用語・フォーマットで 統一して合成するメタSkill。ドキュメント間の整合性が必要な 合成データ生成タスクで使用してください。 --- # 複数ドキュメント統一合成オーケストレータ ## Phase 1: 統一コンテキストの策定 `references/unified_context_schema.json` を読み込み、以下を策定: - **用語辞書**: 正規表現と禁止同義語(最低20語) - **フォーマットルール**: 章番号体系、日付・金額表記 - **相互参照マップ**: ドキュメント間の参照関係と種別 策定結果を `references/unified_context.json` に保存。 ## Phase 2: 生成順序の決定 `scripts/resolve_order.py` で相互参照からトポロジカルソート。 循環参照がある場合はスタブ生成モードを使用。 ## Phase 3: 個別 Skill による順次生成 各Skillに統一コンテキストと先行ドキュメントの**必要セクション抜粋のみ**を渡す。 (全文は渡さない — コンテキスト長を圧迫するため) ## Phase 4: 横断的整合性検証 `scripts/cross_validate.py` で用語・参照・フォーマットを検証。 criticalな問題があれば該当ドキュメントを再生成。
9.3 統一コンテキストと検証スクリプト
統一コンテキストの核となるのは、用語辞書・フォーマットルール・相互参照マップの3つです。
{ "terminology": [ { "canonical": "従業員", "forbidden_synonyms": ["社員", "スタッフ", "ワーカー"], "usage_note": "就業規則上の正式名称として統一" } ], "formatting_rules": { "heading_style": "第X条(タイトル)", "date_format": "令和Y年M月D日", "numbering_system": "条 → 項 → 号" }, "cross_references": [ { "source_doc": "employment-regulation", "source_section": "第15条(出張)", "target_doc": "travel-expense", "target_section": "第3条(適用範囲)", "reference_type": "委任" } ] }
この定義に基づき、全ドキュメントに対して禁止同義語の出現チェック、参照先セクションの存在確認、日付フォーマットの準拠チェックを決定論的に実行します。Agent Skills のアーキテクチャでは、スクリプトは bash 経由で実行され出力のみがコンテキストに入るため、検証ロジックがどれだけ複雑でもトークンコストは結果分だけで済みます。
9.4 個別ドキュメント生成 Skill の例
メタAgent Skillで生成した統一コンテキストを用いて、合成データを作成します。以下では就業規則を作成するAgent Skillを示しています。就業規則は長文かつ複数ドキュメントにまたがることが多く、全体で矛盾なくフォーマットが統一されていることが求められます。
--- name: gen-regulation description: > 就業規則の合成データを生成するSkill。統一コンテキストが 提供された場合はその用語辞書・フォーマットに厳密に従います。 --- # 就業規則合成 Skill ## 生成手順 1. `references/unified_context.json` の用語辞書・フォーマットルールを読み込む 2. 先行ドキュメントの参照セクション抜粋との整合性を確保 3. 総則〜附則の10章構成で生成(出張条文に旅費規程への委任を含める) ## 品質チェック - [ ] 全条文が `heading_style` に従っているか - [ ] `forbidden_synonyms` が一切含まれていないか - [ ] 相互参照先の条文番号が正確か ## ノイズ注入ガイドライン - 一部条文に「ただし書き」や例外規定を含める - 附則に施行日を記載 - 別表(勤務時間表、賃金テーブル)への参照を含める
9.5 なぜ「Skill で Skill を作る」構造が有効なのか
第一に、段階的処理との相性です。メタ Skill のメタデータ(約数百トークン)だけが常時読み込まれ、個別 Skill も必要な時だけトリガーされます。
第二に、スクリプトによる決定論的な検証です。用語チェックや参照確認は LLM に任せるよりPythonスクリプトでルールベースで行うほうが確実で、スクリプト出力のみがコンテキストに入るためコスト効率も高いです。
第三に、モジュール性です。新しいドキュメント種別の追加は gen-xxx/SKILL.md を一つ作り、統一コンテキストの cross_references にエントリを足すだけです。共通のSkillsで組織全体に展開すれば、チーム全員が同じパイプラインを利用できます。
9.6 Tips
- 用語辞書は「多すぎるくらい」が正解:
forbidden_synonymsは思いつく限り列挙しましょう。辞書の拡張自体を Claude に依頼するアプローチも有効です。 - ルールベース評価とLLM-as-a-Judgeを併用する: 文字列マッチでは意味的な不整合(「週休2日」と「土日休み」の矛盾など)は見逃します。最終チェックにはLLM-as-a-Judgeを通しましょう。
- 循環参照にはスタブ生成で対処する: まず循環ドキュメントの「スタブ」(章立てと条番号のみ)を生成し、他方を本生成した後にスタブを差し替えます。
まとめ: 合成データのエンジニアリングは面白い
というわけで、LLMやAIエージェントを使って合成データを作る色々なTipsを紹介しました。工夫次第で多様なエンジニアリングや合成方法が可能になり、とても楽しい領域です。
R&Dチームではリサーチエンジニアを募集しています。また、検索エンジニアやデータエンジニア、MLOpsエンジニアも募集しています。一緒にR&Dチームおよびデータ検索基盤チームを0→1で立ち上げたい方はぜひ気軽にお話できると幸いです。
🛰️ ワークフロー自動生成R&Dとか業務フロー合成データとか検索とかに興味ある方、雑談しましょう!
また、Ai Workforce事業部エンジニア組織の詳細は以下Engineering Deckを御覧ください。
https://speakerdeck.com/layerx/ai-workforce-engineering-hiring-deck
