re:Invent 2016はAWSの利用が一段回上に上がる素晴らしい発表が多かったです。さて今回取り上げるのはAthenaです。

https://aws.amazon.com/jp/blogs/news/amazon-athena-interactive-sql-queries-for-data-in-amazon-s3/
すでに素晴らしい資料があるのでそちらをご参照ください。ざっくり個人的な理解は、Google BigQueryのAWS版という雑な印象です。
https://www.slideshare.net/GanotaIchida/re-growth2016osaka-amazonathena-70077024
今回はS3をStatic website hostingしている場合のS3アクセスログをAthenaで分析してみましょう。ELBとかCloudTrailはあるのに、S3 Access Logの記事見つからないものですね。
なお、この記事は以下のフォーマットを対象にしているため、フォーマットが将来変更された場合に動かないことがありえます。あらかじめご了承ください。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/LogFormat.html
1234abcd1234abcd1234abcd1234abcd1234abcd1234abcd1234abcd1234abcd hogemogeTestTest.contoso.com [07/Dec/2016:05:59:12 +0000] 191.1.1.2 1234abcd1234abcd1234abcd1234abcd1234abcd1234abcd1234abcd1234abcd 667C2B96205F407E REST.GET.VERSIONING - "GET /hogemogeTestTest.contoso.com?tagging HTTP/1.1" 404 NoSuchTagSet 285 - 45 - "-" "S3Console/0.4" -
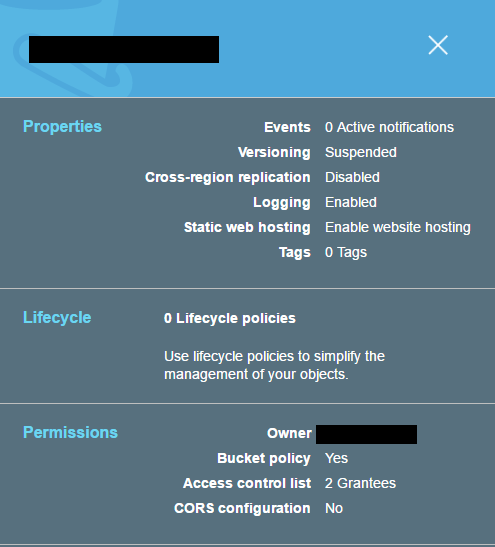
S3 バケットの状態
Athenaは US East (Virginia) と US West (Oregon) のみで選択できるサービスですが、対象となるS3はその制約がありません。当然ですね。

さて、Athenaの対象となるS3バケットをStatic website hostingとして用意します。
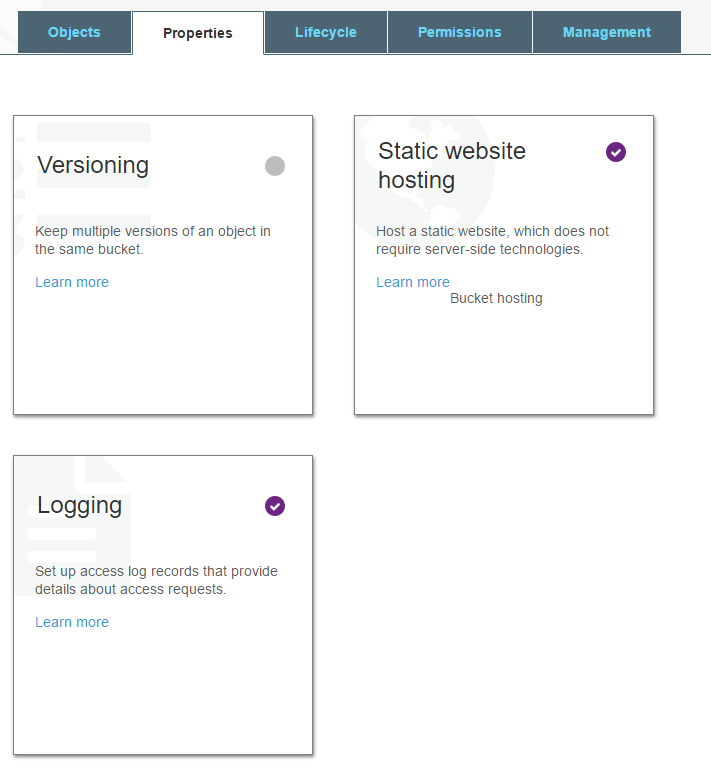
Loggingを有効にしておいて事前にログが吐かれた状態にしましょう。今回は、BucketName/logsに出力します。

このような構成だと思ってください
| バケット名 | ログパス |
|---|---|
| hogemogeTestTest.contoso.com | logs/ |
この状態でlogsフォルダをみると.... 絶望ですね。これを手やAPIで見ようというのは人間のやることではなくなりました。Athenaを使うのです。
Athenaの処理
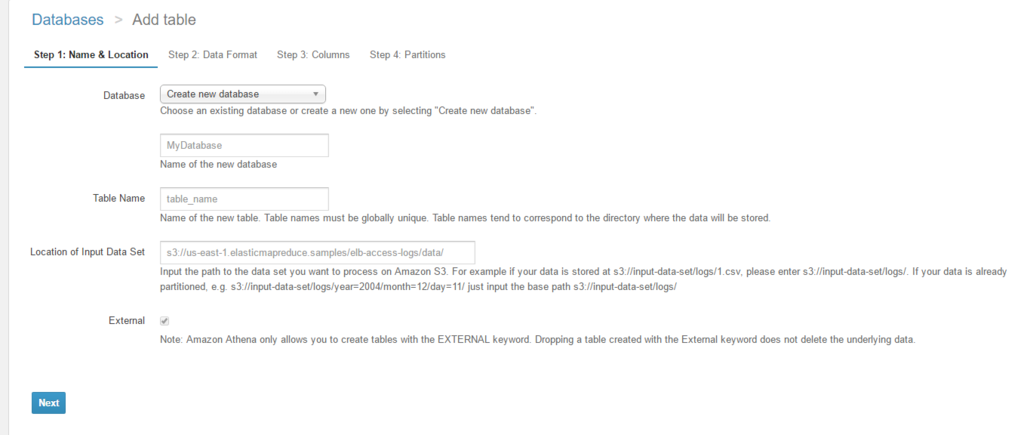
さて分析対象が定まったのでAthenaにDBとテーブルを用意して分析しましょう。作成する内容は次の通りですね。
| 対象バケット名 | Athena データベース名 | Athena テーブル名 |
|---|---|---|
| s3://hogemogeTestTest.contoso.com/logs/ | s3_AccessLogsDB | hogemogeTestTest_contoso_com |
対象バケット名を見ると、作成ウィザードではリージョンが必要そうなブランク欄の薄い灰色表示ですが、リージョンは不要です。
では早速見てみましょう。今回はパーティションを省いてクエリ (HiveQL) のみで一気に行きます。
データベースの作成
まずは、AthenaでS3AccessLogに関するデータベース s3_AccessLogsDB を作成します。すでにデータベースがあるならここはスキップしていただいてokです。
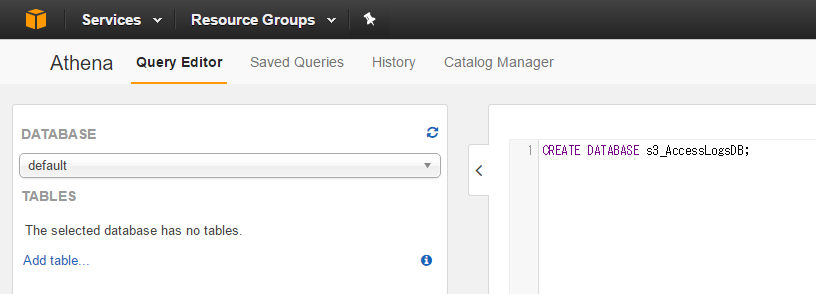
https://gist.github.com/guitarrapc/ed1bffa78dcac37f5b72d76f4a97ad87
実行を待ってねと出て上手く作成できました。
ちなみにCREATE DATABASE文と後述するCREATE TABLE文は同時に投げられません。1つずつ投入、実行してください。
テーブル定義の作成
お次はテーブル定義です。
S3 Access Logのログ形式は次の通りです。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/LogFormat.html
さてフォーマットのシリアライザはどれが使えるでしょうか。
一見org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeがよさそうですがクォートのサポートがないので、今回はorg.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeを使ってごりごりやります。
https://gist.github.com/guitarrapc/c07bd7dc52935aee36e78ac178ef940d
2点だけ説明をした方がよさそうなので触れておきます。
s3_accesslogsdb.hogemogeTestTest_contoso_comは、s3_accesslogsdb.hogemogeTestTest_contoso_comとしている (自分の設定に書き換え)- Locationにある
s3://hogemogeTestTest.contoso.com/logs/が対象のS3バケット名
これで実行すると、上手くテーブルが作られたはずです。


テーブルプロパティをみてみます。
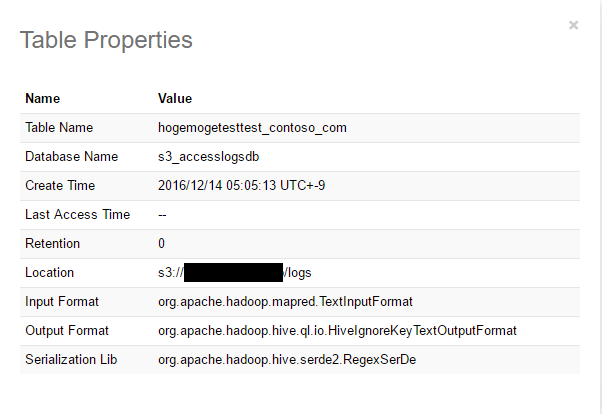
適当なクエリで中身を見てもうまくいっていますね。
SELECT * FROM hogemogetesttest_contoso_com limit 10;

あとは任意のクエリで分析しましょう。
まとめ
AthenaがきたことでようやくS3にエコシステムが出来てよかったですね!
ちょくちょく使ったりデータ量が多いならパーティションを貼っておいた方が精神安定上いいです。
