こんにちは、ENECHANGEエンジニアの藤巻です。
私たちのチームでは、本番環境のアラート対応にBugSnag と CloudWatchを使っています。
既知のアラートについては Notion に対応方針をまとめているのですが、慣れていないメンバーにとっては、Notion を検索して該当記事を探し、手順を読み、本番環境を確認するという一連の流れがなかなか大変です。
この記事では、Claude Code のカスタムスキル機能を使って、アラートの対応を効率化した事例を紹介します。
はじめに
私が所属するチームでサービスのバックエンドでは、BugSnag によるアプリケーションエラー監視と CloudWatch によるインフラ監視を行っています。
アラートは Slack に通知され、エンジニアが対応します。
対応方針は Notion のデータベースに蓄積されており、手順自体は整理されています。
実際にアラートが来たときの作業はこんな感じです:
- Slack 通知からエラーの種類・発生箇所を読み取る
- Notion でキーワード検索して、既知のアラートか確認する
- 該当する記事を開いて、確認手順を読む
- 本番環境で状況を確認する
- 結果を判断して、必要なら関係者に報告する
これを日常的に対応しているメンバーは問題なくこなせますが、普段対応していないメンバーにとっては、どこから手をつければいいか迷うことがあります。
「このエラーメッセージ、Notion のどの記事に対応してるんだっけ?」「確認コマンドはどう打てばいい?」といった具合です。
そこで、アラートメッセージを貼り付けるだけで、既知アラートの突合から確認手順の提示までを自動で行う Claude Code スキルを作りました。
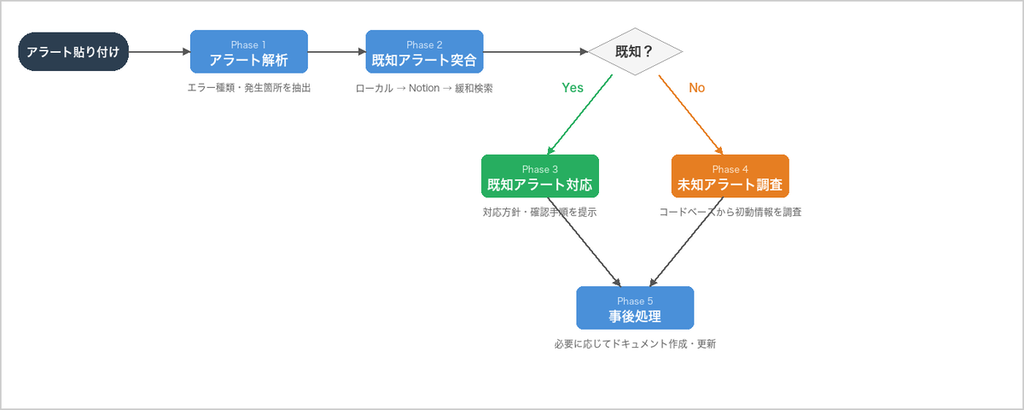
スキル全体のワークフローは以下の通りです:
Claude Code スキルとは
Claude Code には「スキル」というカスタマイズ機能があります。SKILL.md というMarkdownファイルにワークフローを記述すると、Claude Code がその手順に従って動作します。
.claude/skills/my-skill/ └── SKILL.md # スキル定義(ワークフロー)
スキルの起動方法は 2 種類あります。ユーザーがスラッシュコマンドで明示的に呼び出す方法と、ユーザーの発言内容から Claude Code が自動的に判断して起動する方法です。
自動起動の判断には、SKILL.md の frontmatter に記載する description フィールドが使われます。ワークフロー本体(markdown 部分)は、起動後に初めて読み込まれます。
今回のスキルの frontmatter は以下のようになっています:
--- name: alert-triage description: BugSnag/CloudWatchアラート発生時の初動対応をフォローする。アラートメッセージを貼り付けると、既知アラートDBと突合し、対応方針・確認手順を表示。 allowed-tools: Read, Write, Edit, Glob, Grep, Bash, mcp__notion__* ---
description にアラート対応である旨を書いておくことで、Slack 通知を貼り付けるだけでスキルが自動起動します。allowed-tools にはファイル操作系のツールに加え、Notion MCP のツールを指定しています。
設計: 5つのフェーズ
スキルのワークフローは 5 つのフェーズで構成しました。
アラート貼り付け → 解析 → 突合 → 対応提示 → (未知なら調査) → (事後処理)
Phase 1: アラートメッセージ解析
BugSnag の Slack 通知は、改行なしの 1 行で届くことが多く、人間が読むにはやや辛いフォーマットです。
Event in production:prod from my-project - prod in users#create (details)Handled errorActiveRecord::RecordNotFound: Couldn't find User with [WHERE ...]Locationapp/services/user_registration_service.rb:54 - register
SKILL.md にパースルールを定義しておくことで、Claude Code がこのメッセージから情報を自動抽出します。実際の SKILL.md には、以下のようなテーブルでセパレータと抽出方法を定義しています:
**形式1: BugSnag Slack通知** Event in production:prod from <プロジェクト名> - prod in <コンテキスト> (details)Handled error<エラークラス>: <メッセージ>Location<ファイルパス> - <メソッド名> | パート | 抽出方法 | |--------|---------| | 対象サーバー | `from my-project` → サーバーA | | コンテキスト | `in` と `(details)` の間のテキスト | | エラークラス | `Handled error` の直後、`:` の前 | | エラーメッセージ | エラークラスの `:` 以降、`Location` の前 | | 固有パラメータ | メッセージ中の `user_id:`, `charger_id:` 等 | | 発生箇所 | `Location` 以降のファイルパスとメソッド名 |
このルールに基づき、先ほどの通知からは以下が抽出されます:
| 項目 | 抽出結果 |
|---|---|
| 対象サーバー | サーバーA |
| コンテキスト | users#create |
| エラークラス | ActiveRecord::RecordNotFound |
| エラーメッセージ | Couldn't find User with [WHERE ...] |
| 発生箇所 | user_registration_service.rb:54 |
Slack 通知と BugSnag ページからのコピーの 2 つのフォーマットに対応しており、どちらの形式かは自動判定されます。
Phase 2: 既知アラート突合
解析結果をもとに、既知アラートを検索します。検索は 3 段階のフォールバック構成です。
Step 1: ローカルインデックス検索
スキルと同梱している alerts/_index.md のキーワードテーブルで部分一致検索します。
| キーワード | サーバー | ドキュメント | 即時対応 |
|-----------|---------|-------------|---------|
| RecordNotFound, User, user_key | server-a | record-not-found-user.md | check |
| Max retries, ExternalAPI, ResponseCode | server-b | max-retries-external-api.md | check |
| ...(数十件) |
Step 2: Notion DB 検索(MCP 連携時のみ)
ローカルでヒットしない場合、Notion MCP を使ってデータベースを直接検索します。チームの誰かが Notion に新しい記事を追加していれば、ローカルに同期されていなくても見つかります。
Step 3: キーワード緩和
それでもヒットしない場合、エラークラス名だけ、コントローラ名だけなど条件を緩めて再検索し、類似候補を提示します。
Phase 3: 既知アラート対応
既知アラートが見つかった場合、ローカルドキュメントの内容に基づいて以下を提示します:
- 即時対応要否:
required(即時対応)/check(状況確認)/none(対応不要) - 確認手順: DB 確認コマンドやログ検索コマンドなど
- 判断方法: どういう状況なら対応が必要で、どういう状況なら様子見でよいか
- 関連アラート: 連鎖して発生する可能性のある別のアラート
Phase 4: 未知アラート調査
既知アラートが見つからない場合は、コードベースを調査して初動情報を提供します。SKILL.md に調査の手順(Grep でエラー発生箇所を特定 → Read で処理フローを読み解き → 確認コマンドを生成)を記述しているため、Claude Code が自律的に調査を進めます。
Phase 5: 事後処理
対応完了後、新しいアラートドキュメントの作成や既存ドキュメントの更新を行います。ローカルの Markdown ファイルと Notion 記事の両方を更新できます(Notion 更新は MCP 連携時のみ)。
実装のポイント
ローカルドキュメントの設計
各アラートの対応方針は、frontmatter 付きの Markdown ファイルとして管理しています。
--- title: "Slack通知メッセージをそのまま使用" notion_url: "https://www.notion.so/..." server: server-a # 対象サーバーの識別子 urgency: check # required | check | none keywords: - "RecordNotFound" - "User" last_synced: "2026-03-02" --- ## 概要 - ある条件下で該当レコードが見つからない場合に発生するエラー ## 確認方法 ### 1. Rails console でレコードの状態を確認 ```bash # ECS タスクに接続 aws ecs execute-command --cluster my-cluster --task <task-id> \ --container app --interactive --command "/bin/bash" ``` ```ruby # エラーメッセージに含まれるキーで該当レコードを検索 User.find_by(key: "abc-123-def-456") ``` ### 2. CloudWatch Logs でエラー前後のログを確認 ```bash aws logs start-query \ --log-group-name /ecs/my-service \ --start-time $(date -v-1H +%s) \ --end-time $(date +%s) \ --query-string 'fields @timestamp, @message | filter @message like /RecordNotFound/ | sort @timestamp desc | limit 50' ``` ## 判断方法 - 複数ユーザーで同時多発 → 外部APIの障害の可能性、先方に共有 - 単一ユーザー → 様子見で問題なし
ポイントは以下の通りです:
keywords: 突合に使うキーワード。エラークラス名やコンテキスト名など、Slack 通知に含まれる文字列を指定urgency: 即時対応要否。スキルはこの値を見て、対応の優先度を表示するnotion_url: 対応する Notion 記事の URL。同期の追跡に使用title: Slack 通知メッセージそのまま。検索しやすさのためにこの形式を採用
ファイル構成
.claude/skills/alert-triage/
├── SKILL.md # ワークフロー定義
├── README.md # 使い方
├── templates/
│ └── alert_doc.md # 新規ドキュメントのテンプレート
└── alerts/
├── _index.md # キーワードテーブル + 関連アラート対応表
├── server-a/ # サーバーAのアラート
│ ├── typeerror-nil-value.md
│ ├── push-notification-error.md
│ └── ...
└── server-b/ # サーバーBのアラート
├── record-not-found-user.md
├── external-api-500-error.md
└── ...
スキルのファイルはすべてリポジトリに含まれるため、git pull するだけでチーム全員が最新のアラート対応ナレッジを使えます。
MCP 連携の有無による動作の分岐
チームメンバー全員が Notion MCP を設定しているとは限りません。そこで、MCP 連携の有無に応じて動作を分岐させています。
| 機能 | MCP 連携あり | MCP 連携なし |
|---|---|---|
| アラート検索 | ローカル + Notion DB | ローカルのみ |
| 事後処理 | ローカル + Notion 記事 | ローカルのみ |
| Notion → ローカル同期 | 可能 | 不可 |
MCP 非連携でも、ローカルに同期済みのドキュメントで基本的な対応はカバーできます。
関連アラート対応表
あるアラートが発生した場合、別のアラートも連鎖して発生することがあります。例えば、外部サービスがエラーを返すと、後続の処理でもエラーになる、という連鎖です。
_index.md に関連アラートの対応表を定義しておくことで、スキルが関連するアラートも合わせて提示します。
## 関連アラート対応表
| ドキュメント | 関連先 | 関係 |
|-------------|--------|------|
| downstream-error.md | external-api-500-error.md | 外部APIエラーで処理が失敗 → 後続処理でもエラー |
| external-api-500-error.md | downstream-error.md | 本アラートの後続でエラーが連鎖発生する |
実際の動作例
Slack に届いた BugSnag 通知をそのまま Claude Code に貼り付けます。
入力:
Event in production:prod from my-project - prod in users#create (details)Handled errorActiveRecord::RecordNotFound: Couldn't find User with [WHERE ...]Locationapp/services/user_registration_service.rb:54 - register
出力(要約):
スキルが自動で起動し、以下の流れで対応が進みます:
- Phase 1(解析): メッセージをパースし、エラークラス・発生箇所・対象サーバーを抽出
- Phase 2(突合): ローカルインデックスでキーワード
RecordNotFound, User, user_keyにヒット - Phase 3(対応提示):
- 即時対応要否: check(状況確認が必要)
- 確認手順: 分析ツールでユーザーの挙動確認 → 不審な場合は DB でレコード検索
- 判断方法: 複数ユーザーで同時多発 → 外部API側に共有 / 単一ユーザー → 様子見
- 関連アラート: 参考手順として関連ドキュメントを提示
アラートを貼り付けてから対応方針が表示されるまで、体感で 10 秒程度です。
導入の効果
Before
- Slack 通知を見て、Notion を開いて検索して、該当する記事を見つけて、確認手順を読んで……という一連の作業に数分かかっていた
- 慣れていないメンバーは「このアラート、前にも見た気がするけどどの記事だっけ?」と迷いやすい
After
- アラートメッセージを貼り付けるだけで、既知/未知の判定から確認手順まで一括で提示される(確認時間の短縮)
- 誰が対応しても同じ品質で対応しやすくなった
SKILL.md を書くときに意識したこと
1. フォールバックを設計する
検索がヒットしない場合のフォールバック(キーワード緩和、MCP 非連携時のローカルのみ動作)を明示的に記述しました。「見つからなかったら終わり」ではなく、次に何をするかを定義しておくことが重要です。
2. 人間の判断ポイントを残す
スキルが提示するのは情報と選択肢であり、最終的なアクション(関係者への連絡、本番環境での操作など)は人間が判断します。SKILL.md にも「ユーザーの承認を得てから実行すること」と明記しています。
おわりに
Claude Code のカスタムスキルは、繰り返し行う作業の中にある「手順は決まっているけど、毎回調べながらやっている」部分を効率化するのに向いていると感じました。
今回のアラート対応スキルは、Notion に蓄積していたナレッジを SKILL.md のワークフローとローカルドキュメントという形で構造化し直すことで、Claude Code が活用できる形にしたものです。ナレッジ自体は以前からあったので、新しく何かを作ったというよりは、既存の資産を別の形で活かせるようにした、という感覚です。
同じように、チーム内で手順書やナレッジベースを持っているけれど、それを毎回手動で参照している……という場面があれば、スキル化を検討してみるとよいかもしれません。
