みなさんこんにちは。たかぱい(@takapy0210)です。
最近、ほぼ日手帳アプリで、毎日日記をつけるようにしています。 不思議なことに日記をつけるとなると、何かしら写真を撮りたくなってしまい、毎日何気ない風景などの写真を撮るようになりました。 まだ継続して1ヶ月強くらいですが、過去の日記を振り返るのが楽しいです。
さて今回は、コネヒトを支えるデータ基盤の現在地について前後編の2部構成で紹介していこうと思います。
前編となる本記事では、アーキテクチャの設計やFirebase AnalyticsのRAWデータをどのように扱っているのかについてご紹介します。
後編では、Dataformの開発環境について紹介する予定です。
目次
- はじめに
- 2024年当時に抱えていた課題
- なぜDataformにしたのか
- データモデルの設計
- Firebase Analytics × BigQuery Export特有の事象についての対応方法
- 最後に
- We Are Hiring
はじめに
コネヒトではママリというモバイルアプリを開発・運営しています。
ママリのログに関してはFirebase Analyticsに送信しており、BigQuery Export機能を使って、BigQueryにExportしています。
Firebase AnalyticsからBigQueryへのExport処理はざっくり以下のようなフローになっています。
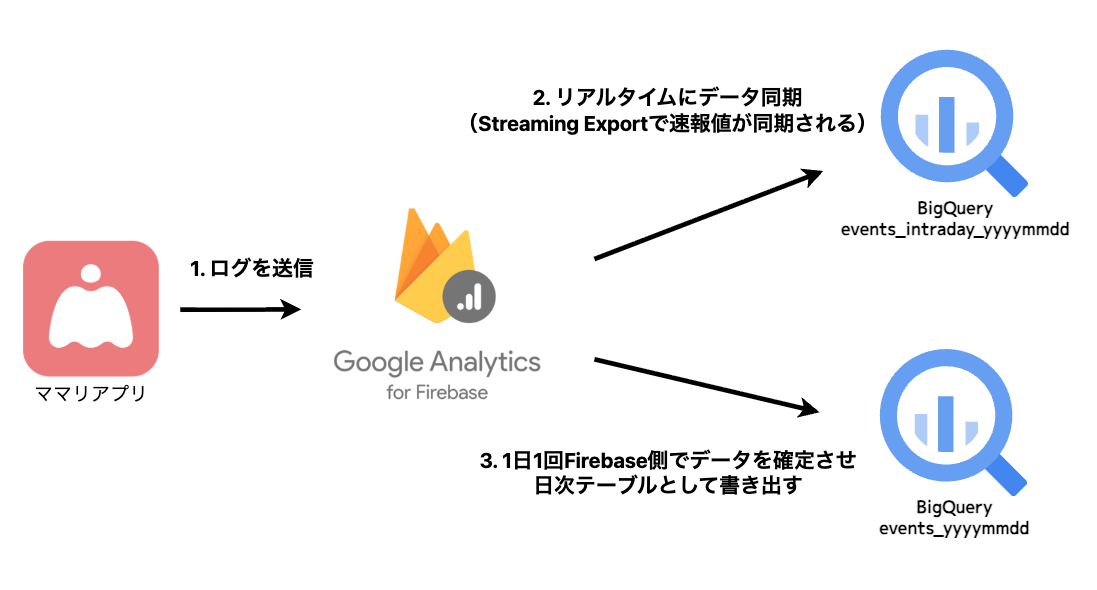
このFirebaseからExportされるRAWデータは以下のような特徴があります。
event_paramsカラムがネスト構造になっているevent_paramsの型が動的(STRING、INT、DOUBLE、FLOATの4種類)- データ到着遅延がある(最大72時間程度)
これらの特徴もあり、RAWデータをそのままクエリするのは非効率で現実的ではないです。 このデータは、スケジュールクエリを使って分析しやすい形に整形はしていたのですが、これはこれで課題感が満載でした(後述)
そのような背景もあり、2024年あたりから少しずつデータ基盤の整備を進めてきました。
以降では、2024年当時の課題感と、それに対してDataformを導入した経緯、データモデルの設計思想について紹介しようと思います。
2024年当時に抱えていた課題
前述したように、RAWデータをそのままクエリするのは現実的ではなかったので、BigQueryにあるスケジュールクエリ機能を使い、分析しやすい形にTransformして分析を行っていました。
しかし、このスケジュールクエリに関しては以下のような課題がありました。
- クエリ間の依存関係を制御できないので、「テーブルAの更新が終わったらテーブルBを更新する」という定義ができず、「Aを2:00、Bを2:30に実行」といった形で、時刻のバッファで管理していた
- コード管理ができておらず、履歴管理もできていなかった
- Data Lineageが見れず、「このテーブルの定義を変えたいけど、どこに影響が出るかわからない」といった、所謂データのサイロ化・ブラックボックス化が起こっていた
- 特定のクエリが失敗した際のオペレーションとして、その下流にあるクエリだけを芋づる式に再実行する、という操作を手動でやる必要があったが、この影響範囲を探すのも一苦労だった
そこで、スケジュールクエリ撲滅PJを立ち上げ、徐々にデータパイプライン管理ツールであるDataformに移行させていきました。
スケジュールクエリで作られたテーブルがどのJOBから参照されているか?を特定しながら移行作業を行っていたのですが、その際には以下のようなsqlで泥臭く調査し、作業を進めていきました。
SELECT creation_time, user_email, job_type, statement_type, destination_table.project_id AS dest_project_id, destination_table.dataset_id AS dest_dataset_id, destination_table.table_id AS dest_table_id, query FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY) -- 指定したテーブルを「参照している」ジョブだけに絞り込む AND EXISTS ( SELECT 1 FROM UNNEST(referenced_tables) AS rt WHERE rt.project_id = "sample_project" AND rt.dataset_id = "sample_dataset_id" AND rt.table_id = "sample_table_id" ) ORDER BY creation_time DESC
また、mixpanelを用いた分析も行っていたため、データのダブルスタンダード問題も発生していました。
なぜDataformにしたのか
よくETLツールで比較されるのがdbtかなと思います。
各ツールの比較に関しては多くの記事が公開されているためそちらに譲りますが、弊社に関しては以下のような背景がありました。
- 専属データエンジニアがいない状況であり、なるべく学習・実装・運用コストを下げたい
- 最低限の機能として、前述した「クエリの依存関係制御」「コード管理(Github)」「Data Lineageの把握」という課題が解決できればOK
Dataformに関しては、SQLベースで記述できる点や、Google Cloud上に統合しておりJOBの実行に関しては料金が発生しないなど(BigQueryのクエリ料金のみ)、導入までのハードルや運用コストの低さに関して優れており、スモールスタートしやすいといった観点で採用しました。
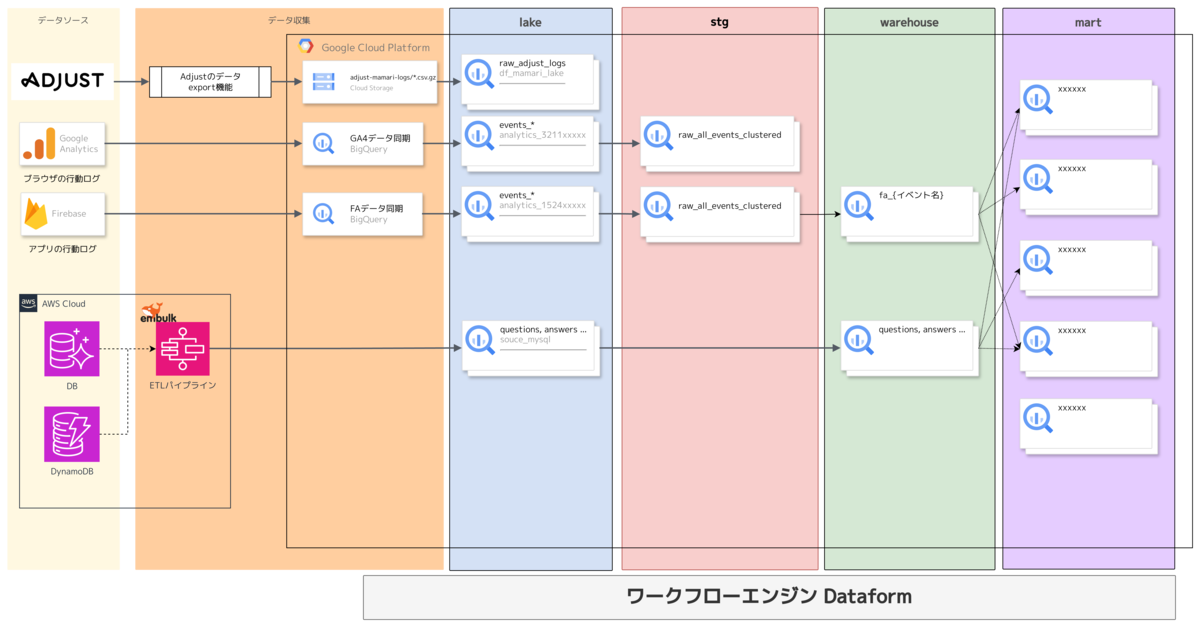
データモデルの設計
Dataformプロジェクトでは、概ね次の4層(+用途別)で整理しています。
- sources:外部データソースの参照定義(declaration)
- stg:生データの初期加工(扱いやすい形への整形)
- warehouse:クレンジング・標準化済みの中間テーブル
- mart:部門・ユースケース別の集計データマート
- (必要に応じて)extra:MLや探索用途の作業場
Dataformのディレクトリイメージは以下です。 これはベストプラクティスや各社の事例を参考にしつつ、弊社の状況に合わせて設計しました。
definitions ├ dwh │ ├ app │ │ ├ extra(機械学習やデータプロダクト開発において使用されるデータを定義) │ │ │ ├ machine_learning │ │ │ │ └ ... │ │ │ └ ... │ │ ├ mart(データマートを定義) │ │ │ ├ marketing │ │ │ │ └ ... │ │ │ ├ product │ │ │ │ └ ... │ │ │ ├ sales │ │ │ │ └ ... │ │ │ └ ... │ │ ├ sources(データソースを定義) │ │ │ ├ firebase_analytics │ │ │ │ └ app_events.sqlx │ │ │ │ └ ... │ │ │ ├ google_analytics │ │ │ │ └ web_events.sqlx │ │ │ │ └ ... │ │ │ ├ mysql │ │ │ │ ├ users.sqlx │ │ │ │ └ ... │ │ │ └ ... │ │ ├ stg(中間テーブルを定義) │ │ │ ├ raw_fa_events_page_view.sqlx │ │ │ └ ... │ │ ├ warehouse(データ変換、クレンジング、メタ情報付与済みデータを定義) │ │ │ ├ fa_events_page_view.sqlx │ │ │ └ ... │ │ └ ... │ └ ... └ ... └ ...
概念図としては以下のようになっており、各種BIツールからはwarehouseまたはmartのデータのみを参照できるようにしています。
Firebase Analytics × BigQuery Export特有の事象についての対応方法
冒頭で挙げた以下の特徴について、どのように対応しているのかについて紹介します。
event_paramsがネスト構造になっているevent_paramsの型が動的(STRING、INT、DOUBLE、FLOATの4種類)- データ到着遅延がある(最大72時間程度)
event_paramsがネスト構造になっている
Firebase AnalyticsからBigQueryにエクスポートされるデータは、以下のようなスキーマになっています。
events_YYYYMMDD ├── event_date: STRING ├── event_timestamp: INT64 ├── event_name: STRING ├── event_params: ARRAY<STRUCT<key STRING, value STRUCT<...>>> ├── user_pseudo_id: STRING ├── user_id: STRING ├── device: STRUCT<...> ├── geo: STRUCT<...> ├── app_info: STRUCT<...> └── ...
この中でも重要なデータが格納されているが、扱いづらいのがevent_paramsです。これは以下のような構造になっています。
event_params: ARRAY<STRUCT<
key STRING,
value STRUCT<
string_value STRING,
int_value INT64,
float_value FLOAT64,
double_value FLOAT64
>
>>
例えば、page_viewイベントのSTRING型であるpage_titleパラメータを取得するには、以下のようなクエリを記述する必要があります。
SELECT (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_title') AS page_title FROM `dataset.schema.events_20260101` WHERE event_name = 'page_view'
これに関してはstg層でフラットなテーブルに変換し、イベント毎にテーブルを分けて保存しています。
event_paramsの型が動的(STRING、INT、DOUBLE、FLOATの4種類)
event_paramsに関しては前述した通りARRAY型になっており、各値の型が動的になっています。
そのため、INT型だと思っていたら実はSTRING型でデータが送られてきており、うまくデータ取得できない、という問題が発生しかねません。
そこで以下のクエリをイベント単位で実行することで、このイベントのevent_paramsには、どんな値がどんな型で送信されてきているか?を確認することができます。
もちろん、ログ仕様は事前に定義して実装しているのですが、考慮漏れや実装ミスにより意図しないデータが送られている可能性もあるので、怪しいログデータなどがあった際にはこちらでチェックしています。
WITH base_table AS ( SELECT eventParams.key AS key, max(eventParams.value.string_value) AS string_value, max(eventParams.value.int_value) AS int_value, max(eventParams.value.float_value) AS float_value, max(eventParams.value.double_value) AS double_value, FROM `PROJECT.DATASET.events_*`, UNNEST(event_params) AS eventParams WHERE 0 = 0 AND _TABLE_SUFFIX >= FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 7 DAY)) AND event_name = 'YOUR_EVENT_NAME' GROUP BY key ) SELECT * FROM base_table WHERE key NOT IN ( 'ga_session_id', 'ga_session_number', 'engaged_session_event', 'firebase_screen_id', 'firebase_screen_class', 'firebase_event_origin', 'firebase_event', 'error_value', 'debug_event' );
データ到着遅延がある
Firebase Analyticsは、イベントが発生してからBigQueryに到着するまで、最大72時間程度の遅延があります。そのため、単純なincremental更新では、遅延したデータが取り込まれません。
解決策として、過去N日分を毎回削除・再取得する方式を採用しています。
config {
type: "incremental",
...
columns: {
...
},
bigquery: {
partitionBy: "meta_event_date",
partitionExpirationDays: 4000,
requirePartitionFilter: true
},
}
js {
const REFRESH_DAYS = 3; // 72時間遅延に対応するため
const LOOKBACK_DAYS = 30
}
-- incrementalで実行する場合、過去REFRESH_DAYS日分を削除
pre_operations {
${when(incremental(), `
DELETE FROM ${self()}
WHERE meta_event_date >= DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL ${REFRESH_DAYS} DAY)
`)}
}
SELECT
...
FROM
${ref("table_name")}
WHERE 0 = 0
...
AND event_name = 'page_view'
AND meta_event_date >= ${when(incremental(),
// 増分更新時: 更新対象期間より前の最大日付を取得
`DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL ${REFRESH_DAYS} DAY)`,
// 初回実行時: 過去LOOKBACK_DAYS日分を取得
`DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL ${LOOKBACK_DAYS} DAY)`
)}
uniqueKeyを利用した MERGE(Upsert)を使えば良いのでは?
前述のコードを見て、DELETE→INSERTせずに、uniqueKeyを使ったMERGEを使えば良いのでは?と思った方もいると思います。
しかしここには罠があり、実際にMERGEで実装したところ、データ量が1.5倍〜2倍になってしまう、という事態が発生しました。
uniqueKeyを使う場合、「"event_date", "event_timestamp", "event_name", "user_pseudo_id", "event_bundle_sequence_id"」あたりのカラムをKeyに設定する必要があります。
冒頭でも述べた通り、Firebase AnalyticsからBigQueryへのExport処理はざっくり以下のようなフローになっています。 ここで、②で作られるデータと③で作られるデータに関して、event_timestampなどのカラムの値が微妙にずれることが分かりました。
デバイス ↓ ① ログを送信 Firebase Analytics ↓ ② リアルタイムにデータ同期(Streaming Exportで速報値が同期される) BigQuery(events_intraday_yyyymmdd) ↓ ③ 1日1回、Firebase側でデータをクレンジング・確定させ、日次テーブルとして書き出す BigQuery(events_yyyymmdd)
例えば、2026年1月1日の日中に②の処理で「events_intraday_20260101」テーブルにリアルタイムでデータ同期されていたとします。そのデータが③の処理で2026年1月2日に日次テーブルとして「events_20260101」に書き出されます。
この時の②、③のそれぞれの時点において、同じ日付データでも「event_timestamp」がずれることがありました。
その結果、前述したuniqueKeyを使ったMERGE処理を行うとデータ量が1.5倍〜2倍に膨れてしまう、ということが起きました。
よって現在は、仮に2日後に遅延して到着したデータがあっても拾えるように、DELETE→INSERT処理を行い、データの品質も担保するようにしています。
最後に
本記事では、Firebase AnalyticsのRAWデータの取り扱いや、Dataformを用いたアーキテクチャ設計についてお話ししました。
後日公開予定の後編では、Dataformの開発環境をGoogle Cloud上のマネジメントコンソールから、ローカルのVS Code with dev containe環境に移行し、快適に開発が行えるようになったことについて紹介しようと思います。
We Are Hiring
コネヒトではデータを用いてプロダクト・会社を成長させる機械学習エンジニアを募集しています!
興味のある方は以下よりご連絡お待ちしております! herp.careers
コネヒトにおける機械学習、データ周辺業務に関しては以下の記事で紹介していますので、合わせてご覧ください!
