こんにちは、taroです!
今回は、直近の新機能の開発でどのようにAIを活用したのかを紹介します。
といっても「設計から実装まで全てAIを使って爆速で開発できました!」という内容ではありません。
AIを試しつつも基本的には人間が設計して実装しつつ、AIを活用できた部分を場面別に紹介する内容です。
「お!これは良さそう!」と思うものがあれば、ぜひ明日の開発からお試しいただけると嬉しいです。
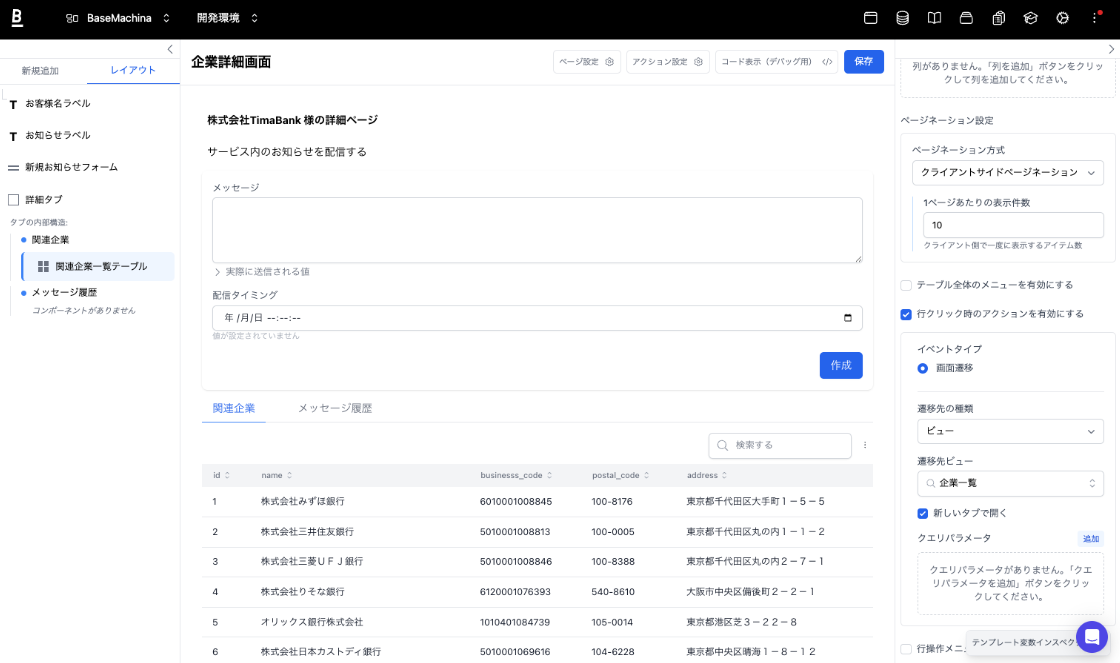
開発したのは管理画面SaaS「ベースマキナ」の「ビジュアルエディター」という機能で、 簡単に言えばフォームでポチポチ設定していくだけで典型的な管理画面を作成できる機能です。
開発で使用しているAIツールは以下です。
- ChatGPT
- Claude
- Claude Code
- Cursor
ちなみにベースマキナでは業務または個人での開発で使用するAIツールの費用を会社負担で利用できる制度があります。
では本題に入っていきます。
設計
まずは機能の設計時点でのAI活用です。
競合の似た機能を調べるのが楽になった
同様の課題を解決するために競合がどんな機能を提供しているかを調べるのにChatGPTとClaudeを使用しました。
ベースマキナはローコード/ノーコードの管理画面開発SaaSという特性上、同じ目的でも機能の実現方法が競合各社で異なり、 これまで機能名などで似た機能を調査するのに時間がかかるという問題がありました。
それに対しAIの場合は自然言語で以下のような情報を伝えるだけで、同じ目的の機能を簡単に調査できます。
- ベースマキナのサービス概要
- ベースマキナのドキュメントのURL
- 作ろうとしている機能の概要
さらに海外のサービスの英語のドキュメントを読み漁る手間が減ったのも嬉しい点だったりします。
プロトタイプが爆速で作れるようになった
ベースマキナでは実装に入る前にDesign Docを書いて社内でレビューし、それを元に開発をしています。
これまでは社内でレビューする際にFigmaやローカル環境で見た目だけ作ったものをモックとして使用していましたが、今回は実際にローカル環境で動作するプロトタイプをClaude Codeで作成しました。
モック作成の手順は以下の通りです。
- Design DocのMarkdownファイルをリポジトリに置く
- PlanモードでDesign Docを元に、実装のTODOリストを生成する
- TODOリストを順番に埋めるように指示し、プロトタイプを生成する
比較的規模の大きい機能だったこともあり結果的に数千行のコードを生成しましたが、自分自身では一切コードを修正することなく、Claudeとのやりとりのみでプロトタイプを作成できました。
「ユーザーがJavaScriptで書いて画面をカスタマイズできる」といった複雑な機能なども普通に動いているし、期間も一日程度で指示や成果物の確認以外の時間は別の作業を並列で進められるし、と最高の体験でした。
また爆速で作れる点以外にも以下のようなメリットがありました。
- 実際に作って触れる分機能の解像度が高まりやすく、より良い体験や仕様の矛盾、実装観点での難しさなど「作ってから気づく」的な問題に早期に気づける
- 実際に動くものがあるため、社内でのレビュー時に機能のイメージがすぐに伝わる
- レビューで出たフィードバックをその場で反映できるため、持ち帰って修正後に再度共有という手間が減る
個人的には特により良い体験や仕様の矛盾、実装観点での難しさなど「作ってから気づく」的な問題に早期に気づけるメリットが大きいと感じています。
これまではモックやプロトタイプを作るのに時間がかかるため、複雑な機能だとやりづらかった「具体的な成果物から機能の体験や解決したい課題を逆説的に考える」設計の進め方が簡単にできるようになりました。
今回はある程度Design Docを用意した上でプロトタイプを作りましたが、今後はある程度機能のイメージができた段階でプロトタイプを作成し、プロトタイプを触って修正しながら詳細を詰めてDesign Docを作成していけばさらに設計が早くなるかなと思います。
ちなみに今回の開発からClaude Codeでプロトタイプを作ろうと思ったのは以下のツイートがきっかけでした。ありがとうございました。
IVSで聞いたホットトピック。DeNAさんではプロダクト企画は企画書ではもう通らず、Devin等を使ってプロトを作ってこないとダメになった、とのこと。
— 片山 良平@paiza代表 (@rk611) July 3, 2025
やばい。
実装
次に実装です。
React,TypeScriptのWebフロントエンドとGoのバックエンドの実装で使用しましたが、 機能の特性上ほとんどがWebフロントエンドの実装だったため、React,TypeScriptでの実装の話となります。
実装方法
基本的には以下の方法で実装していました。
- Claude CodeのPlanモードで拡張思考で実装方針を立てて、その後に実装
- PlanモードのモデルはOpus 4(最近はSonnet 4.5)
- 実装のモデルはSonnet 4(最近はSonnet 4.5)
- ユニットテストも生成しそれが通るまで実行させる
- 生成されたコードはdifitでレビュー
- StorybookをPlaywright MCPで操作し、ブラウザでのデバッグも行う
- 積極的にSubagentsを作る
生成されたコードのレビュー
コードレビューはdifitを使うのが圧倒的に楽で、まだ試してない方はぜひ試してみてください。
コンテキストウィンドウの枯渇を防ぐために積極的にSubagentsを作る
以下はClaude Codeの公式ドキュメントに記載されているSubagentsの機能です。
- 特定の目的と専門分野を持つ
- メインの会話とは独立した独自のコンテキストウィンドウを使用する
- 使用を許可された特定のツールで設定できる
- その動作を導くカスタムシステムプロンプトを含む
この中で個人的に一番嬉しいポイントは「メインの会話とは独立した独自のコンテキストウィンドウを使用する」で、メインのコンテキストウィンドウの枯渇を防ぐために、Subagentsは積極的に作成しました。
Subagentsを作成したのは、例えば以下のような作業です。
コードレビューに関しては、頻繁にレビューが必要になる分野ごとにAgentsを作っていました。
例えば、Reactのコードを書く際にuseEffectが多用されるのを防ぐための「Reactの公式ドキュメントを参照してコードレビューするエージェント」などです。
あまりにも最近Claude CodeがuseEffectとuseStateを不必要に多用するので、Reactの公式ドキュメントのLearnを読んでコードレビューしてくれるエージェントを入れてみたら、意外と仕事してくれる気配を感じているhttps://t.co/UsyMRrTCay
— taro (@taroro_tarotaro) July 29, 2025
(ほぼほぼClaudeが自動生成したプロンプト) pic.twitter.com/z0GaPpbxA5
ちなみにSubagentsを作成しても呼び出されない場合、公式ドキュメントではsubagentのmdファイルのdescriptionで指示するのが推奨されています。
To encourage more proactive subagent use, include phrases like “use PROACTIVELY” or “MUST BE USED” in your description field.
ただそれでも呼び出されない場合があるのでCLAUDE.mdにも記載するようにしています。
基本は2並列で作業
基本的にはClaude Codeを2セッション起動し、上記の方法で2並列で動かしていました。
何度か2並列以上もチャレンジしましたが、自分自身が別の開発やコードレビューなどの別の作業をしていると、現状は2並列が安定してできるラインでした。
Hooksで音付きでデスクトップ通知していても、どうしても放置してしまうことがあるので、 Claude Codeのタスク状況などが可視化できるツールとかがあったら楽かなとも思いつつ、まだ良い解決方法が見つけられていないです。
以下は場面別にどんな感じにAIを活用できたかの話です。
既存のコードを参考にできる単純な実装
Claude Codeに任せていたタスクの中の大半は「既存のコードを参考にできる単純な実装」です。
例えば以下のような設定フォームであれば1つ手本となるフォームを実装し、あとは同様のフォームの実装をClaude Codeに任せていました。

実装するフォームの仕様と参考にするファイルの2つのみを指示するといった感じです。
既存のコードを真似するような実装は本当に精度が高く、ほぼほぼ生成したコードのみでPRを作成できました。
流し読みでレビューできるコードを生成させる
ただ単純な実装とはいえコード量が多くなるとミスも増える上、ちゃんとレビューしないとミスを見落としてPRを作成してしまうことが増えてしまいます。
そのため単純なフォームとはいえ以下のような単位で細かくタスクを分けて指示していました。
さらに参考にするコードはClaudeが真似しやすいように過剰なくらいにコードの構造が同じになるように揃えていました。
例えばファイルの分け方や命名はもちろん、変数・型の宣言やテストケースの順番、改行の有無までできる限り揃えて、コードの意味が分からなくてもパターンを認識できれば真似できるような状態です。
ここまで揃えると生成されるコードが自分が書くであろうコード(なんなら人間よりtypoなどのミスをしない分、自分よりも自分らしいコード)になり、流し読みでのレビューで十分になります。
逆に構造にブレがあるとただ真似をすればいい場面でClaudeが既存にはないコードを生成し、その分レビューで流し読みできないコードが増えてしまいます。
既存のコードを参考にできない複雑な実装
既存のコードをあまり参考にできない複雑な実装もとりあえず一度はClaude Codeに任せていました。
ほぼ使えないコードが生成されることも多いですが、うまくいったらラッキーですし、使えないコードが生成された場合も、その結果から、実装前に見えていなかった難しさに気付けたりします。
ちなみに複雑な実装の場合は、Plan時にClaudeから私に質問させるようにしていました。
ハマった時の調査
なぜか動かない、型エラーが直らない、テストが通らないみたいにハマった時は、一旦Claude Codeに修正を依頼するようにしていました。
特にハマった時にあるあるの「真偽値の条件が逆だった」みたいな単純なミスは本当に一瞬で見つけてくれるのでめっちゃ助かりました。
あとReactの無限レンダリングみたいなClaude Codeが不具合の動作を確認するのが難しい系のバグでも、ソースコードを読んでもらうだけで原因を見つけてくれたりして驚きました。
Playwrightを使ったe2eテスト
最後にPlaywrightを使ったe2eテストです。
ベースマキナでは本番と同等のテスト環境を使用して、Playwrightを使ったe2eテストを行っています。
今回の開発ではe2eテストの実装でもClaude Codeを使用しました。
実装方法
基本的には以下の方法で実装しました。
- Claude Codeの使用方法は機能を作る時とだいたい同じ
- 1つ目のテストは人間が実装し、2つ目以降はClaude Codeで生成する
- Playwright MCPとAgentsを使用
- テストのreporterはjsonを指定
当初は「試しに生成させてみるか」くらいの印象でしたが、ある程度テストの数が増えてくると精度が高まり、終盤はほぼ修正なしでPRにできるようなテストを生成できるようになりました。
ソースコードとサービスのドキュメントを参照できるようにする
Playwrightのテストやドキュメントはアプリケーションとは別のリポジトリで管理しているのですが、生成するテストの精度を高めるためにClaude Codeからソースコードとサービスのドキュメントを参照できるようにしていました。
特にテストシナリオを作る段階では参考情報がないと、テスト対象の画面にどんな要素があるかを全て指示するか、Playwrightを使って探索してもらう必要があり手間がかかります。
逆に参考情報を渡しておけば特に細かい指示をしなくても要素を把握し、例えばフォームのテストであれば全ての入力項目を洗い出した上でテストを生成してくれます。
またソースコードを渡しておくもう一つの利点として、テストの生成がうまくいかない時にソースコードを読んで原因を見つけてくれるようになります。
ちなみにドキュメントとソースコードの参照は、コンテキストウィンドウの枯渇を防ぐためにSubagentsを作成していました。
細かくutility関数を作ると良いテストが生成されやすい
page.getByXXXやexpect()などを直接使用せず、openXXXPage、fillYYYName、expectZZZFieldValueのように細かくutility関数を切って使用したテストを参考に、テストを生成すると同様のテスト観点のテストが生成されやすかったです。
おそらくpage.getByXXXやexpect()などを直接使用したコードの場合、コードだけだと「どんなシナリオなのか」「何を検証したいテストなのか」の情報が残りにくいためです。
例えばpage.getByRole("button", {name: "保存"}).click()というコードの場合、(前後のコードで多少推測がつくかもしれないですが)基本的には何かを保存していることしかわかりません。
対してsaveTableComponentForm()のような適切な名前のutility関数を使うとコードから読み取れる情報量が増え、Claude Codeが既存のテストを上手く真似してくれるようになります。
またutility関数に分けることで複数のテストで共通の構造が生まれるため、上述の「流し読みでレビューできるコードを生成させる」と同様に、レビューが楽になります。
その他
その他、細かいTipや便利だった点です。
git操作
この機能の開発以前からも使用していましたが、git操作はClaude Codeで行うことがだいぶ増えてきました。
例えばPRの作成は、普段1つのPRの修正が小さくだいたい1PRで1commitのため、メインブランチで実装後にclaude -p draftでPRを作ってで、branchを切るところからPRを作成するところまでClaude Codeに任せています。
またコンフリクトの解消やメインブランチへの追従もclaude -p {PRのURL}、コンフリクトを解消して or メインブランチに追従してでほぼほぼうまくいきます。
あとはgitの変更履歴を追って時系列順にまとめてもらうのも便利です。

リファクタリングなどでファイルが移動したりしていると、gitの変更履歴を追うのが面倒だったりするんですがファイル名と行数を指定するだけで、時系列順に変更内容とPRをまとめてくれます。
Claude Codeには画像を入力できる
使い初めの頃は気が付かなかったのですが、Claude Codeには画像を入力できます。
UIのデザインなどを画像を使って伝えたいときやaltテキストの生成などができて便利です。
おわりに
今回は「ベースマキナのビジュアルエディター」の開発でAIを活用できた部分を紹介しました。
冒頭で述べた通り、いきなり「設計から実装まで全てAIを使って爆速で開発できました!」とはいかず、AIを前提とした開発方法を人間が整備していく必要があると感じました。
今後も「これはAIでは難しいな…」と決めつけず「どうやったらAIでできるか」を考え柔軟に開発方法を対応させていきたいです。