
はじめに
こんにちは。Algomatic AI Transformation(AX) のsergicalsix(@sergicalsix)です。
近年、大規模言語モデル(LLM)の登場により、AIがビジネスの現場で急速に浸透しています。ChatGPTやClaudeなどのAPIを活用し、業務効率化や新サービス開発に取り組む企業も増えてきました。
しかし、実際にLLMをAPIで活用しようとすると、コストや安全性などの課題にぶつかることがあります。
その課題の解決策として、本記事ではオープンウェイトモデル(モデルの重みパラメータが公開されており、自由にダウンロード・利用できるLLM)の活用という観点で事例や先行研究をご紹介していきます。
LLMのAPI活用の課題
LLMのAPI活用における課題として、今回取り上げる課題は以下3つです。*1
コスト面の課題
LLMを本格的に業務へ導入すると、API利用料は短期間で高額になり得ます。 例えば、社内のナレッジベースから検索・要約を行うシステムや、大量の顧客対応を自動化するチャットボットでは、「1リクエストあたり数円」でも、数十万〜数百万リクエストが積み重なれば月間で数百万円規模のコストになることも珍しくありません。 さらに、モデルの大型化やコンテキスト長の増加に伴ってコストが増加するという構造的な課題もあります。 *2
速度面の課題
リアルタイム性が求められる業務では、APIの応答速度が致命的な制約になります。 たとえば、顧客とのチャットサポートや現場作業員への指示出しなどでは、わずか数秒の遅延でもUXの悪化やオペレーション効率の低下につながります。 特に大規模モデルでは、推論計算自体の遅延に加え、API経由のネットワーク遅延、さらにプロンプトやコンテキストの長文化によるトークン生成速度の低下が複合的に影響します。*3
安全面の課題
業務でAPIを活用する場合、データが外部に送信されることによる情報漏洩リスクや、生成結果の正確性・安全性の担保といった問題も避けられません。 特に法務や金融、医療分野では、誤った生成結果が即座に業務リスクにつながるため、単に「高性能モデルを使う」だけでは不十分です。 これらはモデルそのものの性能というより、API活用時の運用設計などの問題ですが、生成AI導入には避けて通れません。
これらの課題は、多くの企業がLLM APIを本格活用する際の障壁となっています。
解決策としてのオープンウェイトモデルの自社活用
前章で述べた3つの課題に対して、有効な解決策として注目されているのが「オープンウェイトモデルを自社の閉域網内で運用する」というアプローチです。
これにより、以下のメリットが期待できます。
コスト:ランニングコストの削減
速度:通信遅延削減による低レイテンシー実現
安全性:データが社外に出ないため、セキュリティリスクが軽減
ただオープンウェイトモデルの活用には欠点があり、その一つが性能面です。一般的にオープンウェイトなモデルは、現在最も性能が高いと言われているGPT-5やClaude Opus 4、Gemini 2.5 Proなどのクローズドなモデルと比べて性能が低いです。その理由の一つには、モデルサイズが小さいことが挙げられます。
ただタスク特化させた場合は、必ずしもモデルサイズが性能に比例するわけではありません。例えばコード生成系のタスクにおいてCodeLlama 7BがLlama 2 70Bよりも精度が高いことが報告されています(Subramanian et al., 2025)。
このように、個別タスクに特化させることにより「小さくても強い」モデルの構築が可能であることが明らかになっています。
さらにこのような背景の中、約1週間前に発表された「gpt-oss」は、o3-miniなどの既存モデルに匹敵する性能であることが報告されています(Open AI, 2025)。 gpt-ossについては特に注目度が高く、弊社(株式会社Algomatic)や株式会社リコー様が実用化に向けた取り組みを発表しています。
次章では、オープンウェイトモデルの具体的な導入・活用手法について、最新の研究成果をもとに解説します。
オープンウェイトモデルの活用
本章では、オープンウェイトモデルを実践的に活用するための2つのアプローチを紹介します。
1. 既存システムからの移行
2. 複数モデルを組み合わせたハイブリッド運用
以下で紹介する手法は、元々Small Language Model (SLM) のarXivで提案されたものですが、オープンウェイトモデルに適用可能なフレームワークのため紹介していきます。
以下では、オープンウェイトモデルを自社環境にデプロイして運用する場合を「自社運用モデル」と呼びます。
既存システムからの移行(Belcak et al., 2025)
Belcak et al., 2025は、既存システムから自社運用モデルへの移行プロセスを6つのステップで整理しています。またこれらは必ずしもAPIを利用しているシステムからの移行のみならず、人間が実施している業務でも同様の移行プロセスを実施することが可能です。
Step1. データ収集
まずは既存のモデルやエージェントが処理したすべての入出力ログを網羅的に集めます。 対象はテキストプロンプトやモデルの応答だけでなく、外部ツールやAPIの呼び出し履歴、検索クエリ、ユーザーのクリックや選択などの行動データも含まれます。 特に後続の分析や改善では、モデルの出力だけではなく「なぜその結果になったのか」を追えるコンテキスト情報が重要です。そのため、リクエストのタイムスタンプ、ユーザー属性(匿名化済み)、使用モデルやバージョンなどのメタデータも併せて収集します。
Step2. データ前処理
収集したデータは、そのままでは学習に使えません。品質の低いデータやリスクのある情報が混ざっているため、次のような処理を行います。
- 個人情報や機密情報の削除/マスク
例:氏名、住所、メールアドレス、顧客IDなどを正規表現やNER(固有表現抽出)で検出し匿名化。
- ノイズの除去
無意味な会話や重複データ、明らかな誤回答などを除去し、学習効率を高めます。
- データの正規化
言い回しや表記揺れ(例:「メール」「Eメール」)を統一し、モデルが学習しやすい形に整えます。
- バリエーション生成(パラフレーズ作成)
同じ意味を異なる表現で追加することで、モデルの汎化性能を向上させます。
こうした処理により、安全かつ多様性のある高品質データセットが得られます。
Step3. タスクのクラスタリング
ログを分析し、類似タスクをグルーピングすることでデータを分類します。これにより、各領域に特化したカスタムモデルやプロンプトチューニングが可能になります。
補足ですが、Step2. データの前処理とStep3. タスクのクラスタリングについては、以下に詳しく記述されています。
Step4. モデル選定
クラスタリングされたタスクごとに、性能・推論速度・コンテキストウィンドウ・運用要件などを総合的に評価し、最適なモデルを選びます。 ここでは単一の指標を見るだけではなく、各タスクに最も適した特性を持つモデルを選び、無駄な計算資源を削減しながらも必要な精度を確保することが重要です。
Step5. チューニング
プロンプトチューニングや選定したモデルに対して、LoRAやQLoRAなどでファインチューニングを行います。必要に応じて、蒸留も活用し、性能を補強します。 こうした軽量かつ効率的な学習手法を組み合わせることで、限られたリソースでも実運用に耐える精度と応答速度を実現できます。
Step6. 継続的な改善
運用後についてもStep2〜Step5の工程を繰り返し、精度や速度向上などを実施します。 新しい利用パターンやデータが蓄積されるたびにモデルを更新し、変化する業務ニーズやユーザー期待に対応できる状態を保つことが大切です。
しかし、すべてのタスクを一度に移行するのは現実的ではない場合もあります。 次節では、段階的な移行を可能にするハイブリッドなアプローチを紹介します。
複数モデルを組み合わせたハイブリッド運用(Chen et al., 2025)
完全な自社運用モデル移行が困難な場合でも、以下の4つのパターンでクローズドモデル(API)とオープンウェイトモデルを効果的に組み合わせることで、コスト削減とセキュリティ向上を実現できます。*4
1. Pipeline(パイプライン)
処理を複数のステップに分解し、自社運用モデルで前処理や定型作業を実行後、その結果をAPIに渡して後続の処理を実行します。
例えばCoGenesis(Zhang et al., 2024)では、端末上のSLMが個人のコンテキストを読み取って整形し、クラウド上のLLMがタスクを実行するといったワークフローが採用されています。
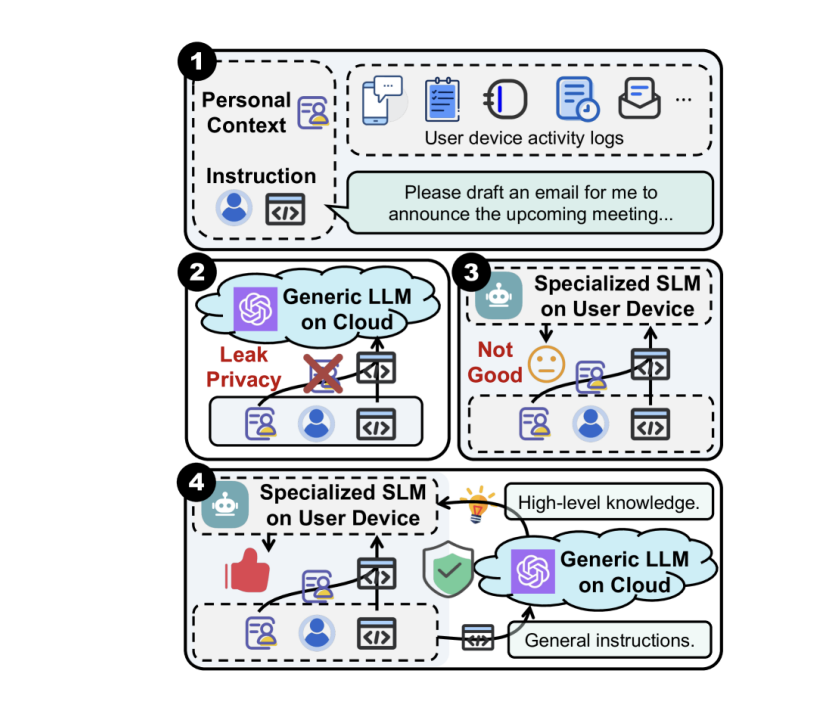
2. Routing(ルーティング)
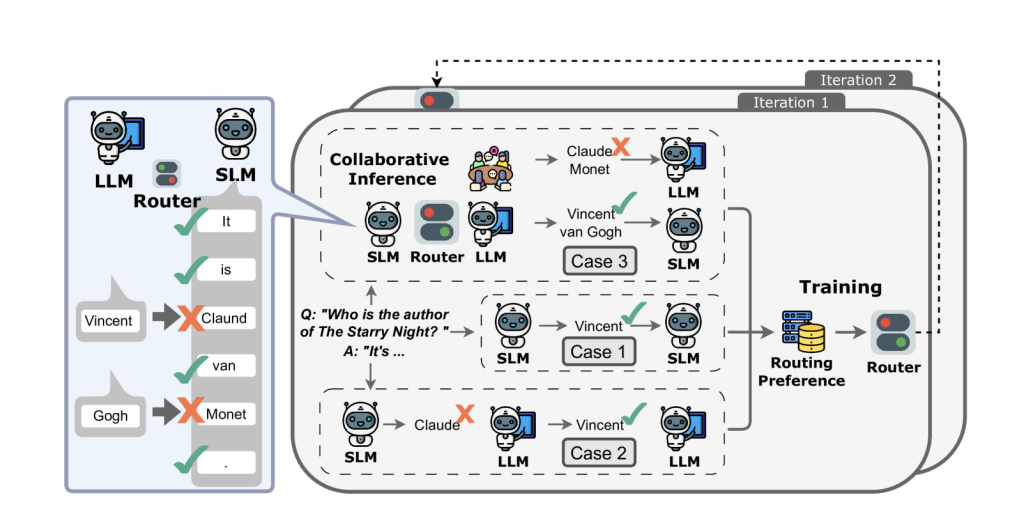
入力内容の複雑度や機密性に応じて、自社運用モデルとAPIを動的に使い分けます。簡単なタスクは自社運用モデルで素早く回答し、難しいタスクはAPIを通じて実施します。
例えばCITER(Zheng et al., 2025)では、出力の生成過程をトークン単位で制御し、定型的な部分や平易な部分はSLMが生成し、重要度が高く正確さが必要な部分はLLMが担当します。このルーティングは強化学習で最適化され、品質とコストのバランスを取っています。
3. Auxiliary(補助/強化)
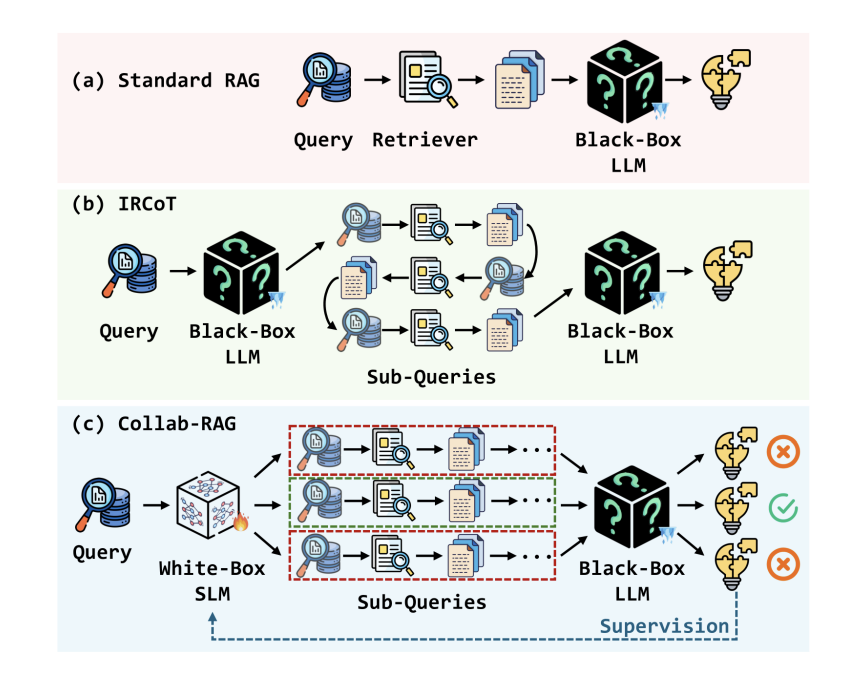
APIをメインとしつつ、自社運用モデルが前処理や情報抽出で支援します。例えば自社運用モデルが社内文書から関連情報を検索・構造化し、その結果をコンテキストとしてクローズドモデルに提供するなどです。
例えばCollab-RAG(Xu et al., 2025)では、SLMが複雑な質問を複数のサブクエリに分解することで検索精度を向上させ、LLMが最終的な回答を作成します。
4. Knowledge Distillation(知識蒸留)
クローズドモデルの出力を教師データとして、自社運用モデルを改善します。
例えば全体の出力のN(0 < N < 100)%をAPIで処理し、データを収集することで自社運用モデルを継続的に訓練するといった活用方法が考えられます。
余談ですが、知識蒸留については以下のサーベイ論文に参考になります。
複数モデルを組み合わせたパターンの選択指針
所属されているチームの優先事項や目的に応じて、以下のアプローチを選択すると良いです。
コスト削減: Pipelineを採用し、前処理や簡単な処理を自社運用モデルで対応
セキュリティ最優先: Routingを採用し、機密データが関わる部分を自社運用モデルに分離
精度向上: Auxiliaryを採用し、社内ナレッジや専門知識を自社運用モデルで補強
段階的移行: Distillationを採用し、徐々に自社運用モデルを強化
まとめ
本記事では、LLM APIの活用で多くの企業が直面する「コスト」「速度」「安全性」の課題に対して、オープンウェイトモデルの活用は現実的な解決策の一つです。
定型的なタスクから自社運用モデル化を始め、徐々に適用範囲を広げていくといったアプローチやハイブリッドなモデル運用などが今後必要になってくるかもしれません、
今後もオープンウェイトモデルの動向を注視しながら、最適な活用方法を模索していきたいと思います。
最後にAlgomaticは一緒に働くメンバーを募集しています!
以下よりお気軽にカジュアル面談をお申し込みいただけると幸いです!
*1:今回取り上げなかった課題として、①オフライン環境またはネットワーク速度が低い環境で使えない②エネルギー制約がある場合に使えないといった課題があります。①は概ね速度面の課題や安全面の課題で吸収でき、②はまだ日本で課題として顕在化していないと判断しています。
*2:コスト面の課題に対する対処法として本記事では触れませんが、①定額課金制のサービスを使用する②性能が高く安価なモデル(例: Gemini 2.5 Flash)を使用するなどがあります。
*3:速度面の課題に対する対処法として本記事では触れませんが、CerebrasやGroqなどの高速なプロバイダーを使うなどがあります。
*4:Chen et al., 2025内では、紹介したパターン以外にIntegration/Fusionが紹介されています。しかしアーキテクチャレベルや重みレベルのモデル統合は本記事の対象外であるため、紹介していません。
