こんにちは、Algomatic AXカンパニー所属の大塚です。
こんにちは、Algomatic AXカンパニー所属の大塚です。
本日は、LLMアプリケーション開発に欠かせない技術となったRAG(Retrieval-Augmented Generation:検索拡張生成) について、その誕生から最新動向までを論文とともに振り返っていきたいと思います。
RAGは2020年に提案されて以来、様々な改良が加えられてきました。単純な検索と生成の組み合わせから始まり、自己反省機構の追加、グラフベースの構造化、エージェント型アーキテクチャへと進化しています。そして現在、RAGは「コンテキストエンジニアリング」というより広い概念の一部として位置づけられています。
今回の記事では、RAGを全体像から理解することを目的として、13本の主要論文とともにその歴史を時系列でたどっていきます。
この記事のサマリー
- 2020年:REALM、DPRが検索と言語モデル統合の基盤を作り、RAG原論文が「検索拡張生成」の概念を定義
- 2022-2023年:HyDE(クエリ拡張)、FLARE(能動的検索)、Self-RAG(自己反省)により検索精度と生成品質が向上
- 2024年:CRAG(検索結果の訂正)、Adaptive-RAG(動的戦略選択)、GraphRAG(知識グラフ活用)、Modular RAG(モジュール設計)で高度化
- 2025年以降:エージェント型RAG、マルチモーダルRAGへと広がる。LLMアプリ開発の視点も「コンテキストエンジニアリング」という広い枠組みへ
前史・基盤技術(2020年)

RAGが登場する前に、その基盤となる技術が2つ発表されました。検索と言語モデルを統合するというアイデアは、これらの研究から始まっています。
REALM:検索を事前学習に統合
| 項目 |
内容 |
| 論文タイトル |
REALM: Retrieval-Augmented Language Model Pre-Training |
| 著者/組織 |
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, Ming-Wei Chang / Google Research |
| 発表時期 |
2020年2月 |
| arXiv |
https://arxiv.org/abs/2002.08909 |
主要な貢献・技術的特徴
REALMは、言語モデルの事前学習段階で検索機能を統合した研究です。従来の言語モデルは、モデルのパラメータ内に知識を暗黙的に記憶していました。しかし、この方法では知識の更新が困難であり、膨大なパラメータ数が必要になるという問題がありました。
REALMは以下のアプローチを提案しました。
- Knowledge Retriever(知識検索器): 入力テキストに関連する文書をコーパスから検索します
- Knowledge-Augmented Encoder(知識拡張エンコーダ): 検索された文書を入力と組み合わせて処理します
- End-to-end学習: 検索器とエンコーダを同時に学習し、最適化します
ポイントは、検索操作を微分可能にすることで、誤差逆伝播法による学習を可能にした点です。「どの文書を検索すべきか」をモデルが自動的に学習できるようになりました。
RAGの進化における位置づけ
REALMは、「検索と言語モデルの統合」という方向性を示した研究です。後のRAGアーキテクチャの設計でも参考にされており、事前学習段階での検索統合という考え方はここから来ています。
Dense Passage Retrieval(DPR):密ベクトル検索の基盤
| 項目 |
内容 |
| 論文タイトル |
Dense Passage Retrieval for Open-Domain Question Answering |
| 著者/組織 |
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih / Facebook AI Research |
| 発表時期 |
2020年4月 |
| arXiv |
https://arxiv.org/abs/2004.04906 |
主要な貢献・技術的特徴
DPRは、オープンドメイン質問応答タスクにおいて、BERTベースの密ベクトル(Dense Vector)による検索手法を提案しました。
従来の検索システムは、TF-IDFやBM25といった疎ベクトル(Sparse Vector)ベースの手法が主流でした。これらは単語の出現頻度に基づく手法であり、同義語や言い換え表現に弱いという欠点がありました。
DPRは以下の特徴を持っています。
- Dense Encoder構造: クエリと文書をそれぞれ独立したBERTエンコーダで埋め込みベクトルに変換します
- In-batch negatives learning: 学習時に同一バッチ内の他のサンプルを負例として使い、効率的に学習します
- FAISS統合: Facebookが開発した高速類似検索ライブラリFAISSとの組み合わせで、大規模コーパスでも実用的な速度で検索できます
実験では、Natural QuestionsやTriviaQAなどのベンチマークで、BM25を大幅に上回る性能を示しました。
RAGの進化における位置づけ
DPRは、現代のRAGシステムにおける検索コンポーネントの代表的な手法です。密ベクトル検索が有効であることを示し、後続の多くの研究がDPRをベースラインとして使っています。
RAGの誕生(2020年)

RAG原論文:用語と概念の確立
| 項目 |
内容 |
| 論文タイトル |
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks |
| 著者/組織 |
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela / Facebook AI Research, University College London, New York University |
| 発表時期 |
2020年5月(NeurIPS 2020で発表) |
| arXiv |
https://arxiv.org/abs/2005.11401 |
主要な貢献・技術的特徴
この論文は、RAG(Retrieval-Augmented Generation)という用語を生み出し、検索拡張生成の概念を整理しました。
RAGは、事前学習済み言語モデルが持つパラメトリックメモリと、外部知識ベースによるノンパラメトリックメモリを組み合わせるハイブリッドアーキテクチャです。
論文では2つのバリエーションが提案されました。
- RAG-Sequence: 検索された同一の文書を使用して完全な出力シーケンスを生成します
- RAG-Token: 各出力トークンの生成時に、異なる文書からの情報を参照できます
技術的な構成要素は以下です。
- 検索器(Retriever): DPRをベースとした密ベクトル検索
- 生成器(Generator): BART(Bidirectional and Auto-Regressive Transformers)を使用
- Marginalization: 検索された複数の文書からの情報を確率的に統合
RAGの進化における位置づけ
この論文は、RAG研究の出発点です。後続の多くの研究がこの論文を参照しています。「検索して生成する」というシンプルな考え方を示し、知識集約型タスクにおける新しいアプローチを提案しました。
事前学習済みモデルの知識を外部データベースで補完できることを示した点がポイントです。モデルの再学習なしに知識を更新できるようになりました。
検索拡張の広がり(2022-2023年)

RAGの基本概念ができた後、検索の質と生成の精度を高めるための様々なアプローチが研究されました。
HyDE:仮説的文書による検索改善
| 項目 |
内容 |
| 論文タイトル |
Precise Zero-Shot Dense Retrieval without Relevance Labels |
| 著者/組織 |
Luyu Gao, Xueguang Ma, Jimmy Lin, Jamie Callan / Carnegie Mellon University, University of Waterloo |
| 発表時期 |
2022年12月 |
| arXiv |
https://arxiv.org/abs/2212.10496 |
主要な貢献・技術的特徴
HyDE(Hypothetical Document Embeddings)は、ゼロショット検索の問題を解決する手法です。
従来のDPRなどの密ベクトル検索は、大量のラベル付きデータで学習する必要がありました。しかし、新しいドメインでは適切な学習データが存在しないことが多く、性能が低下するという問題がありました。
HyDEは以下のアプローチでこの問題を解決します。
- HyDE: ユーザーのクエリに対して、LLM(InstructGPT)が「理想的な回答を含む文書」を生成します
- Embedding: 生成された仮説的文書をContrieverで埋め込みベクトルに変換します
- Dense Retrieval: 仮説的文書の埋め込みを使って、実際の文書コーパスを検索します
この手法のポイントは、クエリと文書の「表現のギャップ」を仮説的文書で埋めることです。質問形式のクエリは、回答を含む文書とは表現が大きく異なります。HyDEは、LLMに回答を生成させて、検索対象の文書に近い表現を得ます。
RAGの進化における位置づけ
HyDEは、LLMを使ったクエリ拡張(Query Expansion)という方法を示しました。検索精度を上げるためにクエリ自体を工夫するというアイデアは、後の研究でも使われています。
また、LLMを検索の前処理に使うという発想は、RAGパイプライン全体を最適化する流れにつながっています。
FLARE:能動的な前向き検索
| 項目 |
内容 |
| 論文タイトル |
Active Retrieval Augmented Generation |
| 著者/組織 |
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, Graham Neubig / Carnegie Mellon University, Meta AI |
| 発表時期 |
2023年5月 |
| arXiv |
https://arxiv.org/abs/2305.06983 |
主要な貢献・技術的特徴
FLARE(Forward-Looking Active REtrieval augmented generation)は、生成プロセス中に動的に検索を行う能動的検索手法です。
従来のRAGは、生成の開始前に一度だけ検索を行う「ワンショット検索」でした。しかし、長文生成タスクでは、生成が進むにつれて新しい情報が必要になることがあります。
FLAREは以下の仕組みで能動的な検索を行います。
- Confidence-based trigger: LLMが生成する各トークンの確率を監視し、低信頼度のトークンが出現した際に検索をトリガーします
- Forward-looking retrieval: 次に生成される内容を予測し、その予測に基づいてクエリを生成します
- Iterative generation and retrieval: 検索結果をコンテキストに追加し、生成を継続します
具体的には、LLMに「次の文」を一時的に生成させ、その文をクエリとして検索を行います。検索結果を得た後、その情報を使って実際の生成を行います。
RAGの進化における位置づけ
FLAREは、適応的検索(Adaptive Retrieval)の概念を提案しました。「いつ検索すべきか」「何を検索すべきか」を動的に判断するという考え方は、後のSelf-RAGやAdaptive-RAGに引き継がれています。
また、長文生成タスクにおけるRAGの適用範囲を広げ、単純な質問応答を超えた応用が可能になりました。
Self-RAG:自己反省による品質向上
| 項目 |
内容 |
| 論文タイトル |
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection |
| 著者/組織 |
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi / University of Washington, IBM Research, Allen Institute for AI |
| 発表時期 |
2023年10月 |
| arXiv |
https://arxiv.org/abs/2310.11511 |
主要な貢献・技術的特徴
Self-RAGは、LLMが自身の検索と生成プロセスを自己反省(Self-Reflection)できるようにした研究です。
従来のRAGには、以下の問題点がありました。
- 検索が常に有益とは限らない(関係のない情報を取得することもある)
- 検索結果の品質を評価する仕組みがない
- 生成された回答の正確性を検証できない
Self-RAGは、特殊な反省トークン(Reflection Token) を導入することでこれらの問題に対処します。
反省トークンには以下の種類があります。
| トークン |
役割 |
| Retrieve |
検索が必要かどうかを判断 |
| ISREL |
検索結果がクエリに関連しているか評価 |
| ISSUP |
生成内容が検索結果に支持されているか評価 |
| ISUSE |
生成内容がユーザーにとって有用か評価 |
Self-RAGのモデルは、生成時にこれらの反省トークンを出力し、自身の出力を批評しながら生成を進めます。推論時には、反省トークンのスコアに基づいて、複数の候補から最適な出力を選択できます。
RAGの進化における位置づけ
Self-RAGは、RAGシステムに自己評価能力を持たせた研究です。「検索すべきか否か」「生成結果は信頼できるか」をモデル自身が判断できるようになりました。
この自己反省メカニズムは、後のCRAGやAgentic RAGの設計にも取り入れられています。また、推論時に品質と引用の厳密さのバランスを調整できる点も使いやすいです。
高度なRAG手法(2024年)

2024年に入ると、RAGの研究は多様化しました。検索品質の向上、動的な戦略選択、構造化された知識の利用、モジュラー設計へと広がっています。
CRAG:検索結果の訂正メカニズム
| 項目 |
内容 |
| 論文タイトル |
Corrective Retrieval Augmented Generation |
| 著者/組織 |
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, Zhen-Hua Ling / University of Science and Technology of China, UCLA, Google Research |
| 発表時期 |
2024年1月 |
| arXiv |
https://arxiv.org/abs/2401.15884 |
主要な貢献・技術的特徴
CRAG(Corrective Retrieval Augmented Generation)は、検索結果の品質を評価し、必要に応じて訂正を行う仕組みを導入しました。
CRAGの中核は、軽量な検索評価器 です。この評価器は、検索された文書がクエリに対して「正しい」「曖昧」「誤り」のいずれかを判定します。
判定結果に応じて、以下のアクションが取られます。
| 判定 |
アクション |
| 正しい |
検索結果をそのまま使用し、知識精製で重要部分を抽出 |
| 曖昧 |
検索結果とWeb検索の両方を組み合わせて使用 |
| 誤り |
検索結果を破棄し、Web検索で新たな情報を取得 |
知識精製のプロセスでは、検索された文書を細かい単位に分解し、関連性の高い部分のみを抽出します。無関係な情報によるノイズを減らすためです。
RAGの進化における位置づけ
CRAGは、検索結果の品質管理を扱った研究です。従来のRAGでは、検索結果をそのまま使用していたため、検索ミスがそのまま生成品質の低下につながっていました。
CRAGの「評価→訂正」というパターンは、安定したRAGシステムを作るときに使えます。Web検索をフォールバックとして使うアイデアも実用的です。
Adaptive-RAG:クエリに応じた動的戦略
| 項目 |
内容 |
| 論文タイトル |
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity |
| 著者/組織 |
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, Jong C. Park / KAIST |
| 発表時期 |
2024年3月 |
| arXiv |
https://arxiv.org/abs/2403.14403 |
主要な貢献・技術的特徴
Adaptive-RAGは、クエリの複雑度に応じて最適な検索戦略を動的に選択する手法です。
すべてのクエリに同じRAG戦略を適用することは非効率です。簡単な質問にはシンプルなアプローチで十分であり、複雑な質問には高度な処理が必要です。
Adaptive-RAGは、クエリを3つの複雑度レベルに分類します。
| レベル |
説明 |
戦略 |
| Level A |
簡単なクエリ(LLMの知識で回答可能) |
検索なしで直接生成 |
| Level B |
中程度のクエリ(1回の検索で回答可能) |
シングルステップRAG |
| Level C |
複雑なクエリ(複数回の検索・推論が必要) |
マルチステップRAG(反復的な検索と推論) |
クエリの複雑度を判定するために、小規模な分類器を学習させます。この分類器の学習には、様々なデータセットから自動的にラベルを生成する手法を用います。
RAGの進化における位置づけ
Adaptive-RAGは、計算効率と精度のバランスをとる方法を示しました。すべてのクエリに重い処理を適用する必要はなく、必要に応じてリソースを割り当てるという考え方は実用的です。
また、クエリの複雑度を自動的に判定する方法も提案しており、後の研究でも参照されています。
GraphRAG:知識グラフによる構造化検索
| 項目 |
内容 |
| 論文タイトル |
From Local to Global: A Graph RAG Approach to Query-Focused Summarization |
| 著者/組織 |
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Jonathan Larson / Microsoft Research |
| 発表時期 |
2024年4月 |
| arXiv |
https://arxiv.org/abs/2404.16130 |
主要な貢献・技術的特徴
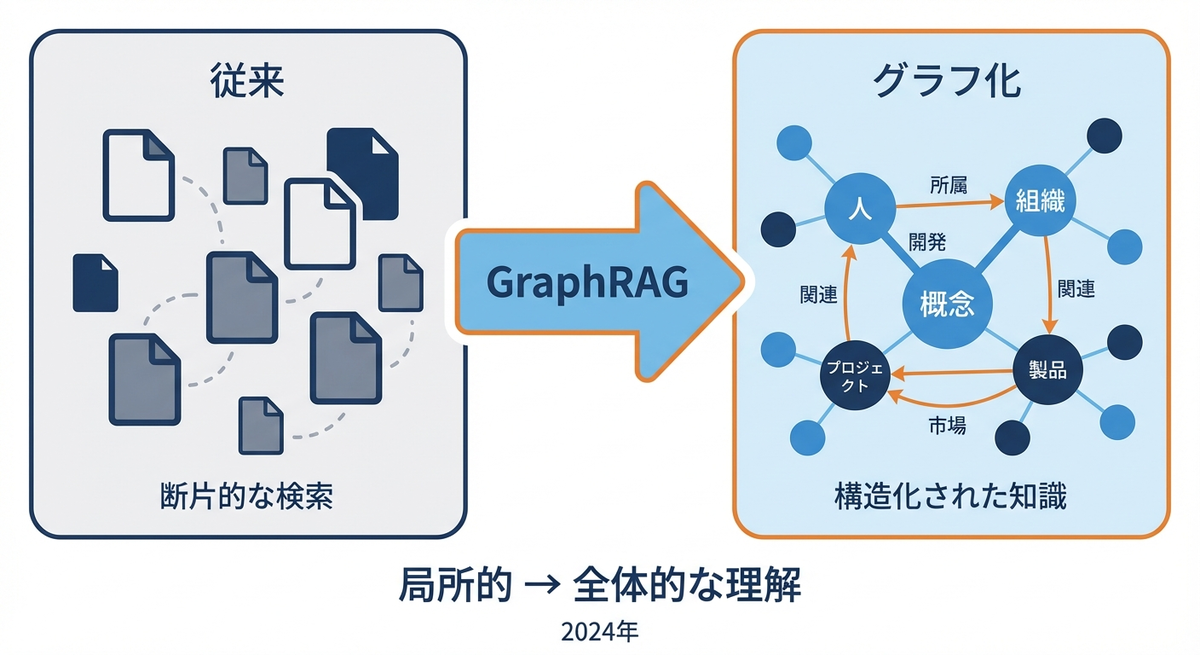
GraphRAGは、知識グラフ(Knowledge Graph)を使ってRAGの検索精度を高める手法です。
従来のベクトル検索ベースのRAGには、以下の限界がありました。
- 局所的な情報のみを取得し、全体的な文脈を捉えにくい
- エンティティ間の関係性を明示的に扱えない
- 「データセット全体についての質問」に弱い
GraphRAGは、以下のプロセスで知識グラフを構築・利用します。
- エンティティ抽出: LLMを使用して文書からエンティティと関係を抽出
- グラフ構築: 抽出された情報から知識グラフを構築
- コミュニティ検出: グラフをクラスタリングし、階層的なコミュニティ構造を特定
- コミュニティ要約: 各コミュニティについてLLMで要約を生成
- 検索と生成: クエリに関連するコミュニティ要約を検索し、回答を生成
グローバルな質問(例:「このデータセットの主要なテーマは何か」)に対応できる点がポイントです。コミュニティ要約を使うことで、データセット全体を見た回答ができます。
RAGの進化における位置づけ
GraphRAGは、構造化された知識表現をRAGに取り入れた研究です。ベクトル検索だけでは捉えられない、エンティティ間の関係性や階層構造を使えるようになりました。
Microsoftが提供するGraphRAGの実装は、オープンソースとして公開されており、実際の業務システムへの適用も進んでいます。
Modular RAG:モジュール式の柔軟な組み立て
| 項目 |
内容 |
| 論文タイトル |
Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks |
| 著者/組織 |
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, Haofen Wang / Tongji University, Fudan University |
| 発表時期 |
2024年7月 |
| arXiv |
https://arxiv.org/abs/2407.21059 |
主要な貢献・技術的特徴
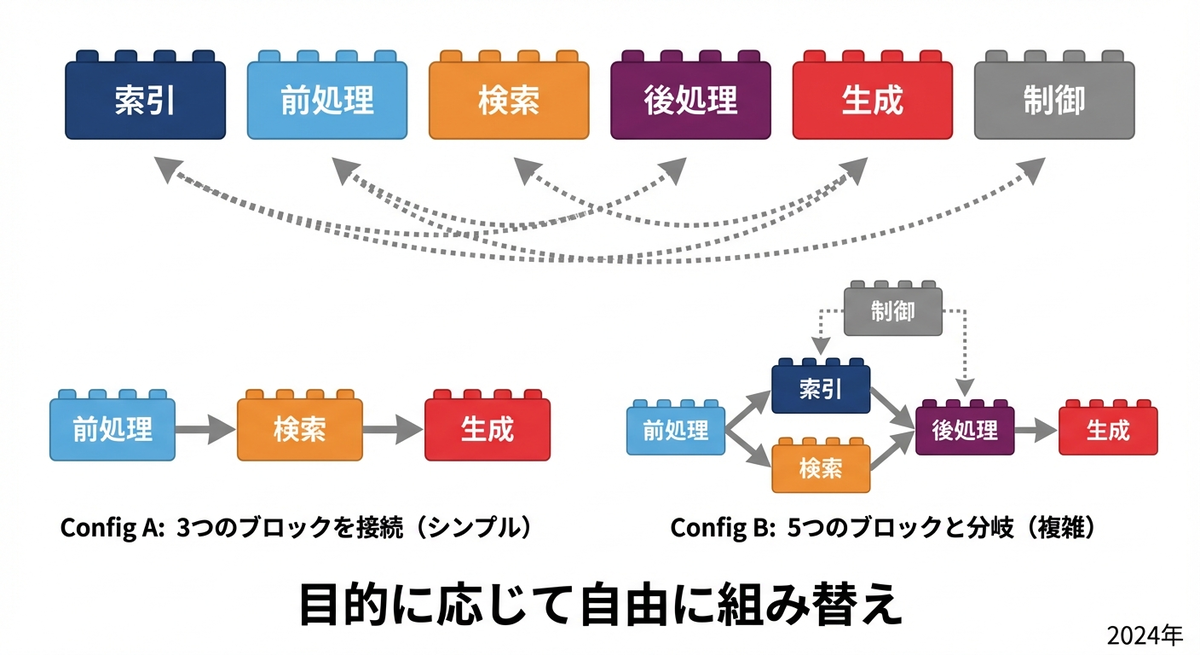
Modular RAGは、RAGシステムをモジュール化し、部品を組み替えるように柔軟に構成できるフレームワークを提案しています。
RAGの研究が進むにつれ、様々な手法が提案されてきましたが、それらを整理・比較することが難しくなっていました。Modular RAGは、RAGシステムを6つの主要モジュールに分解します。
| モジュール |
役割 |
| Indexing(インデクシング) |
文書のチャンキング、埋め込み、インデックス構築 |
| Pre-retrieval(検索前処理) |
クエリ拡張、クエリ変換、クエリルーティング |
| Retrieval(検索) |
ベクトル検索、キーワード検索、ハイブリッド検索 |
| Post-retrieval(検索後処理) |
リランキング、フィルタリング、圧縮 |
| Generation(生成) |
プロンプト構築、LLMによる回答生成 |
| Orchestration(オーケストレーション) |
各モジュールの制御フロー管理 |
各モジュール内には複数のサブモジュール(オペレーター)が存在し、用途に応じて組み合わせを変更できます。たとえば、検索前処理としてHyDEを使うか、クエリ分解を使うかを選択できます。
RAGの進化における位置づけ
Modular RAGは、RAG研究を整理し、統一的なフレームワークを提案しました。メリットは以下です。
- 既存手法の分類と比較がしやすくなった
- 新しい手法の位置づけがわかりやすくなった
- 実装時のアーキテクチャ設計の参考になる
この論文は、RAGが単一の技術から、複数のコンポーネントを組み合わせたパイプライン設計へと変わってきたことを示しています。
最新動向(2025-2026年)
2025年以降、RAGは単なる検索拡張生成を超えて、エージェント型アーキテクチャやマルチモーダル対応へと広がっています。そして、RAGは「コンテキストエンジニアリング」というより広い概念の一部として捉えられるようになっています。
Agentic RAG Survey:エージェント型RAGの台頭
| 項目 |
内容 |
| 論文タイトル |
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG |
| 著者/組織 |
Aditi Singh, Abul Ehtesham, Saket Kumar, Tala Talaei Khoei |
| 発表時期 |
2025年1月 |
| arXiv |
https://arxiv.org/abs/2501.09136 |
主要な貢献・技術的特徴
このサーベイ論文は、Agentic RAG(エージェント型RAG)についてまとめています。
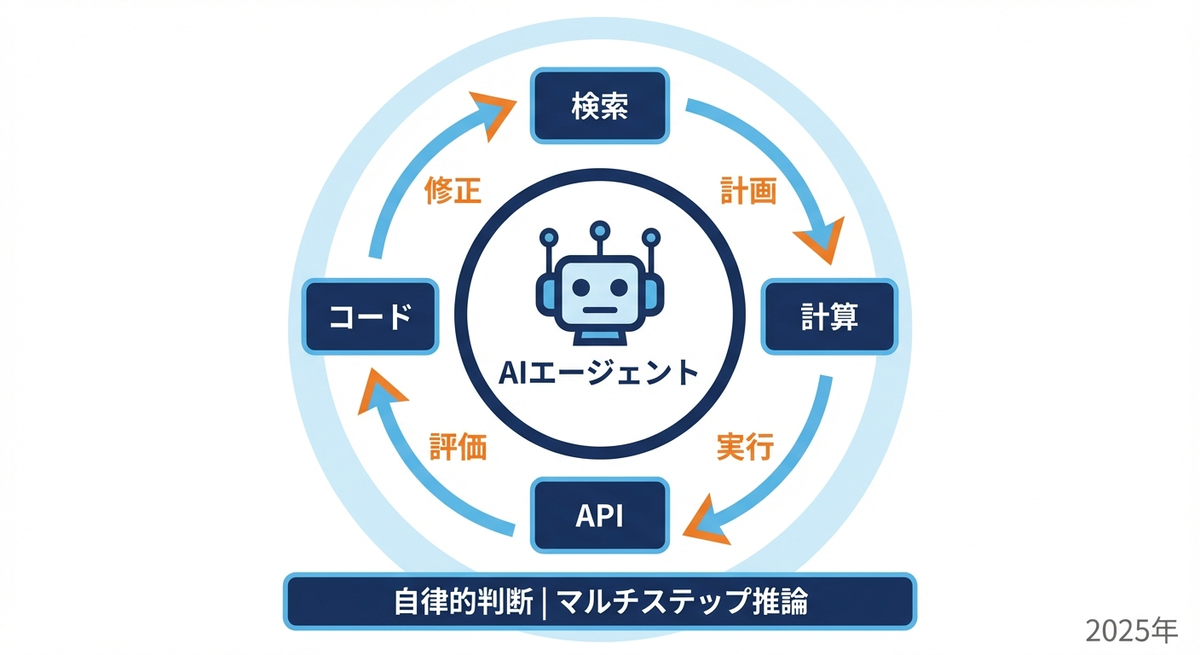
エージェント型RAGは、LLMエージェントの能力をRAGに統合したものです。従来のRAGが「検索→生成」という固定的なパイプラインであったのに対し、エージェント型RAGは以下の特徴を持ちます。
- 自律的な判断: 検索するか否か、いつ検索するか、何を検索するかをエージェントが自律的に決定
- ツール使用: 検索以外にも、計算、API呼び出し、コード実行などのツールを使う
- マルチステップ推論: 複雑なタスクを複数のステップに分解し、段階的に解決
- 自己修正: 結果を評価し、必要に応じて戦略を修正
サーベイでは、エージェント型RAGのアーキテクチャを以下のように分類しています。
| タイプ |
説明 |
| 単一エージェント型 |
1つのエージェントがすべての処理を担当 |
| マルチエージェント型 |
複数の専門エージェントが協調して処理 |
| 階層型 |
エージェントが階層構造を持ち、上位が下位を制御 |
RAGの進化における位置づけ
このサーベイは、RAGが静的なパイプラインから動的なエージェントシステムへと変わってきた流れを整理しています。Self-RAGやAdaptive-RAGで見られた「適応的な判断」が、より一般的なエージェントフレームワークの中で扱われるようになりました。
実際のアプリケーションでも、LangGraphやCrewAIなどのエージェントフレームワークとRAGを組み合わせた実装が増えています。
Multimodal RAG Survey:テキストを超えた検索拡張
| 項目 |
内容 |
| 論文タイトル |
A Survey of Multimodal Retrieval-Augmented Generation |
| 著者/組織 |
Lang Mei, Siyu Mo, Zhihan Yang, Chong Chen |
| 発表時期 |
2025年4月 |
| arXiv |
https://arxiv.org/abs/2504.08748 |
主要な貢献・技術的特徴
このサーベイは、マルチモーダルRAG(画像、音声、動画などを扱うRAG)についてまとめています。
テキストのみを扱う従来のRAGに対し、マルチモーダルRAGは以下の入出力を扱います。
- 入力: テキスト、画像、音声、動画、表、グラフなど
- 検索対象: マルチモーダルな知識ベース(文書+図表、動画アーカイブなど)
- 出力: テキスト回答、画像生成、マルチモーダルな回答
技術的な課題として、以下があります。
| 課題 |
説明 |
| モダリティ間のアラインメント |
異なるモダリティの情報を統一的な埋め込み空間にマッピング |
| クロスモーダル検索 |
テキストクエリで画像を検索、画像クエリでテキストを検索など |
| マルチモーダル融合 |
複数モダリティからの情報を統合して生成 |
CLIPやBLIPなどの視覚言語モデル、マルチモーダルLLMが出てきたことで、マルチモーダルRAGの実用化が進んでいます。
RAGの進化における位置づけ
マルチモーダルRAGにより、RAGの適用範囲が広がっています。ドキュメントに含まれる図表やグラフ、製品カタログの画像、教育コンテンツの動画など、テキストだけでは表現できない情報を使えるようになりました。
Vision-Language Model(VLM)が出てきたことで、従来はOCRやキャプション生成が必要だった画像情報を、直接理解・検索できるようになっています。
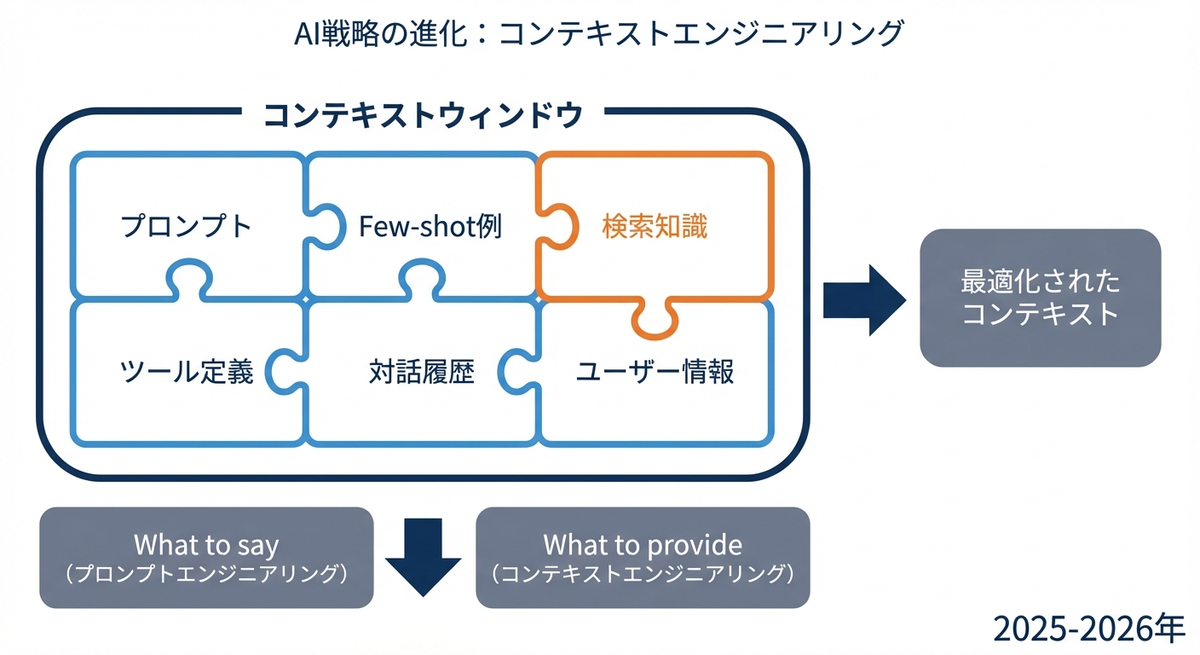
Context Engineering Survey:より広い枠組みへの位置づけ
| 項目 |
内容 |
| 論文タイトル |
A Survey of Context Engineering for Large Language Models |
| 著者/組織 |
Lingrui Mei, Jiayu Yao, Yuyao Ge 他 |
| 発表時期 |
2025年7月 |
| arXiv |
https://arxiv.org/abs/2507.13334 |
主要な貢献・技術的特徴
このサーベイは、コンテキストエンジニアリングという概念を整理し、RAGを含むより広い枠組みをまとめています。
コンテキストエンジニアリングとは、LLMに提供するコンテキスト(入力情報)をうまく構成するためのアプローチです。RAGはコンテキストエンジニアリングの一部であり、他にも以下の要素が含まれます。
| 要素 |
説明 |
| システムプロンプト |
LLMの振る舞いを定義する指示 |
| 具体例の提示 |
タスクの例示(Few-shot) |
| 検索された知識 |
RAGによる外部知識(従来のRAG) |
| ツール定義 |
利用可能なツールの定義 |
| 対話履歴 |
過去の対話履歴 |
| 作業メモリ |
エージェントの作業メモリ |
| ユーザー情報 |
ユーザーの属性や過去の行動履歴 |
コンテキストエンジニアリングの課題は、限られたコンテキストウィンドウの中で、最も効果的な情報の組み合わせを見つけることです。
サーベイでは、以下の研究方向が示されています。
- コンテキスト圧縮: 重要な情報を保持しながらトークン数を削減
- コンテキスト選択: どの情報をコンテキストに含めるか動的に判断
- コンテキストキャッシング: 頻繁に使用するコンテキストを効率的に再利用
- ロングコンテキストの利用: 100K以上のコンテキストウィンドウを効果的に使う
RAGの進化における位置づけ
このサーベイは、RAGがコンテキストエンジニアリングの中に位置づけられる流れを追っています。
RAGは「検索した情報をコンテキストに追加する」という単一の手法でしたが、コンテキストエンジニアリングは「LLMのコンテキストをどう構成するか」というより根本的な問いを扱っています。
プロンプトエンジニアリングが「何を指示するか」に焦点を当てていたのに対し、コンテキストエンジニアリングは「どのような情報を与えるか」に焦点を当てています。
まとめ:RAGの進化とこれから
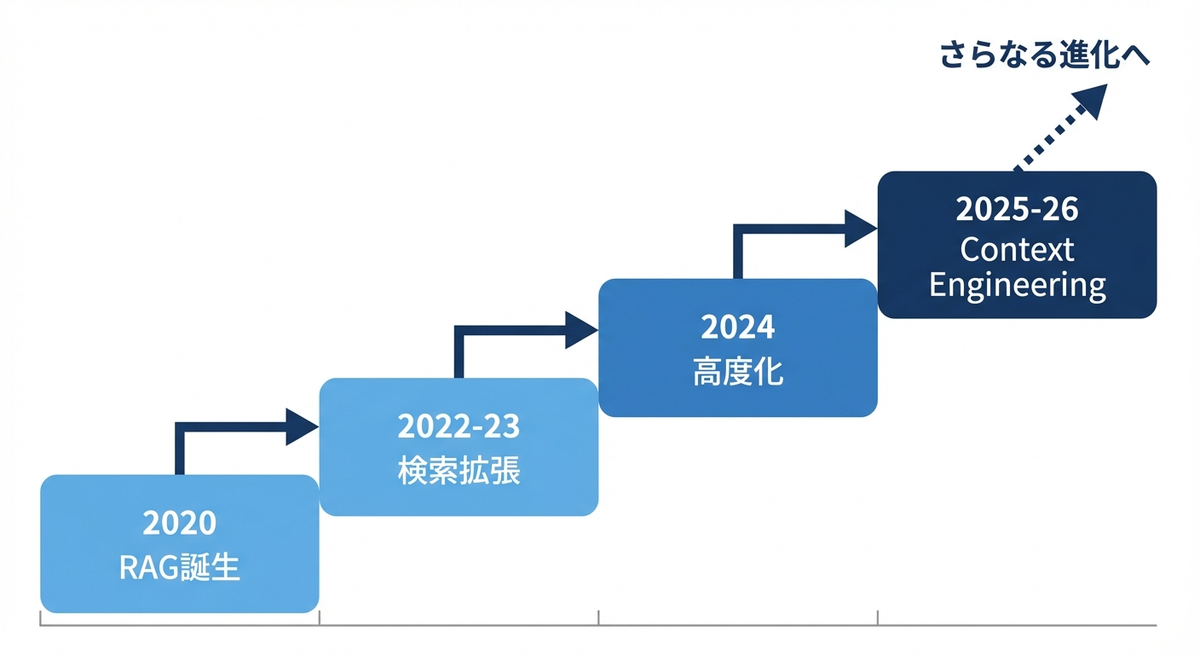
本記事では、2020年のRAG誕生から2025年のコンテキストエンジニアリングへの位置づけまで、主要な論文とともに振り返りました。
RAGの進化の軌跡
| 時期 |
フェーズ |
主要論文 |
キーワード |
| 2020年2月 |
前史・基盤技術 |
REALM |
検索を事前学習に統合 |
| 2020年4月 |
|
DPR |
密ベクトル検索の基盤 |
| 2020年5月 |
RAGの誕生 |
RAG原論文 |
用語と概念の確立 |
| 2022年12月 |
検索拡張の広がり |
HyDE |
仮説的文書による検索改善 |
| 2023年5月 |
|
FLARE |
能動的な前向き検索 |
| 2023年10月 |
|
Self-RAG |
自己反省による品質向上 |
| 2024年1月 |
高度なRAG手法 |
CRAG |
検索結果の訂正メカニズム |
| 2024年3月 |
|
Adaptive-RAG |
クエリに応じた動的戦略 |
| 2024年4月 |
|
GraphRAG |
知識グラフによる構造化検索 |
| 2024年7月 |
|
Modular RAG |
モジュール式の柔軟な設計 |
| 2025年1月 |
新しいパラダイム |
Agentic RAG Survey |
エージェント型RAGの台頭 |
| 2025年4月 |
|
Multimodal RAG Survey |
テキストを超えた検索拡張 |
| 2025年7月 |
|
Context Engineering Survey |
コンテキストエンジニアリングの整理 |
今後の展望
RAGは今後も改良が続くと思います。今後の方向性としては以下があります。
エージェントとの統合: RAGはエージェントの「記憶」として機能し、より自律的なシステムの一部になっていく
マルチモーダル対応: テキスト以外のモダリティを扱うことが当たり前になる
効率性の改善: 長いコンテキストウィンドウを効率的に使う技術が進む
評価手法の整備: RAGシステムの品質を定量的に評価する方法が整っていく
RAGは単なる技術的手法から、LLMアプリケーション開発における基本的な設計パターンになりました。コンテキストエンジニアリングというより広い枠組みの中で、RAGの知見は今後も使われていくと思います。
一緒に働きませんか?
Algomatic AXカンパニーでは、RAGやLLMアプリケーション開発に興味のあるエンジニアを募集しています。興味のある方はぜひご応募ください。
algomatic.notion.site