
はじめに
こんにちは、株式会社ACES でテックリードをしている福澤 (@fuku_tech) です!
本シリーズでは、AI駆動開発における人間とAIの役割分担を、自動運転になぞらえた4つのPhaseで整理しています(詳細は下図を参照)。

本記事は#3・#4で整備した品質ゲートの上に、リリース安全基盤を積み上げる話のため、以下を先にお読みいただくとよりスムーズです。
前回の記事では、AIが自律的に実装を回し人間は要所でレビューする開発スタイルを実際にチームで運用してみた成果と摩擦を率直にお伝えしました。品質ゲート(Lint・Tests・セルフレビュー・別LLMレビュー)による予防が機能し運用開始以来AI実装起因のインシデントは0件という実績を積めた一方で、AIが品質ゲートを通過したPRを量産しても人間側のレビューが追いつかず「これ本当に出して大丈夫か?」という不安も拭えないという課題が残りました。暫定的にタスク分解やPR分割で凌いではいるものの、これは人間の介入を増やす方向の対処であり、スケールする解ではないと感じていました。
シリーズ初回で「壊れたときどう直すか」として予告した問いを、ここで回収します。「壊れないようにする」だけでは限界がある。発想を転換して「壊れても速く直せる」仕組みを作ることで、AIへの委譲範囲をさらに広げていく。この記事では、その設計と構築の現在地をお伝えします。
発想の転換: 「壊れないようにする」から「壊れても速く直せる」へ
#3・#4で整備した品質ゲート(Lint・Tests・セルフレビュー・別LLMレビュー)は、コードレベルの予防策として確かに機能しています。E2Eテストなど統合レベルの検証強化も今後の投資対象ですが、本記事ではその先のレイヤー、つまりリリース後の検知・復旧の仕組みに焦点を当てます。
さらに、本番トラフィックでのみ顕在化するパフォーマンス劣化や、長時間稼働で初めて現れるメモリリークといった、コードレビューだけでは見えないリスクもあります。AIが書いたコードが機能テストを通過していても、本番環境で想定外の負荷を生むかもしれません。これは人間が書いたコードでも同じですが、AI生成コードの量が増えるほどリスクの総量も増えていきます。
ここで発想を転換しました。安全の判断基準を「人間の目」から「データとシステム」に移す。具体的には、壊れないようにすることに全力を注ぐのではなく、壊れたときに速く検知し速く戻せる仕組みを作ることで、「これ出して大丈夫か?」という不安を「なんとなく怖い」から数値に基づく判断に置き換えていきます。そうすれば、人間がコードの一行一行を見なくても、AIへの委譲範囲をさらに広げていけるはずです。
リリース安全基盤の現在地
この発想の転換を実現するために、私たちはリリース安全基盤を段階的に積み上げています。すでに運用実績のあるものから、まだ手をつけていないものまで成熟度に差があります。現在地を正直にお伝えします。
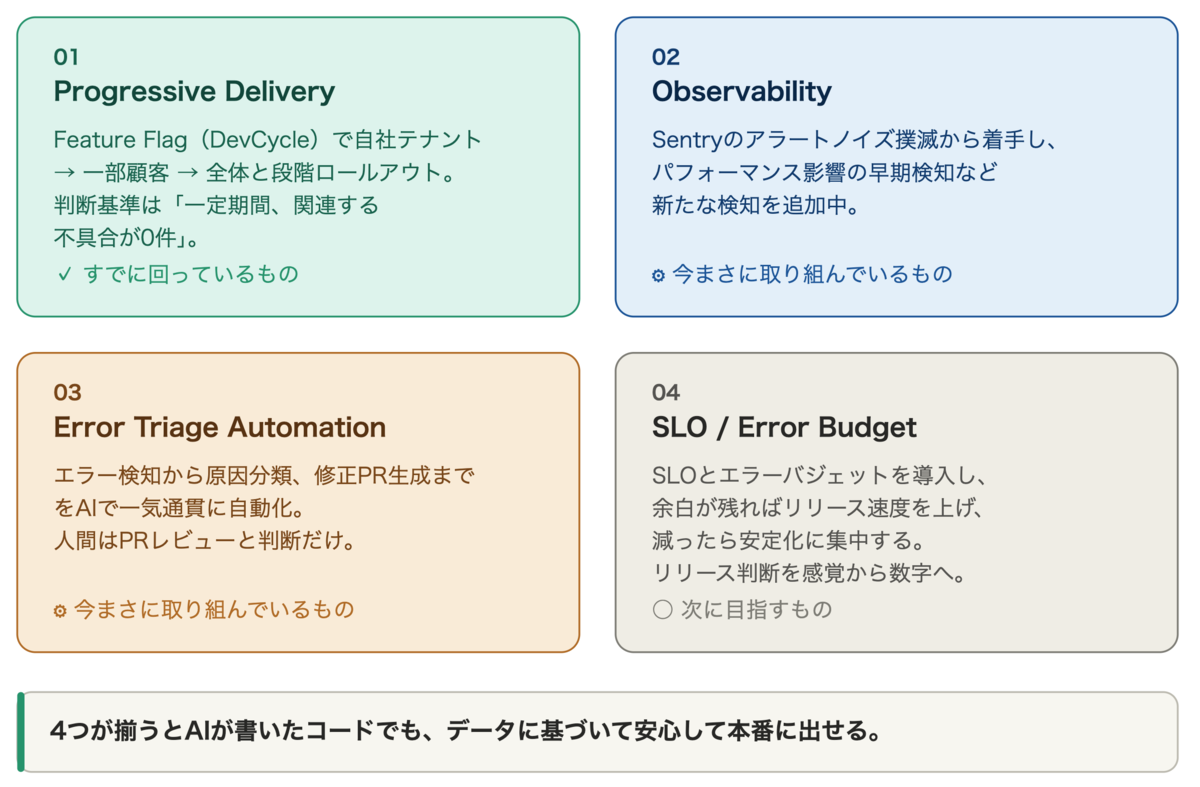
01 Progressive Delivery: Feature Flagで段階ロールアウト
Feature Flagサービス(DevCycle)は、AI活用が本格化する以前から導入済みです。自社テナントのみに先行公開し、エラーレートなどを監視しながら段階的にロールアウトしていく、いわゆるProgressive Deliveryの運用がすでに回っています。ロールアウトのステップは「自社テナントのみ → 一部顧客 → 全体」で、判断基準は「一定期間、関連する不具合が0件であること」としています。
直近の実績として、コア機能である音声解析周りの改修でこの仕組みが効きました。自社テナントのみに先行リリースしたところエラーを検知し、修正後に改めてロールアウトを進めて安全にリリースを完了しています。この事例はAI生成コードによるものではありませんが、すでに回っている運用をAI生成コードのリリースにもそのまま適用できるという確信を持てました。現在、AI生成コードのリリースにFeature Flagをどう組み込むかの検討を始めたところです。
02 Observability: アラートの信頼性確保と異常検知
監視・検知の基盤が機能するには、まずアラートが信頼できる状態でなければなりません。Sentryのアラートノイズ撲滅から着手し、ClaudeのSlack連携を使ってノイズアラート(対応不要なのに繰り返し発火するアラート)をコツコツ潰しているところです。地味ですが、ここを丁寧に整えることが安全基盤の土台になります。
その上で、SentryのTrace機能を使ったN+1クエリの検知など、新たな検知の追加を進めています。これはAI生成コード固有の話ではなく、プロダクト全体の検知能力を底上げする取り組みですが、AI駆動開発の安全基盤としてもこの基盤が効いてきます。
03 Error Triage Automation: 検知から修正PRまでの自動化
アラートの信頼性確保と並行して、検知から修正提案までを一気通貫で回すワークフローの構築を進めています。GitHub Actionsで定期的にSentryを監視し、新規エラーを検知したらIssueを自動作成します。その際にClaude APIでエラーの原因調査と修正方針の起案を行い、改善PRの生成まで自動化する設計で、最終的には人間がPRをレビューして判断します。
まだ検証段階ですが、このパイプラインが回り始めれば、エラーの検知から修正PRの作成までの時間を大幅に短縮できる見込みです。
04 SLO / Error Budget: データ駆動のリリース判断
ここまで述べた仕組みが揃ってきたとき、次に必要になるのはリリース可否の判断基準です。現在のロールアウト判断は不具合0件かどうかのオール・オア・ナッシングですが、これだけではリリース速度と安定性のバランスを柔軟にコントロールできません。そこで目指しているのが、SLO(サービスレベル目標)とエラーバジェットの導入です。たとえば可用性99.9%とSLOを設定すると、月あたり約43分のダウンタイムが許容されます。この許容される余白がエラーバジェットです。余白が十分残っていればリリース速度を上げ、減ってきたら安定化に集中する。リリース判断を感覚ではなく数字で行えるようにする仕組みです。これをAI駆動開発の文脈で設計していく段階です。
これで何が変わるのか
前回の記事で悩んでいた課題に、ここまで述べたリリース安全基盤がどう答えるのかを整理します。
まず、巨大PR問題です。PRの粒度を小さく保つ努力は引き続き重要ですが、Feature Flagによる段階ロールアウトと高速ロールバックの仕組みが整えば、仮にPRが大きくなっても致命傷にはなりません。PRの粒度だけに安全を依存しない構造を作ることが狙いです。
次に、レビューが追いつかない問題です。リリース安全基盤が整うと、レビューの焦点がコードの一行一行から、段階ロールアウトの各ステップの判断に移ります。人間の介入ポイントが減ることで、AIへの委譲範囲を広げられます。
そして、出して大丈夫かという不安です。品質ゲートを通過していて、段階ロールアウトで実際の挙動も確認できていれば、Go判断はずっとしやすくなります。さらにSLO/エラーバジェットが整えば、その判断を数字で裏付けることもできるようになります。まだこの段階には到達していませんが、目指している方向はここです。
その先に見える世界
ここまで述べたリリース安全基盤が整った先には、さらなる自動化が見えています。
1つは、Feature Flagの操作自体をAIに委ねることです。AIが段階ロールアウトの各ステップをメトリクスに基づいて自律的に判断し、異常を検知したら自動でロールバックする*1。まずは既存機能のロールアウト拡大のような定型的な判断から段階的に自動化し、不確実性の高い判断は人間が行うという線引きで、自律性の範囲を慎重に広げていく方針です。
もう1つは、AIが生ログに瞬時にアクセスできる環境の整備です。SentryだけでなくCloudWatchやGrafanaなど、複数の監視基盤のログをAIがリアルタイムに確認できるようになれば、sandbox環境でのリリース前検証でも本番環境でのリリース後監視でも、AIが自律的にフィードバックサイクルを回せるようになります。
この2つが揃うと、AIが自分でコードを書き、自分で検証し、自分でリリースし、問題があれば自分で直すというループが成立します。人間に残るのは最終承認と、ループ自体の設計・改善です。
おわりに
シリーズ初回からここまで振り返ると、一つのストーリーが見えてきます。Phase 1→2で何をAIに任せるかを整理し、Phase 2→3でどうすれば安全に任せ切れるかを設計し、そしてPhase 3→4で壊れたときどう直すかに向き合っています。各Phaseで手放してきたのは、全部自分で書く、自分がやった方が早い、壊れないようにする、という、それぞれの段階で当たり前だった前提です。
そして今、人間がコードを見なければ安全は担保できないという前提を手放そうとしています。この前提が手放せたとき、AIが長時間自律的に稼働するPhase 4への道が開けます。データとシステムに安全の判断を委ねられれば、AIへの委譲範囲はさらに広がります。そのための基盤づくりはまだ始まったばかりで、正直まだまだ足りないことだらけです。ただ、この記事で語ったFeature Flagやアラート整備は、AI時代に突然必要になったものではなく、ずっと大事だったものがAI時代にさらに重要になっただけです。まっとうなエンジニアリングプラクティスこそが、最大の武器だと考えています。
ここまで語ってきたのは、1つのチームの実践です。次回の #6|1チームの実践を、組織の力に変える(2026/03/25公開予定)では、この実践を組織全体に横展開するために何が必要かを語ります。
ACESでは現在、複数のエンジニアポジションで採用を行っています。本シリーズを読んでACESの開発に興味を持っていただけた方は、ぜひカジュアル面談でお話ししましょう!
ACESの採用情報はこちら↓
