BigQueryのパーティションについてのメモ
やりたいこと
BigQueryにレポートなどの日次データを持たせているテーブルで特定日付のバッチ処理のみ再実行できるようにしたい
パーティション分割について
そもそもBigQueryのパーティションには色々種類があるようで使い分ける必要がある
日付 / タイムスタンプ パーティション分割テーブルの作成と使用 | BigQuery | Google Cloud
今回は日付 / タイムスタンプ パーティション分割テーブルに関しての話とする
たとえば適当なjsonからデータを入れ込む際、日付の列に対してパーティションを設定する場合
Embulkを使うと下記のように設定できる
- date列を日付パーティションとして扱うときのEmbulk設定例
out: type: bigquery project: {{ env.PROJECT_ID }} mode: replace dataset: blog_data table: ga_events location: asia-northeast1 compression: GZIP auto_create_table: true source_format: NEWLINE_DELIMITED_JSON auth_method: service_account json_keyfile: {{ env.GOOGLE_APPLICATION_CREDENTIALS }} time_partitioning: type: DAY field: date
ただこの使用方法だとreplaceで特定の日付だけ入れ込み直すといったことができない
実行するとreplaceがあるので全データを洗い替え対象としてしまう
パーティション デコレータ
そういう場合下記のようにパーティションデコレータを用いてテーブル名を指定することで特定のパーティションに対して操作が行える
日付 / タイムスタンプ パーティション分割テーブルの作成と使用 | BigQuery | Google Cloud
table_name$20200801というような感じでsuffixに日付情報を指定することで特定の日付のデータに対してloadできる
なのでバッチの再実行などで特定の日付だけデータを入れ替えるといったことが可能になる
便利
Embulk設定例
Embulkでやる場合
例で挙げた設定との差分
out:
type: bigquery
project: {{ env.PROJECT_ID }}
mode: replace
dataset: blog_data
- table: ga_events
+ table: ga_events$20200801
location: asia-northeast1
compression: GZIP
auto_create_table: true
source_format: NEWLINE_DELIMITED_JSON
auth_method: service_account
json_keyfile: {{ env.GOOGLE_APPLICATION_CREDENTIALS }}
time_partitioning:
type: DAY
field: date
テーブル名に$を含めることでパーティションということを明示的にする
実際に使う場合は日付の部分を{{ env.TARGET_DATE }}のようにし環境変数から日付を指定、対象日数分Embulkを実行する
table: ga_events${{ env.TARGET_DATE }}
こんな感じ
bq コマンドで試す
Embulkだと裏でよしなにやってくれている可能性があるのでCLI経由でも試してみる
テーブルの作成
$ bq mk -t \ --schema 'dt:DATE,column1:STRING,column2:INTEGER' \ --time_partitioning_field dt \ --time_partitioning_type DAY \ --require_partition_filter \ --description "This is my partitioned table" \ --label org:dev \ sample.pt_sample
確認する
$ bq show --schema --format=prettyjson demo-000000:sample.pt_sample
[
{
"name": "dt",
"type": "DATE"
},
{
"name": "column1",
"type": "STRING"
},
{
"name": "column2",
"type": "INTEGER"
}
]
bq loadでロードする
適当にデータを用意してデータを入れてみる
$ cat 0921.jsonl.json
{"dt":"2020-09-21","column1":"hoge","column2":5}
{"dt":"2020-09-21","column1":"fuga","column2":3}
$ cat 0920.jsonl.json
{"dt":"2020-09-20","column1":"hoge","column2":1}
{"dt":"2020-09-20","column1":"fuga","column2":2}
$ bq load \ --replace \ --source_format=NEWLINE_DELIMITED_JSON \ 'sample.pt_sample$20200921' \ ./0921.jsonl.json $ bq load \ --replace \ --source_format=NEWLINE_DELIMITED_JSON \ 'sample.pt_sample$20200920' \ ./0920.jsonl.json
ドキュメントにも載っているがパーティションデコレータで指定している日付と実際のデータの内容が違う場合は怒られる
- パーティションデコレータは
20200920、データは2020-09-21の場合
$ bq load \ --replace \ --source_format=NEWLINE_DELIMITED_JSON \ 'sample.pt_sample$20200920' \ ./0921.jsonl.json Upload complete. Waiting on bqjob_r7acb71eae2ecc487_00000174b42c14c1_1 ... (0s) Current status: DONE BigQuery error in load operation: Error processing job 'demo-000000:bqjob_r7acb71eae2ecc487_00000174b42c14c1_1': Some rows belong to different partitions rather than destination partition 20200920
headで確認する
$ bq head --format=prettyjson --max_rows 10 'demo-000000:sample.pt_sample$20200921'
[
{
"column1": "hoge",
"column2": "5",
"dt": "2020-09-21"
},
{
"column1": "fuga",
"column2": "3",
"dt": "2020-09-21"
}
]
select
Web UIからクエリをたたいてみる
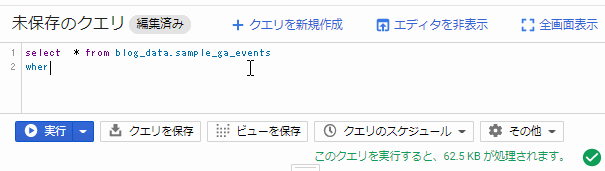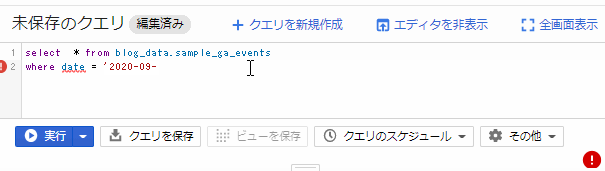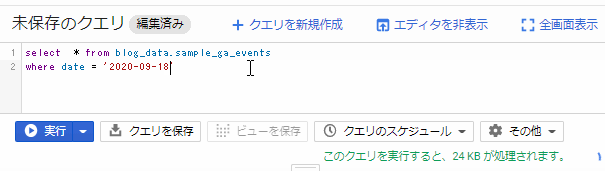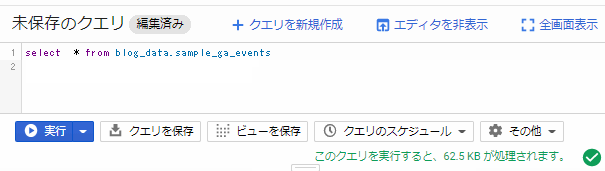
蛇足だがこの容量計算はクエリを書きながらリアルタイムで計算してくれるようでびっくりした
とても使いやすいと感じた
DataPortalからの利用
DataPortalから読み込む場合はデータソース追加時にパーティション列を使用する設定があるのでチェックする

まとめ
- パーティションデコレータを使用してパーティションテーブルへの書き込みを行った
- bqコマンドでパーティションデコレータを使用したテーブルを作成し特定パーティションへの書き込みを行った
- Embulkでパーティションデコレータを使用したテーブルを作成し特定パーティションへの書き込みを行った
- Web UIからselectを実行しクエリ対象データが絞り込まれていることを確認した
- DataPortalでのBigQueryテーブルの設定を確認した
所感
今回はGAのイベントデータをBigQueryに突っ込むため色々調べた
パーティションデコレータ便利
こういうのサンプル動かしただけだと調べるところまで行き着かないので今後も実運用まで考えられるように手を動かしていきたい
また、BigQueryに対して特定のレコードのみ更新するなどの差分更新もできるようになっているみたいなのでそちらも調べて使いたい
今までGCSへ日付ごとにディレクトリ切ってloadする方法しか使っていなかったためGCSのオペレーション料金が少し掛かっていたので折を見て方法を変えていけたらと思う
今回調べていくにあたり取り込み時間パーティションと日付/タイムスタンプパーティションの違いがわからず時間を消費したので別途調べてまとめる
