以下のYoutubuで紹介されていたRのqualitytoolsライブラリを用いる。
www.youtube.com
以下の例題をもとに実装する。
tech-oh.com
Rで必要なライブラリをインストールし、読み込む。
install.packages("devtools")
library(devtools)
install_github("cran/qualityTools")
if(!require(tidyr)){install.packages("tidyr")}
if(!require(dplyr)){install.packages("dplyr")}
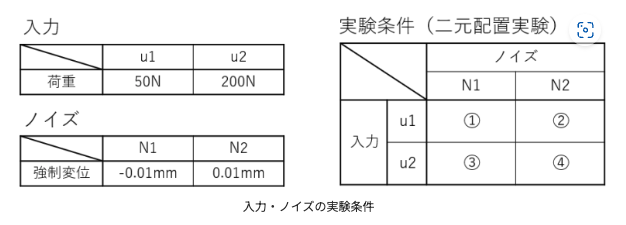
library(qualityTools)まず、混合系直交表L18を作成する。
混合系とは、含まれる因子のレベルが列ごとに異なるもの。
以下の例では第1列が2個の因子レベル(1,2)、第2列から第8列までが3個の因子レベル(1,2,3)から成っている。

また、入力に2因子、ノイズに2因子を考慮した2元配置実験を考える。
この直交表を用い、実験値を記録すると以下のようになる。

スクショだと不便なので、Claudeを用いてCSVに変換した。
サンプルNo. 未使用 A B C D E F G u1 N1 u1 N2 u2 N1 u2 N2 1 1 1 1 1 1 1 1 1 15.93 -10.84 25.4 -6.66 2 1 1 2 2 2 2 2 2 16.61 -12.59 24.92 -4.57 3 1 1 3 3 3 3 3 3 17.32 -13.96 24.04 -7.24 4 1 2 1 1 2 2 3 3 15.72 -12.17 22.82 -5.06 5 1 2 2 2 3 3 1 1 16.37 -13.2 22.71 -6.86 6 1 2 3 3 1 1 2 2 16.88 -13.44 23.77 -6.56 7 1 3 1 2 1 3 3 3 15.38 -12.26 21.6 -6.04 8 1 3 2 3 2 1 3 1 16.4 -13.35 22.51 -7.24 9 1 3 3 1 3 2 1 2 17.01 -14.09 22.84 -8.26 10 2 1 1 3 3 2 2 1 16.82 -12.57 25.32 -4.07 11 2 1 2 1 1 3 3 2 16.05 -12.19 23.02 -4.44 12 2 1 3 2 2 1 1 3 17.21 -12.94 27.23 -4.4 13 2 2 1 2 3 1 3 2 16.43 -12.61 24.07 -4.97 14 2 2 2 3 1 2 1 3 16.55 -13.06 23.51 -6.09 15 2 2 3 1 2 3 2 1 16.58 -13.57 22.59 -7.56 16 2 3 1 3 2 3 1 1 15.82 -12.66 22.17 -6.3 17 2 3 2 1 3 1 2 3 16.48 -13.29 22.85 -6.93 18 2 3 3 2 1 2 3 1 16.36 -13.63 21.83 -8.16
さて、以下でタグチデザインオブジェクトを作成する。
tdo = taguchiDesign(design="L18_2",randomize=F,replicates=4) tdo StandOrder RunOrder Replicate A B C D E F G H y 1 1 1 1 1 1 1 1 1 1 1 1 NA 2 2 2 1 1 1 2 2 2 2 2 2 NA 3 3 3 1 1 1 3 3 3 3 3 3 NA 4 4 4 1 1 2 1 1 2 2 3 3 NA 5 5 5 1 1 2 2 2 3 3 1 2 NA 6 6 6 1 1 2 3 3 1 1 2 1 NA 7 7 7 1 1 3 1 2 1 3 2 3 NA 8 8 8 1 1 3 2 3 2 1 3 1 NA 9 9 9 1 1 3 3 1 3 2 1 2 NA 10 10 10 1 2 1 1 3 3 2 2 1 NA 11 11 11 1 2 1 2 1 1 3 3 2 NA 12 12 12 1 2 1 3 2 2 1 1 3 NA 13 13 13 1 2 2 1 2 3 1 3 2 NA 14 14 14 1 2 2 2 3 1 2 1 3 NA 15 15 15 1 2 2 3 1 2 3 2 1 NA 16 16 16 1 2 3 1 3 2 3 1 2 NA 17 17 17 1 2 3 2 1 3 1 2 3 NA 18 18 18 1 2 3 3 2 1 2 3 1 NA 19 19 19 2 1 1 1 1 1 1 1 1 NA 20 20 20 2 1 1 2 2 2 2 2 2 NA 21 21 21 2 1 1 3 3 3 3 3 3 NA 22 22 22 2 1 2 1 1 2 2 3 3 NA 23 23 23 2 1 2 2 2 3 3 1 2 NA 24 24 24 2 1 2 3 3 1 1 2 1 NA 25 25 25 2 1 3 1 2 1 3 2 3 NA 26 26 26 2 1 3 2 3 2 1 3 1 NA 27 27 27 2 1 3 3 1 3 2 1 2 NA 28 28 28 2 2 1 1 3 3 2 2 1 NA 29 29 29 2 2 1 2 1 1 3 3 2 NA 30 30 30 2 2 1 3 2 2 1 1 3 NA 31 31 31 2 2 2 1 2 3 1 3 2 NA 32 32 32 2 2 2 2 3 1 2 1 3 NA 33 33 33 2 2 2 3 1 2 3 2 1 NA 34 34 34 2 2 3 1 3 2 3 1 2 NA 35 35 35 2 2 3 2 1 3 1 2 3 NA 36 36 36 2 2 3 3 2 1 2 3 1 NA 37 37 37 3 1 1 1 1 1 1 1 1 NA 38 38 38 3 1 1 2 2 2 2 2 2 NA 39 39 39 3 1 1 3 3 3 3 3 3 NA 40 40 40 3 1 2 1 1 2 2 3 3 NA 41 41 41 3 1 2 2 2 3 3 1 2 NA 42 42 42 3 1 2 3 3 1 1 2 1 NA 43 43 43 3 1 3 1 2 1 3 2 3 NA 44 44 44 3 1 3 2 3 2 1 3 1 NA 45 45 45 3 1 3 3 1 3 2 1 2 NA 46 46 46 3 2 1 1 3 3 2 2 1 NA 47 47 47 3 2 1 2 1 1 3 3 2 NA 48 48 48 3 2 1 3 2 2 1 1 3 NA 49 49 49 3 2 2 1 2 3 1 3 2 NA 50 50 50 3 2 2 2 3 1 2 1 3 NA 51 51 51 3 2 2 3 1 2 3 2 1 NA 52 52 52 3 2 3 1 3 2 3 1 2 NA 53 53 53 3 2 3 2 1 3 1 2 3 NA 54 54 54 3 2 3 3 2 1 2 3 1 NA 55 55 55 4 1 1 1 1 1 1 1 1 NA 56 56 56 4 1 1 2 2 2 2 2 2 NA 57 57 57 4 1 1 3 3 3 3 3 3 NA 58 58 58 4 1 2 1 1 2 2 3 3 NA 59 59 59 4 1 2 2 2 3 3 1 2 NA 60 60 60 4 1 2 3 3 1 1 2 1 NA 61 61 61 4 1 3 1 2 1 3 2 3 NA 62 62 62 4 1 3 2 3 2 1 3 1 NA 63 63 63 4 1 3 3 1 3 2 1 2 NA 64 64 64 4 2 1 1 3 3 2 2 1 NA 65 65 65 4 2 1 2 1 1 3 3 2 NA 66 66 66 4 2 1 3 2 2 1 1 3 NA 67 67 67 4 2 2 1 2 3 1 3 2 NA 68 68 68 4 2 2 2 3 1 2 1 3 NA 69 69 69 4 2 2 3 1 2 3 2 1 NA 70 70 70 4 2 3 1 3 2 3 1 2 NA 71 71 71 4 2 3 2 1 3 1 2 3 NA 72 72 72 4 2 3 3 2 1 2 3 1 NA
72列あるのでL18じゃないように見えるが、これはreplicates=4を指定しているため(18x4=72)。
2元配置実験なので、実験値は u1xN1, u1xN2, u2xN1, u2xN2の4通りある。したがって各パターンについて4つの実験値が得られている。これがreplicates=4の理由。
以下で要因効果図(SN比と感度)を描画する。
tdo = taguchiDesign(design="L18_2",randomize=F,replicates=4)
tdo
write.csv(tdo,"L18_2.csv",row.names = F)
d =read.table("L18_2.csv",sep=",",header = TRUE)
y=d$y
response(tdo)=y
#type="nominal: Creates a nominal-the-best signal-to-noise-ratio plot.
#type="smaller" for smaller is the best
#type="larger" for larger is the best
#“nominal”: SN = 10*log(mean(y)/var(y))
#“smaller”: SN = -10*log((1/n)*sum(y^2))
#“larger”: SN = -10*log((1/n)*sum(1/y^2))
snPlot(tdo,
# type="larger",
# type="smaller",
type="nominal",
# factors=c('B','C','D','E','F','G','H'),
# points = TRUE,
col = "black",
single=TRUE,
pch = 16,
lwd=5,
lty = 1,
ylab = "Mean of S/N ratio"
)
par(mfrow = c(1,8)) #1行にする
effectPlot(tdo,
single=TRUE,
# points = TRUE,
col='black',
pch=16,
lwd=5,
lty=1,
ylab = "mean of y"
)
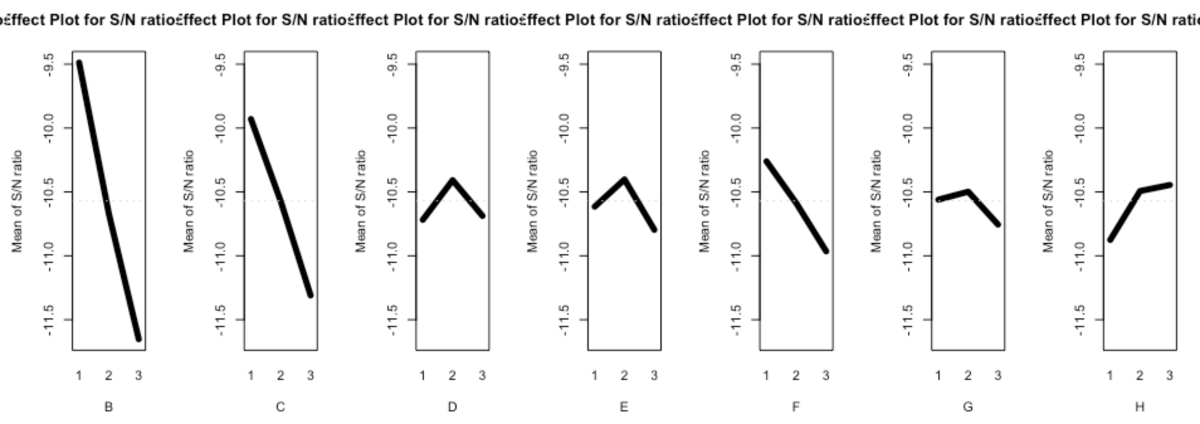
par(mfrow = c(1,8)) #1行にするSN比
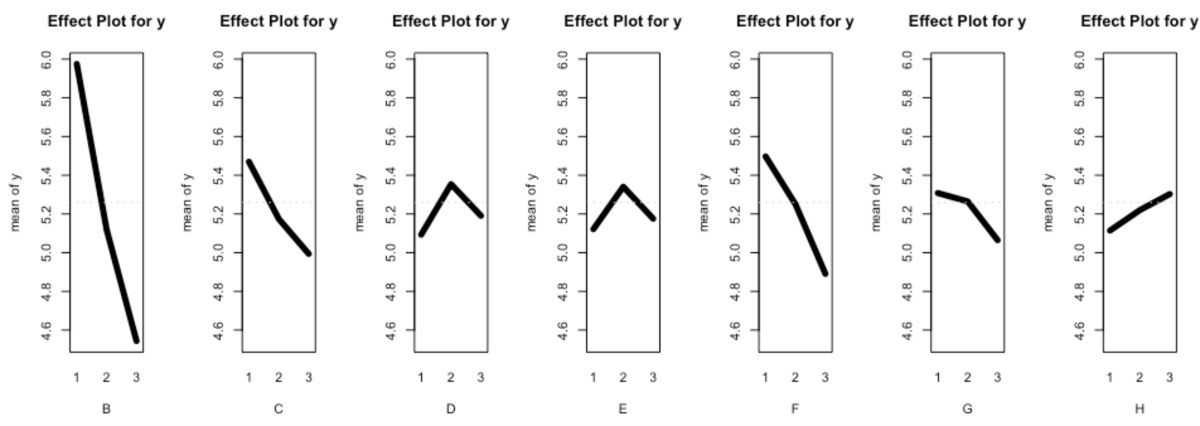
感度
SN比についてはnominalを指定した。参考にした記事とグラフのトレンドは合っているが、絶対値については確認していない。元記事では変動を用いており、qualitytoolsでは分散を使っているようなので、定数倍の違いはありそうである(未確認)。
感度についてもトレンドはあっているが、qualitytoolsの実装の中身を、感度の定義と照らし合わせて確認はできていない。
注意点として、元記事では直交表が[未使用,A,B,C,...,G]となっているところ、qualitytoolsでは[A,B,C,...,G,H]となっている。
ラベルが1つずれているのでB→Aのようにシフトして読み替える必要がある点に注意を要する。したがって要因効果図のAは「未使用」にシフトされるので、これは無視する。
