この記事は 理情 Advent Calendar 2024 - Adventar の12日目の記事として書かれました。
不幸にも前日の記事はありませんでした。
はじめに
コンパイラにおける「活性解析」に関して競技プログラミング形式の問題を作ったが、質や準備の大変さ的にコンテストに出せるようなものではないため、記事として公開する。
活性解析とは
プログラム中で、変数が生きている/死んでいるというのが定義できるので、それを計算すること。
データフロー解析の一種で、プログラム中の変数をレジスタへ割り当てる際などにこの結果を用いる。
コンパイラでは「構文と向き合う」というテイストのパートが多くあるが、活性解析はその中では数理的(?)で個人的には親しみやすいものであった。
問題
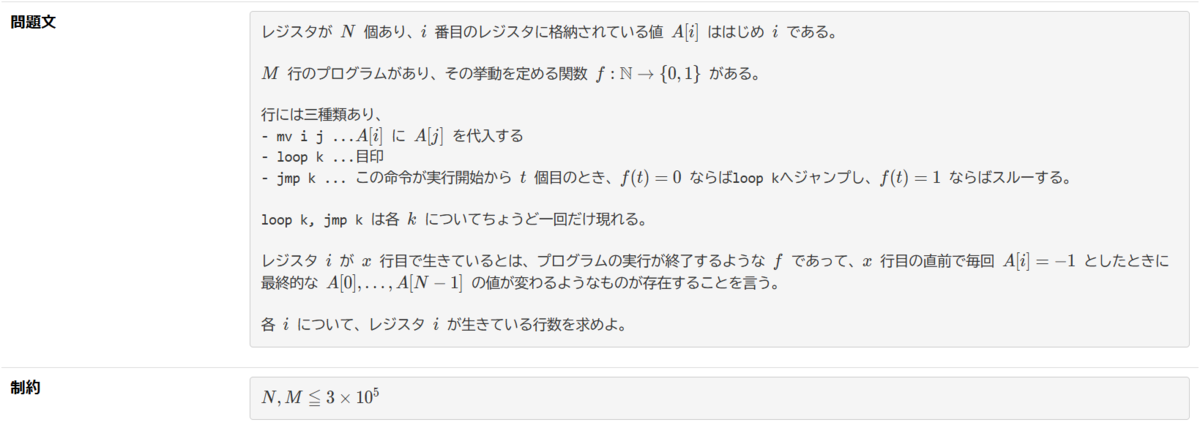
一変数を一変数に代入するという単純なプログラムにおける活性解析をモデル化した問題である。愚直なアルゴリズムとしてO(NM)のものが知られている。
解法
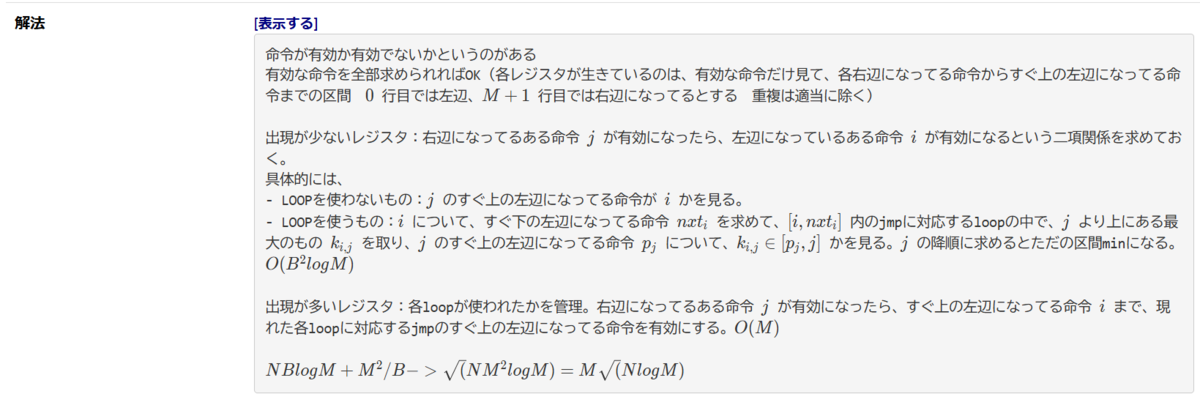
「出現が多い変数とそうでない変数で解法を分ける」という平方分割を行う。
分けた後はいつもどおり頑張る。
計算量はO(M√(NlogM))。
答えは各変数が生きている区間の集合という形で求まる。
おわりに
活性解析のO(NM)のアルゴリズムが授業で紹介されたときに、「疎性を真面目に使えばこれよりは速くなるね」と思ったので、それを詰めて問題にした。
実際は、活性解析は関数単位で行い、その内部の変数の数は通常十分に小さく3×10^5もないので、高速化が求められる場面は恐らくあまりないとされている。
(補足:配列は通常先頭アドレスだけ見て一つの変数として扱うため、O(N)より多くの変数を扱うことにはならない。)
各行で生きている変数の集合を増やしていくという素朴なアルゴリズム(トポロジカルソートに近い実装になる)がO(NM)で動くため、実際のコンパイラでは、使われるのであれば概ねこのようなアルゴリズムが使われているようだ。万が一大きな入力が来た場合には、規定のアルゴリズムから挙動を変えることなく、「単に止まらない」という実装が多いらしい。
