
2025 年 1 月 19 日に AtCoder 上で開催されたプログラミングコンテスト ALGO ARTIS プログラミングコンテスト2025 冬(AtCoder Heuristic Contest 041) に参加し、 76,949,532 点のスコアで本番 1 位となることができました。
上位解法や出題準備者想定解の多くが擬似焼きなまし法ベースの手法を採用するなか、私はかなり異なる方針(高さの小さい頂点から決めていくビームサーチ)で良い結果が得られたため、知見の共有を目的として内容を説明します。
なお本記事では、最終提出で採用された解法の内容に加えて、この解法に至るまでに、汎用ソルバーを活用してどのように検討を進め、ビームサーチ解法にたどり着いたかの説明も試みます。
- 問題の概要
- Step 1. 最適化対象とする変数の検討
- Step 2. 重み付き制約充足問題への帰着
- Step 3. 汎用ソルバーを用いて得られた解の観察
- Step 4. 汎用ソルバーに素早く良い解にたどり着かせるための工夫の検討
- Step 5. 基本的なアルゴリズムの構築
- Step 6. 探索の多様化による解の改善
- まとめ
- 謝辞
- 関連資料について
問題の概要
ランダムに生成された 頂点の平面グラフが入力として与えられます。その全ての頂点といくつかの辺を使って森を作り、さらに連結成分毎に一つの頂点を根に指定していくつかの根付き木を得る方法の中で、後述の方法で計算される スコア ができるだけ高いものを出力する問題です。
ここで、最終的なグラフの構造に一つの制約条件があります。完成したそれぞれの根付き木において、各頂点 から根までの距離
(この問題では頂点
の 高さ と呼びます)は
以下でなければなりません。
最終的なグラフに対して、そのスコアは以下のように計算されます。まず、グラフの各頂点 には予め
] の範囲で独立・一様ランダムに選ばれた重み
が定まっています(この情報は入力で与えられます)。各頂点
のスコアを「(根付き木の根から
までの距離)
」と
の積で定め、全ての頂点に関するスコアの合計値 1 が解のスコアとなります。

したがって、根からの距離が上限値 に近い頂点をできるだけ多く作りたいです。
さらに、重みの大きい頂点をできるだけ根から遠く配置することが望ましいです。
参考までに、(実際には不可能ですが)全ての頂点が高さ
になったと仮定してスコアの計算式を当てはめると平均 55.6 万点となり、これ以上の平均スコアは不可能ですが、本番で 1 位となるには平均 51.3 万点 程度のスコアが必要でした。
Step 1. 最適化対象とする変数の検討
以下、私の今回のコンテストにおける検討過程を順を追って説明していきます。最終提出の内容にのみ興味ある方は Step 5 まで読み飛ばしてください。
まず、与えられた問題文の「言い換え」を試みます。 問題文中で明示的に示された変数とは異なる変数に着目するなど、問題文を言い換えることで、問題が解きやすくなることがしばしばあります。 今回の問題では、最終的にはグラフ(根付き木の集合)を出力する必要がありますが、状態や変数としてグラフを持つのではなく、 グラフから計算される各頂点の高さに着目する という方針が考えられます。
グラフの形が決まれば各頂点の高さも決まりますが、反対に各頂点の高さの列 が与えられたとき、各頂点の高さがちょうどこれに一致するようなグラフ(の一つ)を、実は(条件を満たすグラフが存在するならば)単純な方法で逆算できます。
具体的には、
を満たす各頂点
を根として、
を満たす頂点については
を満たし
に隣接する頂点
を親とすればよいです(もしそのような
が存在しないならば、
は対応するグラフが存在しない制約違反の状態ということになります)。

以上のようにグラフと は(制約違反がなければ)相互に変換可能なので、ざっくりと言って、グラフと
は同じことを 2 つの異なる形式で表現しているに過ぎないと考えることもできます。
この立場に立つと、今回の問題は 高さの列
を最適化する 問題として再解釈できます。
コンテスト後の SNS では、この言い換えに基づく、高さの列 を対象にした擬似焼きなまし法などの近傍探索の解法の共有も多く見られました。
Step 2. 重み付き制約充足問題への帰着
今回の問題において各頂点の高さ を直接の最適化の対象(目的変数)として採用する大きなメリットの一つが、
が満たすべき 制約条件や今回の問題の目的関数が比較的単純な形で記述でき、問題をそのまま汎用ソルバーに解かせてみることが可能になる、という点です。
仮に汎用ソルバーが良い解を出力できるならば、提出コード内で直接汎用ソルバーを利用してしまうか(現行の AtCoder ジャッジサーバーではいくつかの汎用ソルバーが使用可能です)、あるいはソルバーの動作結果から得られた情報や示唆を間接的に自らの解法に利用することで、コンテストで有利に立ち回れる可能性が高まります。
最適化問題の定式化を行います。最初に変数として、各頂点 および高さ
について、
か
の値をとる二値変数
を導入します。
変数
は「頂点
の高さ
がちょうど
のとき
, それ以外のとき
」という値をとるように意図されています。
各変数 についてそれが取り得る値毎に二値変数を定義する本方針は、複雑な最適化問題を汎用ソルバーが扱える形に帰着させるために頑張って変形する際によく用いられます。
また、競技プログラミング等における
値最小カット(参考: 最小カット問題の k 値への一般化 - noshi91のメモ )などの文脈で類似の考え方に触れた方もいるかもしれません。
このように導入された変数 を使うことで、今回のコンテストの問題は以下の最適化問題として表現できます(ただし
は入力で与えられるグラフで頂点
に隣接する頂点の集合を表します)。
それぞれの式の意味を簡単に説明します。
まず 以下の制約条件について、
式は「各
のとりうる値は
か
のみである」という(当然満たすべき)制約です。
次に
式は「各頂点
について、高さ
は
のどれか一つの値をとる」という(こちらも当然満たしてほしい)制約を課しています。
また
式は「頂点
の高さが
以上ならば、
に隣接し高さが
より
だけ小さい頂点が存在する」という制約で、これは頂点
に(根付き木における)親頂点が存在することを要請しています。そして目的関数の
式は、今回の問題のスコアの式そのものです。
この最適化問題は、変数が全て二値変数で、目的関数がこれらの線形和(一次関数)の形になっていますが、このような問題には 重み付き制約充足問題 (weighted constraint satisfaction problem, WCSP)という名前がついています。 WCSP を解くソルバーは多数存在し、特に CP-SAT というソルバーが良質な解を得るための強力なソルバーとして知られています。 解きたい問題を WCSP に帰着できれば、これらのソルバーを活用することで、問題の良い解が手早く得られるかもしれません。
余談ですが、最適化問題の定式化において、 式の制約を
と書き換えると、
の整数制約を除く全ての制約条件が線形になります。したがって、この問題に 混合整数(線形)計画問題 (mixed integer (linear) programming problem, MIP/MILP) 専用の汎用ソルバーを適用してみることも可能です。ただし、私が試した限りでは今回の問題を(無償利用が可能な)MIP ソルバーに解かせて良い解を得ることはできませんでした。
Step 3. 汎用ソルバーを用いて得られた解の観察
今回の問題を CP-SAT を利用して手元環境で解くための Python コードは以下です。 独自のアルゴリズムをフルスクラッチで実装するのに比べ、極めて短いコードで処理が完結することが見てとれるかと思います。 なお、CP-SAT を利用するため、 OR-Tools の Python パッケージをインストールしておく必要があります。 今回は最新の v9.11 を利用しました。
from ortools.sat.python import cp_model n, m, h = map(int, input().split()) A: list[int] = list(map(int, input().split())) to: list[list[int]] = [[] for _ in range(n)] for e in range(m): u, v = map(int, input().split()) to[u].append(v) to[v].append(u) model = cp_model.CpModel() x = [[model.NewBoolVar(f"x_{v}_{d}") for d in range(h + 1)] for v in range(n)] # 制約条件 for v in range(n): model.AddExactlyOne(x[v]) # 制約 (3) for d in range(1, h + 1): model.AddBoolOr(x[u][d - 1] for u in to[v]).OnlyEnforceIf(x[v][d]) # 制約 (4) # 目的関数 (1) model.Maximize(sum(A[v] * d * x[v][d] for v in range(n) for d in range(h + 1))) solver = cp_model.CpSolver() solver.parameters.max_time_in_seconds = 60.0 # 実行時間制限 [秒] をここで設定 status = solver.Solve(model) depth = [sum(round(solver.Value(x[v][d])) * d for d in range(h + 1)) for v in range(n)] par = [-1] * n for v, adj_v in enumerate(to): for u in adj_v: if depth[u] == depth[v] - 1: par[v] = u print(*par)
手元環境 (MacBook Air, Apple M2 (2023)) で上記のコードを実行することで、 seed = 0 の問題について 1 分程度で以下のような解が得られました。なお画像は公式のビジュアライザを利用し、各頂点の色は最終的な解における高さ(赤に近い色ほど高さが最大値 に近い)を示しています。
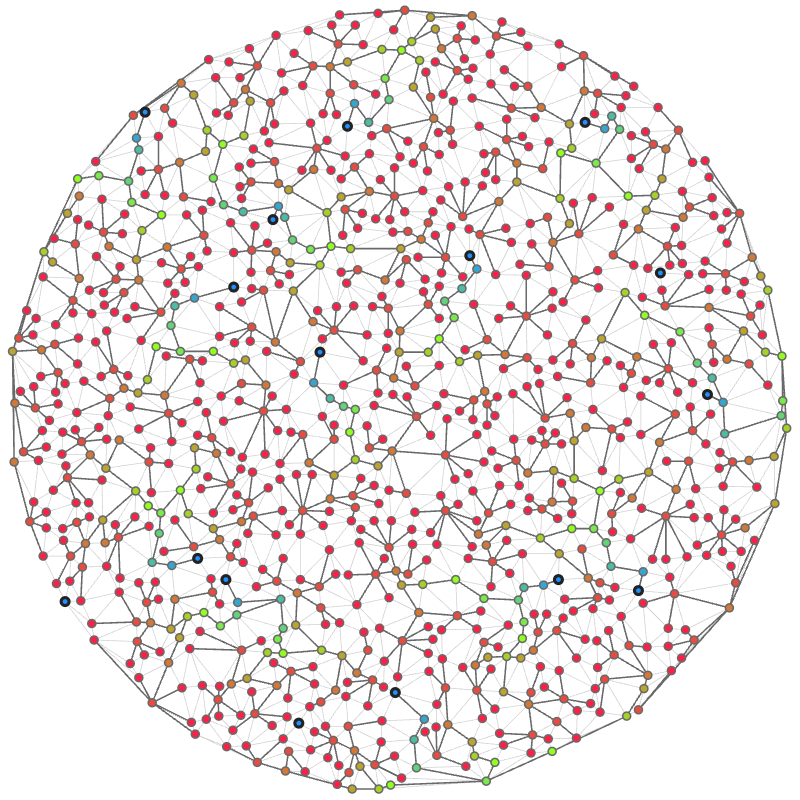
この解のスコアは 51.59 万点で、これは実は本番中の優勝解法の同ケースに対するスコア(51.24 万点)を上回っています!
また、同一のプログラムを繰り返し 10 回実行すると、以下のような異なる解たちが得られました。これらの 10 個の解のスコアは最低 51.38 万点、最高 51.61 万点で、いずれもコンテスト優勝解法のスコアを上回っています。

ソルバーが出力した良い解たちを観察すると、以下のようなことに気づきます。
- 根(高さ
の頂点)は少数個で良さそう。
- 高さが小さい頂点は
の値も小さい傾向にある。
- 高さ
なお、実際のコンテスト本は優勝に何点が必要かは分からないものの、コンテスト最中のリアルタイムの順位表の情報(特に最上位のスコア)を参照することで、ソルバーの出力する解は既に十分質が良く、ソルバーと同様の解を目指せば最終的に 1 位を十分狙えそうであることは推測できました。
Step 4. 汎用ソルバーに素早く良い解にたどり着かせるための工夫の検討
CP-SAT で問題を解く上記のコードは、良い解は得られるもののそれまでに数十秒以上の時間を要します(CP-SAT は手元環境の 8 コア CPU を並列で活用しているため、シングルスレッド換算では更に多くの時間を費やしていることになります)。 この時点の私は、まだ最終提出のコードで CP-SAT を直接利用することを想定しており、どうにかして CP-SAT の求解を高速化できないか試行錯誤していました。 そしてその過程で、 高さを 0 とする数個の頂点を(後述する集合被覆問題を解くことで)事前に全て固定してしまう制約条件を予め手で追加すると、 CP-SAT が 5 秒程度の実行でも 51 万点を超える良質な解にたどり着ける ことを発見しました。

理論的・技術的な根拠はないのですが、この現象は 「高さが小さい頂点を予め固定してしまうと、残る探索空間の性質が良く、良い解に高速にたどり着きやすい(?)」 ということを示唆しているのではないかと私は考えました。また、先ほどのソルバーが出力する解たちの観察結果から、 高さ 0 とする頂点の組合せとして有望なものはある程度効率的に列挙可能ではないか と考えました。
実際、最初に高さを 0 とする頂点を固定してしまえば、高さを 1 とする頂点は必ずそれらの頂点に隣接しなければならないので、高さを 1 とする頂点も固定しやすくなり、次に高さ 2, 高さ 3, ... と次々に固定していきやすそうな気がしてきます。
そこで以降は CP-SAT ソルバーにそのまま解かせる方針は諦め、 の順に「高さを
とする頂点たち」をヒューリスティックに決めていく方針のプログラムを新規実装することにしました(この時点で開始から 2 時間程度が経過していたと思います)。
Step 5. 基本的なアルゴリズムの構築
ここまでの検討に基づき、高さを とする頂点を
の昇順に決めていくアルゴリズムを設計します。
ただし、頂点は闇雲に選べばよいのではなく、例えば以下の観点について考慮する必要がありそうです。
- 要望 1 : 高さを
とする頂点集合を決めるとき、それらの頂点の重みの和は小さい方が望ましい
- 要望 2 : 「現在未決定の頂点の
の値をうまく決めれば、最終的に制約条件を満たす解が作れること」が常に保証された状態を保ち、そのような状態だけを探索したい
高さ が小さい頂点
の重み
が大きいと単純にスコアの観点で損なので、 要望 1 は重要です。また、最終的に手詰まりになる(高さが
を超える頂点ができてしまう)と困るので 要望 2 も考慮する必要があります。

これらの要望の考慮のもと、 について順に、以下の流れで 高さを
にする頂点の組合せを決定していきます。
5-1. 高さを にすることが可能な頂点を列挙し、これを集合  とする
とする
これは のときは全ての頂点が該当し、
のときは高さが
に決まった頂点に隣接する高さ未決定の全頂点が該当します。

以下の頂点を全て決めた時点の状況の例。高さを
にできる頂点は高さ
の頂点に隣接するものに限られる。
5-2. 集合 に含まれる各頂点  について、頂点 から高さが未決定であるような頂点のみを経由して
について、頂点 から高さが未決定であるような頂点のみを経由して  辺以下で到達できる頂点の集合
辺以下で到達できる頂点の集合  を求める
を求める
これは、各頂点について「その頂点の高さを としたときに最終的に高さ
以内に収めてあげることが可能な全ての高さ未決定の頂点」を計算していることになります。

で次に高さ
の頂点を決めたい状況において、図に示した頂点
に対する
と
の範囲を示したもの。
5-3. 何らかのアルゴリズムで の部分集合で重みの和ができるだけ小さいものを決め、これに含まれる頂点の高さを とする
このとき高さを とする頂点集合を
とすると、 要望 2 を満たすためには、高さが未決定である各頂点
は必ず
のいずれかの頂点
について
となる必要があります。

この部分問題を解いて を決定する「何らかのアルゴリズム」として様々なものが考えられますが、今回の状況では以下のような単純な貪欲法が良好に動作するので、ひとまずこれを用いることにします。
を
以内にできるか?」を判定し、結果が真であればその頂点を
処理 2 で削除しても問題ないと判定されたものだけを消していくことで、 要望 2 は常に満たされた状態にできます。
なお、今回の状況のように各集合にコストが定まっていて、全ての要素を覆えるような合計コストが小さい集合の組合せを求める問題には実は 重み付き集合被覆問題 という名前がついています。
この方針を適切に実装することで 76,115,084 点(1 ケース平均 50.74 万点)が得られ、これは本番 18.5 位相当のスコアです。このプログラムは数十 ms 程度で動作し、コンテスト後の SNS でも強力な貪欲アルゴリズムとして話題になりました。
なお、重み付き集合被覆問題自体を CP-SAT などのソルバーに解かせることも可能で、実際今回の問題に対しては極めて高速に動作します。 これを使うことで、例えば seed = 0 の問題に対しては高さ 0 の頂点が 4 つ、これらの重みの和がたった 5 という解を発見することも可能です。
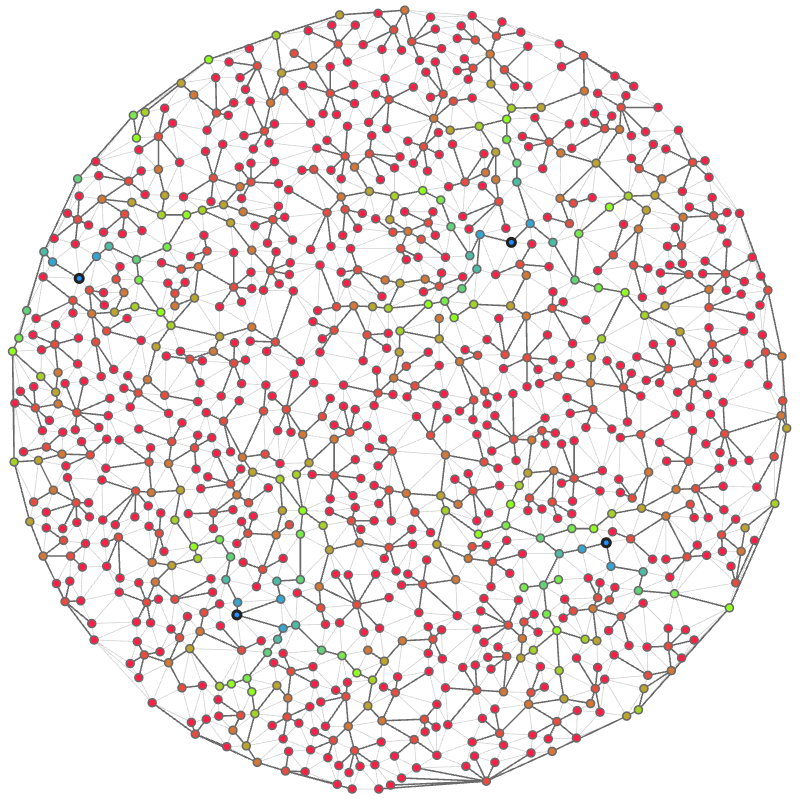
の重み付き集合被覆問題の厳密解を求めて、その結果に従って頂点 55, 128, 331, 958 のみを高さ 0 にすると決め打って CP-SAT で本問題の最適化を 60 秒実行した結果の解。スコアは 51.34 万点であった。
Step 6. 探索の多様化による解の改善
Step 5 で説明した基本的なアルゴリズムは高速に動作し、今回のコンテストの実行時間制限にはまだまだ余裕があります。 この解法では、特に重み付き集合被覆問題を解く「何らかのアルゴリズム」の部分の任意性が大きく、改善・多様化の余地があるため、ここで良い解を複数個生成することで、解法をビームサーチ化すれば、最終的な解を更に改善できそうです。
私はコンテスト本番では以下のような方法で複数個の解を生成しました。
- 配列
の各要素に独立な乱数値を加算した上で重み付き集合被覆問題を解く。
- 重み付き集合被覆問題の解から 1 つの要素を削除し、新たに別の 1 つの要素を追加して別の解を生成する。
- なお、こうして新たに得られた解が 要望 2 を満たすかの判定処理は C++ の bitset などを利用して高速化できます。
なお、深さ 以上などの後半戦は探索の余地が少ないのか、分岐を増やしてもスコア改善があまり見られなかったため、前半をより重点的に探索するよう調整しています。
ビームサーチで探索の優先度を定めるための各状態の評価値としては、高さが未決定の頂点は全て高さ と仮定して計算したスコアを使用しました。これは、最終的に出力されるべき解では多くの頂点が高さ
や
となることを念頭に置いています。
また、ビームサーチでは重複する状態の除去を考慮しました。具体的には、高さ の頂点までが決まった各状態たちについて高さ
の頂点の集合(から計算されるハッシュ値)を求め、これが一致する状態を重複して持たないようにしました。
これらの工夫の結果、スコアを 76,949,532 点(1 ケース平均 51.30 万点)まで伸ばすことができ、本番 1 位となりました。
なお、私はコンテスト中に各手法の有効性を吟味する時間の余裕がなかったため、この節で述べた工夫には未だに大きな改善の余地がありそうです。 特に集合被覆問題の解列挙の検討はあまり詰め切れておらず、より洗練された解法があると期待しています。
まとめ
今回のコンテストのような最適化問題を解く際、もし目標とすべき優れた解の性質が予め分かっていれば、自分が実装したプログラムの出力する解を的確に自己評価できたり、優れた解に共通する特徴やそれらの統計的な性質から適切なアルゴリズムを逆算することで、素早く良い解法にたどり着けるかもしれません(これはコンテストだけでなく実務においても同様かもしれないですね)。
今回のコンテストの問題は重み付き制約充足問題という有名な問題に比較的素直に帰着でき、また汎用ソルバー CP-SAT を利用することでごく短いスクリプトを数分間実行することで優れた解を得られました。 そしてこの結果をヒントとすることで、「高さが小さい頂点から順に決定していくのが良い」「固定する頂点の組合せに選択・探索の余地がある」という問題の重要な性質に気づき、ビームサーチを行う方針を選ぶことができました。
今回の問題は普段の AHC と比較して汎用ソルバーでも(実行時間制限を無視すれば)良い解が出しやすいと思われ、今後の AHC などでこの方法がそのまま通用することはあまりないかもしれませんが、今回のコンテストを通して 汎用ソルバーは単に問題を解く手段としてだけでなく、良いヒューリスティックアルゴリズムを構築するためのヒントとしても活用できる という点に改めて気づかされたのは興味深かったです。
謝辞
今回のコンテストを主催してくださった株式会社 ALGO ARTIS 様、及び大変面白い問題を出題いただいた問題作成者の terry_u16 さんやその他準備に携わった皆様に感謝いたします。
関連資料について
汎用最適化ソルバーを利用した具体的な問題の解き方に関する情報は、(日本語のものを含め)インターネット上に既に多くのページが存在します。 参考までに私が以前書いたもののリンクを以下に示します。
また、混合整数計画問題 (MIP) などの最適化問題を具体的にソルバーで解いてみたい方は、以下の書籍なども参照してみてください。
[1] はクラス替えの最適化など、現実的な課題を汎用ソルバーを活用しつつ解決していく事例が各章で Python のコードと共に紹介されています。 [2] は前半で様々な制約条件を MIP で表現するためのテクニックなどを学ぶことができます。また後半には、食品生産などの具体的なシチュエーションをイメージした 29 問の最適化に関する演習問題とその解答解説が収録されています。
- [1] 岩永 二郎, 石原 響太, 西村 直樹, 田中 一樹, "Pythonではじめる数理最適化(第2版)," オーム社, 2024.
- [2] H. Paul Williams, "Model Building in Mathematical Programming 5e," John Wiley & Sons, 2013.
おまけ
花丸「汎用ソルバーを使えば問題を定式化するだけで解が求まるなんて、本当に未来ずら〜」
善子「アンタ、先週は『LLM なんて未来ずら〜』とか言ってたじゃない」
花丸「ふふっ、便利なものはどんどん使うのが賢いずら」
善子「そ、それより……コンテストの復習、もう済ませたの?」
花丸「もちろんずら。善子ちゃんもサボってないずら?」
善子「わ、私は……ちょっと最近配信が忙しくて……!」
花丸「そんなこと言ってないで、一緒にもっと上を目指すずら! 早く実装するずら、今すぐ部室へレッツゴー!」
善子「ちょ、ちょっと待ちなさいよー!」
ルビィ「みんなも復習、がんばルビィ!」
- 正式には、この値にさらに1を加えた値が順位表上の表示などに利用されるスコアとなります。↩
