さぼっていた間にCUDAが何か全部忘れたので思い出す(せる?)
こんにちわ、こんばんわ。かえるのクーの助手の「井戸中 聖」(いとなか セイ)でございます。

実験機のマザーボードetcを更新してWin10からWin11に完全新規の再インストールしたら、失敗を何度かしてライセンスがどっか行っちゃいました。当面、このままいきます。
さて、Win11にしたら環境も新規にインストールします。
とりあえずCUDAやVisualStudio Communityを入れて動かしてみます。
CUDAはサンプルプログラムを動かしたいので、現時点最新のCUDA 12.6ではなく、12.5をいれました。
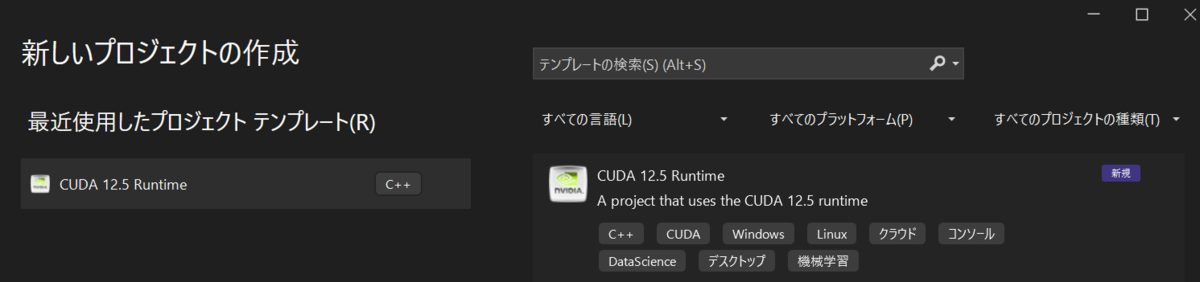
いつものサンプルプログラムひな形がでてきたので、実行してみます。
実行ボタンを押すと、コンパイルして実行してくれました。正常動作しています。
gitから最新のsampleソースをcloneしてビルドしてみます。
ほぼ全部ビルドできました。
サンプルソースをさわってみる
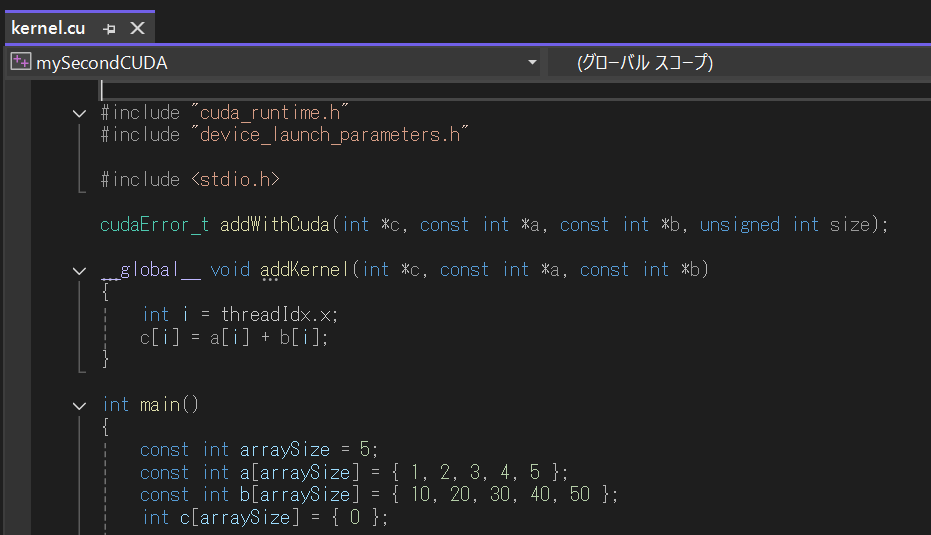
今回mySecondCUDAと名前をつけたプロジェクトのソースを触ってみます
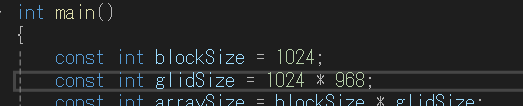
たくさん計算させてみましょう。配列サイズを5から増やします。

コンパイルは通りますが、実行すると、エラーがでます。

どこかが大きすぎるようです。
いろいろやってみると1024までなら実行できるようです。
末尾の配列計算ができているか確認するコードも追加しました。
pythonみたいにrange()して定数定義する方法を知らないので、コーディングしました。

最初と最後のほうを表示できています。

const int arraySize = 1025;にするとだめです。
![]()
ソースをみると、

のようになっており、1 の部分がグリッドサイズで、sizeの部分がブロックサイズを渡すようですが、ブロックサイズの最大は1024までのようです。
グリッドサイズをアップするようにプログラムを修正してみます。




動きました。ではもっとglidSizeをアップしてみましょう。
スタックオーバフローがでました。
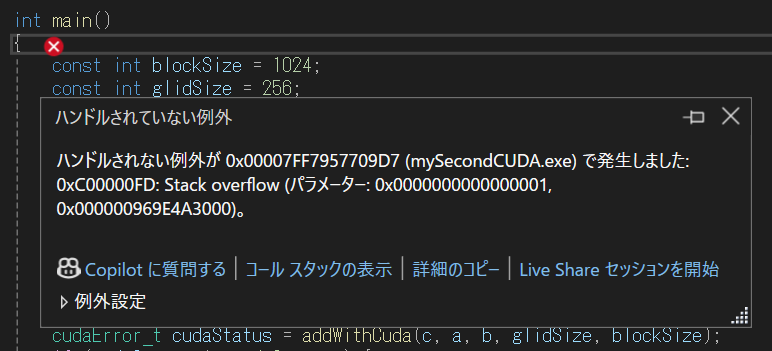
CharGPTにきいてみた。

メモリをたくさん積んでいるので、GPUのメモリより大きく極端にアップしてみます。バイト指定で16GB(17,179,869,184)くらいにしてみます。
メニューの/デバッグ/[プロジェクト名]のデバッグプロパティ/
設定したい「構成」(Release/Debug)を選択/リンカー/システム/スタックのサイズ設定
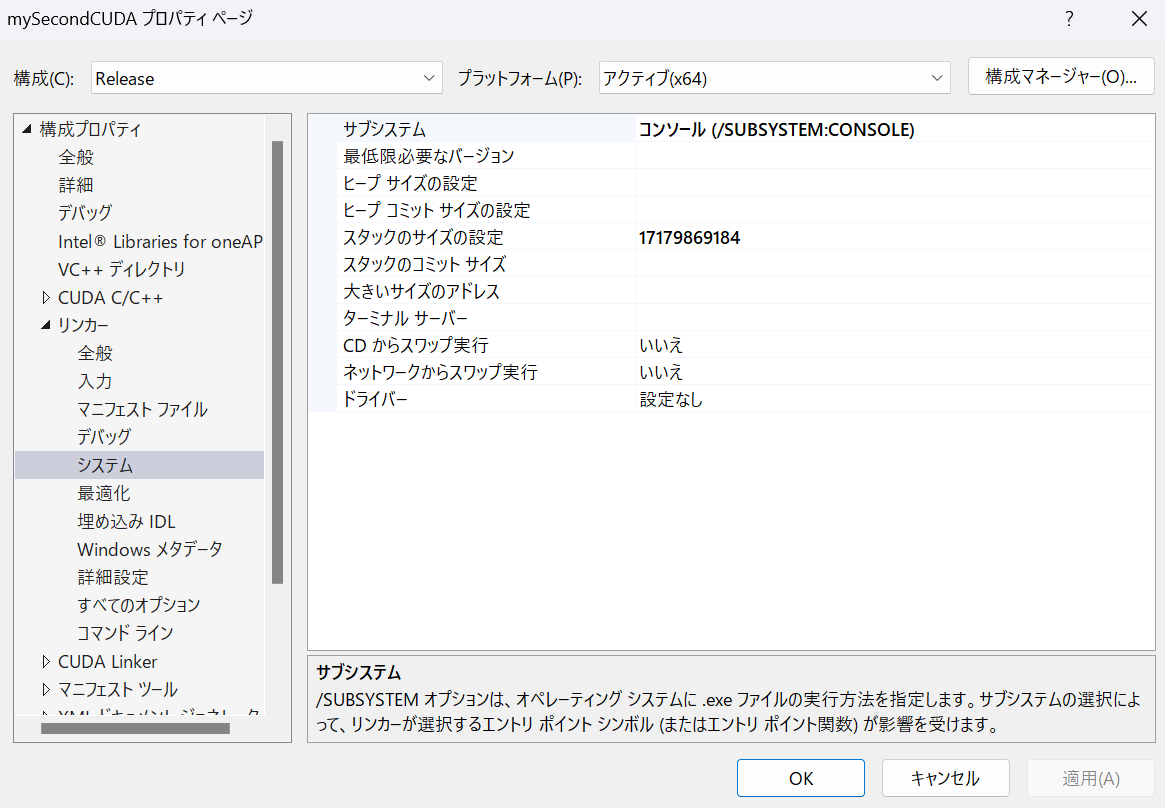
だめだったglidSize = 256が通りました。

どんどん増やします。メモリ割り当てが2Gを超えて怒られました。

![]()
あ、C[]配列をmallocしてませんでした。スタックがオーバーしていた原因はこれだったようです。
![]()
さらに進めて、、、このあたりがRTX3060の限界付近のようです。


int精度はとっくにオーバーしてますが。。。

です。メモリのもっとたくさんあるGPUはもっといくでしょう。
スピードはどう?
せっかくなので計算スピードを計測してみましょう。
作るのが面倒なので、sampleにあるコード”batchCUBLAS.h”を使います。

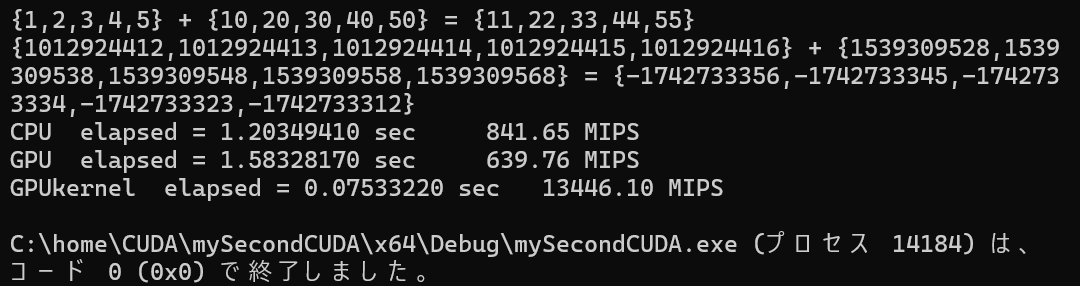
このプログラムの単純な配列加算だけだと、メモリ転送がネックで、CPUをトータルで越えられないようです。。。
配列の積をBLASでやれば爆速なのでしょうが。。。
やってみましょう。
BLAS計算をやってみる
BLASとは「ベクトルや行列の基本演算を行う高性能なルーチン群」です。S(もしくはオリハルコン)ランクプログラマあっても、配列計算は決してこのライブラリを超えられません。
CPUOnlyとGPUのcuBLASとIntelMKLのBLASで競ってみましょう。
少し大きめの行列の積(ドット積)をやらせてみます。
まじめにコーディングせずともほぼやりたい内容がCUDAのsampleにありました。
matrixMulCUBLASを使って測定してみます。
プログラムを少し変更してより大きな行列の積を計算させてみます。
まずは、GPU(cuBLAS) vs CPU(SingleCore)
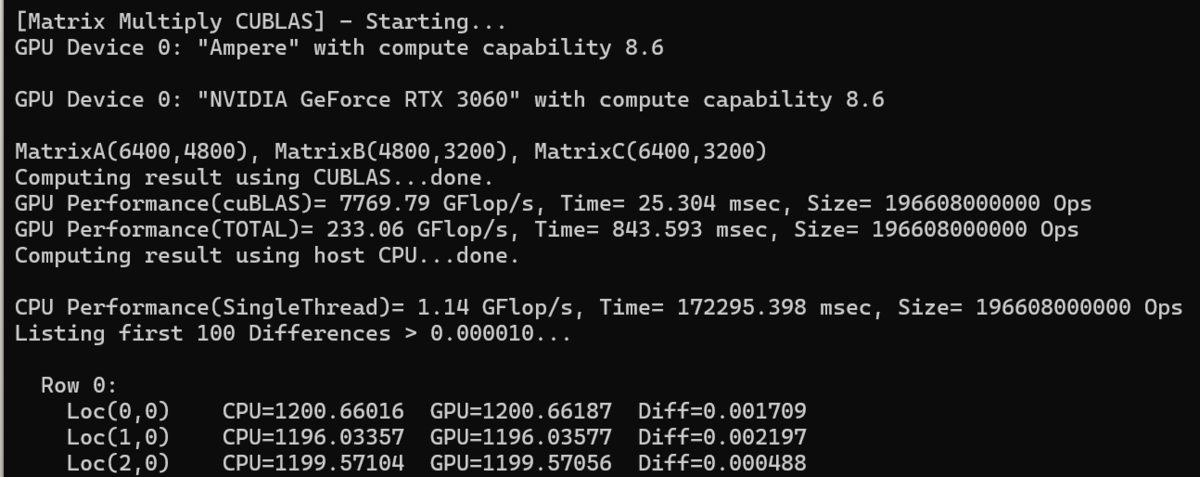
行列A(6400,4800) @行列B(4800,3200) = 行列C(6400,3200)
で行います。これぐらい大きくなるとGPUとCPUの計算誤差が無視できないくらいになりますが、今回は速度の測定のみに注目しましょう。ほぼ、CPU単純計算の6880倍の速度がでています。メモリ転送を含めても約200倍速いです。GPUの論理値が12.8TFLOPSなので、7.76TFLOPS出るのは凄すぎ。CUDA+BLASやっぱり凄いですね。禁断の第十位階梯魔法でブラックドラゴンを屠る迫力です。誰でもアインズ様になれるチートの極みといっていいでしょう。詠唱が長いところが玉に疵ですが。
ならば、IntelのMKLのBLASと意味もなく対決させたくなるのが初心者というものです。
INTELのMKL(マス・カーネル・ライブラリ)のBLAS
MKLいれます。

同じプログラム上で同じデータを使ってMKLで行列計算をさせてみます。
ちなみにCPUはAMD Ryzen9 5950X(16Core/32Thread)です。
時間測定用にパクったCUDAの時間測定関数second()がMKLのライブラリ関すると競合しているので、CUDA側をむりやり変更してみます。
second()->cuSecond()
う~ん。肝心のBLAS本体メソッドを認識してくれません。
![]()
ちゃんと、MKLのLibとIncludeとbin(DLL)の設定しているのですが。。。
ちなみにcblas_sgemm(...)は単精度の行列計算メソッドです。行列C=alpha×行列A・行列B + beta×行列Cを計算してくれます。:
C++追加インクルードの設定が不足していたようです。ビルドはできました!

ところが実行するとエラーになってしまいます。。。

パラメータのエラーはでなくなったけど、「Module not found」(何がみつからないかは不明)がでている。(2次遭難のメッセージかもだけど)パラメータチェックはしているっぽいので、中にはいったあと何かがみつからないんだよねぇ。 MKLのbinにはPathを通しているが、それだけではダメなのかなぁ。
0xC0000374 とでることもある。(STATUS_HEAP_CORRUPTIONか?) (デバッガでながしたときと、リリースで流した時にエラーが異なる。)
原因がわかりました。行列として、CUDAやCPUの計算と同じ行列用の配列を使っていましたが、これがダメでMKL用のメモリアロケーションをした配列でないと受け付けないようでした。malloc(...) ではなく、mkl_malloc(...)を使うべきのようです。そして標準はFORTRANの様に列優先のほうが速い模様です。
 Ryzen9は全コア単精度計算性能が 1.2TFLOPSくらいのようなので、とても善戦しているとおもわれます。(今日は時間がなく、MKLの計算結果の「検算」はしていません。なかなか通らなかったので、試行錯誤で行列を取り違えてしまっているかもしれません。また、「誤差」がどれくらいいくのかが気になります。)もちろんCPUのforループ計算より圧倒的に速いです。
Ryzen9は全コア単精度計算性能が 1.2TFLOPSくらいのようなので、とても善戦しているとおもわれます。(今日は時間がなく、MKLの計算結果の「検算」はしていません。なかなか通らなかったので、試行錯誤で行列を取り違えてしまっているかもしれません。また、「誤差」がどれくらいいくのかが気になります。)もちろんCPUのforループ計算より圧倒的に速いです。
この後は、検算と「スパース行列」(別名すかすか)についてのCUDAとMKLの使い方について学習していきたいです。
