DeepSeek-OCRの精度が高くて驚いたところですが、仕組み的にランダムな文字列での認識率がかなり落ちるんではないかと試してみたところ、やっぱりかなり悪かったです。
DeepSeek-OCRについてはこちら。
画像でテキストをトークン圧縮するDeepSeek-OCRがいろいろすごい - きしだのHatena
DeepSeek-OCRは、画像をトークン化したほうがテキストをトークン化するより情報圧縮できるんでは、というアイデアを試すために、トークン化した画像をテキストに戻してみたらOCRとして精度があがった、というものです。
ここで、「画像のほうが情報量が多いのにトークン化したら容量増えるのでは?」ってなりますが、情報量が多いのは画像を画像として復元する場合で、画像についてお話するために必要十分な情報としてであればそこまで多くならないはずです。
テキストのトークン化は、よくある文字の並びを少ないトークンで表せるように学習したトークナイザをつかって、テキスト中の文字を先頭からトークンに割り当てていきます。テキスト全体は見ません。
一方で、画像のトークン化では画像全体を見てトークナイズします。
たとえば、0が16個ならんでいる場合、ChatGPTでは000が1トークンになるので、全部で6トークンになります。

これを人間が覚えるとき、「0が16個」のようにするはずですね。ちなみに「0が16個」のほうがトークンがひとつ少ないです。

また、LLMというのは「続きにくるトークンを予測する」という仕組みで、続きにくるトークンの確率を割り出せます。その続くトークンの確率を利用すれば、テキストの情報圧縮はより効率的になるはずですね。
画像言語モデル用の画像エンコーダーを作るときには、画像からのベクトルと、等価な文章からのベクトルが一致するように学習を進めます。
そのときに、「続きにくるテキスト」の確率も学習してるはずです。そうすると、視覚的な情報と言語学的な情報を利用した情報圧縮ができることになります。
※ 技術的、学術的裏付けがあるわけではなく 仕組み的にそうでは?というきしだの予測です。
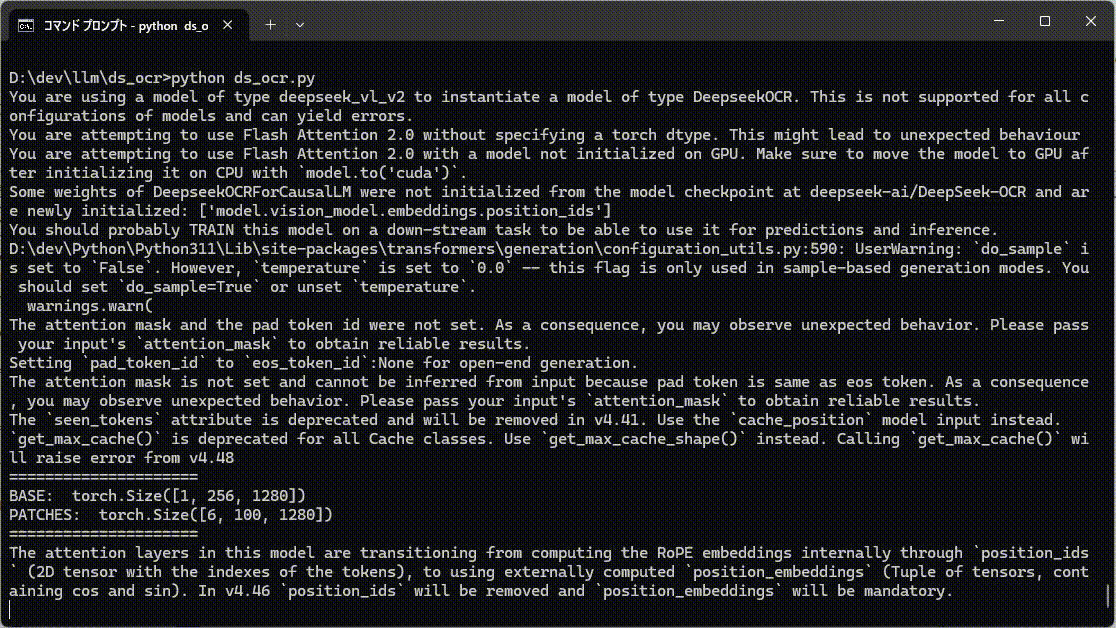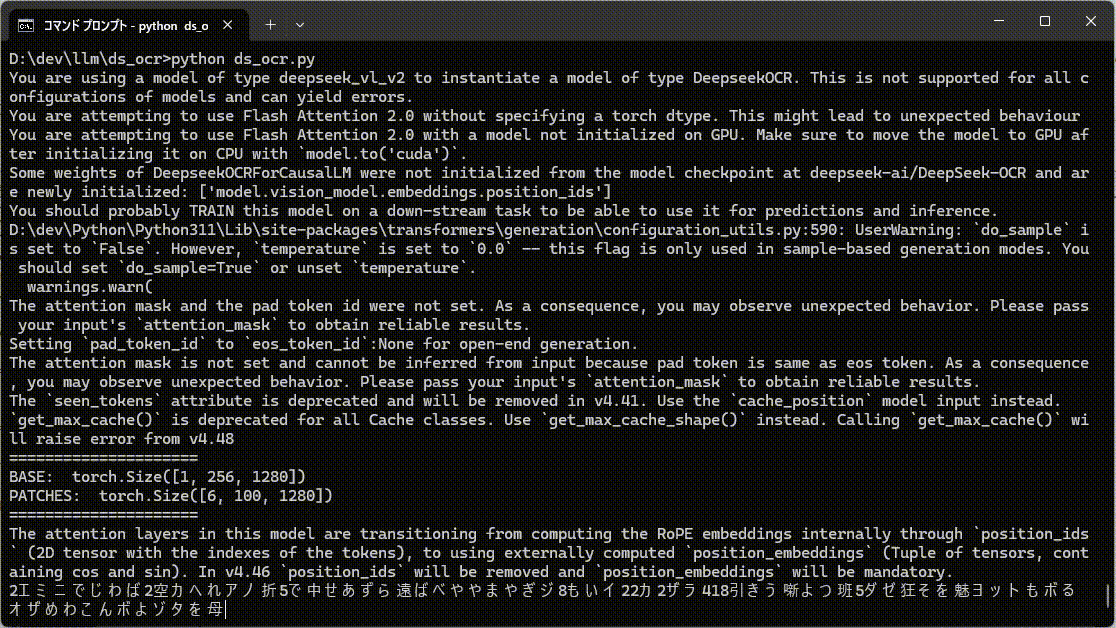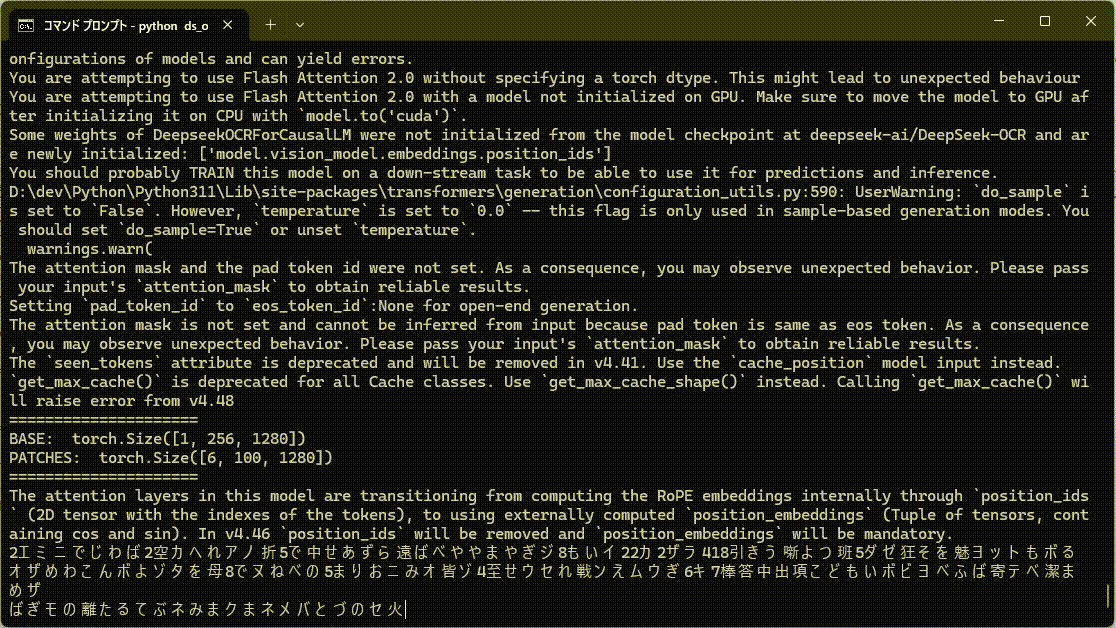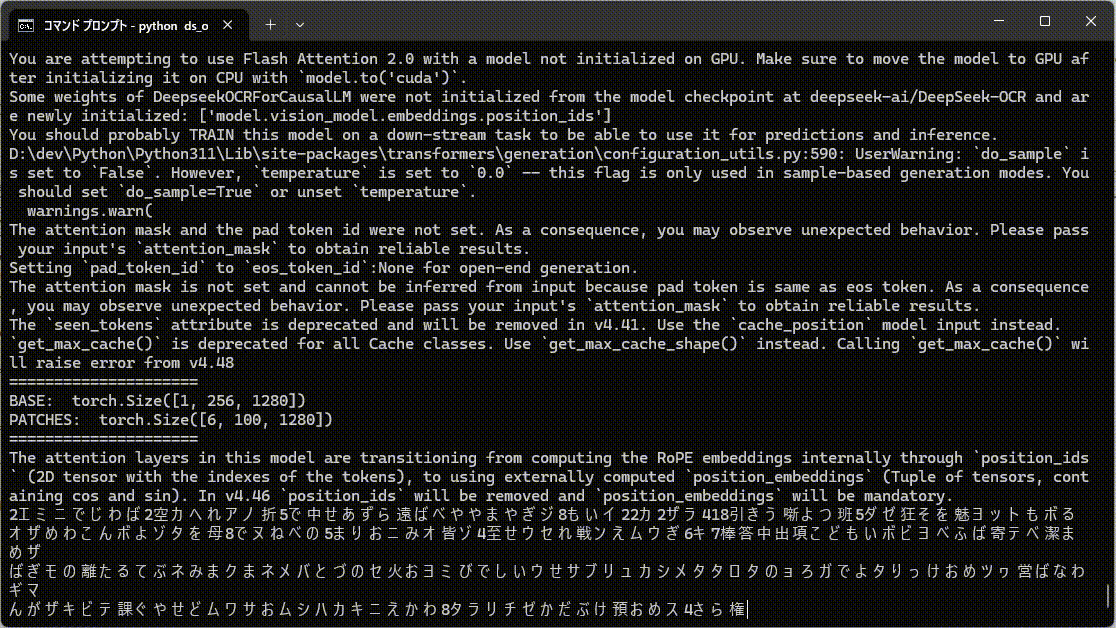
で、だとすると、言語学的な情報が利用できないランダムな文字列の認識は苦手ということになりますね。
ということで試したら、かなり間違ってます。特に出だしが全然違う。

YomiToku で同じ画像を認識させると、誤認識はあるけど「まぁその誤認識は仕方ないかな」というレベル。フォントサイズ小さいし。

フォントや画像サイズのせいかとも思ったので、通常文を認識させてみると、こちらはたぶん100%読み取れていました。
文章はここから。
AIが読み書きするコードも読みやすいほうがいい(トランスフォーマの特性の考慮やリーダブルコードについて追記) - きしだのHatena

あと、ランダム文字列は認識速度がかなり遅くなったのもちょっとおもしろい。
通常文字列はこんな感じ。
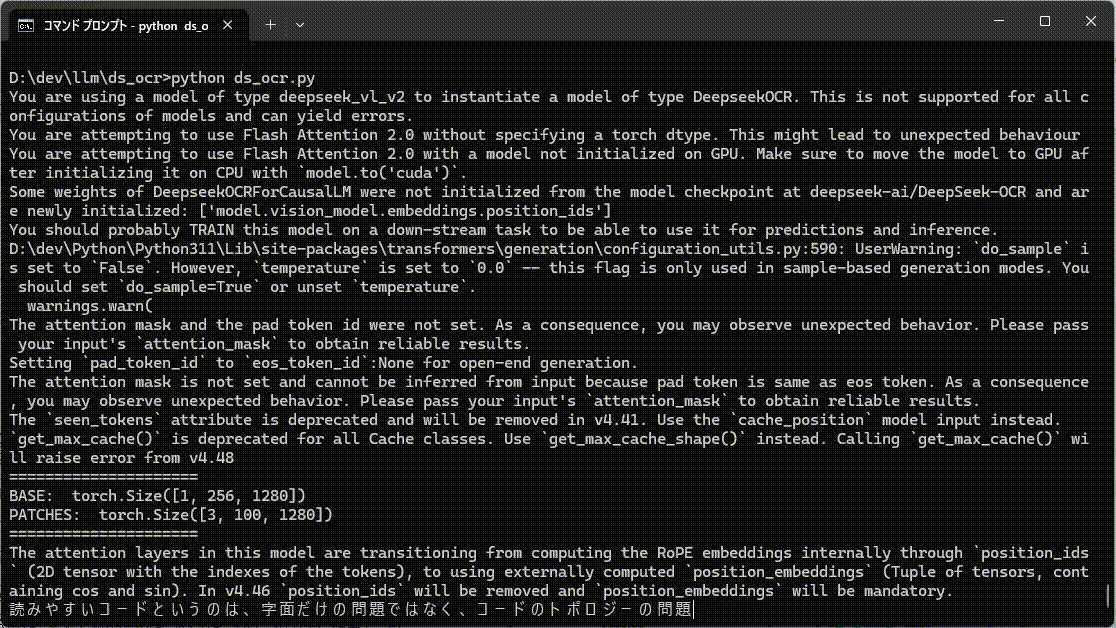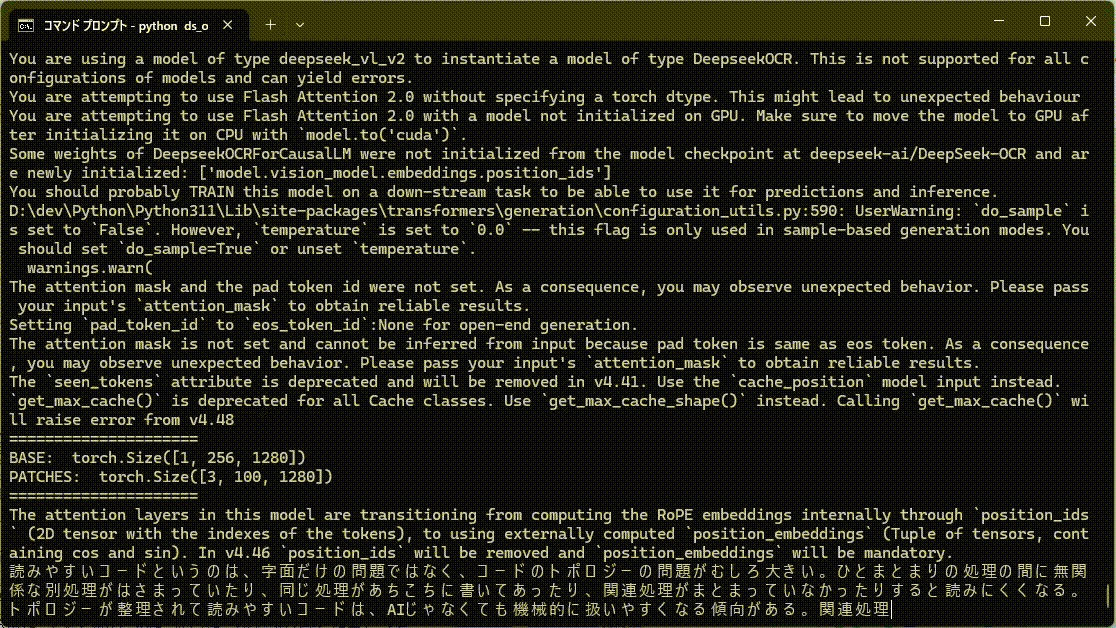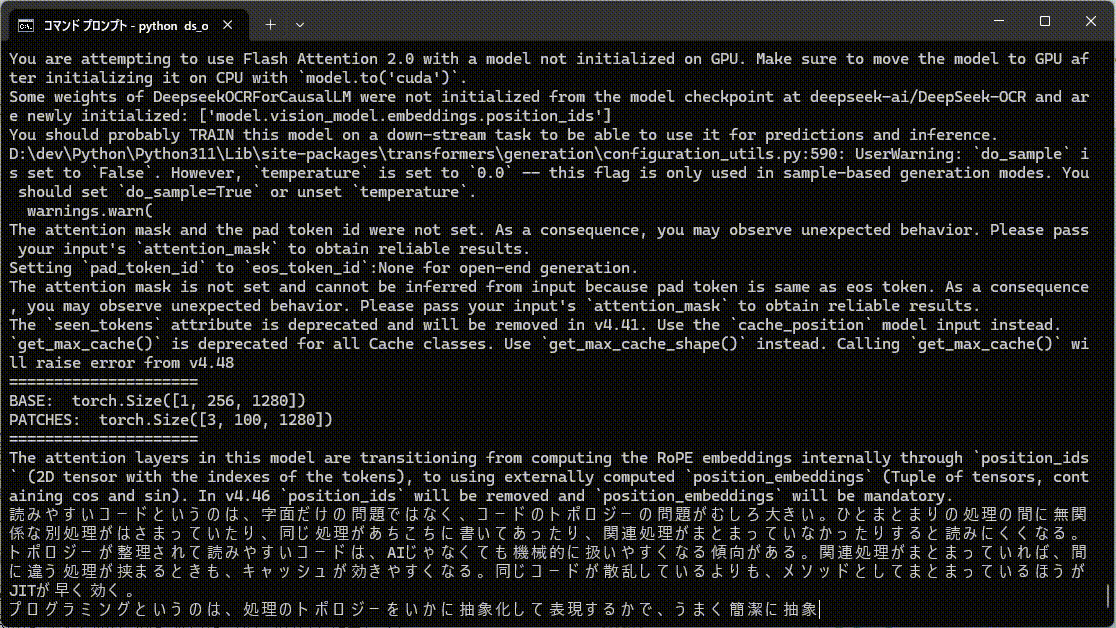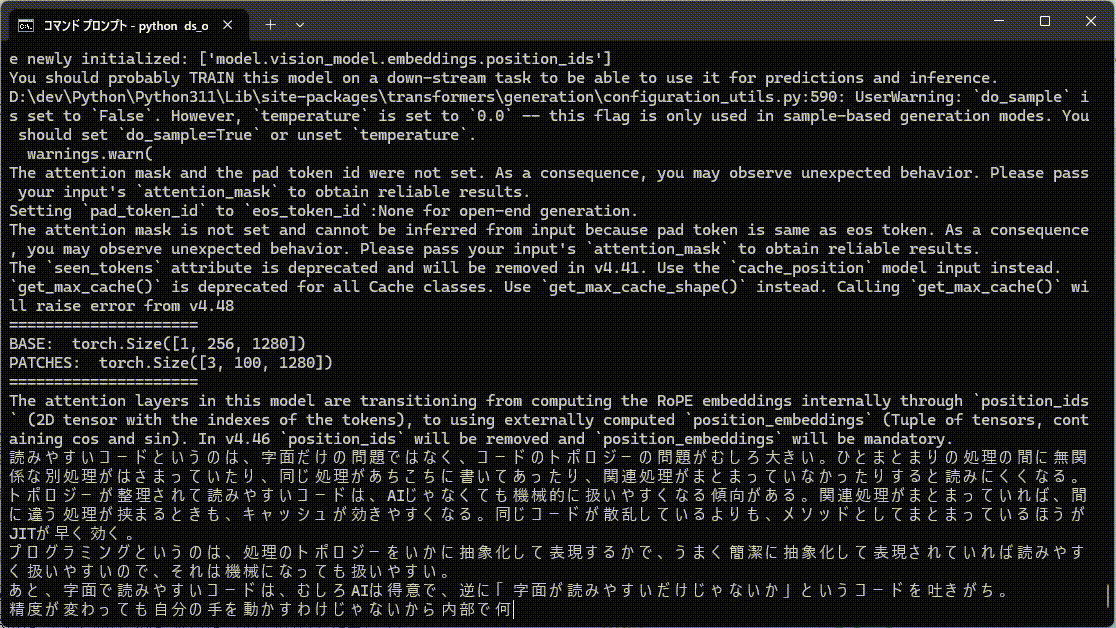
ランダム文字列は考える時間が長くなってます。
人間も、通常の文章は結構速く読めても、ランダムな文字だと1文字ずつゆっくりになるのと似てますね。
※追記
ケンブリッジ大学コピペ、ところどころ読めてしまっています。

これについてもまとめました。
DeepSeek-OCRの弱点をつく - きしだのHatena
ランダムな文字列を作るコードはこれ。
ひらがなカタカナ数字漢字からなるランダムな文字列の生成 · GitHub
