OpenAIのオープンモデルが来ました。
120Bと20B。どちらもMoEで、アクティブパラメータはそれぞれ5.1B、3.6Bです。
そして4bit浮動小数点での量子化があるので、120Bは80GBのVRAM、20Bは16GBのVRAMで動きます。
Introducing gpt-oss | OpenAI
LM Studioで動かす。早い!速い!
LM Studioに即来ていました。早い!
最新版にしてllama.cppも更新が必要です。
追記: 0.3.22-b1で正式にgpt-ossに対応したようです。記事を書いた時点での0.3.21-b4では対応が不完全だったらしい。
起動時にgpt-oss-20bのダウンロードを勧めてきますね。
ということで、RTX4060 Ti 16GBで動かしました。71token/sec!速い!
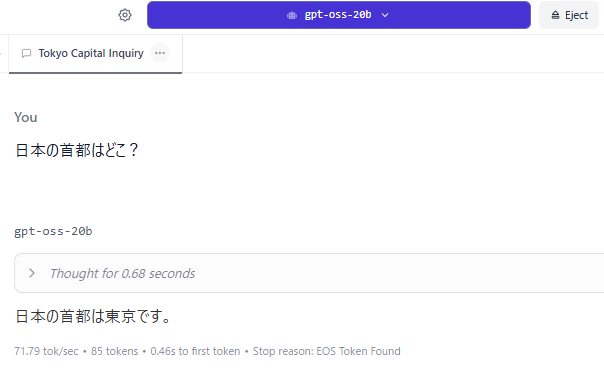
17000トークンまでならVRAMに載りそう。
送信時にReasoningの深さを指定できるようになっています。
Qwen3 30Bを2bit量子化で動かせば80token/sec出てたのだけど、賢さはかなり犠牲にしていました。しかしGPT-ossは賢い!
もう、これを使わない理由はないですね。
口調がChatGPTだ!
「なぜ逆になっているのか」みたいな表題を書いてしまう。
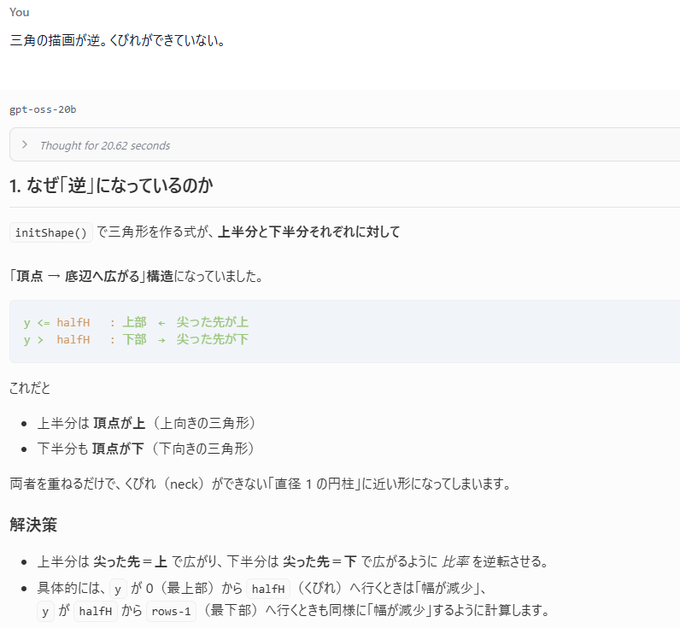
『「頂点→底辺へ広がる」構造』みたいに鍵カッコでくくったり、文の途中に箇条書きが入ったり。
ちゃんと動いたことを報告すると「Happy coding!」って出してくれるのもChatGPTっぽい。
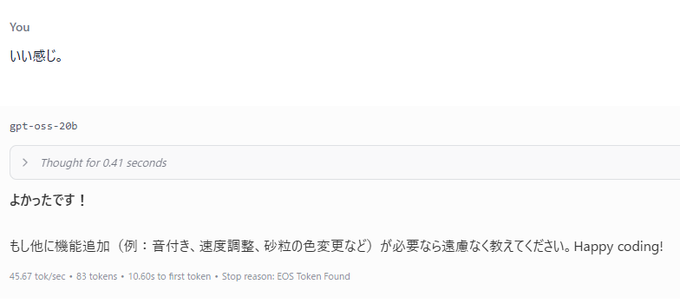
完全に、OpenAIモデルですね。
山口県について聞く
山口県についても聞いてみましょう。
LLMの日本知識を測るのに山口県について聞くのがよかった - きしだのHatena

なんかいっぱい書くけど、市名人名以外の固有名詞だいたい間違ってますね。
ただ、要所は押さえている感じなので、グローバルモデルとしては結構いいと思います。
一応難しい計算させておく
すぐ答えた。
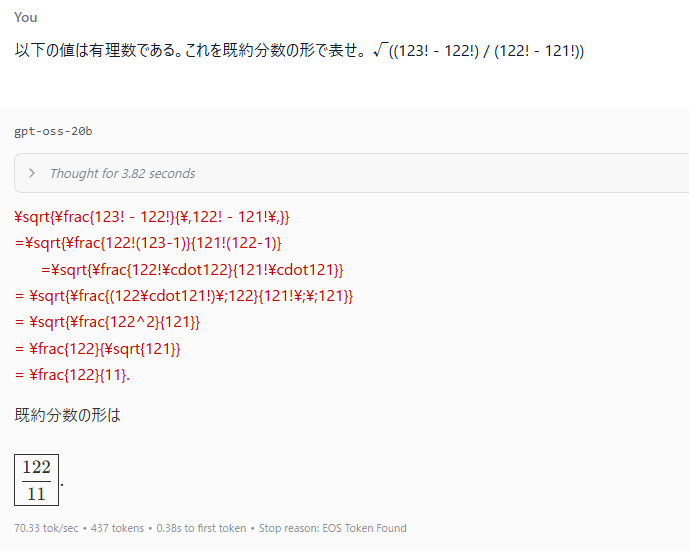
コードを書かせる
ということでコードを書かせます。
「JavaのSwingでブロック崩しをつくって。ブロックを硝子のように表現できる?」とやってみます。
最初はコンパイルエラーが出てましたが、エラーを伝えると一発で修正。
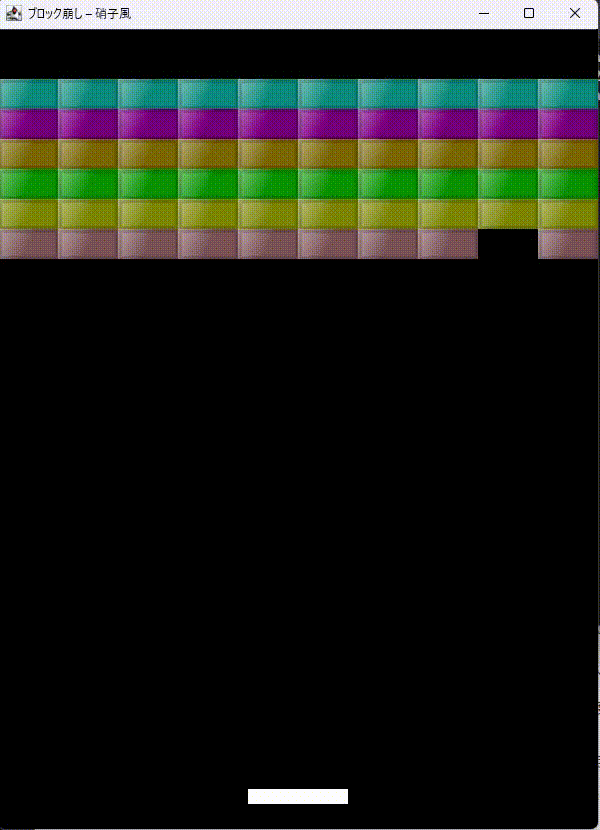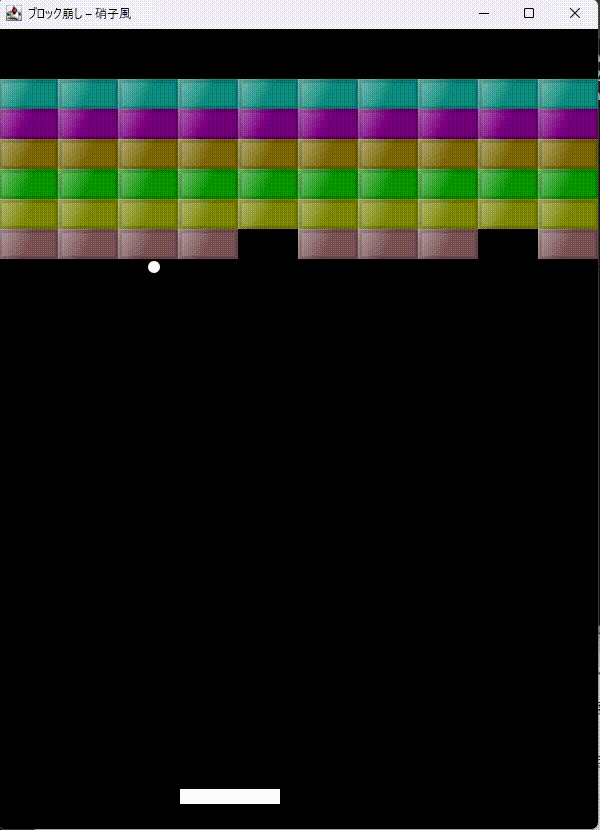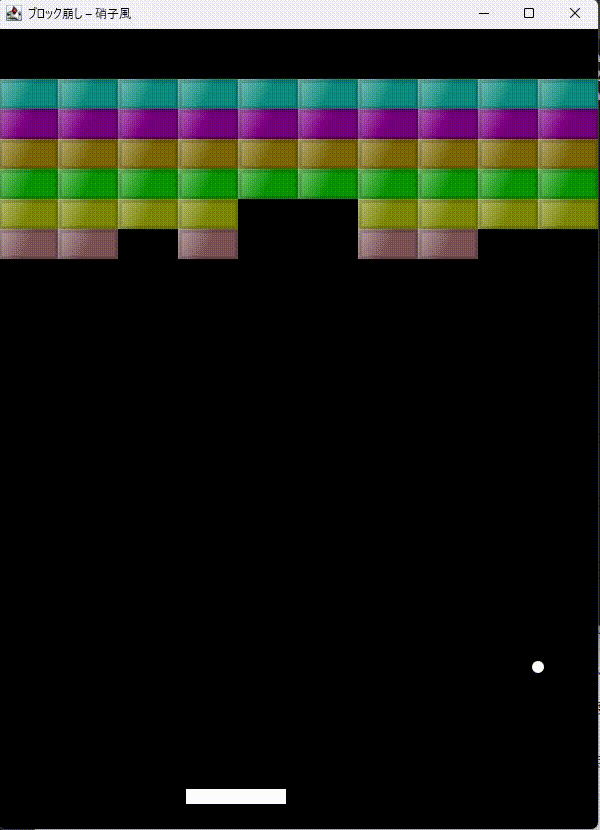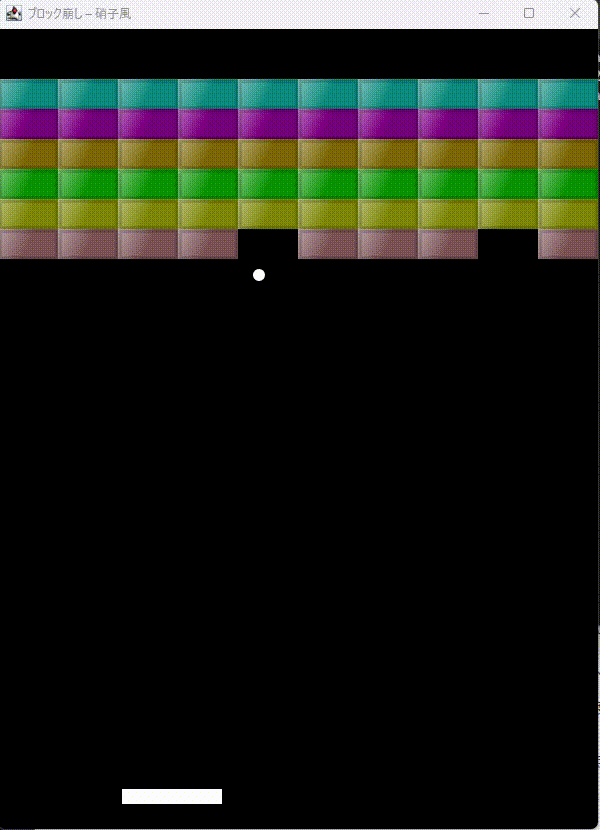
凝った描画させるとAPIがややこしいのでコンパイルエラーは仕方ない。エラーを一発修正が偉いと思います。
その後もリスタート機能を実装したりと修正を加えたけど安定していました。
そして砂時計。
「砂の動きをそれっぽく表現した砂時計をJavaのSwingで作って」
最初は時計の三角が逆向きで、菱形になってたけど、ちゃんと砂時計のようになりました。

かなり修正してもらっていたのだけど、コンパイルエラーは一度もなかった。えらい。
一度、描画まわりで実行時例外が出ていたけど、例外メッセージ貼り付けると修正してくれました。
かなりコーディング能力も高そうです。
ただ、設定したコンテキスト長に達すると、コンテキストあふれに対応してないといわれた。LM Studioの制約かな。

エージェントを動かす
雑なコーディングエージェントを動かしてみました。thinkingで時間くってる割に、結構すぐ終わりました。
GPT-oss 20B、17000トークンくらいだと、ちゃんとVRAM16GBに載った。
— きしだൠ(K1S) (@kis) 2025年8月5日
そして、thinkingにコードを全部書くという無駄をやりつつ、この速さでSpring Boot TODO管理を書き終えた。すごい。
システムプロンプトに書いたことをちゃんと言うこときいてくれるのもすごい。 pic.twitter.com/hllwVrEqyj
というかthinkingで一旦コードを全部書き出したりしていて無駄。
「Reasoning: low」って書いておけばthinkingを減らしてくれそうなことがモデルカードに書いてあったけど、あまり効きませんでした。

https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
ところで、thinkingを表すタグが<|channel|>analysis<|message|>で始まるなど特殊で、Roo Codeが対応できてませんでした。
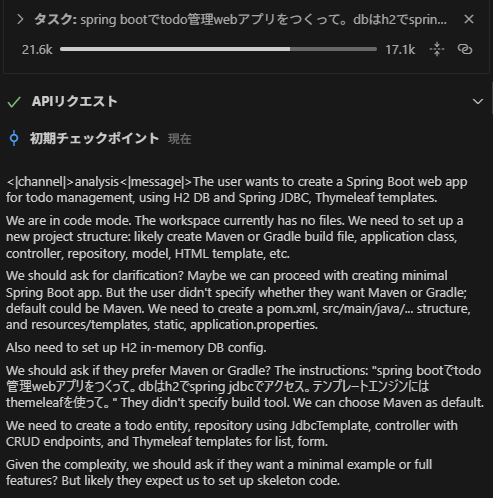
☝の雑エージェントも、そのあたりでちょっとタグの扱いをシステムプロンプトに指示をする必要があったのだけど、すごく素直に書いたとおりに従ってくれて、安心感がありました。
指示追従性めちゃ高い。
追記:LM Studioの更新で<|channel|>などのタグに対応してくれてたりReasoningの深さが設定できるようになっていました。そのおかげで、雑コーディングエージェントも爆速で40秒でSpring BootのTODOアプリを作ってくれました。Roo Codeはやはりうまく動いてくれていないけど。
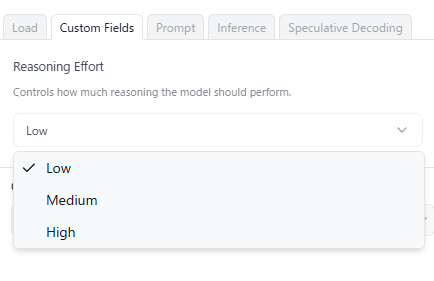
なんか、LM StudioがちゃんとGPT-ossのフォーマットに対応したおかげか、 Reasoning: low が効くようになって最低限のthinkingになったので、 雑コーディングエージェントでRTX 4060 Ti 16GBでSpring Boot TODOアプリを40秒で生成するようになった。
— きしだൠ(K1S) (@kis) 2025年8月6日
リアルタイム。早送りなし。 pic.twitter.com/WGLlMYCLW0
まとめ
速いし賢いし指示に従ってくれるし、すごすぎる。
120Bは試せてないけど、20Bでこれなら120Bどうなってるの・・・という感じします。
ただ、ClineやRoo Codeでのツール呼び出しがうまくいかないようで、<|chennel|>タグとXMLが相性わるそうです。雑エージェントでも結構対策が必要でした。
ともあれ、Qwen3が出たときは「普通のPCで動くローカルLLMにちゃんとした用途ができそう」という感想だったのが、GPT-ossは「普通のPCで動くローカルLLMでちゃんと使えそう」という感じです。
Qwen3はローカルLLMの世界を変えたかも - きしだのHatena
