DeepSeek R1が話題になってだいぶたちますが、日本語対応モデルも出てきてますね。
そして2/15にrinnaからDeepSeek R1の蒸留モデルが出ていて、これがかなりいい感じなのでびっくりしてます。驚き屋してます。
DeepSeek R1では、こっそりと回答方針を決めるフェーズがあるのだけど、そこがなかなか筋がいい。
というか、作り方もなんだかすごいので最後に解説してます。
Qwen2.5とDeepSeek R1を利用した日本語大規模言語モデル「Qwen2.5 Bakeneko 32B」シリーズを公開|rinna株式会社
※ 2/18追記 こういう記事を書くときに「これがローカルで動いてすごい」のように書くんですが、ここではローカルで動いてすごいということは書いてなく、普通にちゃんと答えがでてその内容がすごいという風になってきてますね。追記ここまで。
CyberAgentからもDeepSeek R1の蒸留モデルを日本語化したものが出ているのだけど、これに比べて「いいとこついてるなぁ」となります。というか、o1よりいいんではと思うことすらある。
https://huggingface.co/cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese
VRAMが16GBなので、2bit ggufモデルを使っています。Macでもメモリが32GBくらい載ってれば、割と動きます。
rinnaのモデルは公式にggufが出ているのでこちらを。
https://huggingface.co/rinna/deepseek-r1-distill-qwen2.5-bakeneko-32b-gguf
CyberAgentモデルはmmngaさんのを使っています。rinnaモデルにあわせてQ2_Kを使います。
https://huggingface.co/mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese-gguf
UIにはLM Studioを。
https://lmstudio.ai/
CyberAgentモデルでJavaの講義資料から確認問題を作ってもらうときの計画はこうなっていました。最低限やることを確認しているという感じ。

rinnaのモデルでは「4択形式なので、誤りやすい選択肢を含めるべきでしょう」「ユーザーが混乱しそうなポイントを問います」「ユーザーが理解しているかどうかを確認できるような問題にします」といった意図が明確になっています。

ただ、実際の出力ではそこまで違いは見えなくなっています。CyberAgent版もそこそこいい出力が行われます。rinna版のほうがハズレにくい、という感じ。
あと、rinnaのモデルはDeepSeek R1の標準的な出力と少しフォーマットが違うので、LM StudioがThoughtsとして判定してくれていません。Prompt Templateを書き換える必要があります。
ところで、CyberAgentから出ているものは「DeepSeek R1の蒸留モデルを日本語化したもの」で、rinnaから出ているものは「DeepSeek R1の日本語蒸留モデル」です。似ているけど技術的には別モノです。
CyberAgentは、DeepSeek自身がQwenに対してDeepSeek R1を蒸留したモデルに日本語追加学習を行っています。

一方で、rinnaはQwenを日本語追加学習したものに、DeepSeek R1から作った日本語蒸留データを適用しています。
というか、話はそう単純じゃなく、Qwen2.5に日本語追加学習したQwen2.5-bakenekoを作って、そこにDeepSeekの蒸留モデルからQwen2.5の重みを引いたものを足して、mergeモデルを作ったうえで、そこにDeepSeek R1から作った日本語蒸留データを適用しています。
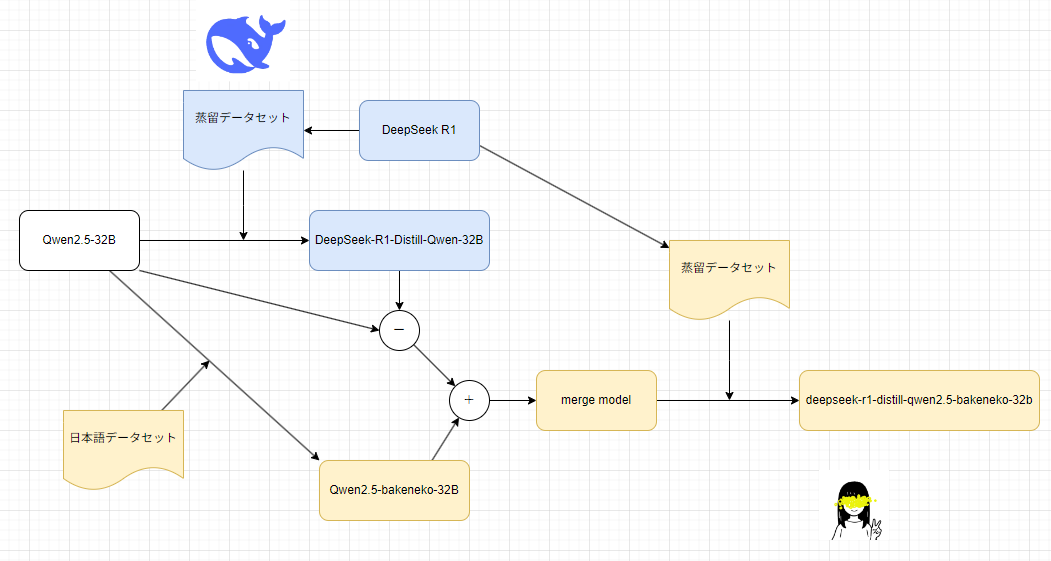
rinnaでは1,200件の日本語蒸留データを使って学習させたということなんですが、このデータの質がかなりいいんじゃないかなと思います。
蒸留について解説されてる本はこのあたりかな。
