はじめに
七尾百合子さん、お誕生日 31日目 おめでとうございます! nikkieです。
ADKをきっかけに、Vertex AIの機能を知りました。
目次
- はじめに
- 目次
- 経緯:Agent Development Kitでエージェントの評価
- 結論:Vertex AIのExperimentを作って、評価を実行している
- EvalTask.evaluate()
- 終わりに
経緯:Agent Development Kitでエージェントの評価
Cloud Next ‘251で発表された Agent Development Kit (ADK)
作ったAgentを評価する(evaluate)機能もあります
その具体的なやり方は「How to run Evaluation with the ADK」を参照。
- pytestで
AgentEvaluator.evaluate()を実行 adk evalコマンドにAgentを実装したモジュールを指定
が挙がっています。
AgentEvaluator.evaluate()の中では、ResponseEvaluator.evaluate()が呼び出されるようです(Claudeにガイドしてもらってソースリード)。
https://github.com/google/adk-python/blob/v0.1.0/src/google/adk/evaluation/agent_evaluator.py#L287-L289
またadk evalコマンドでもResponseEvaluator.evaluate()が呼び出されます。
https://github.com/google/adk-python/blob/v0.1.0/src/google/adk/cli/cli_eval.py#L203
ResponseEvaluator.evaluate()では、vertexai.preview.evaluation.EvalTaskを扱っていました。
https://github.com/google/adk-python/blob/v0.1.0/src/google/adk/evaluation/response_evaluator.py#L109-L111
これが何なのか、手を動かしていきます。
結論:Vertex AIのExperimentを作って、評価を実行している
% uv run --python 3.12 script.py
Associating projects/<project_number>/locations/us-central1/metadataStores/default/contexts/test-experiment-run-20250417-221232 to Experiment: test-experiment
Logging Eval Experiment metadata: {'model_name': 'publishers/google/models/gemini-2.0-flash'}
Generating a total of 1 responses from Gemini model gemini-2.0-flash.
100%|███████████████████████████████████████████████████████████| 1/1 [00:03<00:00, 3.95s/it]
All 1 responses are successfully generated from Gemini model gemini-2.0-flash.
Multithreaded Batch Inference took: 3.966085167019628 seconds.
Computing metrics with a total of 2 Vertex Gen AI Evaluation Service API requests.
100%|███████████████████████████████████████████████████████████| 2/2 [00:02<00:00, 1.05s/it]
All 2 metric requests are successfully computed.
Evaluation Took:2.1127180829644203 seconds
{'row_count': 1, 'rouge_l_sum/mean': np.float64(0.048780486), 'rouge_l_sum/std': 'NaN', 'safety/mean': np.float64(1.0), 'safety/std': 'NaN'}
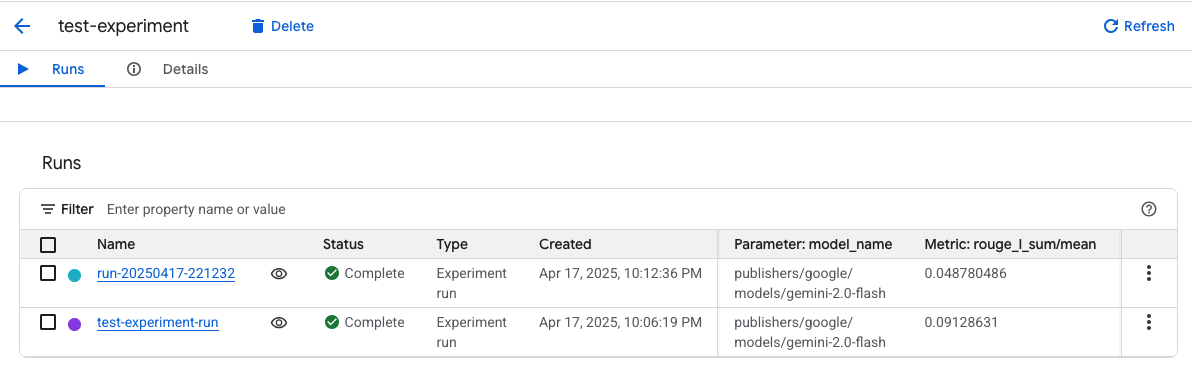
EvalTask.evaluate()
Vertex AIのドキュメントで見たところだ!
とにかく小さく動かしたかったので、ライブラリ内のテストの実装を参考にしました。
https://github.com/googleapis/python-aiplatform/blob/v1.89.0/tests/system/vertexai/test_evaluation.py
vertexai.init()は過去記事より(projectとlocationの指定省略)- datasetは1件
- prompt:「空はなぜ青いの?」
- reference:正解例
- metrics:ROUGEと安全性の2点で評価
- 後者はLLM as a Judgeなのかな?(宿題事項)
- データ1件を2観点で評価したと理解
- runの名前は重複できないようだったので、日時を使用
vertexai.preview.evaluationにもvertexai.evaluationにも見つかったので、「プレビューでなくなった?」と考え後者を選択
終わりに
ADKの評価を機に、Vertex AIのEvaluationを知りました。
今回は触り始めとして一例だけで動かしています。
できることとしては、最近触ったinspect-aiと近いかも
事前にVertex AI Experimentを知っていたらADKでのエージェント評価はスラスラいきそうですが、まだ見ぬ機能の登場に「情報量が...多い...!!」となってます
- 自分用まとめ ↩
