OpenAIのGPTシリーズやxAIのGrok、MetaのLlamaなどさまざまな大規模
言語モデルが存在しますが、これらの構造を図示した「LLM Architecture Gallery」がオンラインで公開されています。
LLM Architecture Gallery | Sebastian Raschka, PhD
https://sebastianraschka.com/llm-architecture-gallery/
The Big LLM Architecture Comparison
https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
AI研究者兼
エンジニアであるセバスチャン・ラシュカ氏は、OpenAIが2019年に発表したGPT-2と2025年に発表された
DeepSeek V3やLlama 4を見比べると、
モデルの構造的な部分がとてもよく似ていると指摘。「こうした細かな改良の裏で、私たちは本当に画期的な変化を目にしてきたのでしょうか?それとも単に同じアーキテクチャの基盤を磨き上げているだけなのでしょうか?」と疑問を提起しています。
大規模
言語モデルのパフォーマンスに影響する要素にはデータセットやトレーニング手法、ハイパーパラメータなどさまざまなものがありますが、これらは大規模
言語モデルによって大きく異なり、多くの場合は十分に文書化されていないため比較が困難だとのこと。
そのためラシュカ氏は、大規模
言語モデルの開発者がどのような取り組みをしているのかを知るには、アーキテクチャ自体の構造的変化を検証することが役立つと主張。大規模
言語モデルのアーキテクチャを図示した「LLM Architecture Gallery」を作成しました。
LLM Architecture Galleryにはさまざまな大規模
言語モデルが掲載されており、クリックすると図を見ることができます。記事作成時点で図が作成されているのは以下の
モデルです。
・Llama 3 8B
・OLMo 2 7B
・
DeepSeek V3
・
DeepSeek R1
・Gemma 3 27B
・Mistral Small 3.1 24B
・Llama 4 Maverick
・Qwen3 235B-A22B
・Qwen3 32B
・Qwen3 4B
・Qwen3 8B
・SmolLM3 3B
・Kimi K2
・GLM-4.5 355B
・GPT-
OSS 120B
・GPT-
OSS 20B
・Grok 2.5 270B
・Qwen3 Next 80B-A3B
・MiniMax M2 230B
・Kimi Linear 48B-A3B
・OLMo 3 32B
・OLMo 3 7B
・
DeepSeek V3.2
・Mistral 3 Large
・Nemotron 3 Nano 30B-A3B
・
Xiaomi MiMo-
V2-Flash 309B
・GLM-4.7 355B
・Arcee AI Trinity Large 400B
・GLM-5 744B
・Nemotron 3 Super 120B-A12B
・Step 3.5 Flash 196B
・Nanbeige 4.1 3B
・MiniMax M2.5 230B
・Tiny Aya 3.35B
・Ling 2.5 1T
・Qwen3.5 397B
・Sarvam 105B
・Sarvam 30B

たとえば「Llama 4 Maverick」をクリックすると、アーキテクチャを示した図が表示されました。図を拡大するにはクリック。

拡大した図はこんな感じ。画面右上の「View in article」をクリックすると、各
モデルについてのラシュカ氏による解説を読むことができます。

ラシュカ氏はさまざまな大規模
言語モデルについて、その他の
モデルと比較しながら共通点や違いを解説しています。

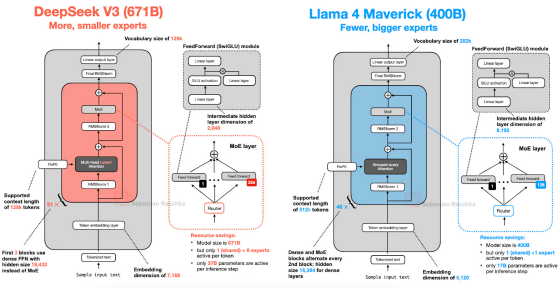
たとえばLlama 4は
DeepSeek V3と非常によく似たアーキテクチャを採用しており、いずれも「Mixture-of-Experts(MoE)」という機械学習アプローチを採用しているとのこと。主な違いは、Llama 4ではTransformer
モデルの注意メカニズムの効率を高める方法としてGrouped-Query Attention(GQA)を採用しているのに対し、
DeepSeek V3ではMulti-Head Latent Attention(MLA)を採用している点だとのこと。
GPT-
OSSとQwen3は類似したコンポーネントを使用していますが、さまざまな処理を行うTransformerブロックの数がGPT-
OSSは24個であるのに対しQwen3は48個となっているほか、埋め込み次元などにも違いがあります。

Grok 2.5は全体的にかなり標準的な構造をしているものの、MoEを構成する個別のサブ
ネットワーク(エキスパート)の数が8個と、Qwen3の128個と比べてかなり少数だという点が特徴です。新しい設計ではより多くのエキスパートを使用することが推奨されているため、Grokは古い
トレンドを反映しているとのこと。また、Grokは追加のSwiGLUモジュールを常時稼働する共有エキスパートとして使用している点も興味深いとラシュカ氏は説明しました。




