DeepSeekが、数学的推論に特化したAI
モデル「
DeepSeek-Math-
V2」を2025年11月27日に公開しました。この
DeepSeek-Math-
V2は定理証明と自己検証機能に重点を置いており、従来の数学AI
モデルとは異なり、解答の正確性を追求するだけでなく、推論プロセスの厳密性と完全性も重視しています。
GitHub - deepseek-ai/
DeepSeek-Math-
V2https://github.com/deepseek-ai/
DeepSeek-Math-
V2
deepseek-ai/
DeepSeek-Math-
V2 · Hugging Face
https://huggingface.co/deepseek-ai/
DeepSeek-Math-
V22025 Major Release: How Does
DeepSeekMath-
V2 Achieve Self-Verifying Mathematical Reasoning? Complete Technical Analysis - CurateClick
https://curateclick.com/blog/deepseekmath-v2
従来の大規模
言語モデルは主に最終的な答えが合っているかどうかを報酬として与える「強化学習」によってトレーニングされてきました。しかし、この方法では、答えが偶然合っていても途中の
考え方が間違っている場合を見抜くことができません。特に、定理の証明のような高度な数学においては、数値の答えが存在せず、厳密な論理の積み重ねそのものが求められるため、従来の手法だけでは限界がありました。
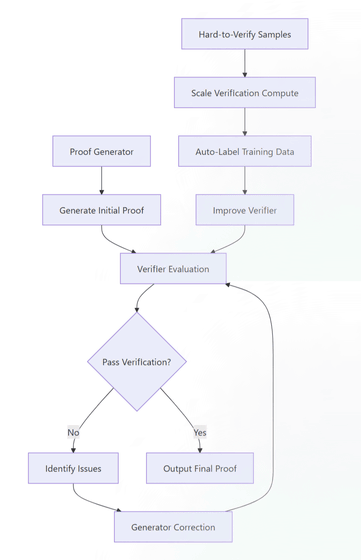
この課題を解決するために採用された技術が、証明を作成する「生成器」と、その証明が正しいかを判定する「検証器」という2つの
モデルを協力させるアーキテクチャです。
DeepSeek-Math-
V2のトレーニングは3つの段階で行われます。最初に検証器をトレーニングし、次にその検証器を先生役として生成器を学習させます。次に、生成器は検証器からのフィードバックを受け取りながら、自分の証明に含まれる誤りを特定し、修正するように訓練されます。そして、検証のための計算量を増やすことで、AIが自動的に難しい証明の正誤を判断し、それを新たな学習データとして活用することで、検証器の能力をさらに高めるというサイクルを回します。
この技術的な革新により、
DeepSeek-Math-
V2は世界的な数学コンテストで非常に高い成績を収めています。たとえば、2025年の国際
数学オリンピック(IMO)では金メダルレベルとなる83.3%の得点率を記録しました。また、
カナダ数学オリンピック(
CMO)2024では73.8%、
アメリカの大学レベルの競技であるPutnam 2024においては98.3%という驚異的なスコアを達成しています。

他社の高性能
モデルと比較しても、Gemini Deep ThinkやCl
aude Sonnet 4などを上回る成果をProofBenchという評価指標で示しており、特に難易度の高い問題においてその強さを発揮しています。
 DeepSeek
DeepSeek-Math-
V2は
DeepSeek-V3.2-Exp-Baseをベースに構築されており、Hugging Faceからダウンロードすることが可能です。



