画像
生成AIや画像を分析するためのAIをトレーニングするためには、ネコの画像に「ネコ」「歩いている」「しま模様」というようなラベルを手作業で大量につけたデータが必要です。しかし、Metaが発表した「DINOv3」という
モデルは、ラベルなしの画像17億枚を使ってトレーニングされており、ラベルに縛られないさまざまなタスクを人間の介入なしに専門の
モデル以上の性能でこなすことができます。
DINOv3: Self-supervised learning for vision at unprecedented scale
https://ai.meta.com/blog/dinov3-self-supervised-vision-model/

DINOv3 | Research - AI at Meta
https://ai.meta.com/research/publications/dinov3/
視覚的タスクをこなすAIの学習は「人間の手でラベル付けした画像」に依存するものが主流で、テキストで明示的に言及されていない情報が無視されたり、専門的な映像には正確なラベル付けが難しかったりといった問題がありました。DINOv3の前身であるDINOv2は、自己教師あり学習により動的な映像から従来のものより高精度なセグメンテーションを生成可能で、人間によるラベル付けなしに自己学習ができるため、人間の説明が届かないデータも余すところなく
モデルに組み込むことができます。
Metaが映像処理
モデル「DINOv2」を発表、将来はAIにより没入型VR環境が作れる可能性 -
GIGAZINE
そんなDINOv2をさらに発展させたのがDINOv3です。まず大きな違いとして、ラベル付きデータを必要としない革新的なトレーニング技術によって、DINOv2が約11億パラメータなのに対してDINOv3は約70億パラメータと、
モデルの規模が約7倍まで拡張されました。

また、トレーニングに使われたデータ量はDINOv2が約1億4200枚、DINOv3約17億枚と、約12倍に増加。
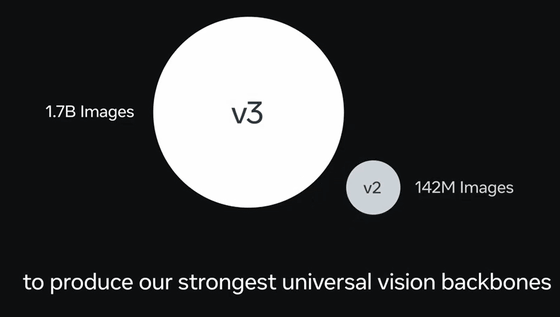
画像や動画を読み込ませる際、通常はどのようなデータなのか人間の手でラベル付けが必要です。

DINOv3では、ラベル付けの手間がなく、背景などの細かいポイントまで余すところなく学習させることができます。また、自己教師あり学習を採用しているため、「画像の一部を隠して、他の部分から予測する」「同じ画像を回転させたり切り抜いたりして特徴を学ぶ」というような、
モデルが自分で学習のための疑似タスクを作ってトレーニングが進みます。

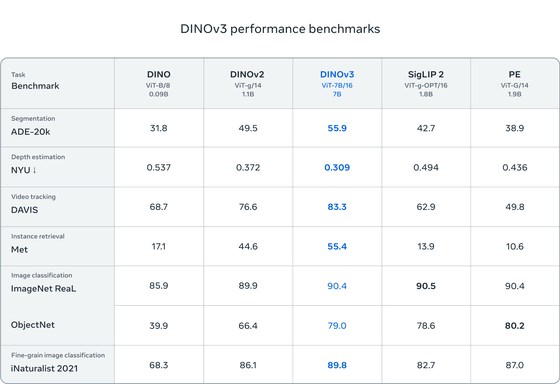
以下は、DINO、DINOv2のほか、Google DeepMindのSigLIP 2やMetaのPerception Encoderという高性能な画像・
言語理解
モデルと比較して、DINOv3の性能をさまざまな画像分類ベンチマークでテストした結果。いずれのベンチマークでも、DINOv3は前
モデルを大きく上回っており、SigLIP 2やPerception Encoderと比べても同等以上の高いパフォーマンスを発揮しています。
Metaによると、画像や動画から要素を分類・抽出するタスクや、高密度の予測タスクにおいて、DINOv3は専用ソリューションを上回る性能を発揮したとのこと。DINOv3は既存のユースケースを加速させるだけではなく、ヘルスケアや環境モニタリング、
自動運転車、小売や製造など、さまざまな業界の進歩につながることが期待されています。
また、DINOのアプローチは特定の種類の画像に特化していないため、組織学、内視鏡検査、
医療用画像処理など、ラベル付けが非常に困難または高価である他の分野にも適用することができます。また、膨大なデータ量と複雑さのため手作業によるラベル付けが現実的ではない衛星画像や航空画像でも、DINOv3なら豊富なデータセットを使用して単一のバックボーンをトレーニングできるため、環境モニタリングや
都市計画、災害対応などの
アプリケーションを発展できます。
MetaはDINOv3の詳細をGitHubやHugging Faceで公開しています。ただし、DINOv2が
オープンソース化されていたのとは異なり、DINOv3はトレーニングコードと事前トレーニング済みのバックボーンを「DINOv3 License」という独自ライセンスの下でリリースしています。
GitHub - facebookresearch/dinov3: Reference PyTorch implementation and models for DINOv3
https://github.com/facebookresearch/dinov3
DINOv3 - a facebook Collection
https://huggingface.co/collections/facebook/dinov3-68924841bd6b561778e31009



