
はじめに
お疲れ様です。2357giです。先日のre:Inventで参加したセッション「Build high-performance inference APIs with Lambda SnapStart」にて、「数GB級のLocal LLMをサーバレスで、本番環境の要求水準で動かす」方法を学んできました。
(その際のセッション形式が「チョークトーク」というもので、めちゃめちゃ良い体験だったのですがその話はこちら )
llama.cppなどの比較的軽量なLLM(1GB~5GB)や、それらと同程度のサイズの自作モデルをLambdaを用いて動かすというものです。
bedrockにカスタムモデルインポートがある現在、本アーキテクチャに優位性があるケースは多くないと思います。セッション中でも「YOLOなどの画像認識や、10 GBに収まる言語モデル、文字起こしなどのモデル組織に合わせてカスタム化されたモデルで、且つ高スループットと低レイテンシーを必要とするケースに適している」と語られていました。
が、Lambdaのパッケージサイズ制限に収まらないモデルを動かす方法や、そのLambdaを本番環境レベルのレイテンシ(1~2s)で動かす方法など技術的面白ポイントが多かったので、そういった点を中心にレポートしていきたいと思います。
正月休みの自由研究として、公式のサンプル実装を先に見ずにまず実際に手元で実装し検証してきたので、そこで得た躓きポイントも含めてレポートしていきたいと思います💪
AWSによるサンプル実装はこちら
AWSによる関連ブログはこちら
(車輪の再発明にはなりますが、長期休みの自由研究なので😎 )
セッションの中で、数GB級のLocal LLMをサーバレスかつ本番環境の要求水準で動かすにあたって、大きく以下3つのポイントとして語られていました。
- 数GBのモデルと、Lambdaパッケージサイズ制限
- コールドスタートの問題
- LLMに求められるストリーミングの実現
それぞれ解説していきます🙌
(*情けない前置きと保険になってしまいますが、本記事内で出てくる「セッションの内容を元にした情報や説明」は筆者の乏しい英語力と、LLMによる文字起こしを根拠にしているので、誤情報が含まれる可能性があります。ご容赦ください 🙇️)
数GBのモデルと、Lambdaパッケージサイズ制限
Lambdaのパッケージサイズには厳しいサイズ制限が存在します。zip Lambdaの場合は250MB、 OCI(Open Container Initiative)の場合は10GBです。数GBのモデルを動かそうとする場合、zip Lambdaではまず不可能です。しかし、無邪気にOCI Lambdaを使用して数GBのモデルをLambdaに乗せようとするとコールドスタートが長くなる可能性があります。10秒以上のコールドスタート時間が発生するケースもあります。
この問題について、re:inventのセッションでは、「モデルをS3に配置し、実行時にLambdaの実行環境にロードする」というアプローチが紹介されていました。
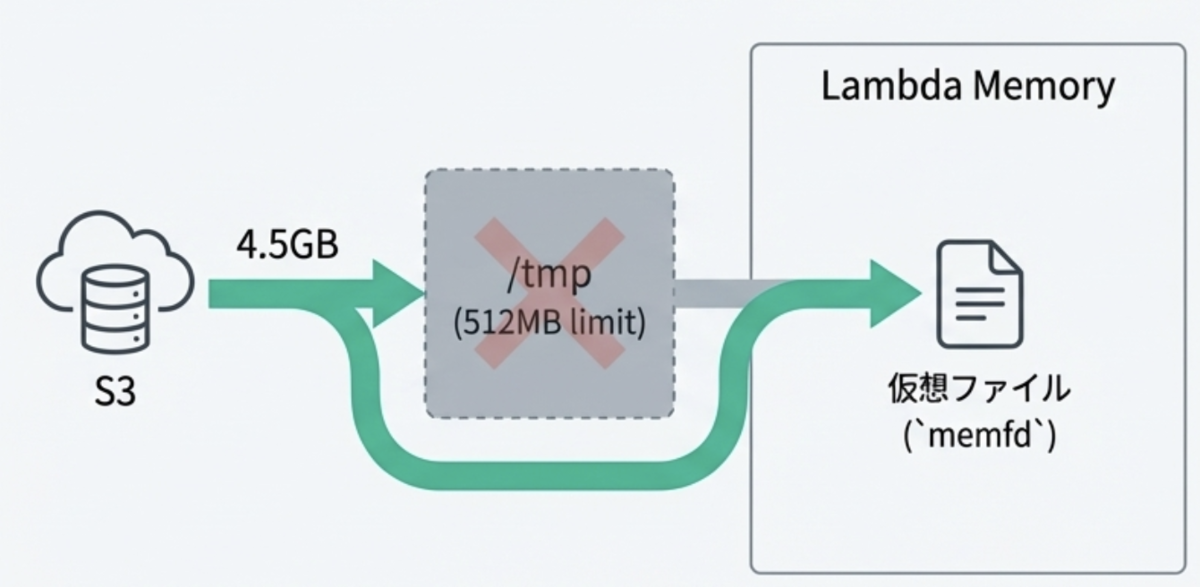
ただ、シンプルにS3からロードしようとすると、Lambdaの /tmp ディレクトリが512MBに制限されているという、また別の壁が立ちはだかります。
通常、Lambdaの /tmp (エフェメラルストレージ)は最大10GBまで拡張することができますが、本番環境で求められる水準で動かすとなると、コールドスタートによる遅延に対処するために後述するSnapStartを有効化する必要があります。
しかし、SnapStartは512MBを超えるエフェメラルストレージに対応していない為、この制限が出てきます。
この/tmp制限を回避するために、S3 SDKのPython Boto Streamを使用して、メモリに直接ストリーミングする方法があります。
しかし、llama.cppなどlocal llmで推論を用いるためにはファイルディスクリプタ、つまりファイルパス必要になります。
これを解決するために、Linuxのシステムコールであるmemfd_createを利用して、インメモリファイルを作成し、次にS3ファイルをダウンロード、そのmemfdへ直接書き込みを行います。
非常に面白いハックで、S3からダウンロードしたモデルデータをディスク(/tmp)を介さず、直接メモリ上に「仮想ファイル」として作成する仕組みです。
 これにより、ディスクI/Oのオーバーヘッドをゼロにし、
これにより、ディスクI/Oのオーバーヘッドをゼロにし、/tmpをバイパスしてファイルを読み込むことで容量制限を完全に回避できます。
memfd_createでインメモリファイルの作成
libc = ctypes.CDLL("libc.so.6", use_errno=True) MFD_CLOEXEC = 1 # Close the fd when executing a new program memfd_create = libc.memfd_create # インメモリファイルの作成 memfd_create.argtypes = [ctypes.c_char_p, ctypes.c_uint] memfd_create.restype = ctypes.c_int fd = memfd_create(b"model", MFD_CLOEXEC)
S3 マルチパートダウンロードを用いてmemfdへ書き込み
# Create memory file fd = create_memfd() # Pre-allocate the full file size try: os.ftruncate(fd, file_size) except OSError as e: logger.error(f"Failed to allocate {file_size/1024/1024:.2f}MB in memory: {e}") cleanup_fd(fd) raise RuntimeError(f"Not enough memory to load model of size {file_size/1024/1024:.2f}MB") # Calculate parts for parallel download parts = [] for start in range(0, file_size, chunk_size): end = min(start + chunk_size - 1, file_size - 1) parts.append({'start': start, 'end': end}) logger.info(f"Downloading {file_size/1024/1024:.2f}MB in {len(parts)} parts") # Download parts concurrently using ThreadPoolExecutor download_func = partial(download_part, s3, bucket, key, fd) with ThreadPoolExecutor(max_workers=multiprocessing.cpu_count()) as executor: executor.map(download_func, parts) # Create a path that can be used to access the file fd_path = f"/proc/self/fd/{fd}" return fd, fd_path
LambdaからLinuxのシステムコールを呼び出すという概念が無かったので流石に痺れました。
実際にこの手法を試し、ファイルサイズが4.5GBもあるllama-2-7b-chatモデルをLambda上でロードすることに成功しました。
コールドスタートの問題
memfd_createでモデルのロードは成功したものの、そのまま呼び出すとコールドスタートの所要時間が絶望的に長い状態でした。
サンプル実装よりも使用しているモデルサイズが大きいこともありますが、以下のような計測値になっていました😇
| フェーズ | 所要時間 |
|---|---|
| S3ダウンロード(4.5GB) | 62-63秒 |
| 推論など | 20-25秒 |
| 合計 | 84-87秒 |
そこで、セッション中で紹介されていた解決策である「Lambda SnapStart」を導入しました。
これは、関数の初期化フェーズ(今回のケースではモデルのS3ダウンロードとメモリへのロード)を完了した状態をスナップショットとして保存し、次回以降はそのスナップショットから高速に復元する仕組みです。
スナップショット時の処理はモジュールレベルで、ハンドラーの外側に記述しておくことで、Lambda関数のデプロイ時(厳密にはalias発行時)に行われます。
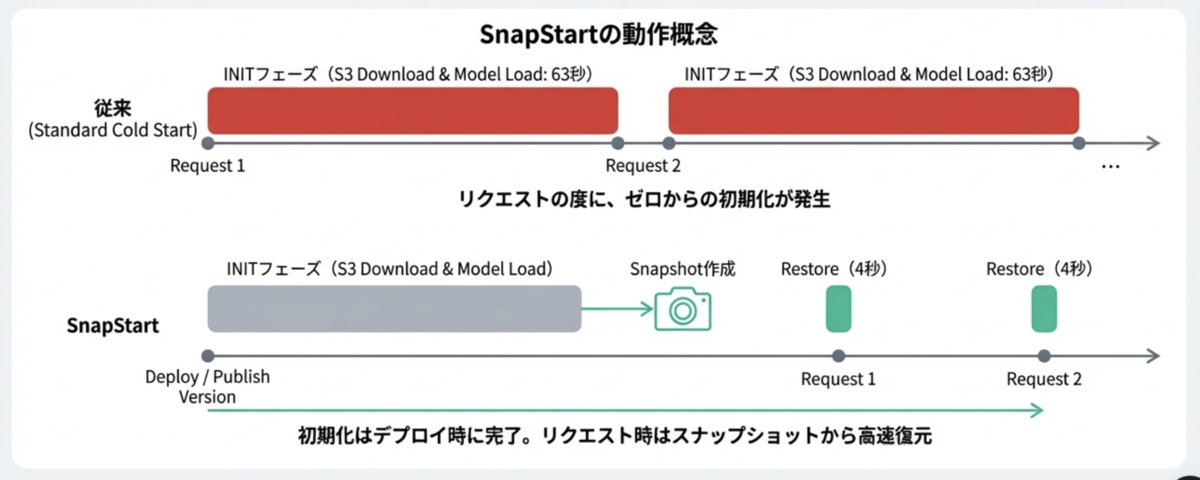
SnapStartの適用により、S3ダウンロードの時間をまるまる削減することに成功しました。
| フェーズ | 所要時間 |
|---|---|
| スナップショット復元時間 | 4.1-4.4秒 |
| 推論時間 | 17.1-17.2秒 |
| 合計 | 21-22秒 |
間話: 推論の高速化
推論時間に20秒もかかるのはとても辛いのでパラメータチューニングを行い、8秒ほどに短縮しました。
これはモデル固有のチューニングであるので詳細は省きますが、割り当てられたCPUリソースを使い切るthreads数を指定していなかったというオチでした😇
LLMに求められるストリーミングの実現
次なる目標は、LLMチャットなどに不可欠な「レスポンスのストリーミング」の実現です。 re:Inventセッションでは「Lambda Web Adapter + FastAPI」というアーキテクチャが紹介されていました。これはLambda内でWebサーバーを動かし、Lambda Function URLs経由でストリーミングを実現するものです。 Lambda内でLLMの回答生成が完了するまでバッファリングすることなく、逐次回答していくことにより、結果として最初の1トークン目がクライアントに届くまでの時間(TTFT[^Time To First Tokenの略])を、Warm Start時には 1~3秒 ほどまで短縮することに実現しました🎉
| フェーズ | 所要時間 |
|---|---|
| ColdStart時のスナップショット復元時間 | 4.1-4.6秒 |
| TTFT | 1.1-3.8秒 |
| 合計 | 1.1-8.4秒 |
この辺り、筆者は5GB近いサイズのモデルを利用しているためこの時間ですが、モデルの選択やスペックによってはもっと早くいけると思います。実際にサンプル実装では1GBほどのモデルにより1~2秒でのレスポンス速度を実現してるとのことです。
ハマりポイントとして、Lambda Web Adapte(LWA)を有効化したところ、SnapStartのためのINIT処理が失敗するようになりました。具体的にはモデルのロード中に失敗してしまう状態です。
原因はLWAがモデルロードの完了を待たずに初期化処理を完了していた点でした。
LWAは同期/非同期2種類の初期化モードを持ちます。非同期モードの場合、LWA自身のReadiness Check(/health等への応答確認)が成功した時点で、Lambdaサービスに対して「INITフェーズ完了」を報告してしまいます。
AWS_LWA_ASYNC_INIT='false'(同期初期化モード)を使用することにより、モデルのロードを待ってINITフェーズの完了とすることになります。この辺りは自前実装をしないと理解に繋がらないポイントだと思うので、良い学びでした。
まとめ
今回はLocal LLMをLambdaで実行するという少し珍しいケースでしたが、この検証を通じて得られた知見は、他の多くのケースでも応用できる汎用的なものばかりでした。
- memfd_createは、LLMに限らず、機械学習のモデルファイルや遅延呼び出し可能なライブラリなど、GB級のファイルをLambdaで扱う際の強力なテクニックになりそう
- SnapStartは、モデルのロードだけでなく、DBコネクションの確立や重いライブラリの初期化など、初期化処理が重いあらゆるLambda関数で有効なコールドスタート対策
- Lambda Web Adapterは、PythonランタイムのLambdaでFastAPIなどの標準的なWebアプリケーションフレームワークを動かすための非常に強力なツールであり、ストリーミング以外にも様々なユースケースが考えられる
ちなみに余談ですが、本セッションの登壇者はLWAの開発者でもありました。
「Pythonランタイムは、今のところ応答ストリーミングを公式にはサポートしていません。幸いなことに、私が作成したLambda Web Adapterというツールがあります。」はウケました(会場もウケてた)。
いやー本当に良い経験をしました。チョークトークに参加して良かったとしみじみ思います。
それではみなさん、良きサーバーレスライフを👋
